







并行算法
棋盘分块,先块内转置,然后在块之间进行转置。用mpi多进程实现,每个进程分配一个棋盘块,主进程进行初始化矩阵,按棋盘块顺序将数据存储到缓冲区一维数组buf中。
size是进程个数,n*n是n维矩阵,n*n /size是每个块的个数,开根号就是每个块的行或列数,而size开根号就是n行或列有多少个块。
我之前一直在想,你主进程把数据send到子进程,以及子进程将数据处理好后又send到主进程,主进程recv时怎么确保它recv的顺序呢?是先接收rank1还是rank2?
利用两个for循环,依次遍历每个棋盘块,而每个进程分配了一个棋盘块,我们指定将棋盘块顺序分配给各进程(如:第一个块分给进程0,第二块分给进程1,以此类推)
好像也可以用mpi_scatter和mpi_gather来传递信息?
参考:并行计算mpi实现矩阵转置,mpi分布式编程简介,点对点通信方法_結城的博客-CSDN博客n
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
#include<mpi.h>
#include<math.h>
int **a,*b,**result; //全局变量
MPI_Status status;
void init_matrix(int n) //初始化矩阵
{
a = (int**)malloc(n * sizeof(int*));
result = (int **)malloc( n * sizeof(int) );
for(int i = 0; i < n; i++)
{
a[i] = (int*)malloc(n * sizeof(int));
result[i] = (int *)malloc( sizeof(int) * n );
}
int b = 0;
for(int i = 0; i < n; i++)
{
for(int j = 0; j < n; j++)
{
a[i][j] = b;
result[i][j] =b;
b++;
printf("%2d ", a[i][j]);
}
printf("\n");
}
}
int main(int argc, char **argv)
{
int n = 6;
MPI_Init(NULL,NULL);
double t1 = MPI_Wtime();
int rank,size;
MPI_Comm_rank(MPI_COMM_WORLD,&rank);
MPI_Comm_size(MPI_COMM_WORLD,&size);
int each_row_has_block = sqrt(size); //矩阵是n*n,表示行或列有多少个block
int block_size = n / each_row_has_block; // 每个block的size
b = (int*)malloc( sizeof(int) * n * n);
if(rank == 0)
{
init_matrix(n); // init the matrix
for(int i = 0; i < each_row_has_block; i++)
{
for(int j = 0; j < each_row_has_block; j++) //遍历每个block
{
int index = 0;
for(int m = i*block_size; m < (i+1)*block_size; m++) //为每个block赋值
{
for(int w = j*block_size; w < (j+1)*block_size;w++)
{
b[index] = a[m][w];
index++;
}
}
if( i == 0 && j == 0 ) //rank==0时,先块内转置完
{
for(int k = 0;k<block_size;k++)
{
for(int w = 0;w<block_size;w++)
{
result[k][w] = a[w][k];
}
}
}
else
MPI_Send(b,block_size*block_size,MPI_INT,i*each_row_has_block+j,i*each_row_has_block+j,MPI_COMM_WORLD);
// i*each_row_has_block+j because a block belongs a process
// buf only one dimesion so b is b[n*n],
}
}
}
else{
MPI_Recv(b,block_size*block_size,MPI_INT,0,rank,MPI_COMM_WORLD,&status);
for(int i=0;i<block_size;i++)
{
for(int j=0;j<block_size;j++)
{
int temp = b[i*block_size+j];
b[i*block_size+j] = b[j*block_size+j];
b[j*block_size+i] = temp;
}
}
MPI_Send(b,block_size*block_size,MPI_INT,0,rank,MPI_COMM_WORLD);
}
if(rank == 0)
{
for(int i = 0;i<each_row_has_block;i++)
{
for(int j = 0; j < each_row_has_block; j++)
{
if(i != 0 || j != 0)
MPI_Recv(b,block_size*block_size,MPI_INT,i* each_row_has_block+j,i*each_row_has_block+j,MPI_COMM_WORLD,&status); //rank0接收各子进程传来的数据
for(int k = 0; k < block_size; k++) //各块进行转置
{
for(int l = 0; l < block_size; l++)
{
result[i*block_size+k][j*block_size+l] = b[l*block_size+k];
}
}
}
}
}
for(int i = 0; i < n; i++)
{
for(int j = 0; j < n; j++)
{
printf("%2d ",result[i][j]);
}
printf("\n");
}
double t2 = MPI_Wtime();
if(rank == 0)
printf("the time is %f seconds\n",t2 - t1);
free(a);
free(b);
free(result);
MPI_Finalize();
return 0;
}
在ubuntu中运行不出来。。但在windows中用VS可以跑出来(虽然也有提示错误。。)
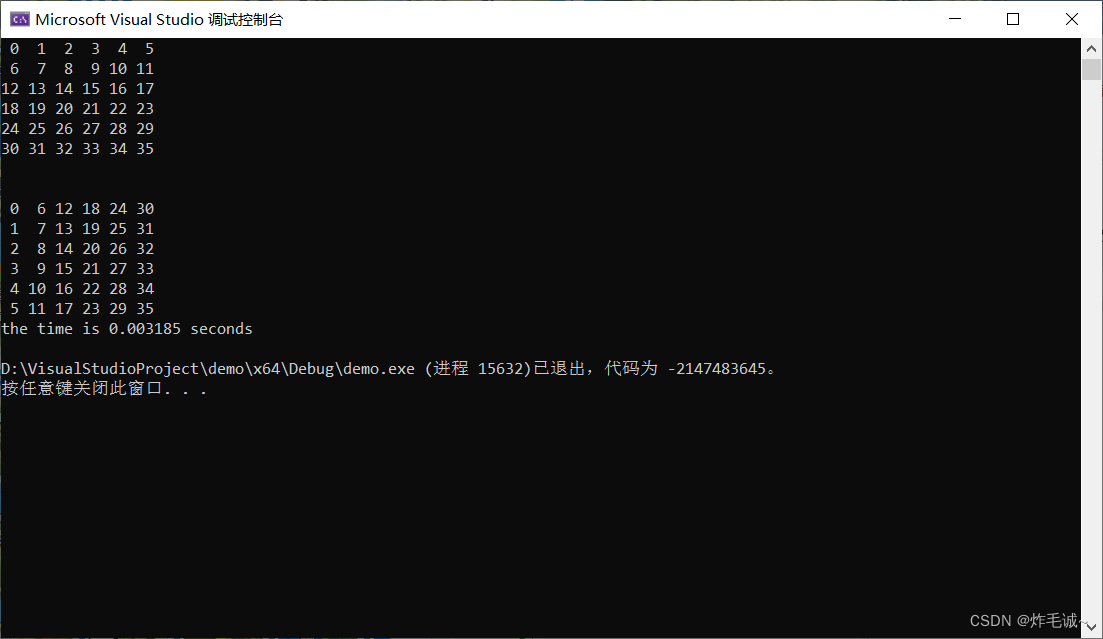
我怎么感觉并行计算还麻烦些~…~















 825
825











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









