






哪些问题?
梯度消失会导致我们的神经网络中前面层的网络权重无法得到更新,也就停止了学习。
梯度爆炸会使得学习不稳定, 参数变化太大导致无法获取最优参数。
在深度多层感知机网络中,梯度爆炸会导致网络不稳定,最好的结果是无法从训练数据中学习,最坏的结果是由于权重值为NaN而无法更新权重。
在循环神经网络(RNN)中,梯度爆炸会导致网络不稳定,使得网络无法从训练数据中得到很好的学习,最好的结果是网络不能在长输入数据序列上学习。
原因何在?
举个例子

如上图,是一个每层只有一个神经元的神经网络,且每一层的激活函数为sigmoid,则有:
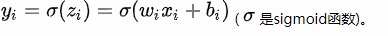
我们根据反向传播算法有:
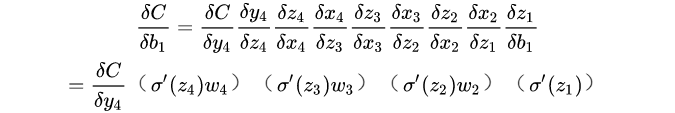
而sigmoid函数的导数公式为:
他的图像曲线

由上可见,sigmoid函数的导数的最大值为1/4,我们将初始权重初始化小于1,随着层数的增多,求导结果就会越小,这就是梯度消失的原因,大于1的话梯度会变大,造成爆炸。
总之,无论是梯度消失还是梯度爆炸,都是源于网络结构太深,造成网络权重不稳定,从本质上来讲是因为梯度反向传播中的连乘效应。
为什么LSTM能解决梯度问题
举个例子:在英文短语中,主语对谓语的状态具有影响,而如果之前同时出现过第一人称和第三人称,那么这两个记忆对当前谓语就会有不同的影响,为了避免这种矛盾,我们希望网络可以忘记一些记忆来屏蔽某些不需要的影响。
因为LSTM对记忆的操作是相加的,线性的,使得不同时序的记忆对当前的影响相同,为了让不同时序的记忆对当前影响变得可控,LSTM引入了输入门和输出门,之后又有人对LSTM进行了扩展,引入了遗忘门。
总结一下:LSTM把原本RNN的单元改造成一个叫做CEC的部件,这个部件保证了误差将以常数的形式在网络中流动 ,并在此基础上添加输入门和输出门使得模型变成非线性的,并可以调整不同时序的输出对模型后续动作的影响。
















 7039
7039











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











