






 摘要:
摘要:
近年来,零次(或无需训练)神经结构搜索(NAS)方法被提出,以从昂贵的训练过程中解放 NAS。零次 NAS 的核心思想是设计一个代理(proxy),无需训练网络参数即可预测给定网络的准确率。到目前为止,已经提出的这些代理通常受益于对深度学习理论理解的最新进展,并在若干数据集和 NAS 基准上展现了巨大潜力。本文旨在全面回顾并比较当前最先进的(SOTA)零次 NAS 方法,并着重探讨它们对硬件的关注度。为此,我们首先回顾主流的零次代理并讨论它们的理论基础。然后,我们通过大规模实验比较这些零次代理,并展示它们在硬件相关和硬件无关的 NAS 场景中的有效性。最后,我们指出若干有前景的思路来设计更好的代理。
关键词
神经结构搜索、零次代理、硬件感知神经网络设计
I.INTRODUCTION
NAS 的本质是:在一组候选结构(搜索空间)内,结合一定的计算预算,解决一个具有特定目标(例如高分类准确率)的优化问题。NAS 的最新突破使得手动设计网络的反复试错过程得以简化,并能发现比人工设计更高效、更优性能的新型深度网络结构 [10]-[28]。
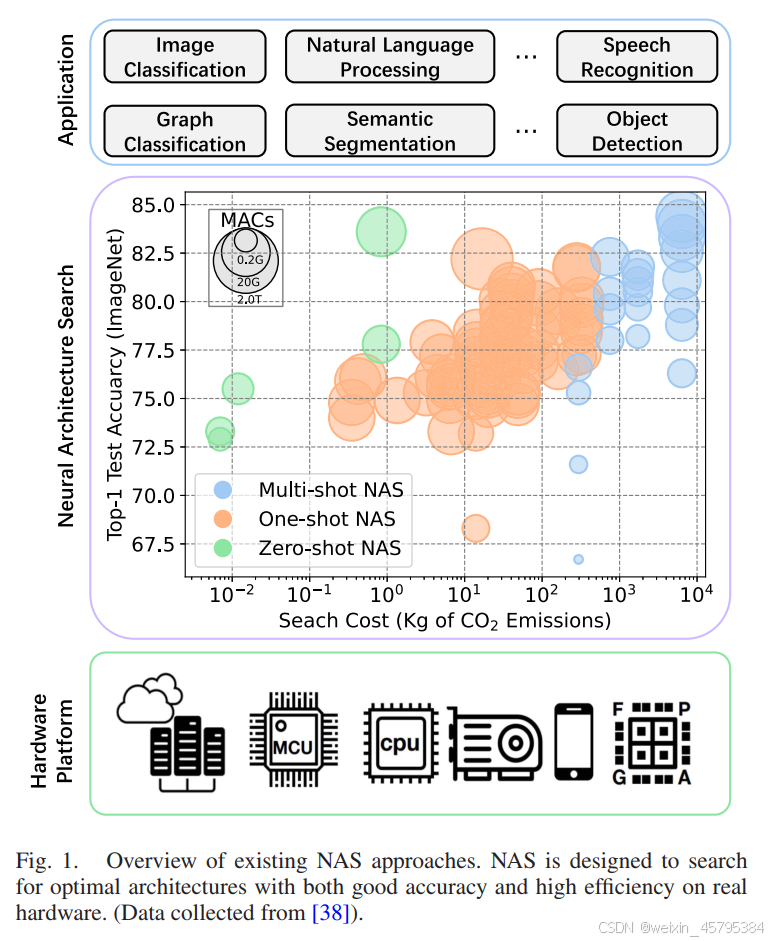
NAS 的一个重要应用是根据各种约束(如内存占用、推理延迟和功耗)来设计硬件高效的深度模型 [29]。现有 NAS 方法大致可分为三类,如图 1 所示:多次搜索(multi-shot NAS)、一次搜索(one-shot NAS)以及零次搜索(zero-shot NAS)。
-
多次搜索 NAS: 在多次搜索 NAS 中,需要分别训练多个候选网络。每个候选网络都要从头开始训练,得到其准确率或其他指标后,再进行对比和筛选。因此时间开销巨大,可能需要从数百 GPU 小时 [30] 到数千 GPU 小时 [31]。
-
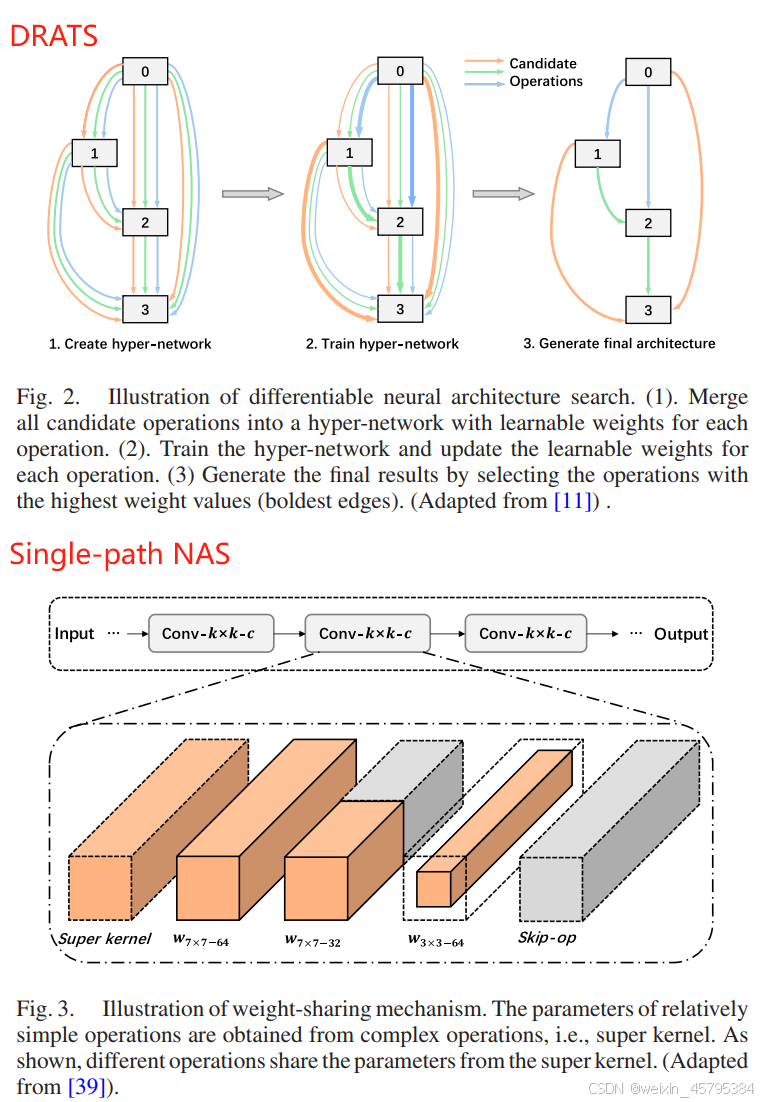
一次搜索 NAS: 在某个层/阶段,所有可能的操作(如 3×3 卷积、5×5 卷积、1×1 卷积等)都放在一个超网络里,并为它们分配不同的“权重分支”。一次搜索 NAS 只需训练一个超网络如图 2 所示,而非指数级数量的候选结构。然而,将所有候选操作合并到一起,导致超网络参数量庞大。为此,权重共享(weight-sharing)方法进一步提升了 NAS 的搜索效率 [13],[39]-[42]。如图 3 所示,权重共享方法进一步复用了不同操作之间的参数,以此降低模型规模和训练开销。权重共享 NAS 的核心思想是在不同操作之间共享参数(将相似或相同功能的操作(如不同尺寸的卷积核)用一套通用的参数来表示。例如,一个 5×5 的卷积核可以包含 3×3、1×1 等更小卷积核的权重)。在每个训练步骤中,从超网络(含共享权重)中随机采样一个子网络,进行前向与反向传播后,更新的梯度再回写到超网络的共享参数中。通过在各种子网络之间共享参数,这种可微分搜索大幅将搜索成本降低到数个或数十个 GPU 小时 [39]。
-
零次搜索 NAS: 零次 NAS 使用某种代理(proxy)来近似模型的测试准确率,从而在搜索阶段完全省去了模型训练过程。零次 NAS 的性能最终取决于精度代理的质量。零次 NAS 的代理设计通常基于对深度网络的某些理论分析,因此有助于加深对“为什么某些网络表现更好”的理论理解。
基于以上宏观观察,本文旨在对现有的硬件感知零次 NAS 方法进行综合分析。本文的主要贡献包括:
-
我们回顾了现有的零次 NAS 代理,并提供了这些代理背后的理论洞察。我们将现有的精度代理分为 (i) 基于梯度的代理 和 (ii) 无梯度的代理。
-
我们将各种零次代理与两个简单的代理(即 #Params 和 #FLOPs)进行了直接对比,揭示了一个基本局限:在受约束的搜索设置(即只考虑高精度网络)时,这些代理与测试精度的相关性通常比在无约束设置(即考虑搜索空间中的所有结构)时要差得多。
-
我们还对零次 NAS 在代理设计、基准选择和真实硬件分析等方面进行了全面研究。结果表明,对于一些高性能架构(如 ResNet 和 MobileNet),某些代理比 #Params 和 #FLOPs 与测试精度有更好的相关性。
-
首次在大规模任务(如 ImageNet-1K 分类、COCO 目标检测和 ADE20K 语义分割)上对这些零次代理进行全面比较的工作。我们也是首个探索这些零次代理在视觉Transformer上的潜在适用性的研究。同时,我们首次详细对比了在硬件感知场景下应用零次 NAS 的情况,这对于将零次方法应用于实际(尤其是边缘AI)场景至关重要。
II. ZERO-SHOT PROXIES
简而言之,一个好的零次代理应能揭示网络学习复杂表示、对未见样本泛化以及在训练中快速收敛的能力。因此,一个理想的精度代理应当关注以下三个主要方面 [65], [66]:
-
表示能力(Expressive Capacity):
代理应当反映深度网络对复杂模式和数据关系的捕捉与建模能力,这对处理大型数据集(如 ImageNet-1K、COCO)等复杂任务十分关键 [67], [68]。 -
泛化能力(Generalization Capacity):
代理还应当反映网络从训练数据泛化到未见数据或分布外数据的能力。一个高泛化能力的网络不仅能在训练数据上表现良好,而且能在新样本上也取得好成绩,这说明它学习到了有意义、可迁移的特征表征 [69]-[71]。 -
可训练性与收敛性(Trainability and Convergence):
代理还应当指示网络能多快收敛到理想的性能水平。更快的收敛意味着网络能更有效地适应手头的训练数据和任务,对实际应用而言至关重要,因为训练往往代价高昂 [72]-[74]。
如表 II 所示,现有大多数代理往往只关注上述三个方面中的一个。这种狭隘关注导致它们的表现常常无法超越一些简单代理(如 #Params 或 #FLOPs)。我们在第四节通过实验证明这一点。
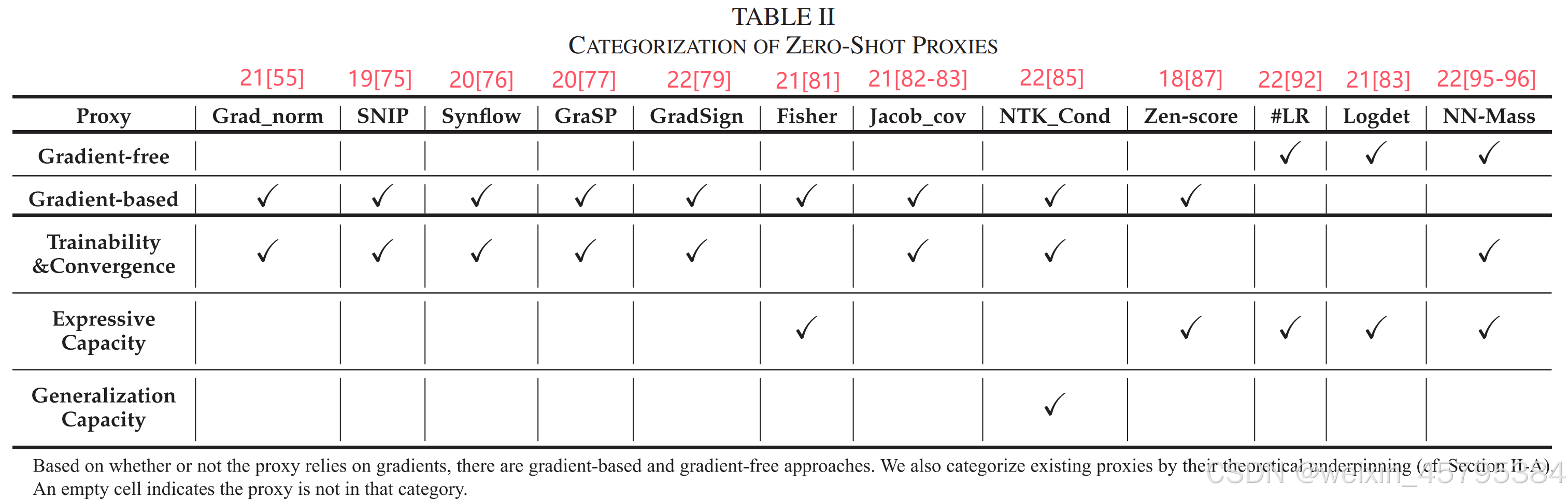
在本文中,我们根据是否需要用到梯度计算,将现有零次代理分为两大类:(i) 基于梯度的精度代理 和 (ii) 无梯度的精度代理(见表 II 总结)。
-
基于梯度的代理(Gradient-Based Proxies)
- 代表方法:Gradient Norm、SNIP、Synflow、GraSP、GradSign、Fisher Information、Jacob_cov、Zen-score、NTK_Cond 等。
- 主要特点:大多侧重衡量网络的可训练性或表示能力,需要进行一次反向传播来获得梯度信息。
- 不足:由于要计算梯度,效率不如无梯度方法;大多只关注网络的某个单一方面(如可训练性或表示能力),难以兼顾泛化能力。
-
无梯度的代理(Gradient-Free Proxies)
- 代表方法:Number of Linear Regions、Logdet、Topology Inspired Proxies(NN-Mass、NN-Degree 等)。
- 主要特点:无需梯度计算,直接从网络的拓扑结构或线性区域数等方面推断网络的表示能力或可训练性。
- 不足:大多数方法只能衡量网络的表达能力或可训练性,对网络的泛化能力缺乏刻画。
对于上述三种代理(Synflow、SNIP、GraSP),已有多项理论分析。例如,在线性网络中,Synflow 和 SNIP 被证明在反向传播过程中是分层常量 [75],[76];此外,一些研究表明 Synflow 和 GraSP 是深度网络一阶泰勒展开的不同近似形式 [77],[78]。泰勒展开可识别对损失值贡献最大的参数,因此能衡量参数重要性。
如表 II 所示,现有的大多数零次代理都是基于梯度的,需要进行一次反向传播才能计算梯度,因此其效率低于无梯度的代理。此外,除 Fisher 和 Logdet 外,大多数基于梯度的代理主要度量深度网络的可训练性;而除了 NN-Mass 之外,大多数无梯度代理主要反映网络的表示能力。此外,除 NTK_Cond 之外,当前的代理几乎都无法定量衡量网络的泛化能力。未来的代理设计应针对这一不足加以改进。
更重要的是,如前所述,现有绝大部分零次代理(除 NTK_Cond 和 NN-Mass 外)只关注 {表示能力、泛化能力、可训练性} 三大维度中的单一方面。这是一个根本性缺陷,因为一个好的神经网络需要同时兼顾这三方面。我们在第四节将提供实验证据来说明这一问题。
III. BENCHMARKS AND PROFILING MODELS
我们在以下标准 NAS 基准上评估零次代理:
-
标准 NAS 基准:
- 包括 NASBench-101、NATS-Bench、TransNAS-Bench-101 等,这些基准定义了不同数据集和任务下的网络架构和性能,为零次代理提供了评估平台。
- NATS-Bench 包含多个子搜索空间,适用于不同深度和宽度的网络架构。TransNAS-Bench-101 涉及七个视觉任务,且提供两类搜索空间,适用于多种不同的应用。
-
硬件感知 NAS 基准:
- 如 HW-NAS-Bench 和 Eagle,这些基准将硬件性能(如延迟和能耗)纳入 NAS 搜索过程,针对云服务器到边缘设备的广泛硬件平台提供数据支持。
- Eagle 还包括一种性能估算器,用于预测网络在不同硬件上的表现。
-
硬件性能建模方法:
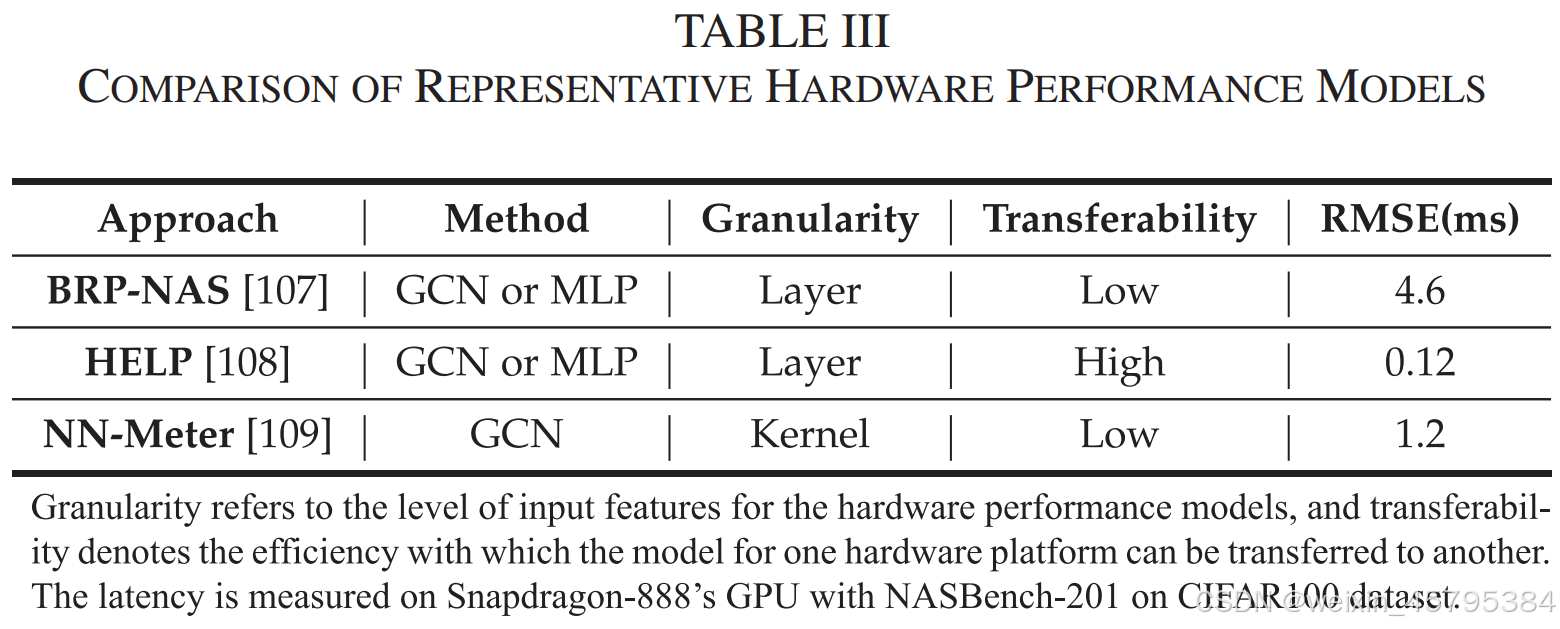
- BRP-NAS、HELP 和 NN-Meter 是三种主要的硬件性能建模方法,分别利用图卷积网络、硬件信息输入以及运行时内核计算来提高性能预测的准确性。
- BRP-NAS 通过深度学习模型来预测硬件性能,但它需要为每种硬件平台重新训练;HELP 则通过少量样本进行迁移学习,适应新硬件;而 NN-Meter 提供了更高精度的预测,通过细粒度分析和内核预测提高了硬件性能的估算质量。
-
方法(Method):使用的模型方法,分别为图卷积网络(GCN)或多层感知机(MLP)。
-
粒度(Granularity):指的是输入特征的层次或细节级别:
- BRP-NAS 和 HELP:采用层级粒度(Layer),即基于神经网络的每一层特征来进行建模。
- NN-Meter:采用内核粒度(Kernel),即通过细化网络的内核操作来进行建模。
-
可迁移性(Transferability):表示该硬件性能模型在不同硬件平台之间的适应能力:
- BRP-NAS 和 NN-Meter:可迁移性较低,意味着这些模型训练时为某特定硬件平台设计,需要重新训练以适应新硬件。
- HELP:具有较高的可迁移性,能够适应多种硬件平台,仅需少量样本就可以调整并迁移。
-
均方根误差(RMSE,ms):该数值衡量了预测延迟与实际延迟之间的差异,数值越小,模型的预测精度越高。
- BRP-NAS:RMSE 为 4.6 毫秒,表示其预测精度较低。
- HELP:RMSE 为 0.12 毫秒,精度非常高,意味着它能够非常准确地预测硬件性能。
- NN-Meter:RMSE 为 1.2 毫秒,预测精度介于 BRP-NAS 和 HELP 之间。
IV. EXPERIMENTAL RESULTS
A. 无硬件感知的 NAS
为了比较这些提出的精度代理的性能,我们计算了这些代理值与真实测试精度之间的相关性。接下来,我们讨论在两个 NAS 基准上的结果:NASBench-201 和 NATS-Bench。
无约束搜索空间:
我们首先调查零次代理在无约束搜索空间中的表现,即考虑基准中的所有网络。
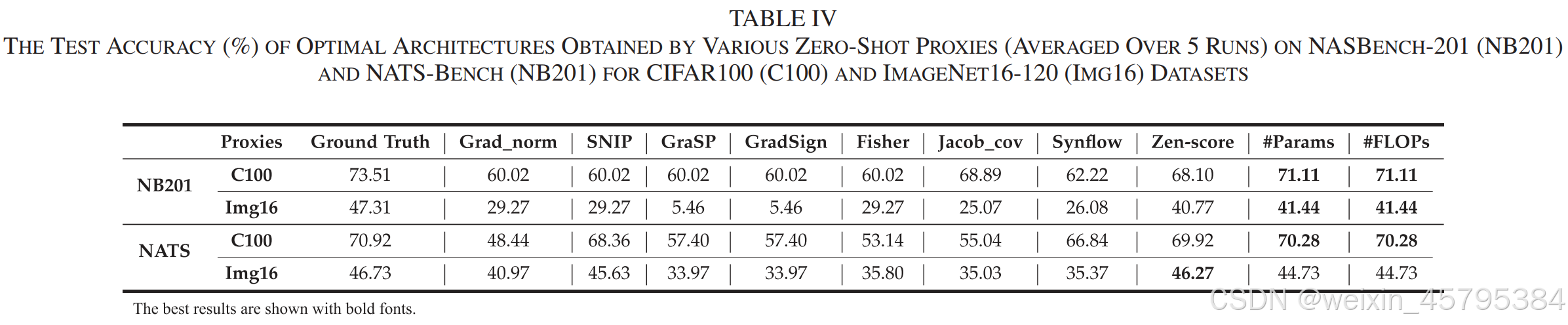
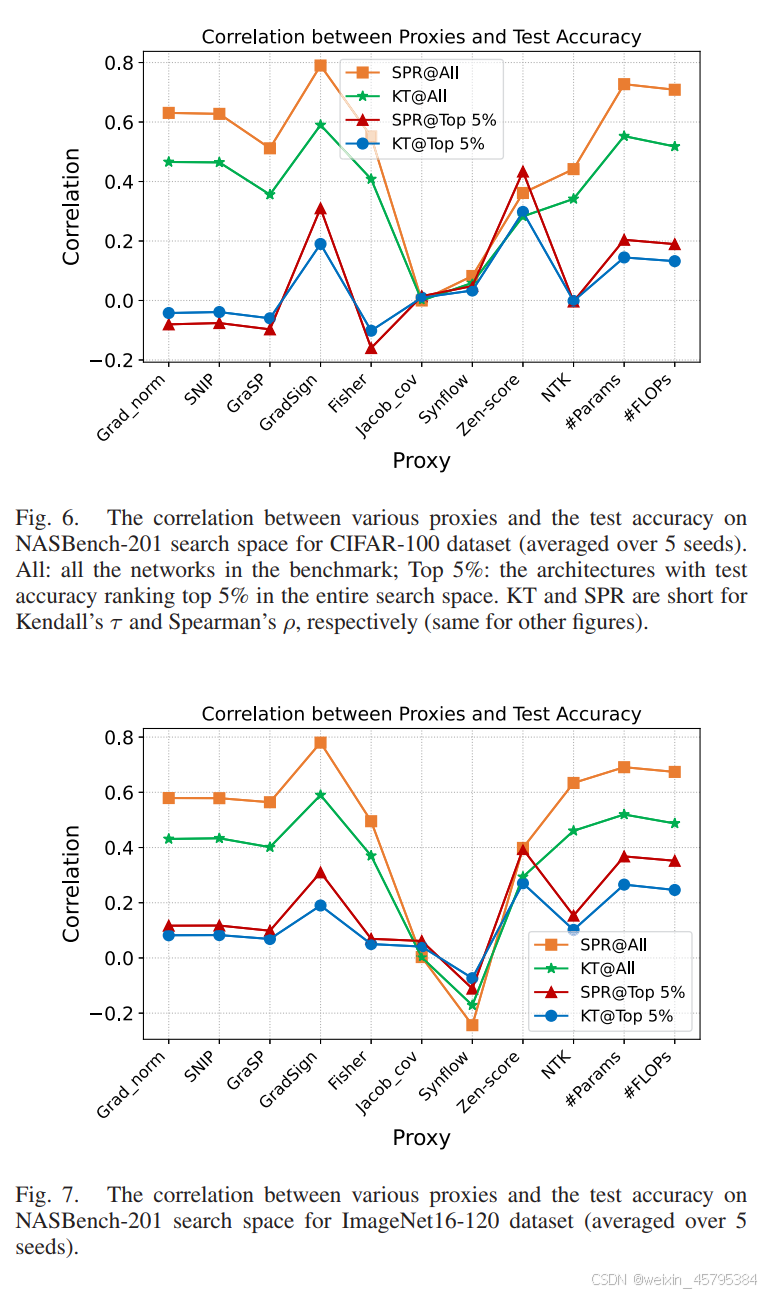
NASBench-201:我们计算了多个代理与 CIFAR-100 和 ImageNet16-120 数据集上的测试精度之间的相关系数。如图 6 和图 7 所示,#Params 通常在这两个数据集上表现最好。除了 #Params 之外,几个基于梯度的代理,如 Grad_norm、SNIP、GraSP 和 Fisher,也表现良好。如表 IV 所示,我们比较了通过各种代理找到的测试精度最高的神经架构。通过 #Params 和 #FLOPs 获得的神经架构在 NASBench-201 上具有最高的测试精度,这符合上述的相关性分数。
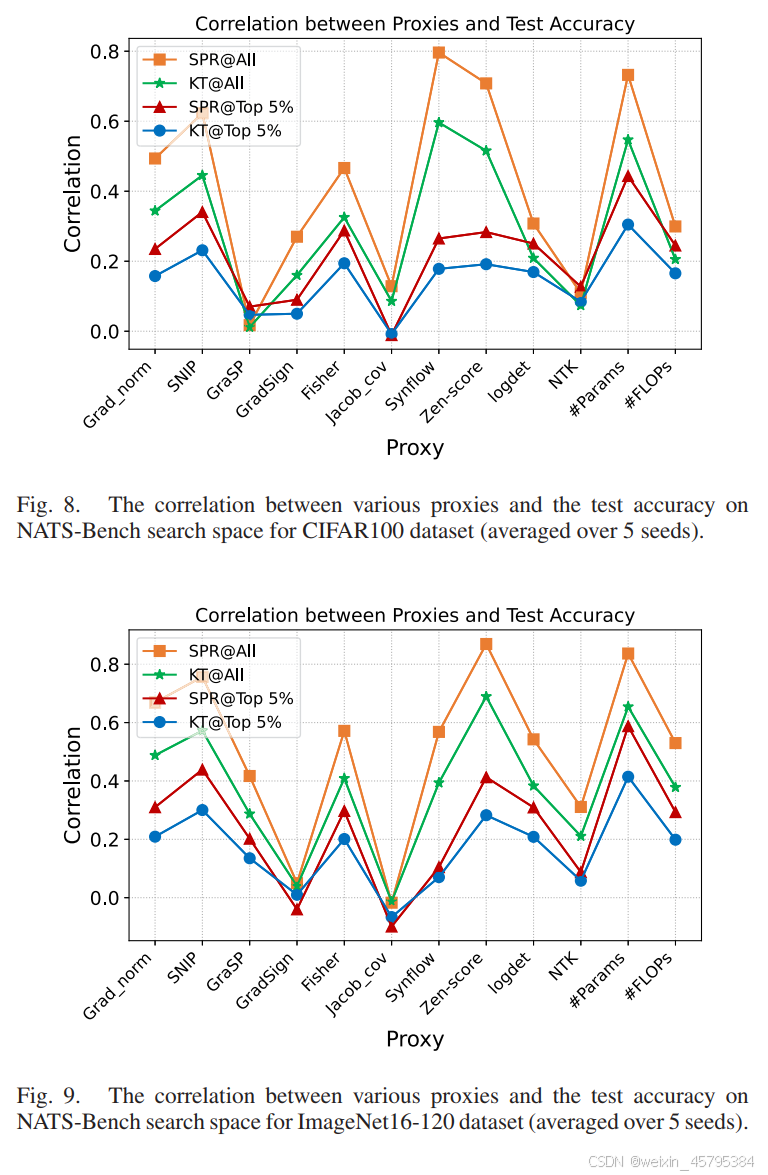
NATS-Bench:与 NASBench-201 类似,我们计算了这些代理与 CIFAR-100 和 ImageNet16-120 数据集上的测试精度之间的相关系数。如图 8 和图 9 所示,#Params 和 Zen-score 通常在这两个数据集上表现最好。
TransNAS-Bench-101:到目前为止,我们主要在分类任务上比较这些零次代理。为了验证这些代理在更广泛应用中的有效性,我们对 TransNAS-Bench-101 中选择的非分类任务进行了比较。我们选择了最大的搜索空间 TransNAS-Bench-101-Micro,该空间包含 4096 个具有不同单元结构的架构。我们在以下三类非分类任务中比较这些代理:
- 语义分割:语义分割涉及将图像中的每个像素分类到预定义的类别或类中。与目标检测(识别物体边界框)或图像分类(对整个图像分配一个标签)不同,语义分割提供了详细的像素级分类。
- 表面法线:类似于语义分割,表面法线是一个像素级预测任务,预测表面法线的统计信息。
- 自编码:自编码是一个端到端的图像重建任务,它将输入图像编码为一个低维表示向量,然后将这个向量重建为原始图像。
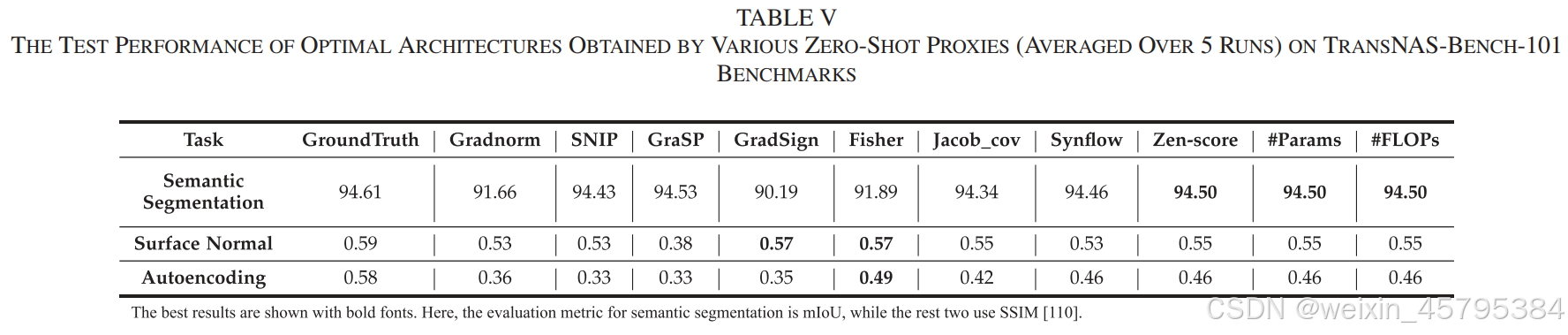
如图 10 所示,Jacob_cov 通常在这两个任务中达到最高的相关性,并始终优于 #Params。除了 Jacob_cov 外,Zen-score 也表现良好,并且始终优于 #Params。
我们还比较了通过各种代理找到的测试精度最高的神经架构。如表 V 所示,通过 #Params 和 #FLOPs 获得的神经架构在 TransNAS-Bench-101 上始终具有最高或第二高的测试性能。
总的来说,现有的精度代理(包括 #Params 和 #FLOPs)没有一个能够在所有两个 NAS 基准上始终保持高相关性。
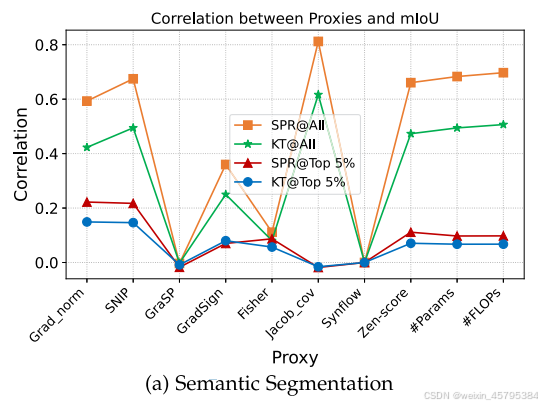
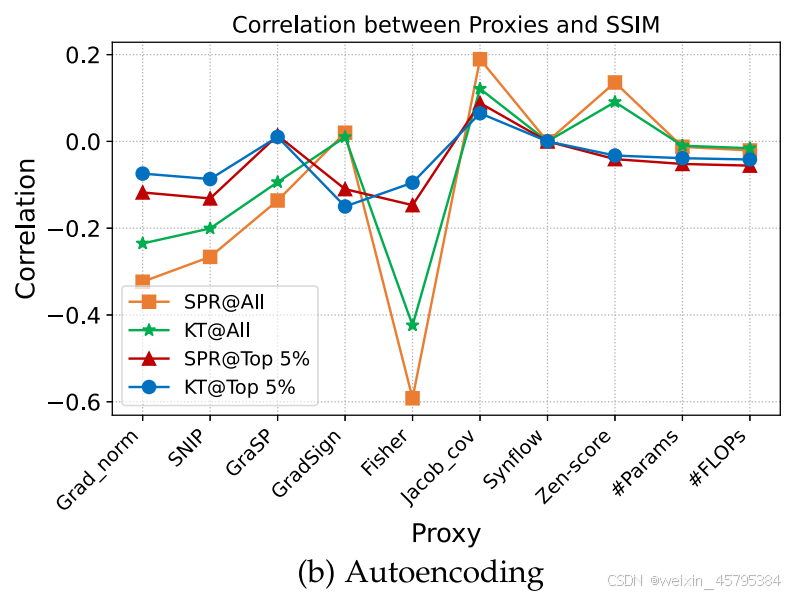
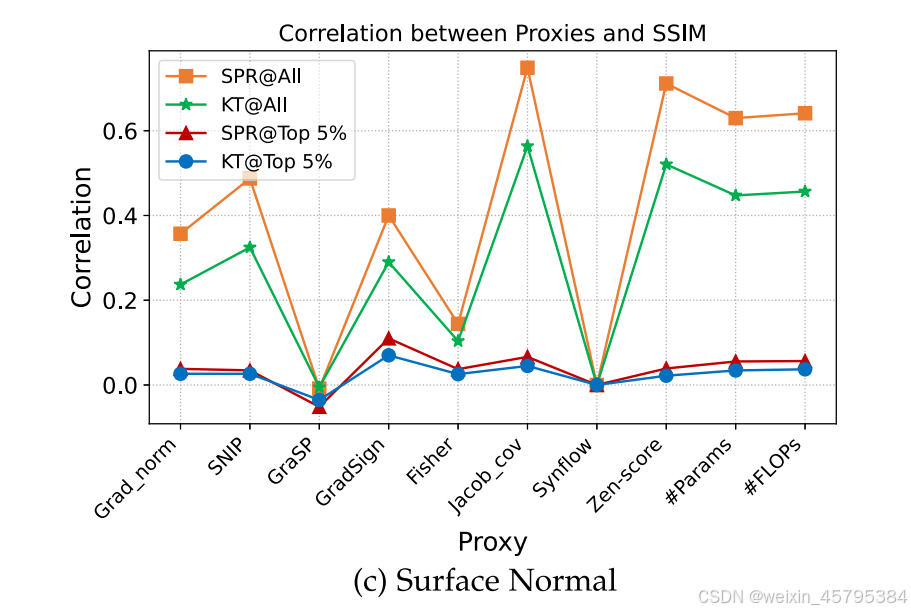
![]()
有约束搜索空间:
我们注意到,高准确度的架构比低测试精度的架构更为重要。因此,我们计算了在整个搜索空间中测试精度排名前 5% 的架构的相关系数。在这些约束场景下,相关性分数显著下降。在前 5% 网络中,相关性分数的下降意味着零次 NAS 更容易错过最优或接近最优的网络。表 IV 显示,每个代理获得的网络与真实值之间存在较大的精度差距。当搜索空间的硬件约束更宽松时,结果变得更差(参见第 IV-D 节)。
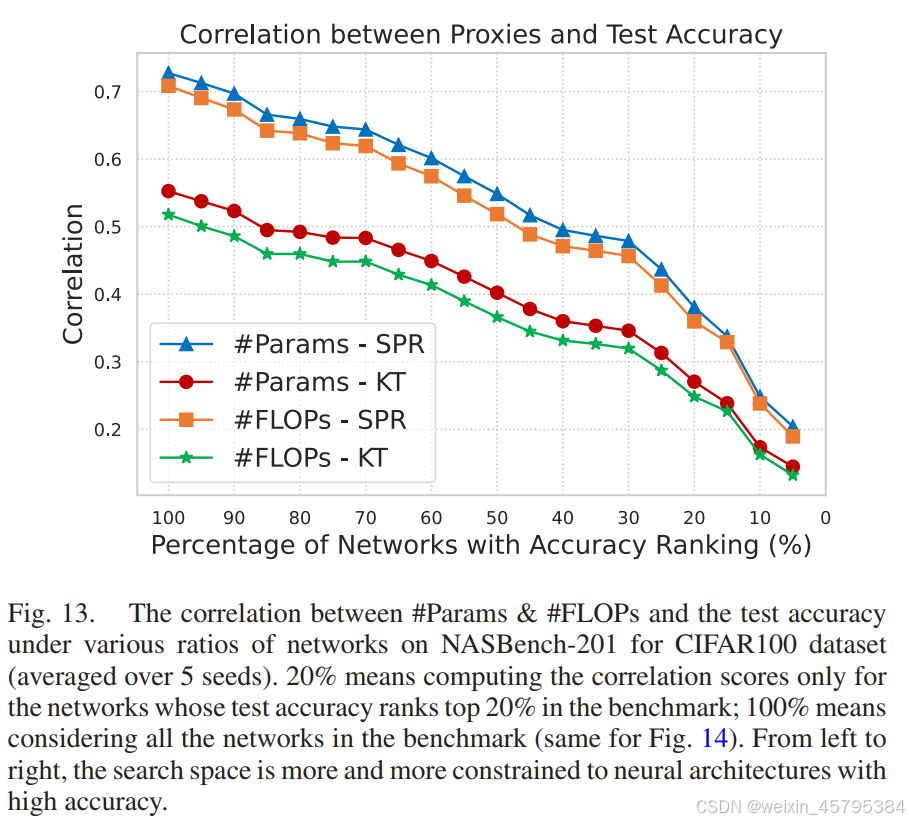
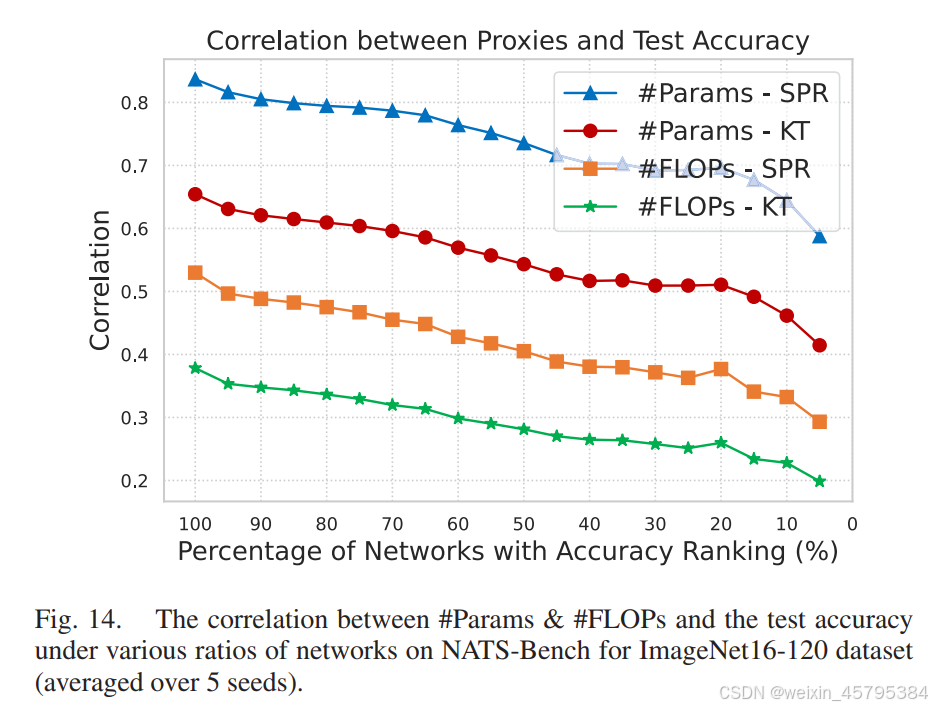
如前文所述,#Params 和 #FLOPs 在多个基准测试中优于其他代理 [63]。因此,我们深入研究了通过逐步限制搜索空间来评估 #Params 和 #FLOPs 的有效性。如图 13 和图 14 所示,如果我们计算更高精度网络的相关性,#Params 和 #FLOPs 的相关性分数显著下降。
基于以上结果,我们得出结论,现有的所有代理(包括 #Params 和 #FLOPs)在高精度网络中的相关性表现都不好。这是一个根本性缺陷,因为 NAS 中最重要的就是这些高精度网络。因此,设计能够对这些高精度网络提供更高相关性的代理具有巨大的潜力。
特定网络家族:
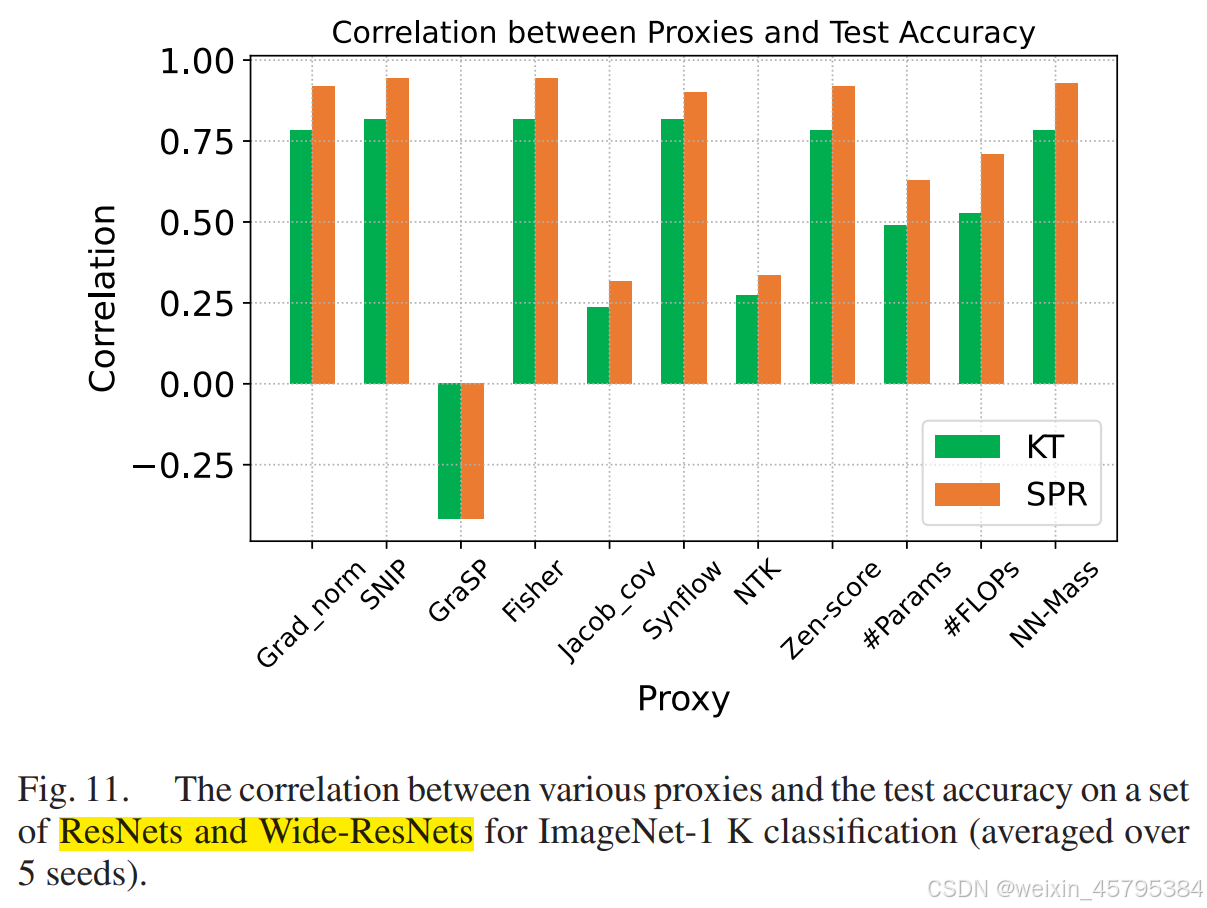
我们提到,许多流行的神经架构未被大多数 NAS 基准测试包含。因此,在这一节中,我们考虑了几种常用的网络家族作为搜索空间,因为它们在各种应用中被广泛使用。如图 11 所示,如果我们在 ResNet 和 Wide-ResNet 网络家族中进行搜索,则 SNIP、Zen-score、#Params、#FLOPs 和 NN-Mass 与测试精度有显著的高相关性(Spearman ρ > 0.9)。
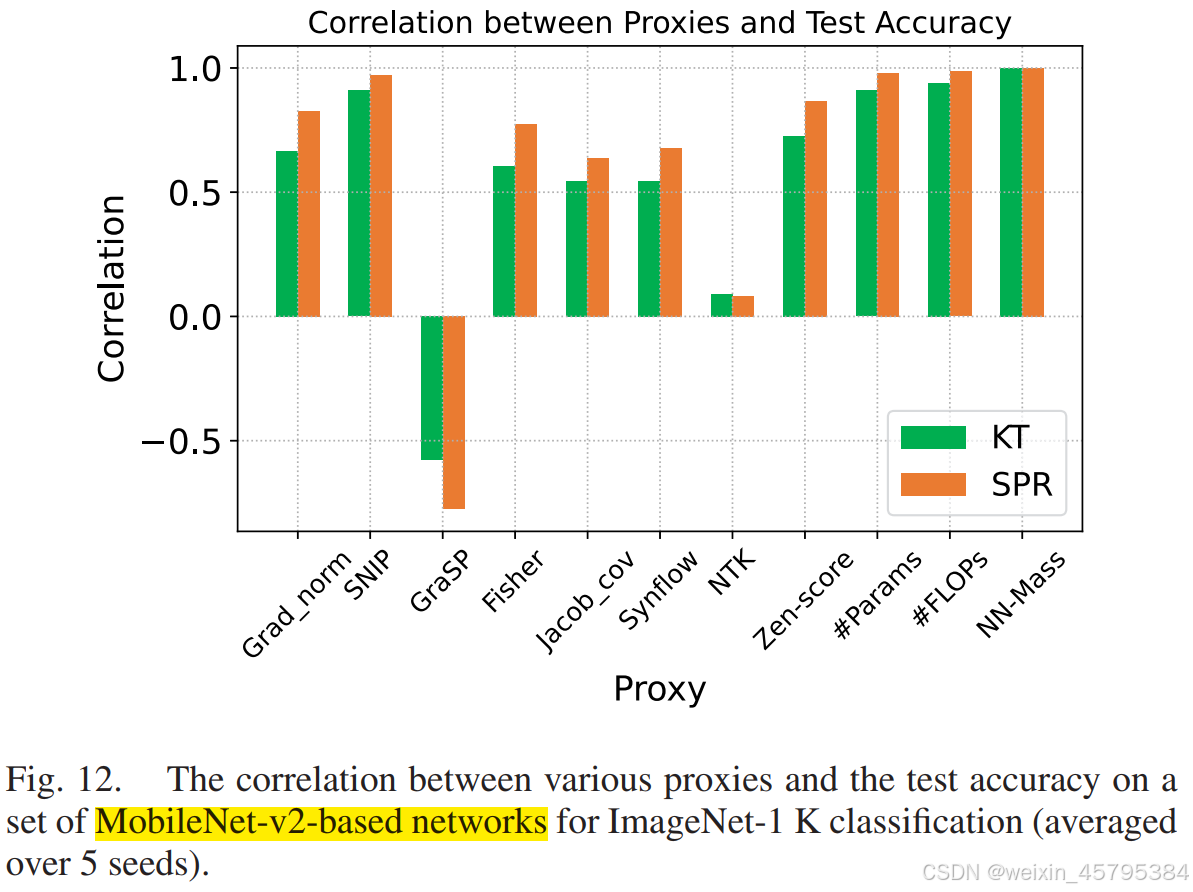
如图 12 所示,Grad_norm、SNIP、Fisher、Synflow、Zen-score 和 NN-Mass 在 MobileNet-v2 网络家族中表现最好,略优于两个简单代理 #Params 和 #FLOPs。这些结果表明,在约束且广泛使用的搜索空间中,设计良好的代理具有巨大的潜力。
B. 大规模数据集
为了进一步比较这些代理在更复杂情境中的表现,我们展示了在 ImageNet-1K 分类、COCO 目标检测和 ADE20K 语义分割任务中的表现。
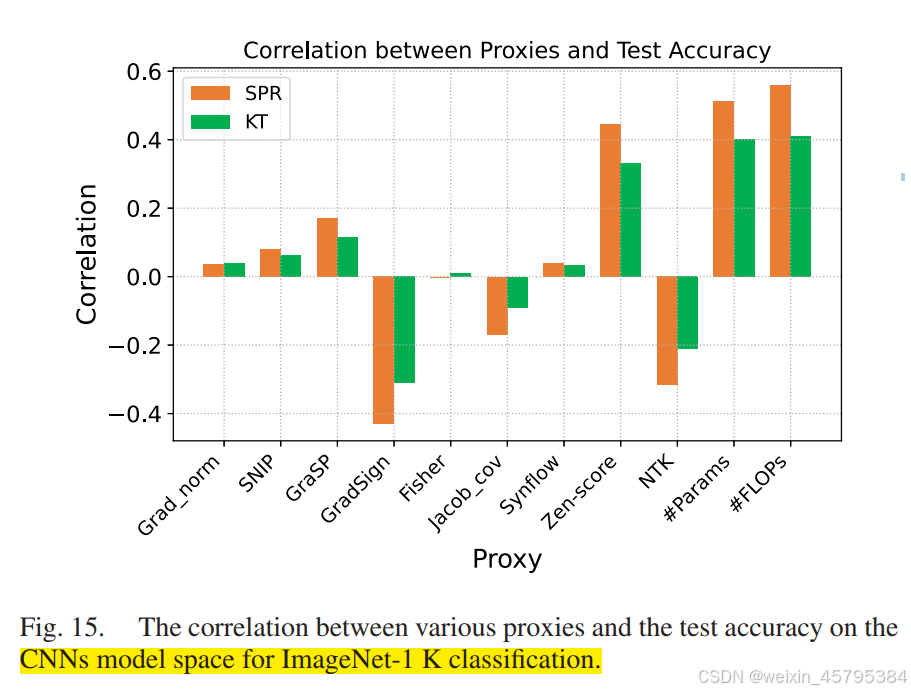
- ImageNet-1K 分类:我们首先计算了 TIMM 模型空间中 CNN 架构的零次代理 [111]。需要注意的是,我们只考虑在 ImageNet-1K 上独立训练的网络,而没有预训练或蒸馏。总共评估了 200 个 CNN,并报告了 Top-1 精度与多个代理之间的相关性,如图 15 所示。结果表明,#Params 和 #FLOPs 的相关性仍然高于这些零次代理。这与我们在 NAS 基准测试中的观察一致。
我们还比较了这些代理基础的 NAS 与在相同搜索空间下的一次搜索 NAS。在 MobileNet-V2 基础的搜索空间中,我们在相同 #FLOPs 配置下(600M)进行了比较。对于代理基础的 NAS,我们使用进化算法搜索具有最高代理值的架构,最多进行 10K 步搜索。对于一次搜索 NAS,我们使用与 [36] 中相同的算法,并在标准数据增强配置下训练获得的架构 150 个 epoch。如表 VI 所示,与一次搜索 NAS 相比,零次代理基础的 NAS 在准确性上略有下降(不到 1%),但搜索成本比一次搜索 NAS 少了几个数量级。
-
COCO 目标检测:我们使用在 ImageNet-1K 上获得的架构作为目标检测模型的骨干网络,并使用 NanoDet [112] 的检测头在 COCO 上训练这些网络 50 个 epoch。表 VI 显示的结果与 ImageNet-1K 上的趋势类似。具体而言,基于 #FLOPs 和 NTK_Cond 的零次 NAS 获得的性能与一次搜索 NAS 相同或非常接近。
-
ADE20K 语义分割:我们计算了在 PyTorch Segmentation [111] 模型空间中的 CNN 架构的零次代理。我们改变了骨干网络和分割头,获得了多个分割网络,然后从头训练这些模型并获得它们的测试表现。我们共评估了 200 个 CNN,并报告了像素准确率(或 mIoU)与各种代理之间的相关性,如图 16 所示。结果表明,#Params 和 #FLOPs 的相关性高于其他零次代理。
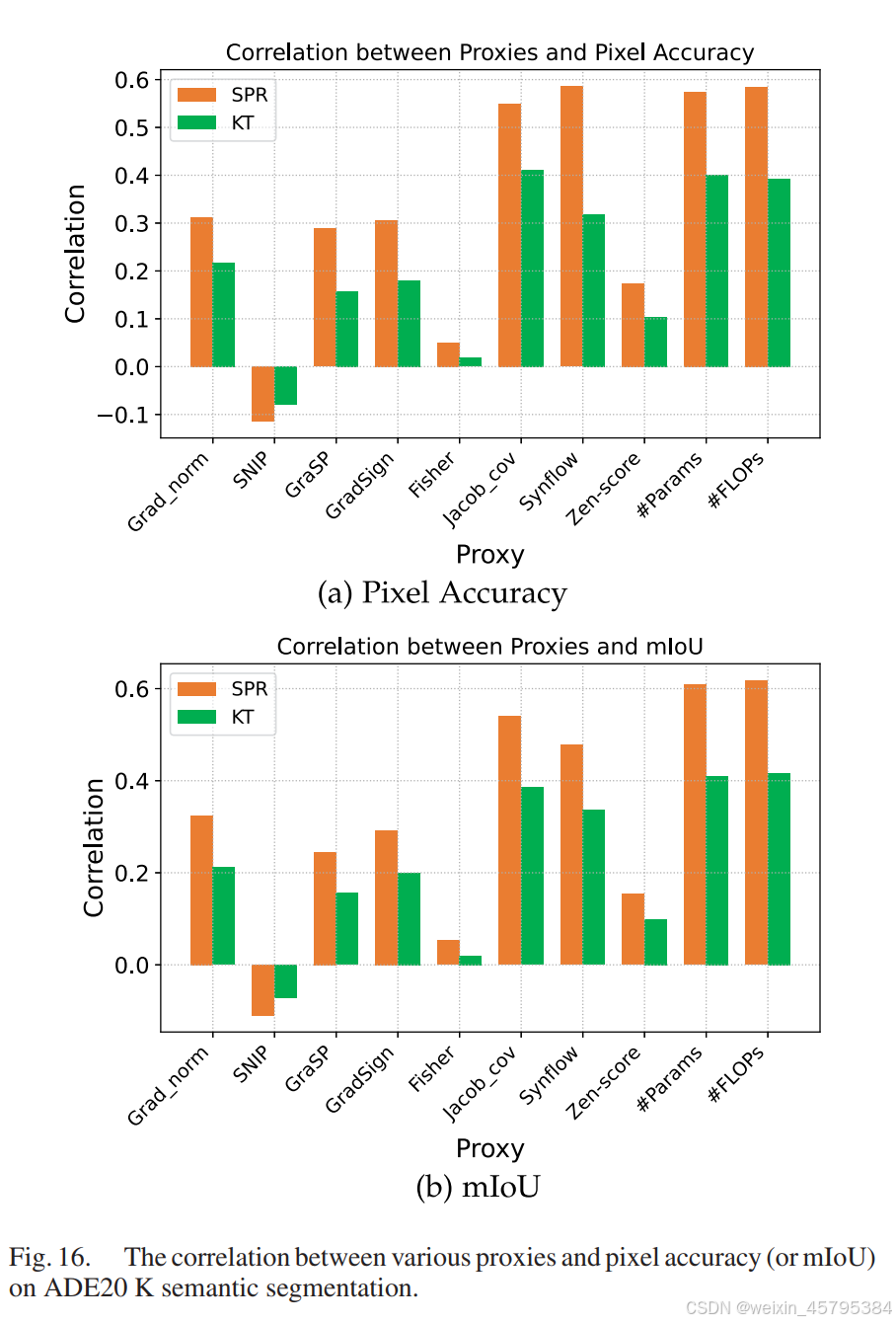
C. 视觉变换器
到目前为止,我们的评估主要集中在卷积神经网络(CNN)上。然而,随着视觉变换器(ViTs)在计算机视觉领域的表现和受欢迎程度的急剧上升,ViTs 在计算机视觉中的重要性正在不断增加。因此,本节我们使用 ViT 模型空间(针对 ImageNet-1K 数据集)评估这些零次代理。
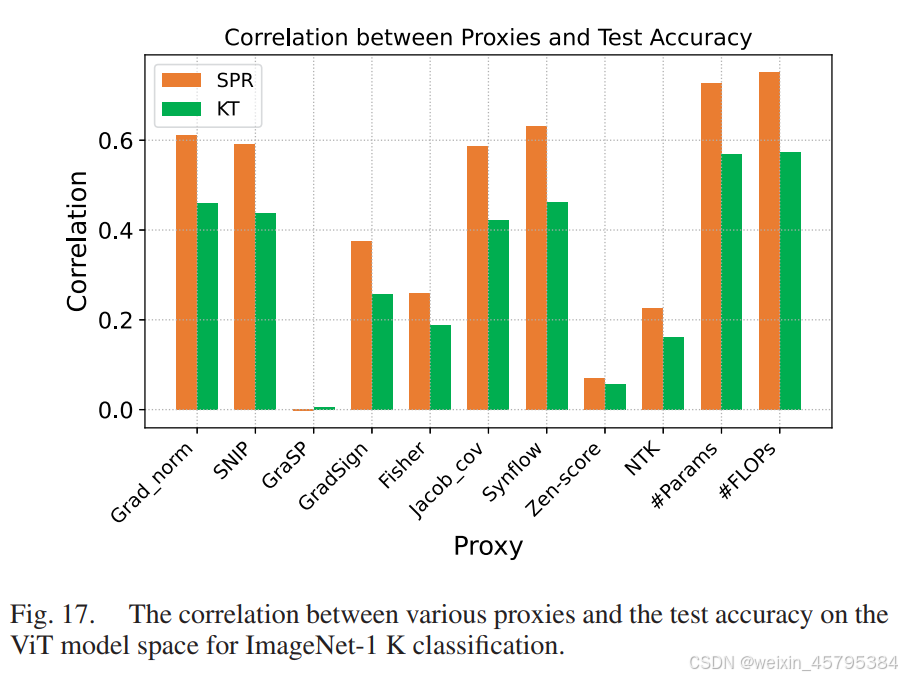
具体而言,我们在 TIMM [111] 的 ViT 模型空间中比较这些零次代理。需要特别注意的是,我们只考虑在 ImageNet-1K 上独立训练的网络,不包括使用预训练或蒸馏的网络。总共评估了 100 个 ViT,并报告了 Top-1 精度 与各种代理之间的相关性,如图 17 所示。结果表明,#Params 和 #FLOPs 与测试精度的相关性比分别的零次代理要高。这与我们在 CNN 上的观察一致。
总结来说,无论是分析 CNN 还是 ViT,#Params 和 #FLOPs 相比零次代理具有更高的相关性。
在实际应用中,测试性能并非唯一的设计考虑因素。实际上,通过 NAS 获得的模型应满足一些硬件约束,特别是在部署到边缘设备时。因此,接下来我们探讨这些代理在硬件感知搜索场景中的表现。
- 视觉变换器(Vision Transformers,ViTs)是一种新的神经网络架构,它基于变换器模型(Transformer)而不是传统的卷积神经网络(CNN)。最初,变换器模型是为自然语言处理任务设计的,但近年来,它们在图像处理任务中也取得了显著的成功。ViT通过处理图像的每个部分(如图像的块)来学习全局信息,而不是像CNN那样通过卷积层局部提取特征。
- TIMM(PyTorch Image Models)是一个由开源社区提供的用于训练和评估图像分类模型的库,提供了多种预训练的模型,包括视觉变换器(ViT)等架构。在这项研究中,作者使用TIMM库提供的ViT模型空间来进行比较实验。
D. 硬件感知 NAS
在这一部分,我们使用上述介绍的零次代理进行硬件感知 NAS。具体而言,我们使用这些零次代理来替代真实的测试精度,搜索在各种约束下的帕累托最优网络。接下来,我们介绍了在 NASBench-201(与 HW-NAS-Bench)和 NATS-Bench 上的结果。
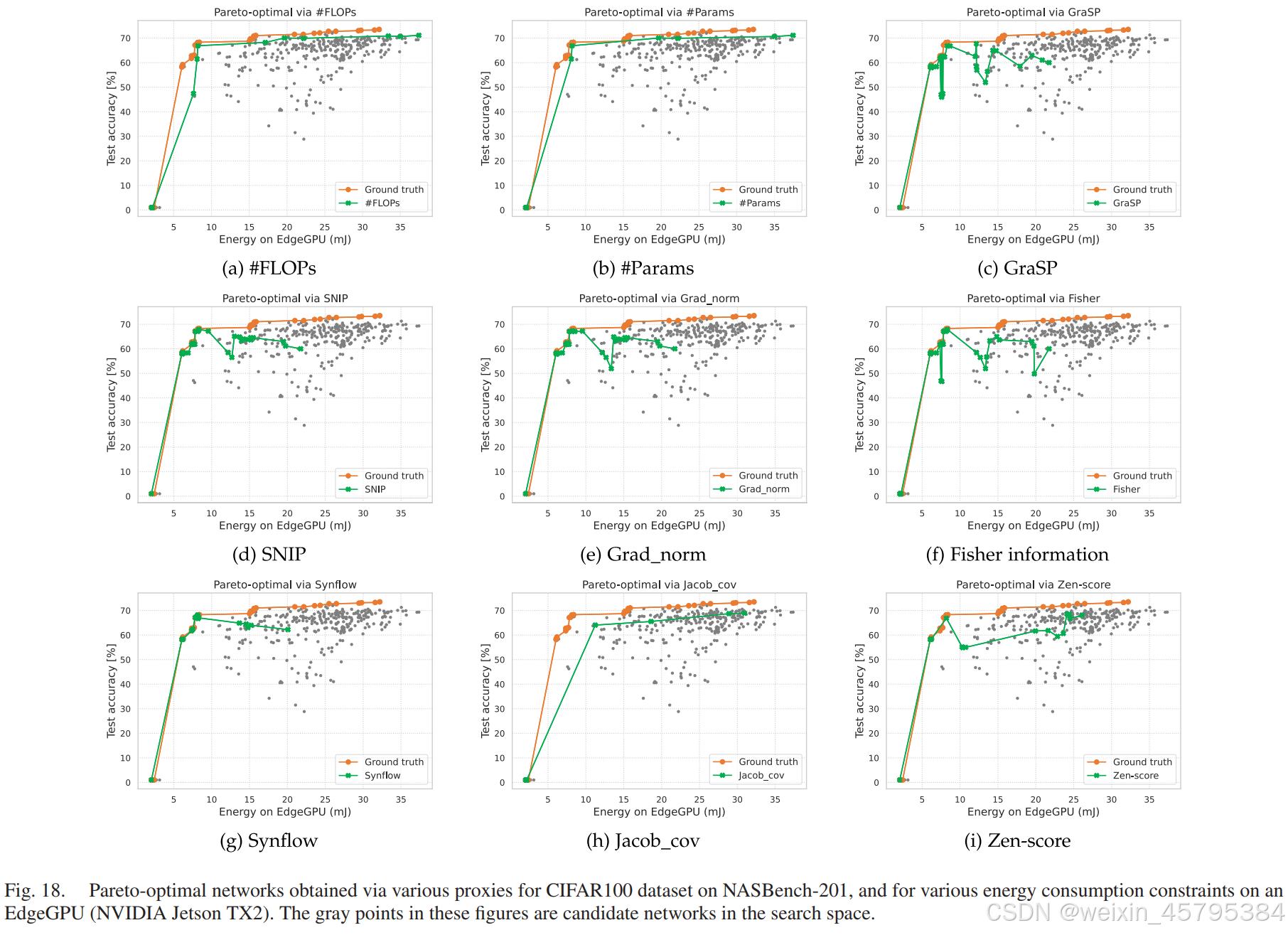
- NASBench-201 / HW-NAS-Bench:我们使用 EdgeGPU(NVIDIA Jetson TX2)作为目标硬件,并使用 HW-NAS-Bench 提供的能耗数据;然后我们设置不同的能耗值作为硬件约束。接下来,我们使用不同的精度代理来遍历搜索空间中的所有候选架构,并在各种能耗约束下获得帕累托最优网络。
为了说明这些网络的质量,我们在图 18 中绘制了这些网络和通过实际精度获得的真实结果。如图所示,当能耗约束较紧(例如小于 10 毫焦)时,大多数代理都能找到非常接近真实帕累托最优的网络,除了 Jacob_cov。然而,当能耗约束较为宽松(例如大于 20 毫焦)时,只有 #Params、#FLOPs 和 Jacob_cov 能找到一些接近真实结果的网络。
- NATS-Bench:我们在 NVIDIA GTX-1080 上测量了 NATS-Bench 的延迟数据。然后,我们使用不同的精度代理来遍历所有候选架构,在各种延迟约束下获得帕累托最优网络。如图 19 所示,我们绘制了这些网络和真实结果。当我们将延迟约束设置为 50 毫秒左右时,只有 #Params、SNIP 和 Zen-score 能找到几乎与真实帕累托最优网络匹配的网络。
在这两个基准上的结果进一步验证了当前的代理在高精度网络上的相关性较差,因为当硬件约束更宽松时,真实的帕累托最优网络通常具有更高的精度。这一观察表明,在这种情境下,设计更好的代理具有巨大的潜力。
NATS-Bench 搜索空间的限制可能确实会影响某些代理在放宽硬件约束时的表现
E. 讨论与未来工作
- NAS基准测试:
-
搜索空间的多样性:我们指出,目前大多数现有的NAS基准测试的搜索空间仅包含基于单元的神经网络架构。为了进一步提高NAS基准的通用性,社区可能需要将来自更广泛搜索空间的新架构纳入其中。例如,NATS-Bench已添加了不同阶段的不同单元架构。此外,这些现有基准中的单元结构类似于DARTS单元结构。然而,在实际应用中,MobileNet-v2中的倒瓶颈模块因其更高的硬件效率而被更广泛地使用。因此,NAS基准的下一步可能需要覆盖更具实践性和广泛使用的搜索空间,例如FBNet-v3。
-
硬件效率意识:到目前为止,只有HW-NASBench提供了针对几种硬件平台的多个硬件约束,但它没有为基准中的大多数网络提供精度数据。因此,我们建议未来的NAS基准应结合精度和硬件指标,以适应典型的硬件平台。
- 零次代理:
-
为何#Params有效:如第IV-A1节所示,#Params在多个数据集和多个基准测试中,针对无约束搜索空间,其与测试精度的相关性高于其他代理。有人可能会疑惑,为什么这样一个简单的代理能表现得如此出色。通常,良好的神经网络架构应满足以下几个属性:良好的收敛性/可训练性和较高的表达能力。我们提出以下几点观察:
- 表达能力:众所周知,具有无限宽度或深度的网络能够表达任何类型的复杂函数,且误差可以非常小[113][114][115]。此外,先前的工作表明,随着深度或宽度的增加,网络与真实函数的误差会逐渐减小。换句话说,更多的参数捕获了给定神经网络更高的表达能力[68]。
- 泛化能力:先前的工作揭示了,具有更多参数的网络在适当的训练设置下,通常具有更高的测试精度[116]。
- 可训练性:一方面,在相似的深度下,较宽的网络具有更好的可训练性和更高的收敛速度,显然也有更多的参数[53]。另一方面,大多数在流行基准上评估的网络共享类似的深度值。因此,在这些基准中,更多的参数也表示更好的可训练性。
- 因此,#Params能够捕捉到这些基准中网络的表达能力和可训练性。相比之下,大多数提出的代理通常只强调网络的表达能力或可训练性(而非两者)。这可能就是为什么#Params比这些代理表现更好的原因。因此,未来的工作应设计一个代理,能够同时指示给定网络的收敛性/可训练性和表达能力与泛化能力。例如,最近提出的代理ZiCo同时表示了神经网络的可训练性和泛化能力,因此在多个NAS基准测试中始终优于#Params[117]。
-
何时#Params失效:
- (i)如本节所示,在考虑测试精度排名前5%的架构时,几个代理在某些基准测试中超过了#Params和#FLOPs。此外,这些高性能的网络架构是最重要的,因为NAS的目标是获取高精度的网络。
- (ii)许多代理在受限的搜索空间中表现良好,例如MobileNet和ResNet系列。这些网络广泛用于许多应用(例如,EdgeAI中的MobileNet-v2)。显然,上述两种失败情况对于推动零次NAS在更实际的场景中应用至关重要。因此,在这些情况下,探索更好的零次代理具有巨大的潜力。
-
搜索方法:虽然#Params在多个场景中超越了大多数代理的相关性,但仍有其他方法可以使用这些零次代理。例如,如[54]中所示,为了更好地利用这些代理,一种可能的搜索方法是将所有候选网络合并为一个超网络,然后在初始化阶段应用这些代理进行网络剪枝,直到满足硬件约束。这样,零次NAS方法的时间效率可以进一步提高,因为搜索空间在剪枝过程中会逐渐收缩。
-
理论支持:我们指出,大多数基于梯度的代理最初是为了估计给定网络的每个参数或神经元/通道的重要性而提出的,因此最初应用于模型剪枝问题,而不是网络排序问题。因此,这些基于梯度的代理在零次NAS中的有效性需要从理论角度进行更深入的理解。此外,尽管大多数基于梯度以外的代理通常伴随有某些理论分析,但正如第IV-A和IV-D节所示,它们通常与基于梯度的代理的相关性较低。为什么这些零次代理能够或不能估计不同网络的测试精度,这仍然是一个开放问题。
-
针对不同类型网络的定制代理:如第IV-A3节所述,几种零次代理在通用搜索空间中表现不佳,但在受限搜索空间中与测试精度的相关性非常高,甚至超过了#Params。事实上,IV-A和IV-D节显示,设计一个普适的零次代理是极其困难的。设计零次代理的一个潜在方向可能是将整个搜索空间划分为多个子空间,然后为不同子空间提出定制的代理。
V. 结论
本文全面回顾了现有的零次NAS方法。首先,我们介绍了零次NAS的精度代理,并提供了这些代理背后的理论启发和几种常用的NAS基准测试。然后,我们介绍了几种流行的硬件性能预测方法。我们还将现有的代理与两种简单的代理(即#Params和#FLOPs)进行了比较。通过计算这些代理与真实测试精度的相关性,我们表明,目前提出的代理在无约束搜索空间(即考虑基准中的所有架构)下,并不一定优于#Params和#FLOPs。然而,在受限搜索空间(即仅考虑测试精度较高的网络)下,我们发现现有的代理,包括#Params和#FLOPs,与真实精度的相关性远低于无约束情况。基于这些分析,我们解释了为什么#Params有效,以及它何时失效。最后,我们指出了几个潜在的研究方向,以设计更好的NAS基准并提供改进零次NAS方法的几种思路。
心迹录
我们现在生活的问题的主要原因在于,我们现在的生活已经变得以追求奖励为中心,我们做的几乎所有事情,都是为了追求最终那一刻的愉悦感。正因如此,我们忽视了过程中的体验,我们总是将注意力集中在未来的奖励上,却无法真正享受当下,紧张又期待或又恐惧总希望手头的事情快点结束,这样我们就能躲起来做自己想做的事情,这种自我刺激的行为是我们常做的。每次想着活在当下,我都会感受到痛苦。就好像我对自己不满意,也不喜欢活在世上,我现在不想呆在这里,我想逃离这里。知道我经历了很多事情,我才意识到,意味着活在当下并且接受当下的不适,并且对感到的不适感坦然,对无法控制我的快乐、痛苦、舒适感到坦然,对未来任何发生的事情保持开放的心态。这是一个很重要的改变,当我不在试图控制当下的感受,并且不再逃避接受不适,我认为这是普遍存在的现象,不要期待未来的奖励,会帮助我们活在当下,想象一下未来不会有好事发生,没有所谓的奖励,这就是现实,就算我们为我们的生活安排好所有的事情,做了该做的事情,并且目标明确,你也无法时刻保持快乐,生活并不总是美好的,众生皆苦从根本上来说活着本身就是一种不适,并且这种不安和不适是持续不断的,如果我们坦诚面对并倾听内心,让自己真正看到并感受到这些,我们可能会从束缚中解脱出来。


















 1037
1037

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









