










简介:我这段时间新进了一家医疗公司,为了测试的质量和效率能提升,我们需要做GUI自动化测试,碰到的第一个拦路虎就是登录时的验证码,本来我是叫开发帮忙在测试环境去掉,线上环境再加上,但是开发觉得麻烦,说为了测试的完整性,不能去掉,让我们测试自己想方法,所以就出现了我们测试人员进行验证码的分析和解决验证码问题。
目的:解决GUI自动化碰到的登录图文验证问题
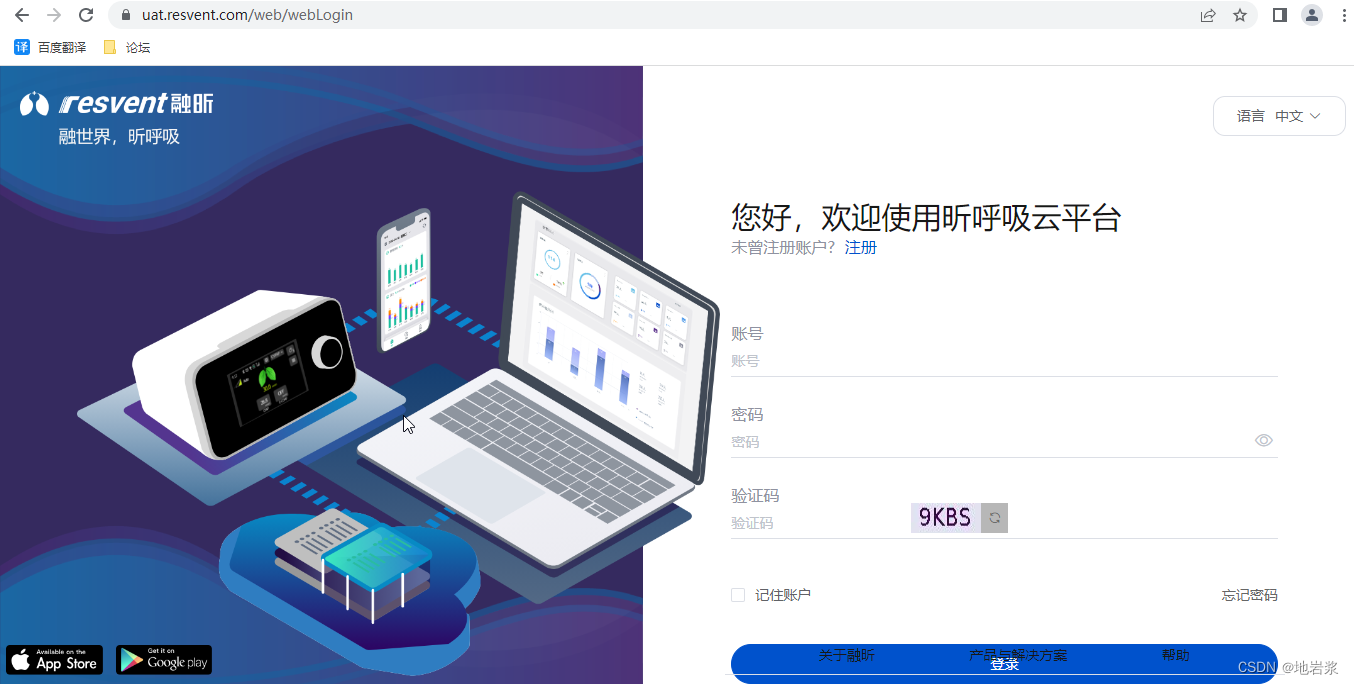
首先要进行验证码图文验证,首先要下载ocr模块,cmd命令行命令如下:
pip install ddddocr -i https://pypi.tuna.tsinghua.edu.cn/simple
思路: 通过元素分析,我们可以看到,验证码是一张img图片,地址就放在验证码元素的src属性上。
所以我们可以使用元素的.get_property("src")获取验证码地址,使用urllib.request.urlretrieve把在线验证码图片下载下来,使用ocr的classification方法识别图片上的数字。下面有具体的代码供参考。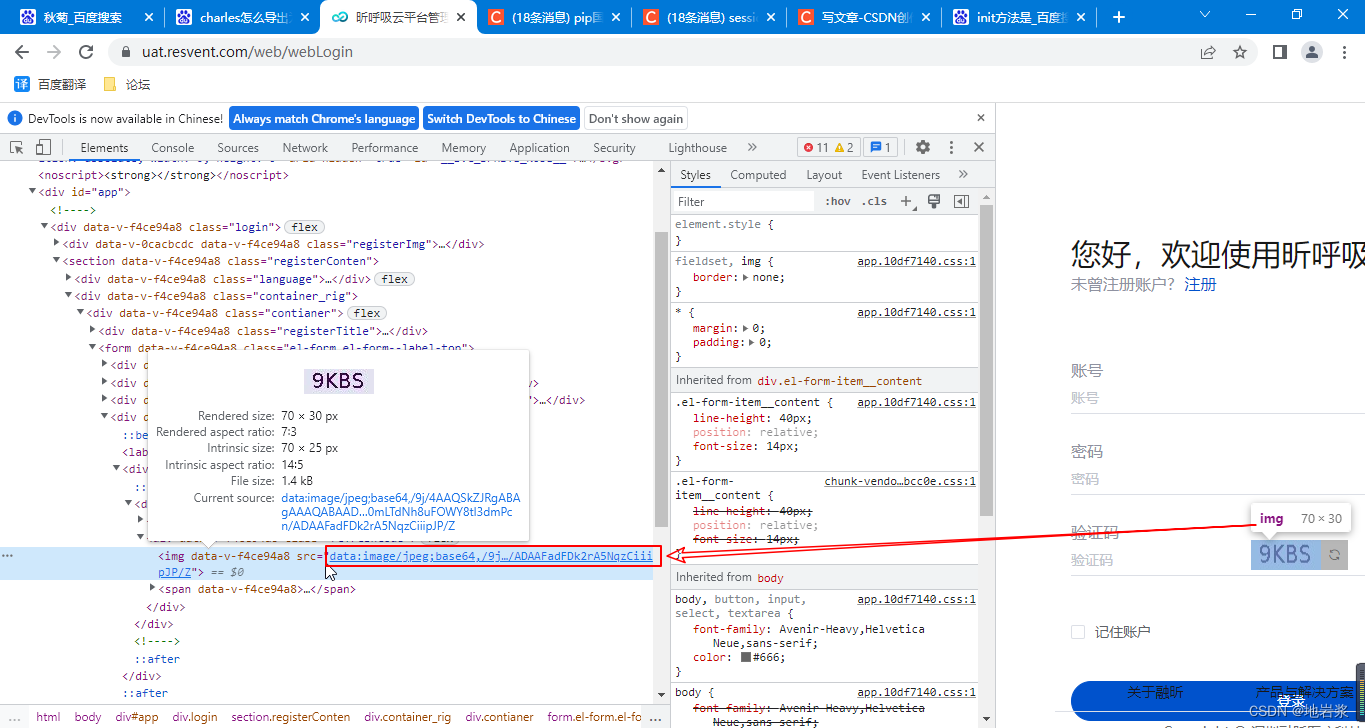
1,初始化方法;
我们的类初始化用于获取驱动,进入登录页面,由于登录页面只有一个页面,所以我们使用了隐式等待
def __init__(self):
self.driver = webdriver.Chrome()
self.driver.get('http://uat.resvent.com/web/homePage')
self.driver.implicitly_wait(10)2,登录方法;
①获取验证码元素
②根据验证码元素,获取验证码的地址(地址放在了src里面)
③使用urllib.request.urlretrieve将image_url的网络对象复制道本地文件上,第一个参数是url,第二个参数是文件名称
④获取ocr对象
⑤使用ocr的classification方法识别验证码内容
def login(self):
#1,获取验证码元素
img = self.driver.find_element_by_xpath('//*[@id="app"]/div/section/div[2]/div/form/div[4]/div/div/div[2]/img')
#2,根据验证码元素,获取验证码的地址(地址放在了src里面)
image_url = img.get_property('src')
#3,使用urllib.request.urlretrieve将image_url的网络对象复制道本地文件上,第一个参数是url,第二个参数是文件名称
urllib.request.urlretrieve(image_url,'yanzhengma.png')
#4,获取ocr对象
ocr = ddddocr.DdddOcr()
#5,使用ocr的classification方法识别验证码内容
with open('yanzhengma.png', 'rb') as f:
img_bytes = f.read()
res = ocr.classification(img_bytes)
print("验证码是: "+res)
self.driver.find_element_by_xpath('//*[@id="app"]/div/section/div[2]/div/form/div[1]/div/div/input').send_keys('songxianrong')
self.driver.find_element_by_xpath('//*[@id="app"]/div/section/div[2]/div/form/div[2]/div/div/input').send_keys('songxianrong')
self.driver.find_element_by_xpath('//*[@id="app"]/div/section/div[2]/div/form/div[4]/div/div/div[1]/input').send_keys(res)
self.driver.find_element_by_xpath('//*[text()="登录"]').click()3,完整的登录类;
以下为完整的python写的GUI页面自动化登录代码
import urllib
from urllib import request
from selenium import webdriver
import ddddocr
# pip install ddddocr -i https://pypi.tuna.tsinghua.edu.cn/simple
class Login():
def __init__(self):#类初始化用于获取驱动,进入登录页面,由于登录页面只有一个页面,所以我们使用了隐士等待
self.driver = webdriver.Chrome()
self.driver.get('http://uat.resvent.com/web/homePage')
self.driver.implicitly_wait(10)
def login(self):
#1,获取验证码元素
img = self.driver.find_element_by_xpath('//*[@id="app"]/div/section/div[2]/div/form/div[4]/div/div/div[2]/img')
#2,根据验证码元素,获取验证码的地址(地址放在了src里面)
image_url = img.get_property('src')
#3,使用urllib.request.urlretrieve将image_url的网络对象复制道本地文件上,第一个参数是url,第二个参数是文件名称
urllib.request.urlretrieve(image_url,'yanzhengma.png')
#4,获取ocr对象
ocr = ddddocr.DdddOcr()
#5,使用ocr的classification方法识别验证码内容
with open('yanzhengma.png', 'rb') as f:
img_bytes = f.read()
res = ocr.classification(img_bytes)
print("验证码是: "+res)
self.driver.find_element_by_xpath('//*[@id="app"]/div/section/div[2]/div/form/div[1]/div/div/input').send_keys('songxianrong')
self.driver.find_element_by_xpath('//*[@id="app"]/div/section/div[2]/div/form/div[2]/div/div/input').send_keys('songxianrong')
self.driver.find_element_by_xpath('//*[@id="app"]/div/section/div[2]/div/form/div[4]/div/div/div[1]/input').send_keys(res)
self.driver.find_element_by_xpath('//*[text()="登录"]').click()
if __name__ == '__main__':
login = Login()
try:
login.login()
except Exception as e:
print("报错了,内容是",e)
finally:
login.driver.quit()
















 279
279











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









