







1.什么是Map
在计算机科学界,被称为相关数组、map、符号表或字典,是由一组<key,value>对组成的数据结构,并且相同的key只会出现一次
Map的数据结构有两种
哈希查找表(HashTable), 搜索树(Search Tree)
开销:主要是哈希函数的计算和数组常数访问时间,很多场景,哈希查找表的性能很高
Hash Table会存在碰撞问题, 一般有两个应对方法: 链地址法和 开放地址法
链地址法:将bucket实现成一个链表,落在一个bucket的key都会插入这个链表
开放地址发:碰撞后,按照一定规律,在数组后面挑选空位,放置新的key
平衡搜索树法的最差搜索效率是 O(logN),而哈希查找表最差是 O(N)。当然,哈希查找表的平均查找效率是 O(1),如果哈希函数设计的很好,最坏的情况基本不会出现。还有一点,遍历自平衡搜索树,返回的 key 序列,一般会按照从小到大的顺序;而哈希查找表则是乱序的。
2.为什么使用map
从 Go 语言官方博客摘录一段话:
One of the most useful data structures in computer science is the hash table. Many hash table implementations exist with varying properties, but in general they offer fast lookups, adds, and deletes. Go provides a built-in map type that implements a hash table.
hash table是计算机网络的重要设计,大部分hash table都实现快速查找,添加,删除功能
为什么使用map 因为他太强大了,增删改查效率都很高
3.Map底层如何实现
1.Map内存模型
type hmap struct {
count int // 元素个数,调用len(map)返回这个值
flags uint8
B uint8 // bucket的对数log_2
noverflow uint16 //overflow的bucket近似数
hash0 uint32 // 计算key的哈希会传入hash函数u
buckets unsafe.Pointer //指向buckets数组,数组大小2^B
//元素个数为0,就位nil
oldbuckets unsafe.Pointer // 扩容的时候,buckets长度是oldbuckets的两倍
nevacuate uintptr// 扩容进度,小于此地址buckets迁移完成
extra *mapextra // optional fields
}
B是buckets数组长度的对数,buckets数组长度是2^B
bucket存储了key和value
type bmap struct{
tophash [bucketCnt] uint8
}
(src/runtime/hashmap.go)
type bmap struct{
topbits [8]uint8
keys [8]keytype
values [8]valuetype
pad uintptr
overflow uintptr
}
bmap是我们常说的"桶",桶里面最多装8个key,这些key会落入同一个桶,是因为他们经过hash计算发现哈希结果是"一类"的,又会根据key的hash值的高8为决定key落在桶的那个位置
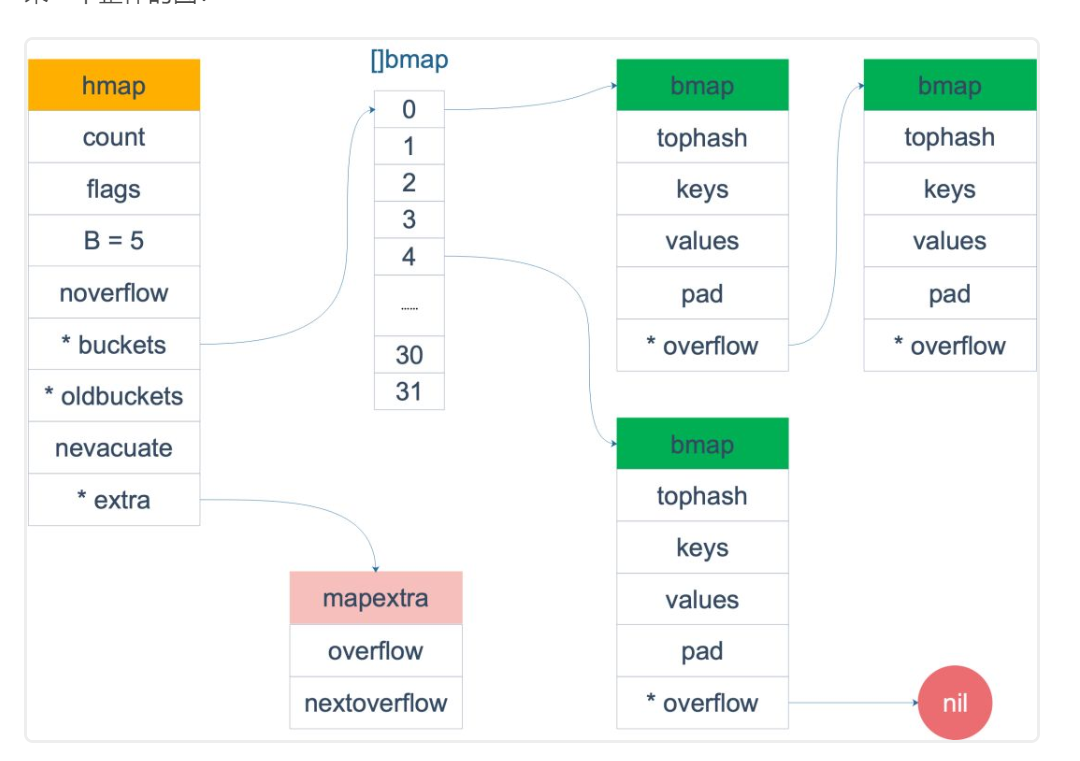
当map的key和value都不是指针,并且size<128字节,会把bmap标记为不含指针,但是我们看bmap是有一个*overflow,破坏了bmap不含指针思想,这时候会把overflow移动到extra来
type mapextra struct{
overflow [2]*[]*bmap
nextOverFlow *bmap
}
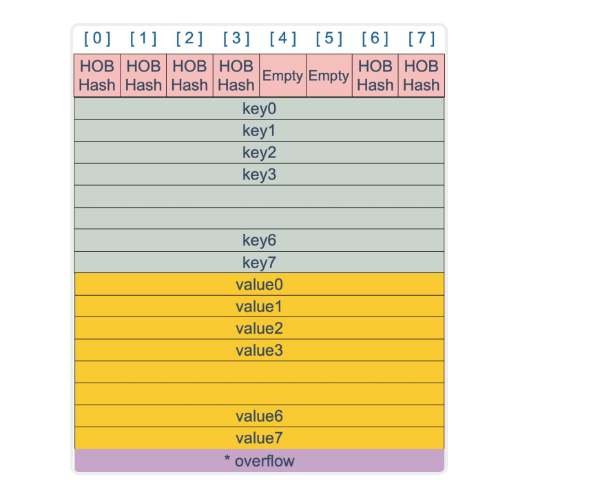
上面key和key放一起,value和value放一起,好处是省略
padding字段
2.创建map
m := make(map[string]int)
m := make(map[string]int,8)
var m map[string]int //m为nil不能添加元素,否则为panic
makemap哈数,初始化hmap结构体各个字段
func makemap(t *maptype, hint int64, h *hmap, bucket unsafe.Pointer) *hmap
map的结构体内部包含底层的数据指针
makemap和makeslice的区别:当map和slice作为函数参数,在函数参数内部对map操作会影响自身,而slice不会
主要原因:一个是指针(*hmap),一个是结构体(slice),Go语言函数传参都是值传递,函数内部的参数会被拷贝到本地,
*hmap经过copy过后仍然指向一个map,slice被拷贝过后会成为新的slice对原来无影响
3.哈希函数
map的一个关键点在于,在程序启动会检测cpu是否支持aes,如果支持则用aes hash 否则用memhash.这是在函数
alginit()完成
hash函数有加密型和非加密型:加密型用于加密数据,数字摘要,典型的:md5,sha1,sha256,aes256
非加密型:查找,map应用场景主要是查找
其中
alg字段就于hash相关
type typeAlg struct{
hash func(unsafe.Pointer, uintptr) uintptr
equal func(unsafe.Pointer, unsafe.Pointer) bool
}
4.key定位过程
key经过哈希计算得到哈希值,计算他要落到那个桶里面,最后会用到B个bit位
10010111|000011110110110010001111001010100010010110010101010│01010
最后的5个bit位,是
01010,也就是10号桶然后取哈希值的高8位,找到key在bucket中的位置,最开始桶内还没有key,新加入的key会找到第一个空位然后放入
buckets编号就是桶编号,当两个不同的key落在同一个桶中,就发生了hash冲突, 解决冲突方法:链表法
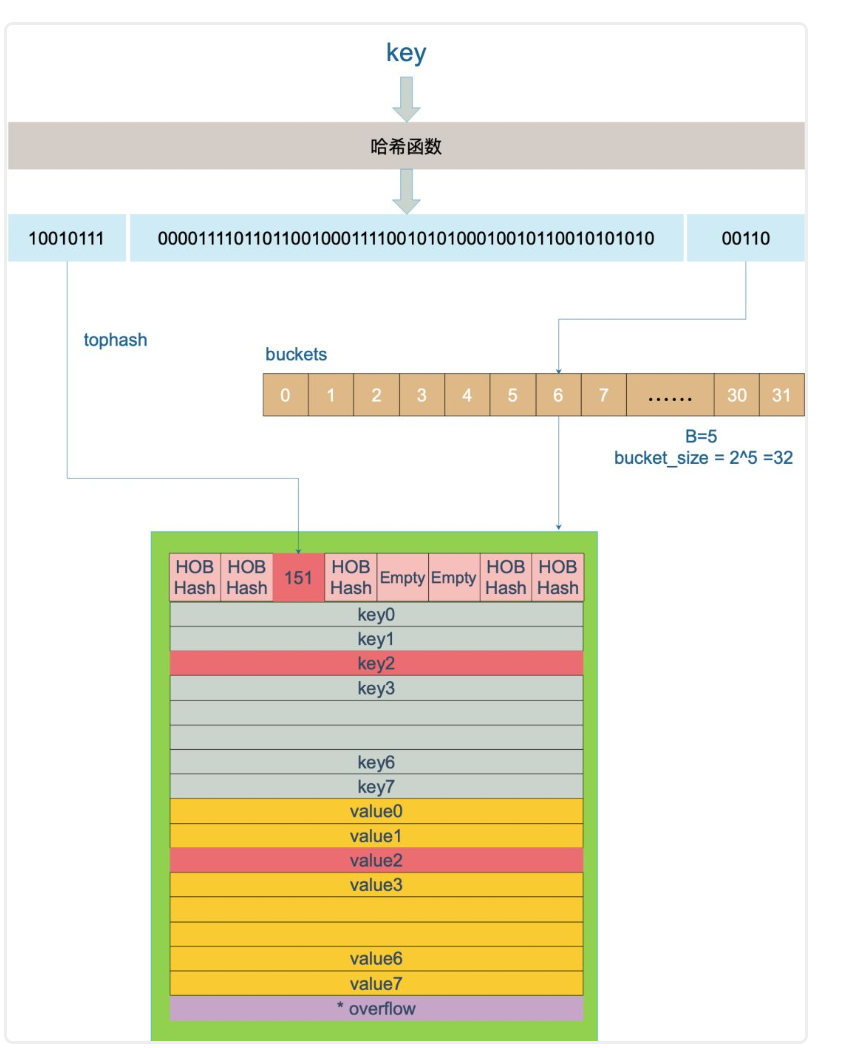
上图B=5,则一共有2^B=32个桶,然后第五位是
00110是6,高8位是10010111对应十进制151,对应2号槽位如果bucket没找到,并且overflow不为空,需要到overflow查找
我们看
mapaccessl函数

key和value方法和整个循环的方法
//key定位公式
k := add(unsafe.Pointer(b),dataOffset+i*uintptr(t.keySize))
//value定位公式
v := add(unsafe.Pointer(b),dataOffset+bucketCnt*uintptr(t.keysize)+i*uintptr(t.valuesize))
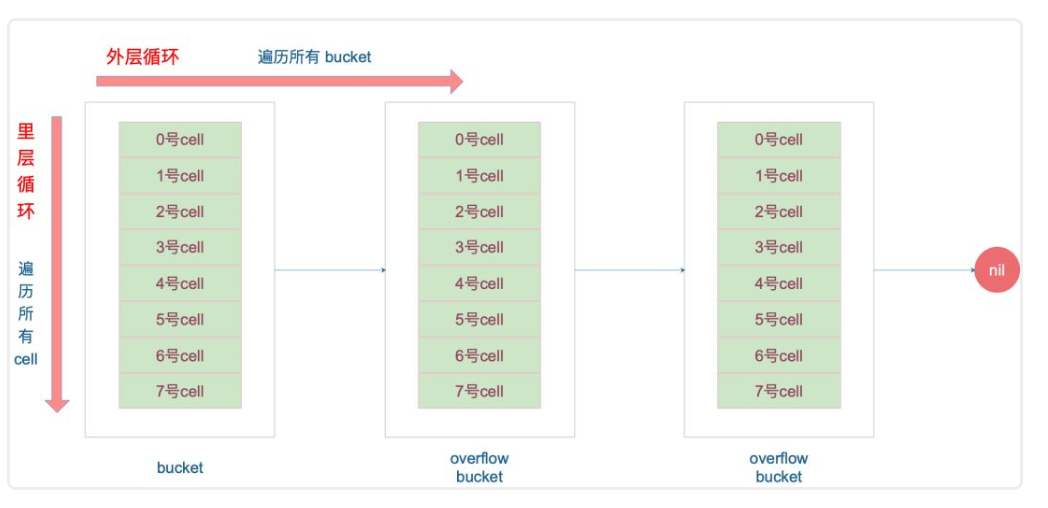
下面几个状态代表bucket
//空的cell 初始bucket状态
empty =0
//空的cell,表示cell已经被搬迁到bucket
evecuatedEmpty = 1
//key.value搬迁完毕 但是key在value的前半部分
evacuatedX = 2
//key在后半部分
evacuatedY = 3
//topHash的最小正常值
minTopHash = 4
源码判断是否搬迁完毕
func evacuated(b *bmap) bool{
h := b.tophash[0]
return h>empty&& h<minTopHash
}
5.Map的get方法
Go中有两种获取map语法:带comma和不带comma
package main
import "fmt"
func main(){
m := make(map[string]int)
m["bwll"]= 21
//不带comma
age1 := m["bwll"]
fmt.Println(age1)
//带comma
age2,ok := m["bwll"]
fmp.Println(age2,ok)
}
//0
//0 false


6.扩容
使用哈希表是为了快速查找Key,随着map被添加,key发生碰撞概率也越来越大,bucket的8个cell会主键填满,插入,查找效率逐渐降低, (最理想状态下,一个Bucket只存一个key,就能达到0(1)效率)
如果所有的key落在一个bucket就导致退化成了链表,各种操作变为0(n)这样不行
需要有一个
装载因子
loadFactor := count /(2^B)
count就是元素数量,2^B是桶的数量
当向map中插入新的key,会进行条件检测
1.装载因子>6.5
2.overflow的bucket过多,
当B<15,如果overflow的bucket超过2^B
或者B>15,overflow的bucket超过2^15
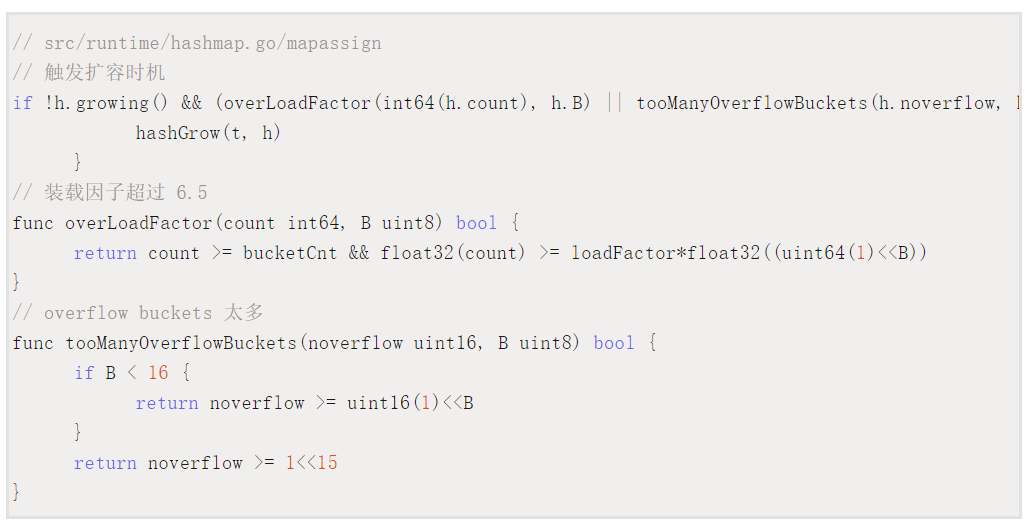
对于条件1,元素太多,bucket太少,将B+1,这时候就有新老bucket,但是元素都在老的bucket,没有迁移到新的Bucket,新bucket数量变为原来二倍(2^B*2)
条件2可以重新开辟一个bucket,然后把老的bucket的key和overflow bucket的key放到新的bucket里面
还有极端情况,如果map的key都一样,落到同一个bucket,超过8个产生overflow bucket,移动元素解决不了问题,整个哈希表退化成了单链表,操作效率是0(n)
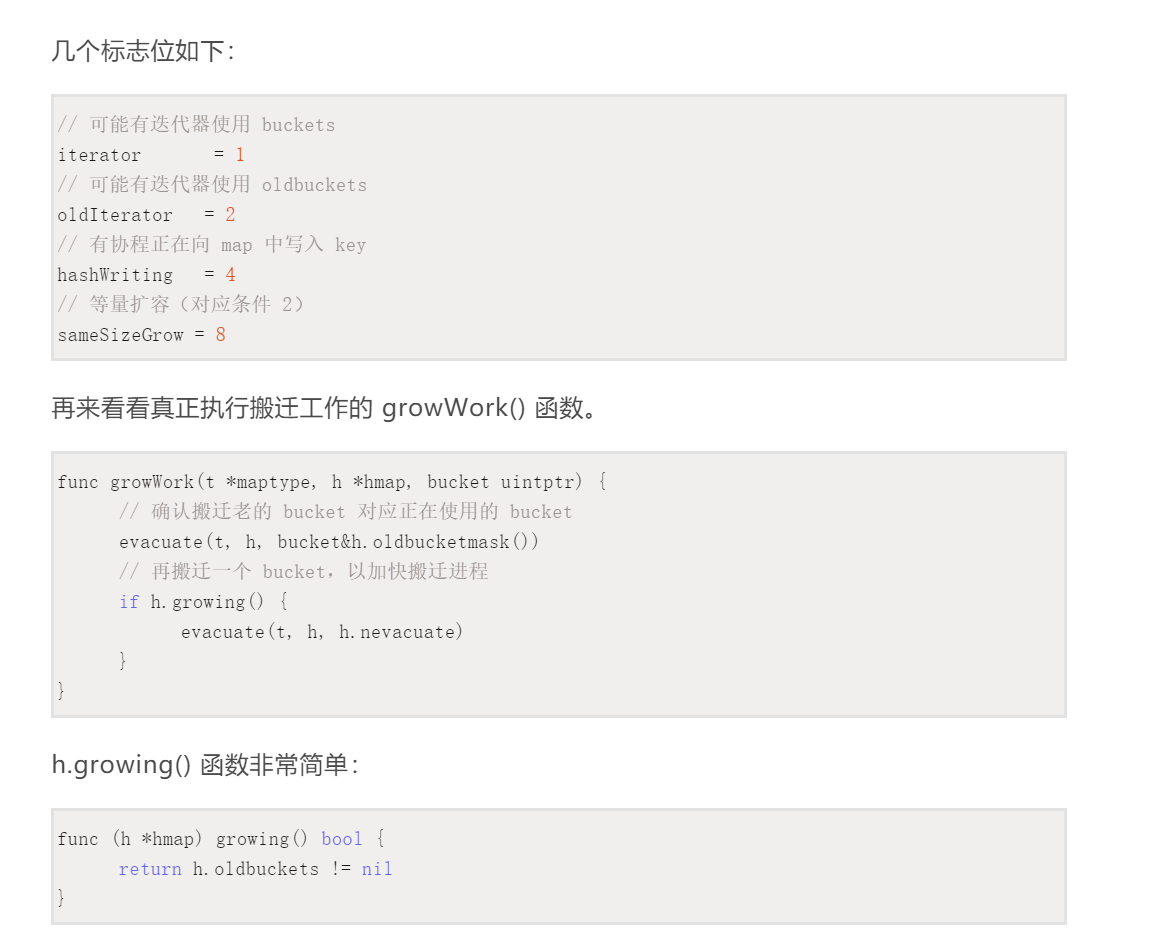
极端问题解决办法: 我们需要将原有的key/value搬迁到新的内存地址,如果需要大量key/value搬迁,这是非常消耗性能, 所以我们使用 渐进式扩容
hasGrow没有搬迁,只是分配号buckets,将老的bucket挂载到oldbuckets,真正搬迁是mapassign和mapdelete,插入,修改,删除key会尝试搬迁

刚开始nevacuate被置位0,显示当前搬迁进度为0
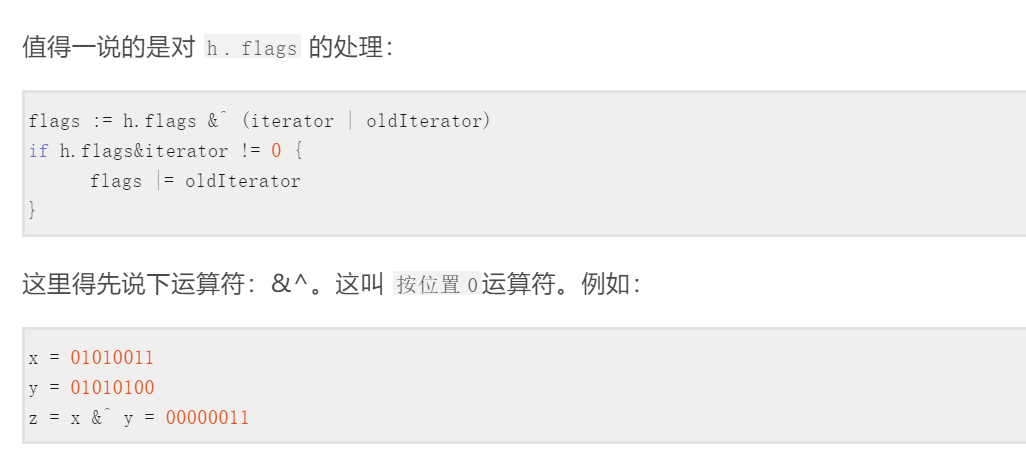
bucketmask就是将key计算出来与bucketmask相与,比如B=5那么bucketmask就是11111,只有hash值低五位决定key落在那个桶















 2991
2991











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









