







前置:C++数据结构_树的理论学习笔记(1)_基本概念和基本操作
1.3 存储结构
1.3.1 数的存储结构
基本要求:
①能够存储各结点信息;
②唯一的表示各结点之间的逻辑结构——父子关系
1.双亲表示法
(1)原理:利用一维数组来表示树,一维数组的每个元素表示树的结点,其中包括结点的数据和该结点 的双亲在数组中的下标;数组中的第一个元 素表示根结点,该结点无双亲,因此parent域用-1表示,其他结点按照层序存储.如结点B、 C、D 的双亲结点是下标为0的根结点,其parent域用0表示。

(2)C++描述
template < class T > struct pNode //结点的C++描述
{
T data;
int parent;
};
#define MAXSIZE 1000
pNode< T > Tree[MAXSIZE]; //树的C++描述
int size; //树的总结点数
(3)结点结构:
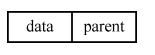
(4) 优点:结构简单,查找结点的双亲或者祖先非常方便
2.孩子表示法
(1)应用时需要查找当前结点的孩子,双亲表示法就会比较复杂。此时为了适应查找孩子结点的需求,可以使用孩子表示法

(2)C++描述
struct CNode //孩子链表结点结构
{
int child; //孩子结点在表头数组中的下标
CNode* next; //指向下一个孩子结点
};
template < class T > struct CBNode //表头结点
{
T data;
CNode* firstchild; //指向第一个孩子结点
};
(3)孩子表示法与双亲表示法正好相反,查找孩子结点很方便,但是查找双亲结点较为复杂
3.多重链表法
(1)原理:多重链表法指每个结点包括一个结点信息域和多个指针域,每个指针域指向该结点的 一个孩子结点,通过各个指针域的值反映出树中各结点之间的逻辑关系。这种表示法中,树中每个结点有多个指针域,从而形成了多条链表。由于每个结点的孩子个数没有限制,各结点的度数又各异,可能会造成存储空间的浪费。例如,一棵度为k的 树,若其结点总数为n,则至少要浪费nk-n+1个空指针域

(2)缺点:不适合存储度数较大的树
4.孩子兄弟表示法
(1)原理:孩子兄弟表示法又称二叉链表表示法,链表中的每个结点包含一个数据域和两个指针域, 其中,数据域用来存储结点数据;第1个指针域指向该结点的第一个孩子结点;第2个指针域指向该结点的第一个右兄弟。

(2)C++描述
template < class T > struct TNode
{
T data;
TNode<T>* firstchild;
TNode<T>* rightsib;
};
(3) 优点:可以将任意复杂的树结构转换成二叉树,这样对树的研究就可以转化为对二叉树的研究,降低了问题的复杂程度
1.3.2 二叉树的存储结构
1.顺序存储结构:
二叉树的顺序存储结构使用一维数组存储二叉树的结点,利用结点的存储位置来表示结点之间的关系。具体如下:
(1)将二叉树按照完全二叉树编号;
(2)其中无结点的位置使用NULL表示,结点则存储在一维数组相应的位置上。如下图所示:

这种存储数据的方法逻辑简单但会造成空间的浪费,因此,该方法最适合存储完全二叉树
2.二叉链表
(1)基本思想如下图所示:

(2)结点结构:
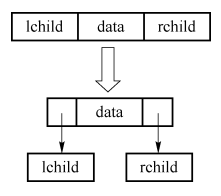
(3)C++描述:
template < class T > struct BiNode
{
T data;
BiNode<T>* lchild;
BiNode<T>* rchild;
};
二叉链表的存储方式和树的孩子兄弟表示法的存储结构完全相同,任何一棵复杂的树都可以容易地使用二叉链表的方式进行存储
3.三叉链表
在二叉链表的存储方式下,从某结点出发可以直接访问到它的孩子结点,但要找到它的双亲,则必须从根结点开始搜索,最坏情况下,可能需要遍历整个二叉链表。所以, 在这种情况下,可以采用三叉链表来存储二叉树,以避免该问题的发生
(1)结构:

(2)结点结构:
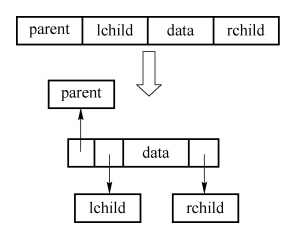
(3)C++描述:
template < class T > struct BiNode
{
T data;
BiNode<T>* parent;
BiNode<T>* lchild;
BiNode<T>* rchild;
};
1.4 二叉树的实现
1.4.1 二叉树的声明
采用二叉链表作为存储结构的二叉树其简单的 C++ 描述如下:
template<class T> class BiTree
{
private:
void Create(BiNode<T>* &R, T data[], int i, int n); //创建二叉树
void Release(BiNode<T>* R); //释放二叉树
public:
BiNode<T>* root; //根结点
BiTree(T data[], int n); //构造函数
void PreOrder(BiNode<T>* R); //前序遍历
void InOrder(BiNode<T>* R); //中序遍历
void PostOrder(BiNode<T>* R); //后序遍历
void LevelOrder(BiNode<T>* R); //层序遍历
~BiTree(); //析构函数
};
1.4.2 二叉树的关键算法
1.二叉树的创建
建立二叉树有很多种方法,其中较为简单的就是使用顺序存储结构来建立二叉链表。以顺序存储结构为输入创建二叉树时,采用先建立根结点,再建立左右孩子的方法递归地建立用二叉链表表示的二叉树,其 C++描述如下:
template<class T>
void BiTree<T>::Create(BiNode <T>*& R, T data[], int i, int n) //i表示位置,从1开始
{
if (i <= n && data[i - 1] != 0)
{
R = new BiNode<T>; //创建根结点
R->data = data[i - 1];
R->lchild = R->rchild = NULL;
Create(R->lchild, data, 2 * i); //创建左子树
Create(R->rchild, data, 2 * i + 1); //创建右子树
}
}
template<class T> BiTree<T>::BiTree(T data[], int n)
{
Create(root, data, 1, n);
}
上述递归程序分解步骤如下,假设输入为下图所示的顺序存储结构表示的二叉树,则递归地建立用二叉链表表示的二叉树示意图如下图所示

2.二叉树前序、中序、后序遍历的实现
由二叉树的前序遍历定义,结合递归,前序遍历的结果如下图所示。
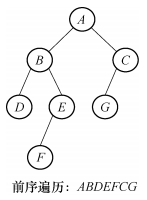
C++算法描述如下:
template<class T>
void BiTree<T>::PreOrder(BiNode<T>* R)
{
if (R != NULL)
{
cout << R->data; //访问结点
PreOrder(R->lchild); //遍历左子树
PreOrder(R->rchild); //遍历右子树
}
}
对于中序遍历,只需要把语句 cout << R->data; 移到语句 PreOrder(R->lchild); 之后即可;
对于后续遍历,只需要把语句 cout << R->data; 移到语句 PreOrder(R->rchild); 之后即可。
3.层序遍历的实现
二叉链表的层序遍历基本思想如下:

具体描述如下:
【1】若根结点非空,入队。
【2】如果队列不空:
【2.1】队头元素出队;
【2.2】访问该元素;
【2.3】若该结点的左孩子非空,则左孩子入队;
【2.4】若该结点的右孩子非空,则右孩子入队。
C++描述如下:
template<class T>
void BiTree<T>::LevelOrder(BiNode<T>* R)
{
BiNode<T>* queue[MAXSIZE];
int f = 0; r = 0; //初始化空队列
if (R != NULL) queue[++r] = R; //根结点入队
while (f != r)
{
BiNode<T>* p = queue[++f]; //表头元素出队
cout << p->data; //出队打印
if (p->lchild != NULL) queue[++r] = p->lchild; //左孩子入队
if (p->rchild != NULL) queue[++r] = p->rchild; //右孩子入队
}
}
4.析构函数的实现
二叉链表属于动态存储分配,因此,需要在析构函数中释放二叉链表的所有结点.为了防止内存泄漏,释放结点时应先释放该结点的左右子树,左右子树全部释放完毕后再释放该结点。采用后序遍历的方法,具体实现如下:
template<class T>
void BiTree<T>::Release(BiNode<T>* R) //释放二叉树
{
if (R != NULL)
{
Release(R->lchild); //释放左子树
Release(R->rchild); //释放右子树
delete R; //释放根结点
}
}
template<class T> BiTree<T>::~BiTree() //释放二叉树
{
Release(root);
}














 179
179











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









