






1. 方法分类
梯度驱动方法
(1)完整梯度下降
梯度驱动的NAS方法通过梯度信息来指导架构搜索。典型代表是一系列权重共享的一次性NAS算法(如DARTS),它们将架构参数松弛为可训练的连续变量,通过梯度下降同时优化权重和架构选择,从而在单次训练中完成搜索。然而,这类方法仍需大量训练开销(需训练超级网络),并存在架构间参数干扰等问题。Zen-NAS
(2)初始梯度信号-梯度敏感度
为彻底避免训练成本,研究者提出了利用初始梯度信号评估架构性能的方法。例如,SNIP和GraSP等指标源自网络剪枝策略,计算网络在随机初始化时某些权重对损失的梯度敏感度,以估计架构的重要性。A Deeper Look at Zero-Cost Proxies for Lightweight NAS
(3)初始梯度信号-梯度的总体大小
再如GradNorm(梯度范数)与Fisher信息等指标,直接度量初始化时网络参数梯度的总体大小,用以预测网络的可训练性或表达能力。这些方法通常只需对未训练网络进行一次前向和后向传播即可得到分数。
(4)其他梯度相关
另一些梯度相关的方法结合理论分析,例如 TE-NAS 利用神经切线核(NTK)矩阵的条件数(衡量网络优化难度)和网络ReLU激活划分的线性区域数(衡量网络表达能力)来打分架构这些梯度驱动的零成本方法无需训练权重,仅通过梯度信号就实现了对架构优劣的初步判别。TENAS
基于代理的方法
基于代理(预测模型)的NAS方法旨在用廉价的代理任务来近似评估架构性能,从而减少完整训练次数。Zero-Cost Proxies for Lightweight NAS
传统做法包括缩短训练(如只训练若干epoch)或缩小数据集进行快速评估,以及训练一个性能预测器来替代真实训练。预测器可以是基于架构特征的回归模型、图神经网络或高斯过程等。EZNAS: Evolving Zero-Cost Proxies For Neural Architecture Scoring
例如,BANANAS等方法通过对少量已训练架构的数据训练神经网络预测器,再利用贝叶斯优化在预测器上选出高性能架构,从而显著降低搜索成本。需要注意的是,训练预测器本身仍需一定开销,因此这类方法并非“零成本”,但相较于每个候选都完整训练,已经大幅节省了计算。近期研究也开始将零成本代理融入预测器方法,例如用一批免训练指标对大量架构打分,生成丰富的训练数据来训练性能预测模型,从而提升预测精度和泛化性。基于代理的方法在NAS中非常实用,因为它们能充分利用已观察的架构性能信息,加速发现优异架构。
启发式方法
启发式方法指根据网络结构的某些先验理论或经验指标来衡量架构优劣。许多零成本指标可归为此类。例如,SynFlow指标来自初始化剪枝方法,它通过构造特殊的输入(如全1张量)来累积网络各参数的“流量”贡献,以数据无关的方式评价架构。
Zen-Score则从网络表达能力出发,衡量随机初始化网络对随机高斯输入的输出变化范围。计算时仅需对未训练网络进行若干随机输入的前向推理,统计输出的多样性即可,因而快速且无需训练数据。
又如NASWOT方法,分析未训练网络对不同输入的激活模式,通过输出的协方差矩阵(等价于Jacobian矩阵的相关性)来估计架构区分不同样本的能力。据报道,好的架构在随机初始化时对不同输入产生更独特的激活模式,而差的架构输出更相似。
这些启发式指标往往有一定理论依据:如NTK谱分析和线性区域数基于深层网络优化与表达理论;又如网络的参数量和FLOPs虽然简单,却可视为性能的粗略启发式,上述研究发现它们在不少情况下是强有力的基线。
在搜索策略上,启发式方法常结合进化算法或随机搜索来使用这些快速评分。比如,研究者可用零成本评分作为适应度函数,快速筛选出高评分架构进行进化。Samsung的研究表明,将零成本评分用于NAS的初始种群筛选或候选生成,能明显加速传统NAS算法收敛。
又如Zen-NAS通过在给定算力预算下最大化Zen-Score来迭代生成架构,实现了无需训练即可找到高性能模型。
总的来说,启发式零成本方法利用经验和直觉指标,实现了在巨大搜索空间中高效地发现优质架构。
其他可能的分类
除上述类别外,还有一些值得讨论的方法。例如,混合方法尝试结合训练型NAS与零成本NAS的优点。Shu等人在NeurIPS 2022提出的HNAS框架,将零成本指标与少量训练评估相结合,在理论上证明了二者互补,可同时获得训练型NAS的高精度和零成本NAS的高效率。HNAS
另一类是一次性NAS(权重共享)方法,如ENAS、GDAS等。虽然严格来说这些方法不属于“免训练”,因为它们需要训练一个超级网络的权重,但相较于传统NAS还是极大降低了成本。值得关注的是,最新观点认为零成本指标可以嵌入到一次性NAS或代理模型方法中,进一步提升后者的性能。
例如,有工作建议在DARTS这类梯度法中引入零成本分数作为正则,引导架构搜索朝更可训练的方向发展。同样地,在基于预测器的NAS中融合零成本特征也被证明可提高预测准确性。
NAS-Bench-Suite-Zero: Accelerating Research on Zero Cost Proxies
此外,根据NAS所处环境的不同,还出现了一些特别的变种:如无监督NAS(UnNAS)在无标签的预训练任务上评估架构以替代有监督训练。
又如硬件感知的零成本NAS,将架构的零成本得分和推理延迟等硬件指标结合进行多目标搜索。这些都属于对零成本NAS范畴的扩展探索。
2. 评估标准
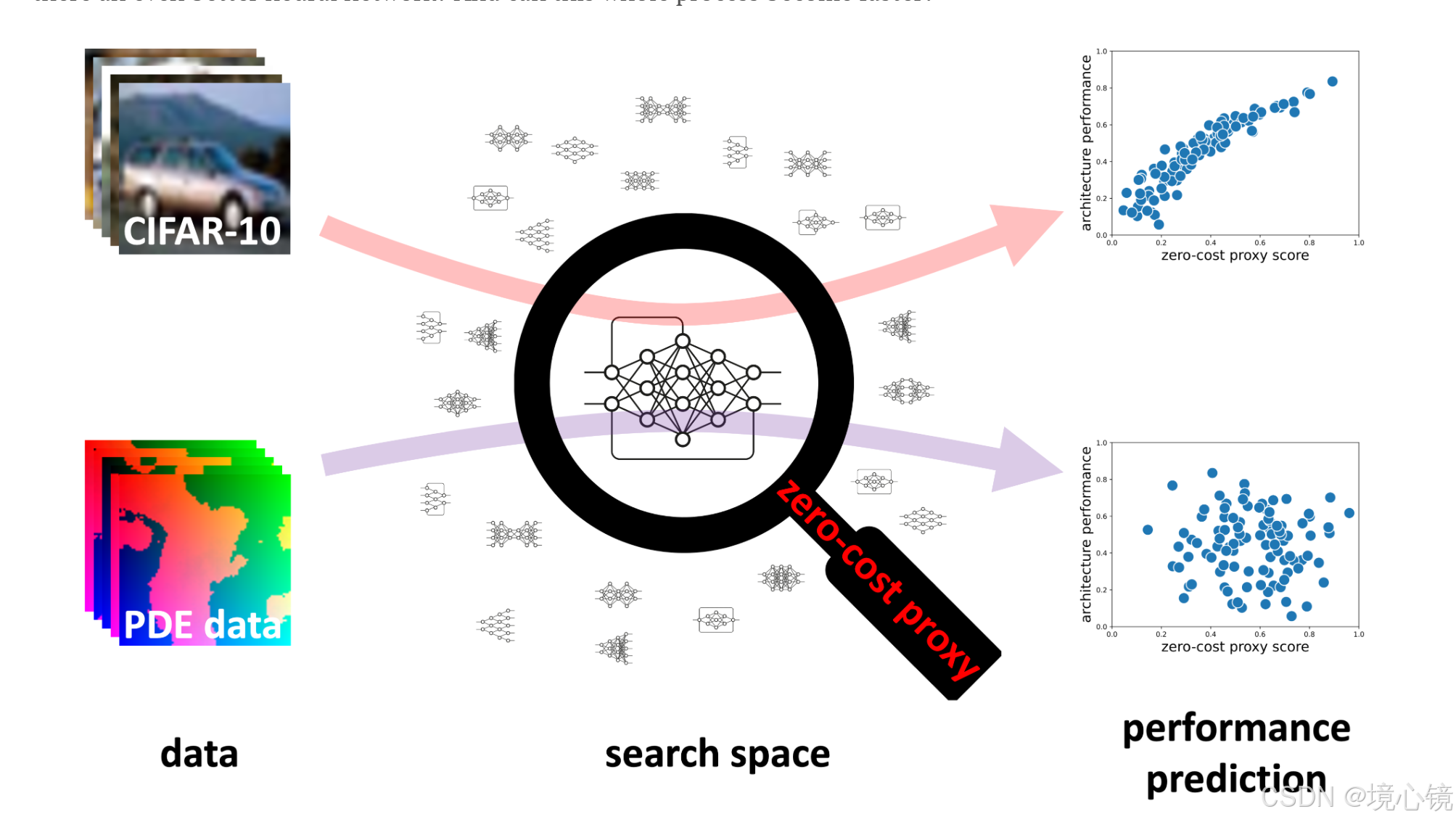
(1)计算效率:免训练NAS的突出优势是计算效率高。大多数零成本评估只需一次小批量数据的前向和后向传播即可得到架构分数。相较于完全训练一个模型(常需数小时至数天),零成本代理通常在几秒内完成单个架构评估。
例如,Abdelfattah等人提出的零成本指标在NAS-Bench-201空间中取得了与部分训练代理相当甚至更高的排名相关性(斯皮尔曼ρ约0.82),但计算量仅为后者的千分之一。实际上,他们的方法使在NAS-Bench-101上达到同等精度的搜索速度提高了4倍。
因此,在大规模架构搜索中引入零成本评估可显著缩短实验周期、降低算力消耗。
(2)性能预测能力:评价零成本NAS方法的重要标准是其性能预测准确度。通常使用排名相关系数(如Spearmanρ)来量化零成本分数与最终准确率之间的一致性。许多零成本指标在标准数据集上表现不俗,例如SynFlow和Jacobian Covariance在CIFAR-10/100上的ρ可超过0.70。Abdelfattah等报告其集成指标“vote”在CIFAR-100上相关系数达0.83
然而,不同指标的预测能力在跨任务时差异很大。一些研究发现,没有哪个单一零成本代理能在所有任务上稳居最佳。甚至简单的参数量或FLOPs等baseline,在某些情境下与最终精度的相关性可以媲美甚至超过复杂零成本指标。例如在NAS-Bench-360更广泛的任务集合上,参数/FLOPs对性能的预测力在很多任务上与高级指标相当。
因此需综合考虑多个指标来提高稳健性。另外,零成本分数主要预测相对排名,其绝对值缺乏直接物理含义,因而通常用于筛选或排序而非精确预测具体精度。
(3)适用性和可扩展性:这涉及零成本NAS方法能否推广到新的任务、架构类型和更大规模的搜索空间。一方面,数据依赖程度影响适用性。像SNIP、GRASP这类需要真实数据计算梯度的指标,在新任务上必须取得一小批数据才能使用;而SynFlow、Zen-Score等数据无关方法可直接在任何架构上计算,但研究显示它们在跨领域时表现可能不稳定。另一方面,架构类型的差异也带来挑战。目前零成本NAS研究主要聚焦于卷积神经网络(CNN)用于图像分类的搜索空间,对循环神经网络、Transformer等架构的效果需要进一步验证。假设网络有特定的激活函数和结构,对于不同架构可能需调整。可扩展性方面,零成本方法在小型搜索空间(如几个OP组成的单元)中验证较多,其在超大规模搜索空间中的效率和判别力也需考察。不过已有成功案例:例如Zen-NAS将零成本方法扩展到ImageNet级别的数据集,在复杂搜索空间中仍然找到了表现领先的架构。又如NAS-Bench-Suite-Zero提供了多达1.5M架构的零成本评分数据,显示这些方法可以应用于大规模评估。
总体而言,零成本NAS在不同领域和规模下的适用性正在被逐步验证,但要做到全面通用仍有难度,需要针对新的任务不断改进和调整方法。
3. 主要研究进展
近期发表的重要论文
免训练NAS是近年兴起的研究热点,涌现出一系列重要工作。Mellor等人在2021年提出了NAS Without Training(NASWOT),首次证明仅凭未训练网络对输入的激活模式差异就能预测架构性能,实现在数秒内评估架构。
Mohamed Abdelfattah等人在ICLR 2021的论文*“Zero-Cost Proxies for Lightweight NAS”*中系统整合了多种零成本指标,包括SNIP、GraSP、SynFlow、GradNorm等,发现综合投票的指标在NAS-Bench-201上与最终准确率的相关性高达0.82。他们还展示了将零成本评分用于强化学习、进化算法等NAS策略中,可明显提升搜索效率。
同年,Wuyang Chen等在ICLR 2021提出TE-NAS(Training-free NAS),引入深度理论指标(NTK谱和线性区域数)对架构进行打分,并通过剪枝逐步生成架构,仅用0.5个GPU小时在CIFAR-10上完成高质量搜索
TE-NAS验证了结合网络可训练性和表达能力的指标在大型数据集上的有效性。随后的ICCV 2021上,Lin等人发布了Zen-NAS,提出Zen-Score指标并在无需训练的情况下设计出ImageNet上的SOTA架构。这是首个在ImageNet尺度上取得零训练NAS成功的工作,证明了零成本方法在大规模任务中的潜力。
2022年,Shu等人在NeurIPS提出HNAS框架,从理论上统一了多种梯度型零成本指标,解释了它们与泛化性能的关系,并提出结合零成本和少量训练评估的混合NAS策略。他们的实验显示,该混合方法在多个搜索空间上相比纯零成本或纯训练NAS都有提升。
最近,Akhauri等人在NeurIPS 2022提出EZNAS(Evolving Zero-Cost NAS),利用遗传编程自动发现新的零成本代理函数。EZNAS在NAS-Bench-201和Facebook NDS等基准的所有子数据集上均达到了当前最优的评分-精度相关性,这一研究证明了自动化设计零成本指标的可行性,减少了人工试错,所发现的指标在不同架构空间上具有更佳的泛化性。
此外,一些工作关注特殊领域的免训练NAS,如针对Transformer网络的训练自由架构搜索、用于逻辑回归任务的零成本指标等,都丰富了该领域的成果。Training-Free Transformer Architecture Search With Zero-Cost Proxy Guided Evolution
现有的开源工具和框架
为了支持免训练NAS研究,社区发布了多种开源资源和工具。NAS-Bench系列基准提供了评估NAS算法的便利:NAS-Bench-101、201涵盖数千到数万种架构及其训练准确率,方便验证零成本指标的预测能力;更丰富的NATS-Bench扩展到多个数据集和搜索空间。近期的NAS-Bench-360和TransNAS-Bench-101引入了非传统任务(如信号分类、PDE求解等),被用于考察零成本方法在新领域的表现。
在NeurIPS 2022的Datasets Track中,F. Hutter团队发布了NAS-Bench-Suite-Zero——一个专门针对零成本NAS的基准套件。该套件预先计算了13种零成本代理在28个任务上的评分,形成了迄今最大规模的零成本NAS数据集(涵盖约1.5M次评估)。研究者可以通过NAS-Bench-Suite-Zero快速获取不同指标的表现、偏差和互补性分析结果。这一统一基准有助于公平比较新提出的指标,加速研究迭代。
在代码工具方面,许多零成本NAS方法都有开源实现。Samsung研究团队开源了ICLR 2021论文的代码仓库“Zero-Cost-NAS”,提供了SNIP、GraSP、SynFlow等指标的计算函数及将它们嵌入NAS算法的示例。Joseph Mellor等也开源了NASWOT的实现(BayesWatch/nas-without-training),支持在NAS-Bench-101/201等基准上一键复现他们的搜索实验。
此外,Facebook发布的NNAS(Neural Network Architecture Search)库和AutoML社区的NASLib库也整合了零成本代理。例如,NASLib在一次Zero-Cost NAS竞赛中被用于统一不同参赛者的零成本指标实现,提供了轻量级的接口方便地插入自定义指标。CodaLab - Competition总的来说,丰富的开源工具和数据基准降低了研究门槛,使得研究者能够方便地测试新想法、复现他人成果并进行公平比较,从而推动免训练NAS领域的快速发展。
4. 应用领域
计算机视觉
计算机视觉是零成本NAS最先也是最广泛应用的领域。大量研究聚焦于图像分类任务,利用免训练方法在CIFAR-10、ImageNet等数据集上搜索卷积神经网络架构。结果表明,零成本NAS在这些基准上能找到与耗时NAS相媲美甚至更优的模型。例如前述的Zen-NAS在ImageNet上搜索出的ZenNet架构,精度达到EfficientNet-B5水平但推理速度快一个数量级。
在目标检测领域,近来也开始借鉴零成本NAS思想。典型案例是ZenDet,受Zen-NAS启发针对检测骨干网络设计零成本指标(结合Zen-Score和检测任务先验),无需训练即可高效评估候选架构。ZenDet成功地设计出在COCO上性能优异的检测模型骨干。除了分类和检测,图像分割、视频理解等视觉任务都有望应用免训练NAS来加速模型设计。此外,在视觉领域引入硬件约束也是一大趋势——研究者可以将零成本性能评分与模型推理延迟、能耗等指标共同作为优化目标,快速搜索出既准又快的模型,以满足移动端或嵌入式设备的需求。
ZenDet: Revisiting Efficient Object Detection Backbones from Zero-Shot Neural Architecture Search
自然语言处理
在自然语言处理(NLP)领域,零成本NAS的应用尚处起步阶段。相较于CV任务,现有零成本指标在NLP任务上的效果不尽理想。不少研究发现,将原先针对CNN的零成本代理直接用于RNN或Transformer架构时,排序相关性很低,甚至不如简单的参数量基线。
这可能因为语言模型架构(如Transformer层)的特性与图像模型差异较大,梯度分布和表达方式不同,现有指标未能捕捉关键性能因素。然而,这一局面正在改变。最新工作LPZero提出了首个面向大规模语言模型的零成本NAS框架。他们构建了一个涵盖现有各种零成本算子的符号空间,通过遗传算法自动组合出新的代理公式,以提高在NLP任务上的排名预测效果。LPZero在BERT、GPT-2、LLaMA等模型的架构选择上显著超过了人工设计的指标,表现出更高的排序一致性。这表明通过针对NLP任务定制或搜索代理指标,可以克服以往方法的不适用性。另外,类似的方法也可用于机器翻译、对话系统等其他子领域架构的高效搜索。例如,为Transformer的编码器和解码器结构设计专门的零成本评分函数,用以快速探索更优的层数、头数配置。随着这方面研究的推进,免训练NAS有望在NLP领域发挥更大作用,为大模型架构优化提供新的工具。
LPZero: Language Model Zero-cost Proxy Search from Zero
其他应用场景
除视觉和语言外,免训练NAS的理念也开始向其他AI领域延伸。在语音处理方面,一些工作尝试将零成本指标用于自动语音识别模型的搜索。例如针对语音卷积或流式Transformer结构,利用初始化时的梯度信号判断模型对语音特征的适应性,以筛选架构原型。又如在强化学习和控制领域,研究者关注能否快速搜寻决策网络结构。由于强化学习一次完整训练耗时更长,零成本评估更具吸引力。一些探索性研究以随机初始化智能体网络在虚拟环境中的初始表现(如随机策略下的状态分布或价值网络的梯度)作为代理,来预选网络结构。初步结果表明某些指标对最终策略的学习效率有相关性。再比如AutoML元学习领域,也出现了利用零成本NAS加速元架构搜索的想法。此外,在神经形态计算中,有工作将免训练NAS用于脉冲神经网络(SNN)的设计,SNN具有非典型的激活动态,但通过定制如“脉冲发放率”一类的零成本指标,也能有效区分网络结构对信息表示的能力。Neural Architecture Search for Spiking Neural Networks
这些探索说明免训练架构搜索具有一定的普适性:只要能提炼出反映目标任务难度的初始信号,就可能用于指导架构选择。当然,不同领域的问题特性各异,需要发明相应的代理指标。总体而言,免训练NAS正在从CV/NLP逐步扩展到更广泛的AI应用,为各领域的神经网络设计提供新思路。
5. 未来趋势和挑战
当前主要挑战
尽管免训练NAS展现了巨大的潜力,但仍有若干亟待解决的问题。
(1)首先是指标的一致性和泛化性不足。正如上述研究所发现的,不同零成本指标在各任务上的表现千差万别,没有哪个指标能够在所有情况下胜出。例如SynFlow在图像分类任务相关性较高,但在某些信号处理任务上表现反常,相关性甚至为负。这种不稳定性限制了零成本NAS在新任务上的直接应用。
(2)其次,许多指标存在偏差问题。NAS-Bench-Suite-Zero的分析指出,不少零成本指标对架构某些属性存偏好,例如倾向于选择更多卷积层或跳跃连接的网络。简单的参数量/FLOPs等也各有偏向。这些偏差可能导致搜索到的架构并非全局最优。如何校正或消除指标偏差,提取真正与泛化性能相关的信号,是一大挑战。
(3)第三,在新兴领域的适用性有待提高。目前零成本NAS对Transformer等架构的刻画还不充分,在大型语言模型等任务上大多失效。这说明我们对不同架构/任务下影响网络性能的初始因素认识不够,现有指标缺乏任务特异性。
(4)最后,从理论上讲,对于零成本代理为何有效(或无效)的深层机理理解不足。目前的指标多基于经验直觉和少量试验堆叠,缺乏统一的理论指导。这导致开发新指标主要靠试错,难以预见其适用范围和局限。
未来发展方向
针对上述挑战,未来研究可能沿以下方向推进:
(1)融合多种方法将是趋势。零成本NAS不一定与现有NAS范式对立,相反可以优势互补。一个方向是将零成本指标融入一次性/梯度NAS,例如在DARTS训练过程中以零成本分数引导架构更新,从而避免陷入次优解。与基于代理的NAS结合,比如用零成本分数大量标注架构以训练精度预测器,或者在贝叶斯优化中作为部分信息源。这类融合有望兼具零成本的效率和训练法的准确性
(2)组合指标提升稳健性是重要课题。正如NAS-Bench-Suite-Zero的互补性分析所示,不同零成本代理往往提供互补的信息。未来可探索自动学习指标权重的方案,将多个弱预测器集成成更强的预测器。例如,Abdelfattah等的“vote”策略是简单投票融合,后续工作可考虑训练一个小型MLP来组合多个零成本特征,从而提高在不同任务上的鲁棒性。有研究已证明,结合所有13种已知零成本特征训练预测模型,可将性能预测的准确度提高多达42%。
(3)自动化发现更优指标将成为趋势。与其人工设计,不如让算法来搜索最佳代理公式。EZNAS和近期的LPZero已经展现了遗传编程、符号回归在这一问题上的威力。未来或可引入强化学习、神经架构搜索本身来设计代理(即“用NAS做NAS的代理”),寻找更复杂但泛化更好的零成本度量。通过大规模演化,有望发现人类难以直观想到的组合特征。
(4)扩展应用边界仍然很重要。随着更多领域尝试免训练NAS,我们需要针对不同任务开发定制化的代理指标,并验证这些方法在工业级应用中的效果。例如,在自动驾驶感知、多模态学习等复杂场景下,评估网络的难度可能需要引入新的初始信号(如多任务平衡能力的度量)。硬件高效NAS也是未来方向之一,可以在代理中纳入对能耗、延迟的估计,使得搜索出的架构在实际部署中最优。
(5)最后,从长远看,需要加强对零成本NAS的理论理解。这包括深究梯度信号与泛化误差的定量关系、随机初始化网络性能的分布性质等基础问题。有了理论指导,我们才能有的放矢地创造新方法。
总之,免训练神经网络架构搜索作为NAS领域的前沿方向,虽然当前存在诸多挑战,但其高效性和潜在通用性使其前景广阔。正如最新综述所指出的,零成本NAS目前的问题是不稳定但它提供了一个新颖而有前途的思路,未来必将成为NAS技术演进的重要组成部分。随着研究的深入,我们有望见证免训练NAS在更多任务上取得突破,并与其他NAS方法融合,推动神经网络设计进入更高效智能的时代。
心迹录
袁了凡先生云∶聚精之道,一曰寡欲,二曰节劳,三曰息怒,四曰戒酒,五曰慎味。
所有想要的东西,买买买,过欲伤精,尤其是先天之精
太过劳累,五劳,久视伤血,久坐伤肉,久卧伤气,久行伤筋,久立伤骨
怒,大怒是大火烧干血,熬夜是小火耗精,先天之精
慎味,清淡促进五脏平衡



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









