







随着新零售业态的快速发展,门店位置信息的获取变得越来越重要。作为知名中式餐饮品牌之一,捞王锅物料理自2009年创立以来,始终致力于为消费者提供高品质的锅物料理与贴心的服务体验。经过多年的发展,捞王在全国范围内不断拓展门店网络,目前已覆盖多个一、二线城市,形成了较为完善的线下服务体系。为了更好地理解和利用这些门店数据,本文将深入探讨GET请求的实际应用,并展示如何通过Python的requests库发送GET请求,从捞王锅物料理官方网站获取详细的门店位置信息,包括全国范围内的所有捞王门店信息。
本文将以爬取官网中的门店信息页面为例,介绍如何解析网页结构、构造合适的请求、处理响应数据,并最终实现数据可视化,展示捞王锅物料理在我国各地区的分布情况。
捞王锅物料理官方网址:门店-门店-捞王(上海)餐饮管理有限公司
首先,在浏览器开发者工具中查看“Network”面板下的“Fetch/XHR”请求时,我们发现其门店信息页面并未使用AJAX或Fetch API进行动态加载,而是直接将门店信息嵌入在HTML源码中。这意味着该页面的数据属于静态内容,可以通过直接解析HTML的方式获取所需信息,无需模拟异步请求或使用Selenium等自动化工具。
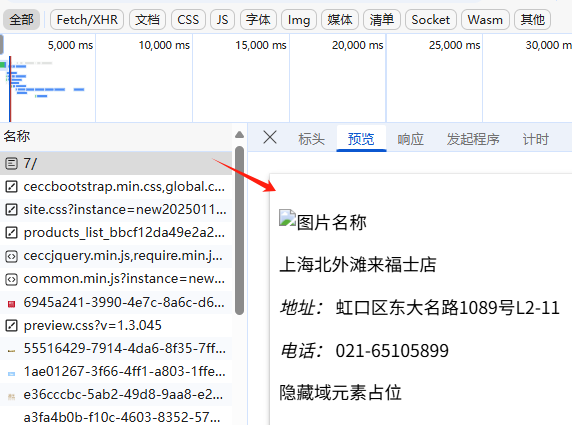
那我们需要调整一下策略,我们第一步先找到门店数据的存储HTML位置,然后再看3个关键部分标头、负载、 预览;
标头:通常包括URL的连接,也就是目标资源的位置;
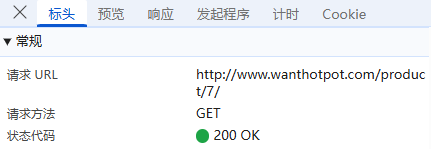
负载:对于GET请求:负载通常包含了传递的参数,有些网页负载可能为空,或者没有负载,比如捞王锅物料理门店网址这里就没有负载;
预览:指的是对响应内容的快速查看或摘要显示,可以帮助用户快速了解返回的数据结构或内容片段;
接下来就是数据获取部分,先讲一下方法思路,一共三个步骤;
方法思路
- 找到对应数据存储位置,读取整个HTML,识别关键字段存储特征;
- 获取所有店铺列表的相关标签数据,另存为csv;
- 坐标系转换,通过coord-convert库实现 GCJ-02转WGS84;
第一步:通过页面测试发现,我们发现,一个城市对应一个页面,对应一个html,不同的之处在于城市编码,比如上海就是对应的7,江苏对应的是8之类的,我们先手动获取所有城市不同编码;

接下来,我们先找到对应数据存储位置,获取所有店铺列表和数据标签,我们可以看到,数据结构是包含门店名称、地址、电话接下来,我们就通过脚本来读取整个HTML;

第二步:利用GET请求获取所有店铺列表,并根据标签进行保存,另存为csv;
完整代码#运行环境 Python 3.11
import requests
from bs4 import BeautifulSoup
import re
import time
import csv
import os
from datetime import datetime
def get_store_info(product_id):
# 设置请求URL
url = f"http://www.wanthotpot.com/product/{product_id}/"
# 设置请求头
headers = {
'User-Agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/136.0.0.0 Mobile Safari/537.36 Edg/136.0.0.0'
}
try:
# 发送GET请求
response = requests.get(url, headers=headers)
# 使用BeautifulSoup解析HTML
soup = BeautifulSoup(response.text, 'html.parser')
# 查找所有店铺信息div
store_divs = soup.find_all('div', class_='cbox-8-1 p_item')
# 存储所有店铺信息
stores = []
# 遍历每个店铺div
for store_div in store_divs:
store_info = {}
# 获取店名
name = store_div.find('p', class_='e_text-4 s_summary')
if name:
store_info['店名'] = name.text.strip()
# 获取地址
address = store_div.find('p', class_='e_text-6 s_summary')
if address:
# 使用正则表达式提取地址文本
address_text = re.sub(r'地址:', '', address.text.strip())
store_info['地址'] = address_text.strip()
# 获取电话
phone = store_div.find('p', class_='e_text-7 s_summary')
if phone:
# 使用正则表达式提取电话文本
phone_text = re.sub(r'电话:', '', phone.text.strip())
store_info['电话'] = phone_text.strip()
stores.append(store_info)
# 打印所有店铺信息
print(f"\n产品ID {product_id} 的店铺信息:")
for i, store in enumerate(stores, 1):
print(f"\n店铺 {i}:")
print(f"店名: {store.get('店名', 'N/A')}")
print(f"地址: {store.get('地址', 'N/A')}")
print(f"电话: {store.get('电话', 'N/A')}")
return stores
except Exception as e:
print(f"请求产品ID {product_id} 时出错: {str(e)}")
return []
def append_to_csv(product_id, stores, csv_file):
# 如果文件不存在,创建文件并写入表头
file_exists = os.path.exists(csv_file)
with open(csv_file, 'a', newline='', encoding='utf-8-sig') as f:
writer = csv.writer(f)
# 如果文件不存在,写入表头
if not file_exists:
writer.writerow(['产品ID', '店名', '地址', '电话'])
# 写入数据
for store in stores:
writer.writerow([
product_id,
store.get('店名', 'N/A'),
store.get('地址', 'N/A'),
store.get('电话', 'N/A')
])
def main():
# 要遍历的产品ID列表
product_ids = [7, 8, 9, 10, 11, 14, 16, 24, 44, 46, 63, 65]
# 指定保存路径(保存到桌面)
output_dir = os.path.join(os.path.expanduser("~"), "Desktop", "店铺数据")
if not os.path.exists(output_dir):
os.makedirs(output_dir)
# 生成带时间戳的文件名
timestamp = datetime.now().strftime("%Y%m%d_%H%M%S")
csv_file = os.path.join(output_dir, f"店铺信息_{timestamp}.csv")
# 打印完整的保存路径
print(f"数据将保存到文件: {csv_file}")
# 遍历每个产品ID
for product_id in product_ids:
print(f"\n正在获取产品ID {product_id} 的信息...")
stores = get_store_info(product_id)
# 立即将数据写入CSV文件
append_to_csv(product_id, stores, csv_file)
print(f"产品ID {product_id} 的数据已保存到CSV文件")
# 添加延时,避免请求过于频繁
time.sleep(2)
print(f"\n所有数据已保存到文件: {csv_file}")
print(f"文件完整路径: {os.path.abspath(csv_file)}")
if __name__ == "__main__":
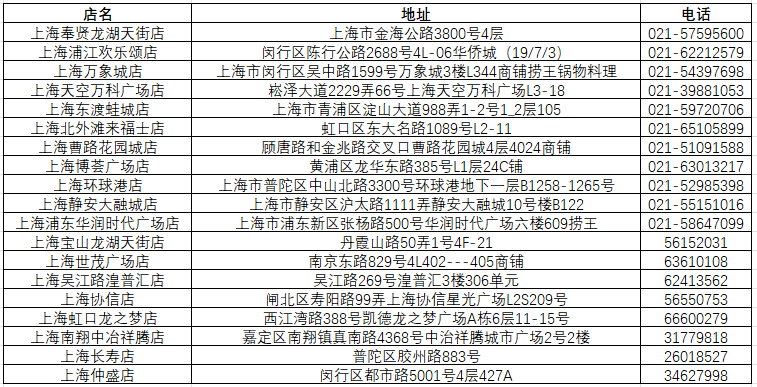
main()数据会以csv表格的形式,保存在运行脚本的目录下,数据标签包括:店铺名称、详细地址、电话;
第三步:地理编码和坐标系转换,这里因为数据标签没有直接的坐标数据,需要把获取的门店地址进行地理编码,具体实现方法可以参考我这篇文章:地址转坐标:利用高德API进行批量地理编码_高德地图api-CSDN博客;
这里直接下载转换结果,坐标系GCJ-02,当然还有个别地址描述太模糊的或者格式无法识别,会查不出坐标,手动查一下坐标即可,大部分还是可以查到的,因为当前坐标系是GCJ02,需要批量转成WGS84/BD09的话可以用免费这个网站:批量转换工具:地图坐标系批量转换 - 免费在线工具 (latlongconverter.online),也可以通过coord-convert库实现GCJ-02转WGS84;
对CSV文件中的服务网点坐标列进行转换。完成坐标转换后,再将数据导入ArcGIS进行可视化;
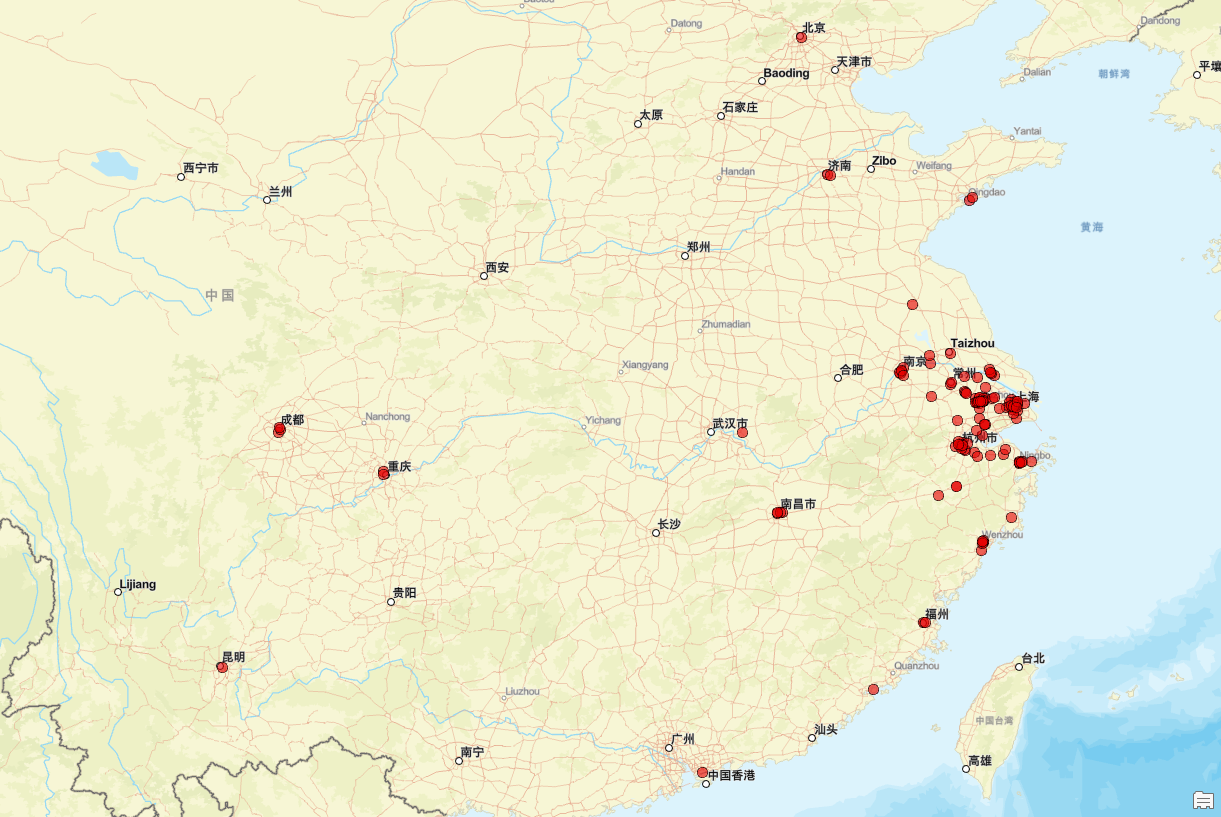
接下来,我们进行看图说话:
城市层级分布:
- 一、二线城市为核心:捞王锅物料理主要集中在经济发达、人口密集的一、二线城市,如上海、北京、广州、深圳、杭州、南京和成都等。这些城市拥有较高的消费能力和对高品质餐饮的需求,为捞王提供了良好的市场基础。
- 向强三线城市扩展:近年来,随着品牌影响力的增强及市场策略的调整,捞王开始逐步向一些消费能力较强且饮食文化多元化的强三线城市进行拓展。这不仅有助于品牌的进一步扩大,也能满足更多消费者对于高品质餐饮体验的需求。
商圈选址偏好:
- 核心商圈与购物中心:捞王门店多位于城市的商业中心区或大型购物中心内,这类位置人流量大,能有效吸引顾客前来就餐。
- 注重可视性与交通便利性:为了提升品牌形象并方便顾客到达,捞王通常会选择在商场中高层(例如3-4层)开设门店,并确保店铺具有良好的可视性和便捷的交通条件,以此打造独特的“目的地型”就餐体验。
门店密度与区域集中度:
- 华东地区为大本营:作为捞王的发展起源地,华东地区的门店密度最高,尤其是在上海,这里不仅是捞王的品牌发源地,也是其最为重要的市场之一。
- 华南、华北、华中等地加速布局:除了华东地区外,捞王还在华南、华北、华中等多个区域加快了开店速度,逐渐形成了一定的区域集中效应。通过这种战略布局,捞王旨在实现全国范围内的均衡发展,同时巩固和扩大其市场份额。
文章仅用于分享个人学习成果与个人存档之用,分享知识,如有侵权,请联系作者进行删除。所有信息均基于作者的个人理解和经验,不代表任何官方立场或权威解读。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











