






 本文介绍了使用Python进行广告效果分析,通过线性回归模型探讨电视、广播和报纸广告对销售额的影响。数据预处理、模型训练、评估及预测过程详细展示。
本文介绍了使用Python进行广告效果分析,通过线性回归模型探讨电视、广播和报纸广告对销售额的影响。数据预处理、模型训练、评估及预测过程详细展示。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib as mpl
%matplotlib inline
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
path=r"C:\Users\Tsinghua-yincheng\Desktop\SZday94\data\Advertising.csv"
data=pd.read_csv(path)
data["TV"]
data.shape
x=data[["TV","Radio","Newspaper"]]
x
y=data["Sales"]
y

解决中文乱码
mpl.rcParams['font.sans-serif'] = ['simHei']
mpl.rcParams['axes.unicode_minus'] = False#中文乱码
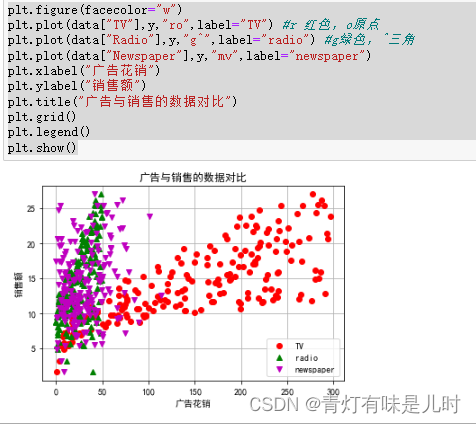
plt.figure(facecolor="w")
plt.plot(data["TV"],y,"ro",label="TV") #r 红色,o原点
plt.plot(data["Radio"],y,"g^",label="radio") #g绿色,^三角
plt.plot(data["Newspaper"],y,"mv",label="newspaper")
plt.xlabel("广告花销")
plt.ylabel("销售额")
plt.title("广告与销售的数据对比")
plt.grid()
plt.legend()
plt.show()
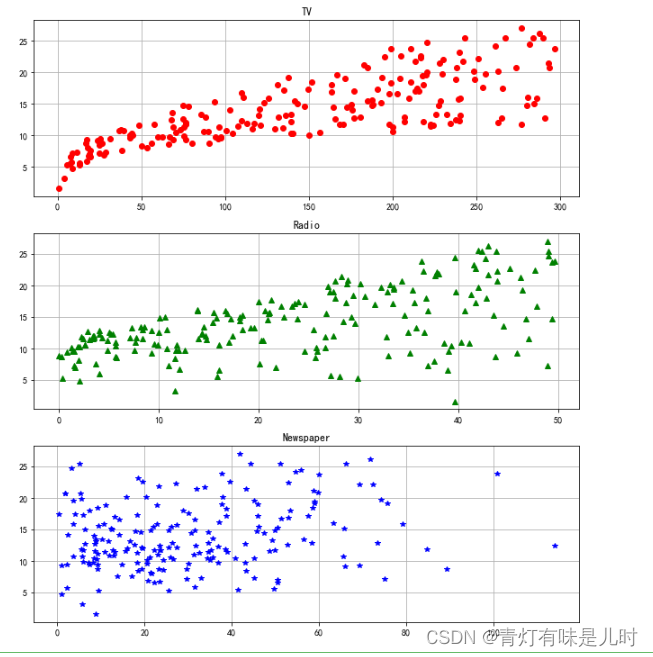
plt.figure(facecolor="w",figsize=(9,10))
plt.subplot(311)
plt.plot(data["TV"],y,"ro") #TV
plt.title("TV")
plt.grid()
plt.subplot(312)
plt.plot(data["Radio"],y,"g^") #音悦台
plt.title("Radio")
plt.grid()
plt.subplot(313)
plt.plot(data["Newspaper"],y,"b*") #报纸广告
plt.title("Newspaper")
plt.grid()
plt.tight_layout()
plt.show()
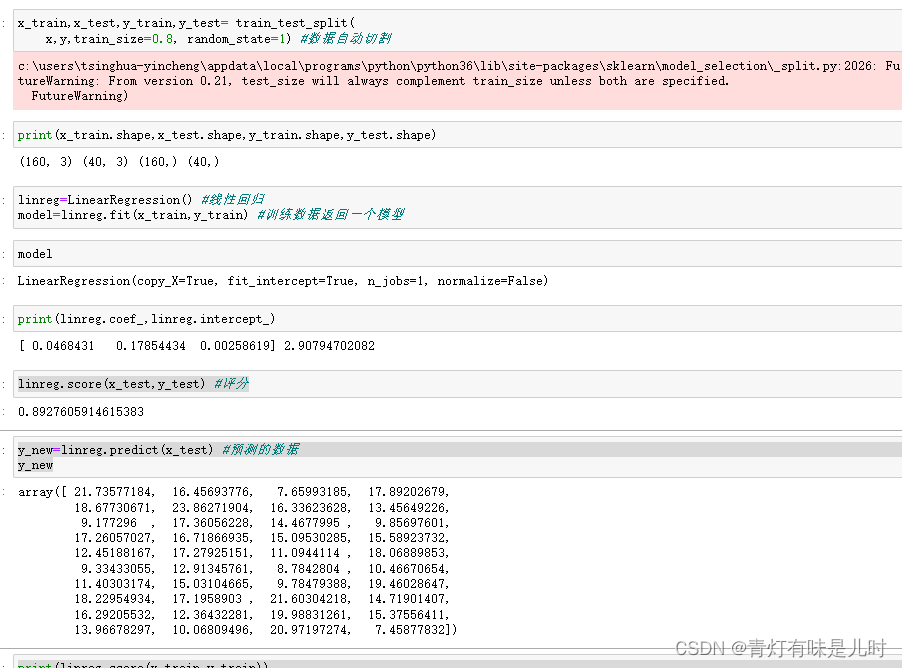
x_train,x_test,y_train,y_test= train_test_split(
x,y,train_size=0.8, random_state=1) #数据自动切割
print(x_train.shape,x_test.shape,y_train.shape,y_test.shape)
linreg=LinearRegression() #线性回归
model=linreg.fit(x_train,y_train) #训练数据返回一个模型
model
print(linreg.coef_,linreg.intercept_)
linreg.score(x_test,y_test) #评分
y_new=linreg.predict(x_test) #预测的数据
y_new
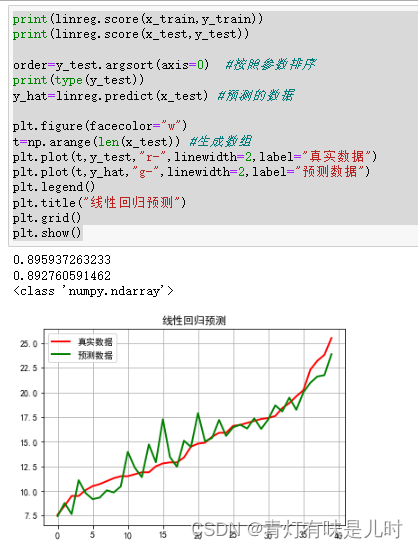
print(linreg.score(x_train,y_train))
print(linreg.score(x_test,y_test))
order=y_test.argsort(axis=0) #按照参数排序
print(type(y_test))
y_hat=linreg.predict(x_test) #预测的数据
plt.figure(facecolor="w")
t=np.arange(len(x_test)) #生成数组
plt.plot(t,y_test,"r-",linewidth=2,label="真实数据")
plt.plot(t,y_hat,"g-",linewidth=2,label="预测数据")
plt.legend()
plt.title("线性回归预测")
plt.grid()
plt.show()
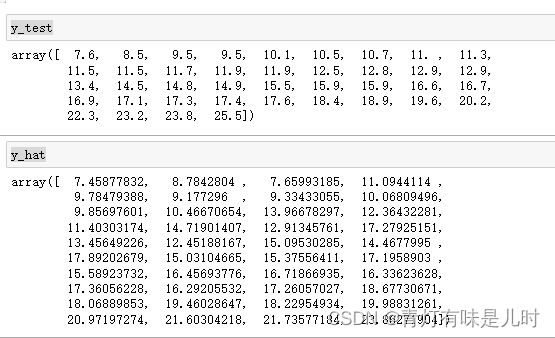
y_test
y_hat



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











