







分享一份 COVID-19比较权威的全球各个国家的感染者人数的 GitHub 项目数据,该项目截止目前获得29.1k的星标,并在柳叶刀发文,项目由约翰斯·霍普金斯大学系统科学与工程中心(Johns Hopkins University Center for Systems Science and Engineering, CSSE)提供支持。该项目提供了全球 COVID-19 疫情的实时数据和统计信息,显示了所有受影响国家/地区的 COVID-19 确诊病例、死亡和康复情况的位置和数量,数据源包括中国、台湾和欧洲各自的疾病控制和预防中心 (CDC)、香港卫生部、澳门政府和世界卫生组织,以及市级和州级卫生当局。
GitHub项目地址:CSSEGISandData/COVID-19: Novel Coronavirus (COVID-19) Cases, provided by JHU CSSE (github.com)
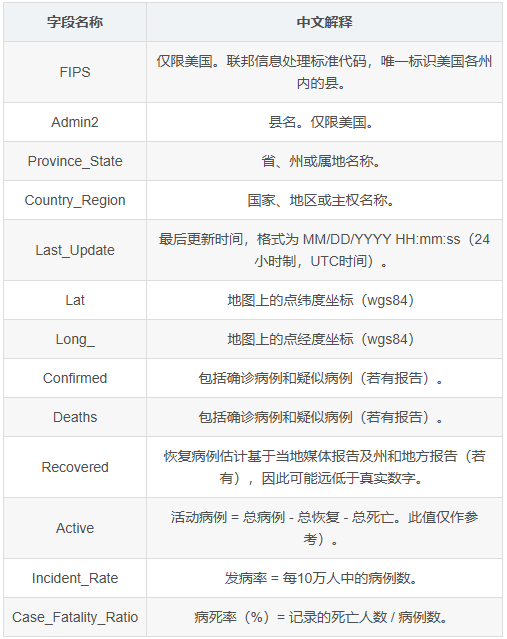
数据标签:
2023年3月10日,约翰霍普金斯大学冠状病毒资源中心停止收集和报告全球 COVID-19 数据,所以我们可以获取到的数据时间范围在(2020年1月22日-2023年3月9日),2020年1月22日—2020年3月21日的部分标签不一样,有需要的可以手动统计一下;
这里也放一下原始数据:【免费】COVID-19全球各个国家的感染者人数数据资源-CSDN文库
这里统计的是全球每天每个国家的感染人数和死亡人数,需要其他标签的可以自行增加,因为文件夹本身是一天对应一个CSV文件,所以这里我们通过脚本来处理;
完整代码#运行环境 Python 3.11
import os
import pandas as pd
def process_csv_files(folder_path):
# 创建一个空字典来存储汇总结果
summary_dict = {
'Date': [], # 存储日期
'Country_Region': [], # 存储国家名称
'Confirmed': [], # 存储确诊人数
'Deaths': [] # 存储死亡人数
}
# 遍历文件夹中的所有CSV文件
for filename in os.listdir(folder_path):
if filename.endswith('.csv'): # 只处理以'.csv'结尾的文件
# 提取文件名中的日期
date = filename.split('.')[0].replace('-', '/') # 将日期字符串格式化为YYYY/MM/DD的形式
# 读取CSV文件
file_path = os.path.join(folder_path, filename) # 构建完整的文件路径
df = pd.read_csv(file_path) # 使用pandas读取CSV文件
# 检查列名
column_names = df.columns.tolist() # 获取列名列表
# 如果存在Country_Region和Province_State列,则进行筛选
if 'Country_Region' in column_names and 'Province_State' in column_names: # 判断是否存在这两个列
# 计算每个国家的Confirmed和Deaths的汇总值
grouped_df = df.groupby(['Country_Region']).agg({'Confirmed': 'sum', 'Deaths': 'sum'}) # 按照Country_Region分组求和
# 将结果添加到summary_dict中
for country_region, values in grouped_df.iterrows(): # 遍历分组后的结果
summary_dict['Date'].append(date) # 添加日期
summary_dict['Country_Region'].append(country_region) # 添加国家名称
summary_dict['Confirmed'].append(values['Confirmed']) # 添加确诊人数
summary_dict['Deaths'].append(values['Deaths']) # 添加死亡人数
# 将字典转换为DataFrame
summary_df = pd.DataFrame(summary_dict) # 创建一个新的DataFrame对象
# 输出汇总结果
summary_df.to_csv(os.path.join(folder_path, 'global_summary.csv'), index=False) # 将DataFrame写入CSV文件
print("Summary CSV file has been created.") # 打印提示信息
# 调用函数
process_csv_files('D:\\Data\\COVID-19-master\\csse_covid_19_data\\csse_covid_19_daily_reports') # 设置文件夹路径这里把结果做了可视化,包括中法美英德五个个国家在同一时期的感染人数累计动态可视化图和选取了一天的全球感染人数数据叠加全球人口的地图;
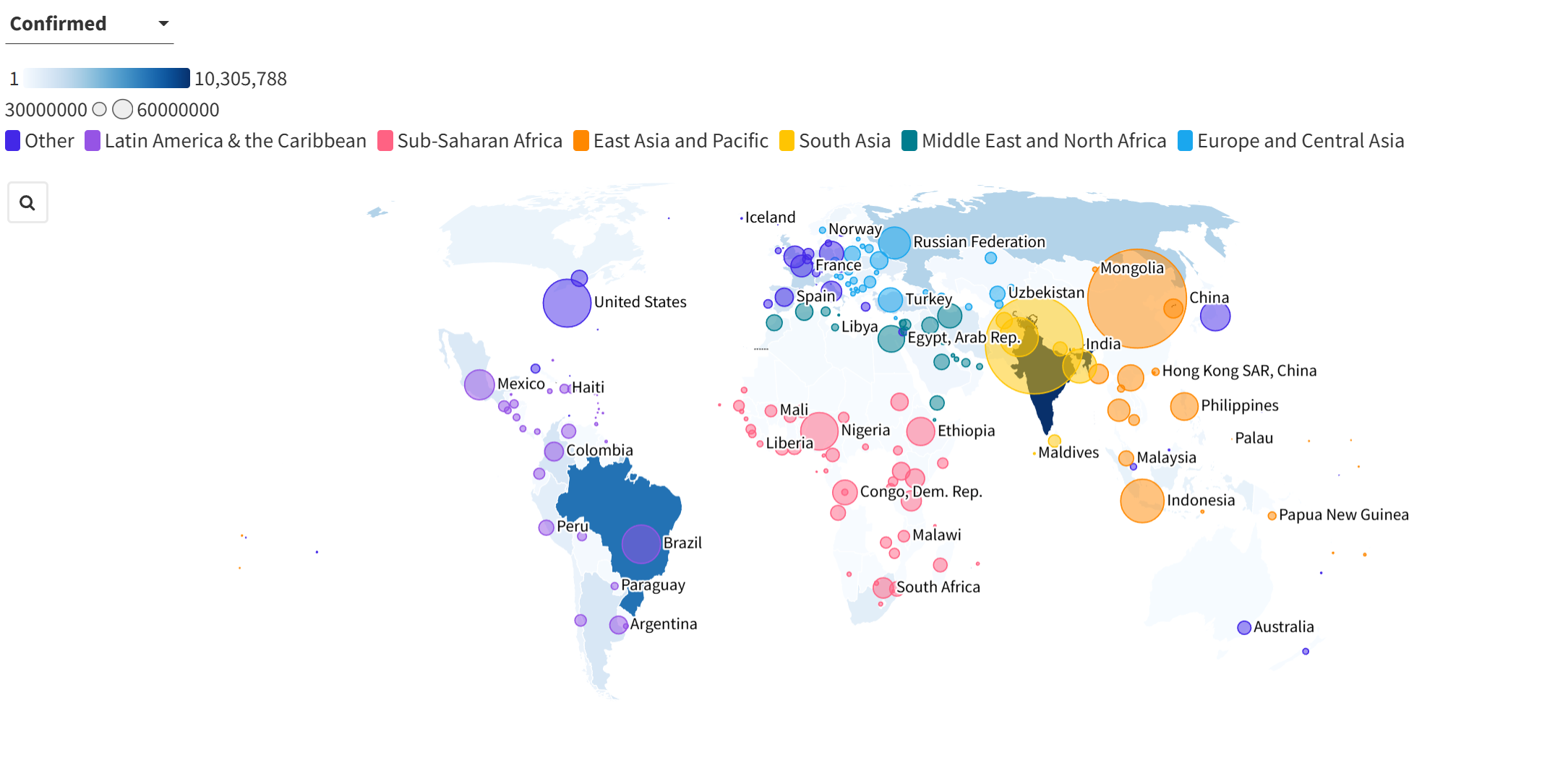
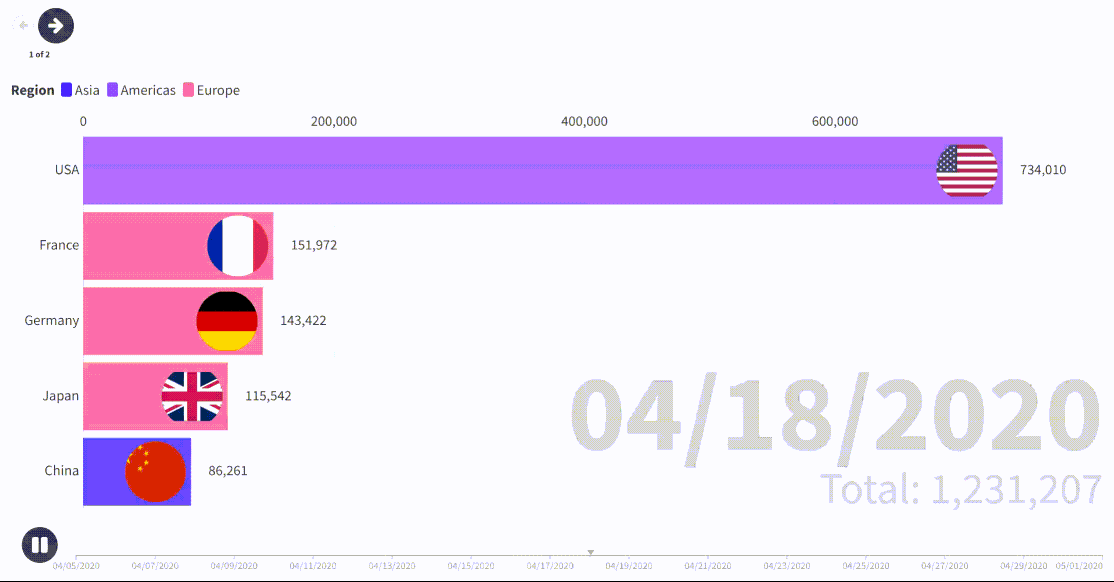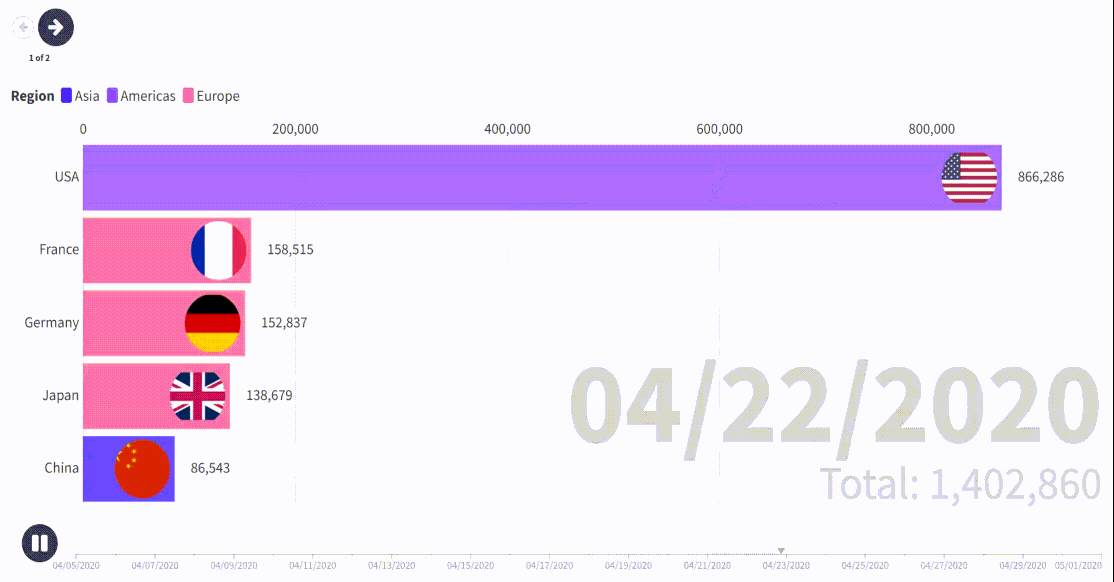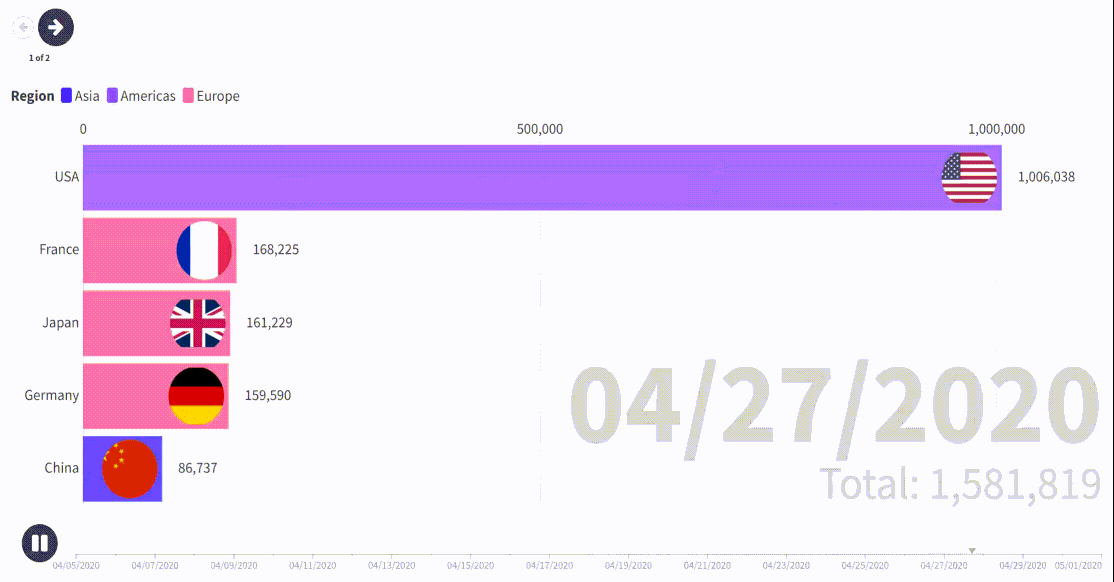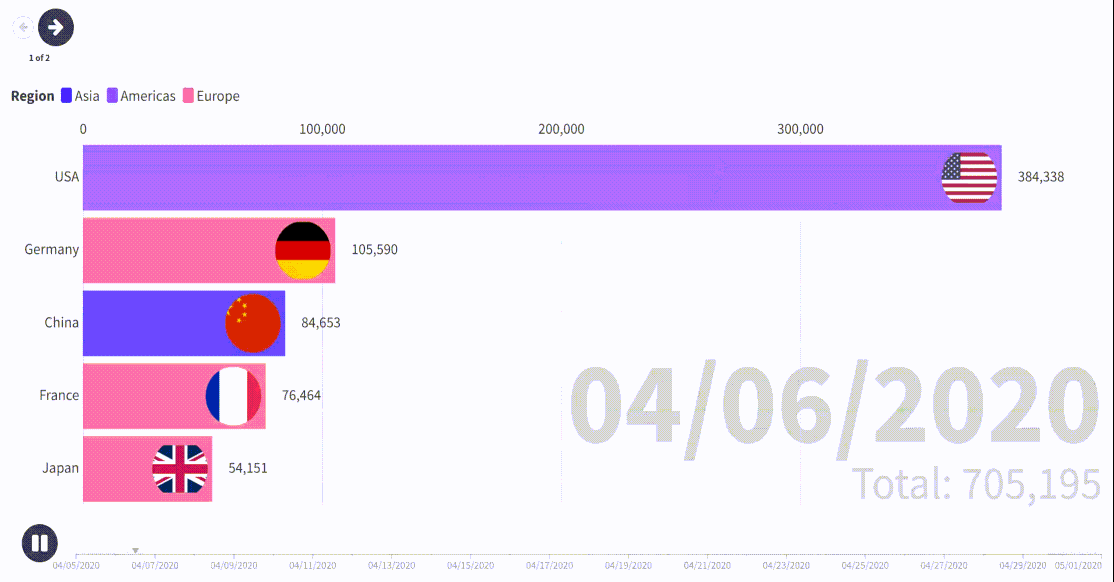
如果只想研究中国某个省、市就把 'Province_State': ['Shanghai'],改成其他地方拼音即可,这里数据最小行政单元就是省、市;
完整代码#运行环境 Python 3.11
import os
import pandas as pd
def process_csv_files(folder_path):
# 创建一个空DataFrame来存储汇总结果
summary_df = pd.DataFrame(columns=['Date', 'Country_Region', 'Province_State', 'Confirmed', 'Deaths'])
# 遍历文件夹中的所有CSV文件
for filename in os.listdir(folder_path):
if filename.endswith('.csv'):
# 提取文件名中的日期
date = filename.split('.')[0].replace('-', '/')
# 读取CSV文件
file_path = os.path.join(folder_path, filename)
df = pd.read_csv(file_path)
# 检查列名
column_names = df.columns.tolist()
# 如果存在Country_Region和Province_State列,则进行筛选
if 'Country_Region' in column_names and 'Province_State' in column_names:
# 筛选Country_Region为中国的数据
china_df = df[(df['Country_Region'] == 'China') & (df['Province_State'] == 'Shanghai')]
# 计算Confirmed和Deaths的汇总值
confirmed_sum = china_df['Confirmed'].sum()
deaths_sum = china_df['Deaths'].sum()
# 将结果添加到summary_df中
new_row = pd.DataFrame({
'Date': [date],
'Country_Region': ['China'],
'Province_State': ['Shanghai'],
'Confirmed': [confirmed_sum],
'Deaths': [deaths_sum]
})
summary_df = pd.concat([summary_df, new_row], ignore_index=True)
# 输出汇总结果
summary_df.to_csv(os.path.join(folder_path, 'shanghai_confirmed_deaths_summary.csv'), index=False)
print("Summary CSV file has been created.")
# 调用函数
process_csv_files('D:\\Data\\COVID-19-master\\csse_covid_19_data\\csse_covid_19_daily_reports')
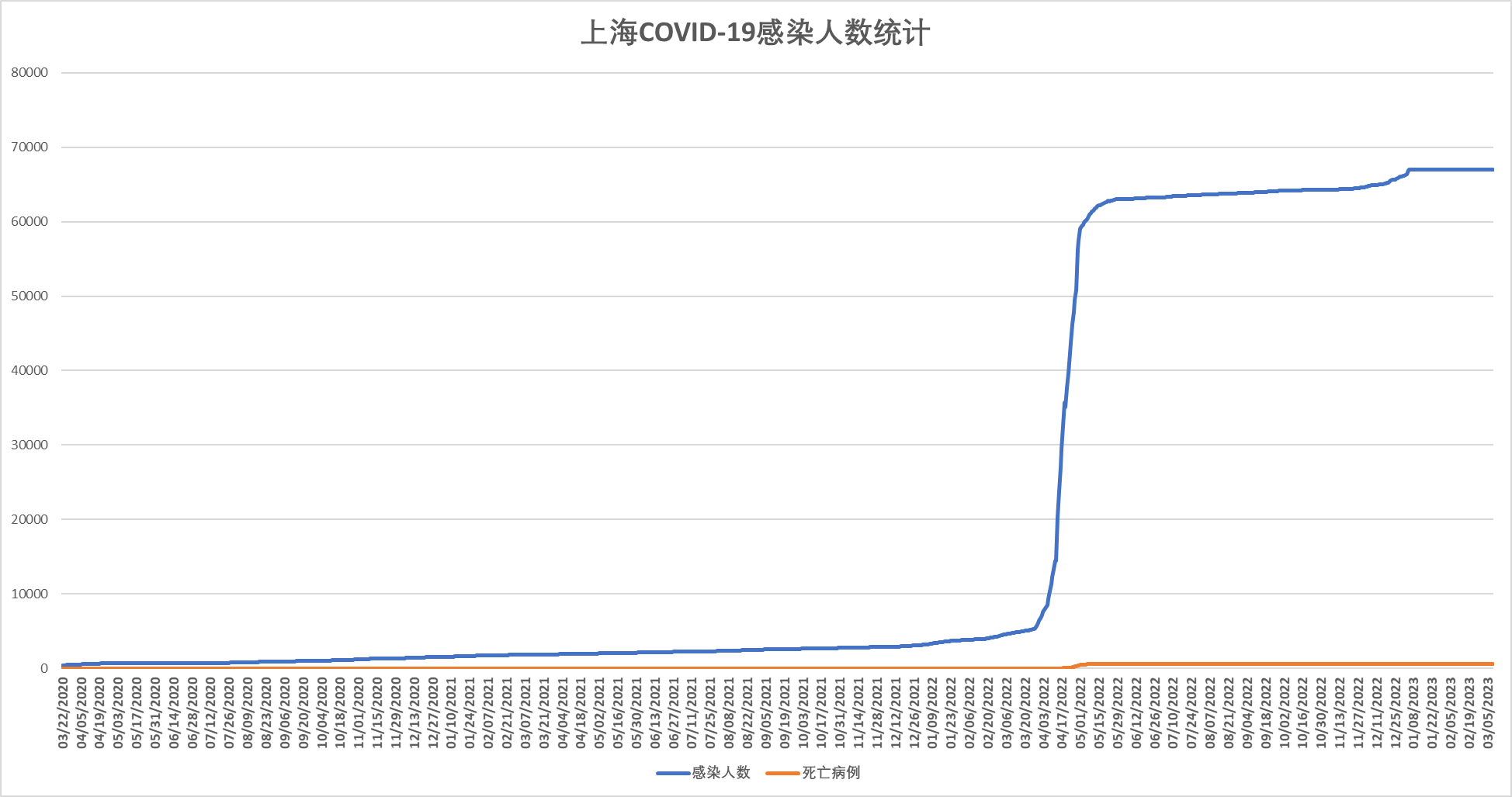
这里我们还是把视角放在上海这个经历过封城的城市,纵观整个统计时间线,上海的COVID-19感染人数经历了如下变化:
-
初期(2020年3月至2021年2月):感染人数保持稳定,处于较低水平,反映出当时的疫情防控效果良好。
-
2021年3月至2022年初:尽管感染人数稍有起伏,但整体仍然在可控范围内,证明了防控措施的有效性。
-
2022年3月起:感染人数突然飙升,尤其是3月底至4月初达到峰值,这可能与奥密克戎变异株的传播直接关联,导致了新一波疫情的发生。
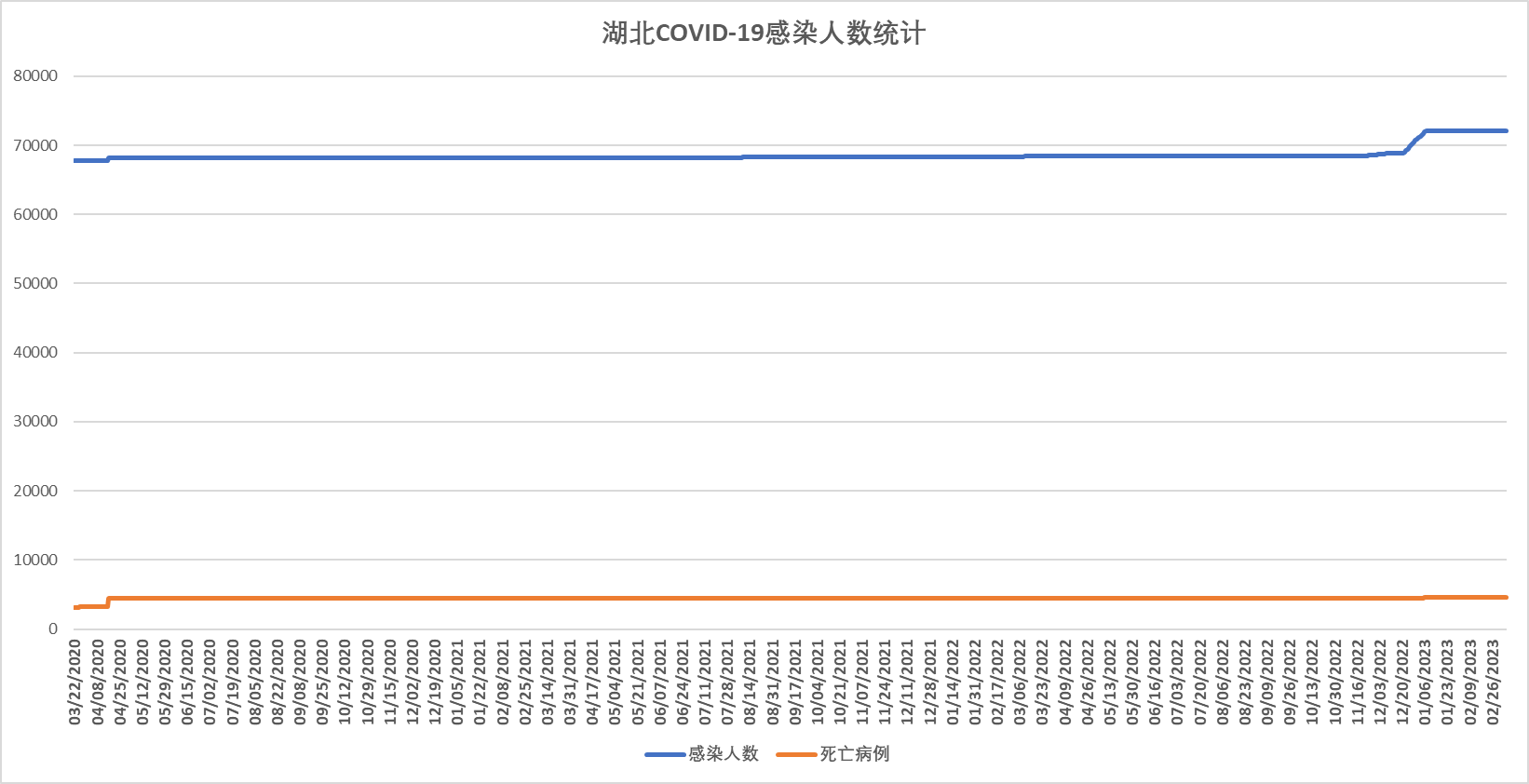
对比同时期COVID-19最先开始大面积传播的湖北省,当地的感染人数就很多,感染人数总体上呈现波动上升的趋势;
总结
-
全球 COVID-19 疫情趋势分析:
- 通过对约翰斯·霍普金斯大学提供的全球 COVID-19 数据进行汇总分析,可以看出不同国家在疫情不同阶段的确诊病例数和死亡人数的变化趋势。例如,中法美英德五国在同一时期的感染人数累计动态可视化图展示了各国疫情的发展情况及其控制措施的效果。
-
上海地区 COVID-19 疫情发展特点:
- 上海作为中国的一个重要城市,在疫情期间采取了一系列严格的防控措施。通过对上海地区 COVID-19 数据的分析,可以看出该地区疫情的发展趋势,尤其是在经历了封城等措施后,疫情得到了有效控制。与湖北省相比,上海的感染人数明显较少,反映了不同地区采取的不同防控策略的影响。
文章仅用于分享个人学习成果与个人存档之用,分享知识,如有侵权,请联系作者进行删除。所有信息均基于作者的个人理解和经验,不代表任何官方立场或权威解读。


















 4717
4717

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











