







1.1 基本概念
1.1.1 图的定义
图G由两个集合V和E构成,记作G(V, E),其中,V代表图中顶点的集合,E代表顶点之间的关系。E可以是空集,表示图只有顶点而没有边。
(v1,v2)表示v1和v2之间有一条边(无方向);<v1,v2>表示v1和v2之间有一条弧(有方向)。图的表示方法示例如下图:
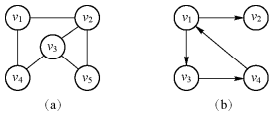
(a)图的表示方法为:V={v1, v2, v3, v4, v5}、E={(v1, v2),(v1, v4),(v2, v3),(v2, v5),(v3,v4),(v3,v5)};
(b)图的表示方法为:V={v1,v2,v3,v4},E={<v1,v2>,<v1,v3>,<v3,v4>,<v4,v1>}
1.1.2 图的基本术语
1.顶点:数据元素常称为顶点;
2.边:顶点之间的无向连线;
3.弧:顶点之间的有向连线;
4.无向图:图中的每条连线都无方向,如下图(a)所示;
5.有向图:图中的每条连线都有方向,如下图(b)所示;
6.简单图:不存在顶点到其自身的边,且同一条边不重复。下图(c)(d)都不是简单图;
7.邻接点:若(vi,vj)是图中的一条边,则vi,vj互为邻接点;若<vi,vj>是图中的一条弧,则vj是vi的邻接点;
8.如下图(e)所示,含有n个顶点,n(n-1)/2条边的图称为完全无向图;如下图(f)所示,含有n个顶点,n(n-1)条弧的图称为完全有向图;
9.边或弧很少的图成为稀疏图,边或弧较多的图称为稠密图。这是相对而言的概念。如下图(g)与(h)相比,(g)是稀疏图,(h)是稠密图;

10.度:一个顶点的度是与他相关联的边或弧的条数;
11.入度:有向图中到达顶点的弧数,下图A的入度为1;
12.出度:有向图中顶点出发的弧数,下图A的出度为2;
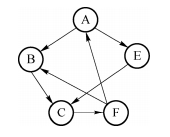
13.网:带权的图,如下图所示,根据网是否有向可以分为有向网和无向网;
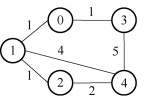
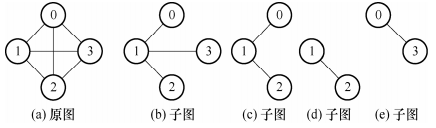
14.图的子集,如下图所示;
15.路径:接续的边的端点构成的顶点序列;
16.路径长度:路径上边或弧的数目;在网中为路径上边或弧的权值之和;下图中v1到v5的路径(v1,v4,v3,v5)的长度为3;
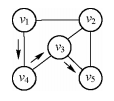
17.回路:起点和终点相同的路径;
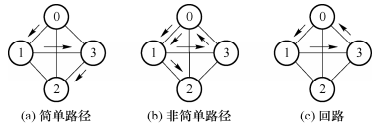
18.简单路径:路径序列中顶点不重复出现的路径,如下图(a)所示;
19.简单回路:路径序列中,除了起点和终点外其余顶点均不相同,如下图(c)所示;
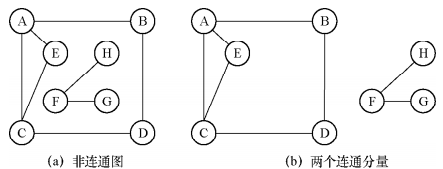
20.连通图:在无向图中,若任意一对顶点都存在路径,则称其为连通图,否则为非连通图;
21.连通分量:无向图中的极大连通子图。极大连通子图包含所有联通的顶点以及和这些顶点相关联的所有边,如下图所示;
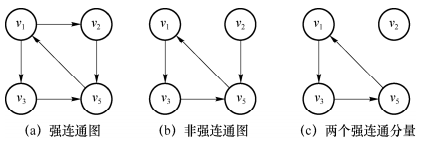
22.强连通图:在有向图中,若任意一对顶点都存在路径,则称其为强连通图,否则为非强连通图;
23.强连通分量:有向图中的最大连通子图,如下图所示;
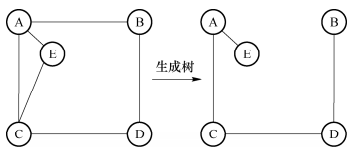
24.生成树:连通图中一个极小连通子图,即含有全部顶点,但只有足以构成树的n-1条边,如下图所示;
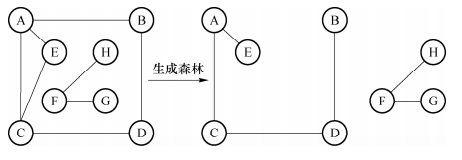
25.生成森林:在非连通图中,每一个连通分量都可以得到一颗生成树,这些连通分量的生成树构成生成森林,如下图所示;
1.2 图的存储结构
图是一种复杂的非线性结构。数据结构中的逻辑结构有集合、线性结构、树结构和图结构。
一个图包括两部分信息:即顶点与顶点之间的关系。
1.2.1 邻接矩阵
二维数组可以用来表示其顶点之间的相邻关系。设G=(V, E)是有n个顶点的图,其序号分别为0,1,2…其邻接矩阵表示为:
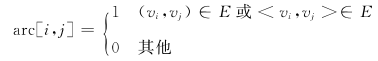
无向图的邻接矩阵一定为对称矩阵,有向图的邻接矩阵可以不对称,如下图所示:

网的邻接矩阵可以定义为:
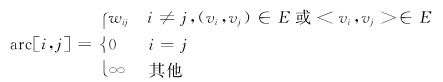
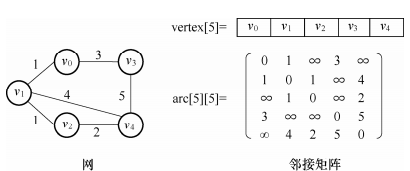
用邻接矩阵表示法,除了存储用于表示顶点间相邻关系的邻接矩阵外,通常还要用一个顺序表来存储顶点信息,其C++描述如下:
const int MAXSIZE = 10;
template<class T> class MGraph
{
public:
MGraph(ifstream& fin); // 构造函数
void DFS(int v); // 从v出发深度优先
void BFS(int v); // 从v出发广度优先
private:
T vertex[MAXSIZE]; // 顶点
int arc[MAXSIZE][MAXSIZE]; //弧
int vNum, arcNum; // 顶点数,边数
};
1.2.2 邻接表
邻接表表示法类似于树的孩子链表表书法,是一种顺序结构和链式结构相结合的存储方法,如下图所示:
邻接表的存储结构中有两种结点结构:顶点结点VertexNode和弧结点ArcNode,如下图所示。

邻接表顶点和弧结点的C++描述如下:
struct VertexNode
{
char vertex; // 数据域:顶点信息
ArcNode* firstarc; // 指针域:指向第一条弧
};
struct ArcNode
{
int adjvex; // 数据域:邻接顶点下标
ArcNode* nextarc; // 指针域:指向下一条弧结点
};
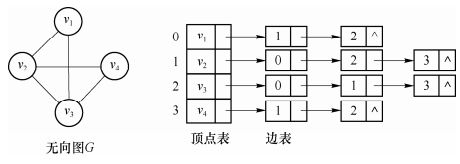
储存无向图时,每一条边都相当于两条弧,如下图所示:
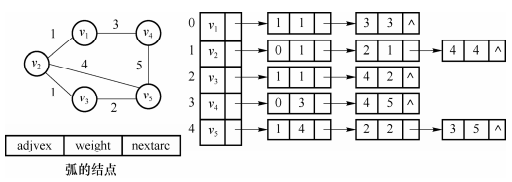
若采用邻接表存储无向网,那么每条弧还需要存储边权值,如下图所示:
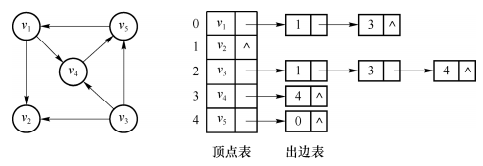
有向图还有一种表示方法为逆邻接表表示法,该方法为图中每个顶点建立一个入边表,入边表中每个表结点均对应一条以该节点为终点的边,如下图所示:
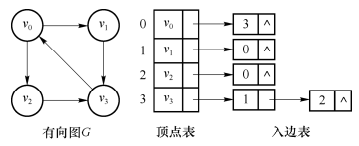
C++描述如下:
const int MAXSIZE = 10;
template<class T> class ALGraph
{
public:
ALraph(ifstream& fin); // 构造函数
~ALGraph();
void DFS(int v); // 深度优先遍历
void BFS(int v); // 广度优先遍历
private:
VertiexNode adjlist[MAXSIZE]; // 结点
int vNum, arcNum; // 顶点数,弧数
};
1.2.3 十字链表
下图是一个十字链表的示例:
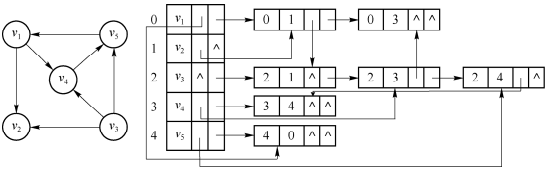
在十字链表中可以很容易找到以某结点为弧头的弧,也很容易找到以某结点为弧尾的弧,因为很容易求得每个结点的出度和入度。
1.2.4 邻接多重表
下图是一个邻接多重表的示例:
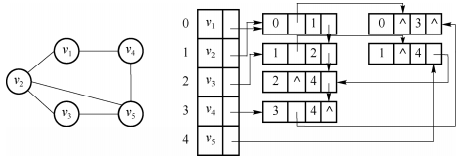
用邻接表存储无向图,其每条边的两个顶点分别在该边所依附的两个顶点边表中。这种重复存储在某些操作时十分不便,例如在对已访问过的边做标记,或者要删除图中某一条边时,都需要找到表示同一条边的两个边表结点,这时使用邻接多重表更适宜。
1.2.5 边集数组
利用两个一维数组,其中一个数组存储图中的顶点,另一个数组存储图中的边,如下图所示:
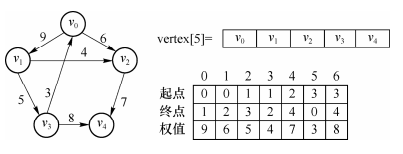
边集数组中查找一条边或求顶点的度需要扫描整个边数组,时间复杂度为O(e),空间复杂度为O(n+e)。因此,边集数组适合表示稀疏图
1.2.6 图的存储结构比较
就空间复杂度而言,采用邻接矩阵需要O(n2)个单位的存储空间,而采用邻接表,则需要O(n+e)个单位的存储空间。哪种表示方法的存储效率高取决于图中边的数目。一般情况下,图越稠密,邻接矩阵的空间效率相应地越高,而对稀疏图使用邻接表存储,则能获得较高的空间效率。















 632
632











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









