







感觉Redis变慢了,这些可能的原因你查了没 ?(上)
Redis 作为一款业内使用率最高的内存数据库,其拥有非常高的性能,单节点的QPS压测能达到18万以上。但也正因此如此,当应用访问 Redis 时,如果发现响应延迟变大时就会给业务带来非常大的影响。
比如在日常使用Redis时,肯定或多或少都遇到过下面这种问题:
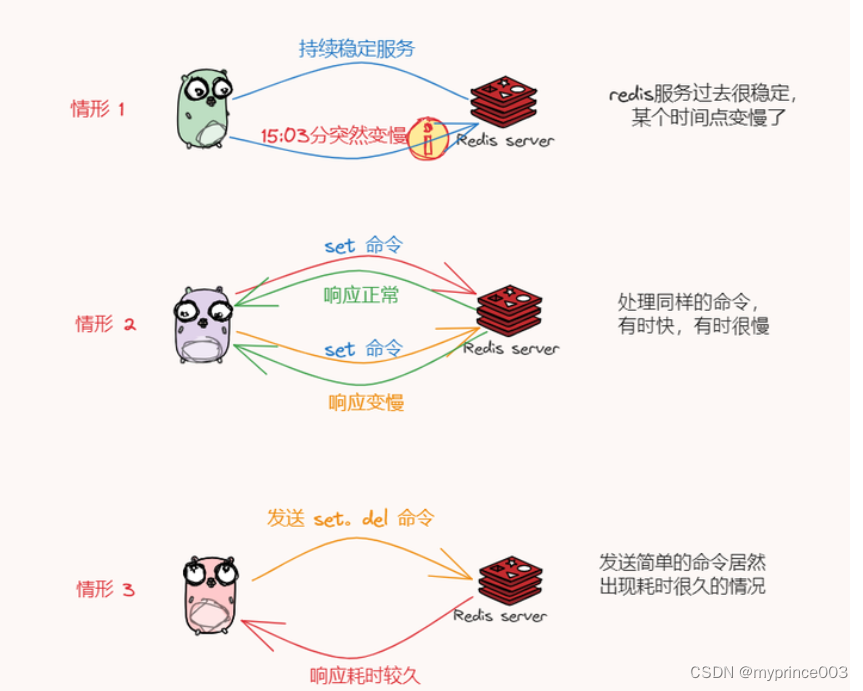
大部分兄弟面对这种访问变慢问题的排查就会一头雾水,不知道从哪里下手才好,因为不理解 Redis 的架构体系、核心功能的实现原理甚至一些命令的使用限制等。
今天就可能引起Redis变慢的原因一一分析,上篇看完后你将会形成一个比较完整的排查思路方案!
Redis真的变慢了吗?
当我们遇到服务响应比较慢时,往往需要先排查内部原因,先弄清楚是不是Redis服务导致的,我们大部分系统可能涉及较长的链路和多服务、比如同一个接口会调用Mysql、MQ、Redis等其他三方组件和服务。
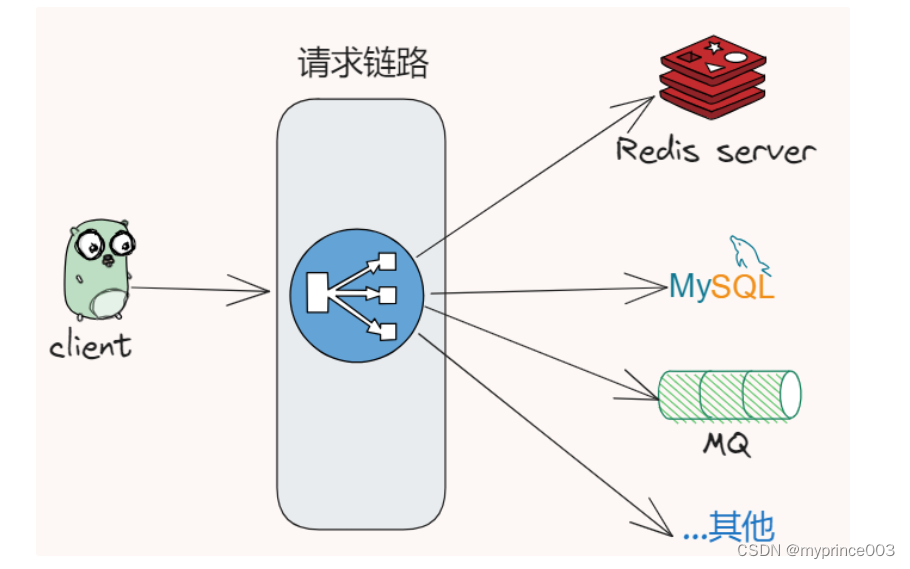
因此需要确定是不是访问Redis服务变慢进而拖慢了整个服务的响应变慢,那就是先自查!🔔
• 应用服务访问Redis的请求,记录下每次请求的响应延时,对比是否响应变长
• 是否其他节点存在同样问题
假设我们确定了是Redis这条链路的问题!(如果不是Redis问题,文章就写不下去啦!!哈哈),这里同样存在两种可能 🤔
• 业务端请求到Redis服务网络是否存在问题,存在网络延迟情况
• Redis服务端本身出现问题,那需要进一步排查
正常来说网络存在问题的可能性还是比较小的,因为如果存在网络问题,那么其他服务同样都会发生网络延迟情况,如果你想了解网络对 Redis 性能的影响,可以用 iPerf 这样的工具,测量从 Redis 客户端到服务器端的网络延迟,如果这个延迟有几十毫秒甚至是几百毫秒,就说明,Redis 运行的网络环境中很可能有大流量的其他应用程序在运行。
好,现在就剩下确定请求Redis的服务响应耗时变长了,也是文章的要讲的焦点问题,分析Redis变慢的原因,先查看Redis的响应延迟,可以对Redis 进行基准性能测试。
基准测试
基准性能就是指 Redis 在一台负载正常的机器上,其最大的响应延迟和平均响应延迟分别是多少
但是这又不能把别人或者官方的测试结果作为参考的指标,因为在不同的软硬件环境下,它的性能表现差别特别大,不同主频型号的CPU、不同的SSD硬盘,都会极大影响Redis的性能表现。
那该以什么标准来认定Redis变慢呢?
🚩🚩一般来说,如果你观察到的 Redis 运行时延迟是其基线性能的 2 倍及以上,就可以认定 Redis 变慢了
比如:执行以下命令,就可以测试出这个实例 60 秒内的最大响应延迟
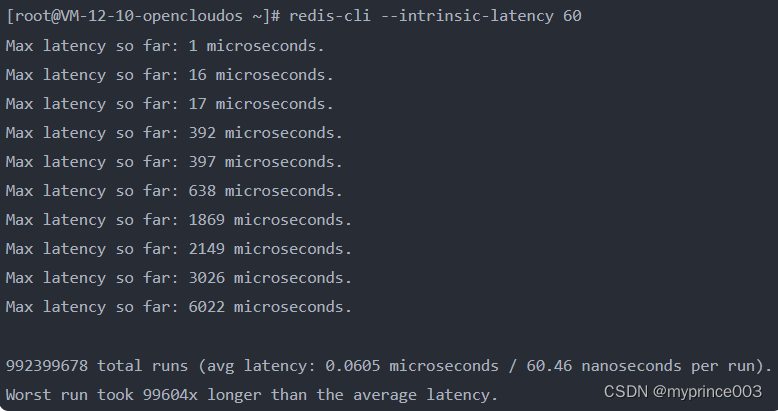
可以看到,此时的基线性能已经达到了 6.022ms,如果响应延时为12ms,那么基本可以认定为Redis变慢了,当然我测试的机器性能比较差,你们可以用自己的机器试试
注意:这个命令只在Redis所在的服务器上运行,避免网络对基线性能的影响,只考虑服务端软硬件环境的影响
到这里已经确定了是Redis服务变慢,那么是哪里变慢了呢,接下来将进行更详细的说明
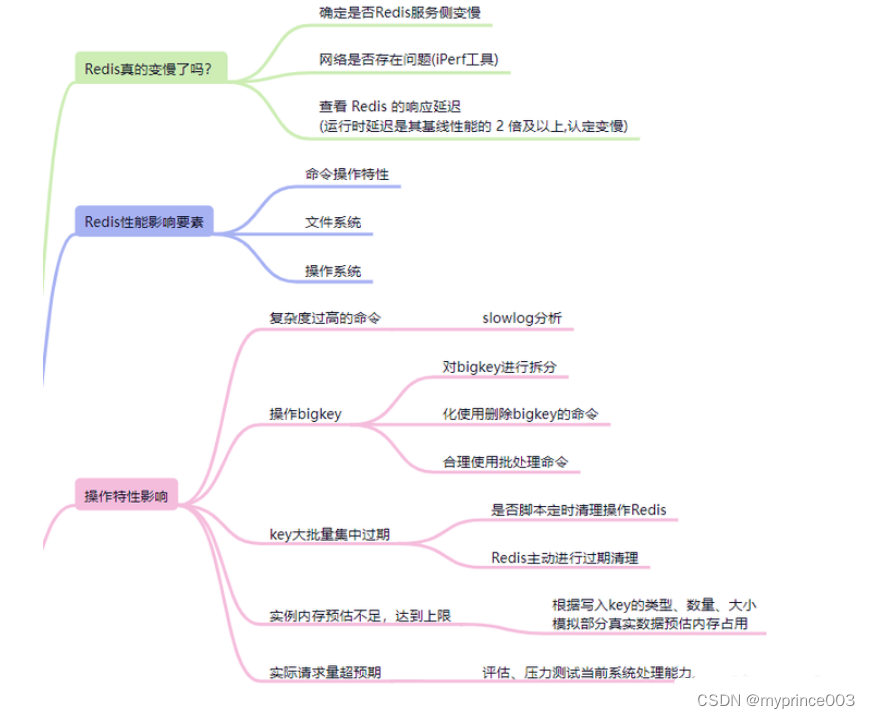
Redis性能影响要素
分析可能影响因素很重要,是判断Redis性能的来源,如下图:
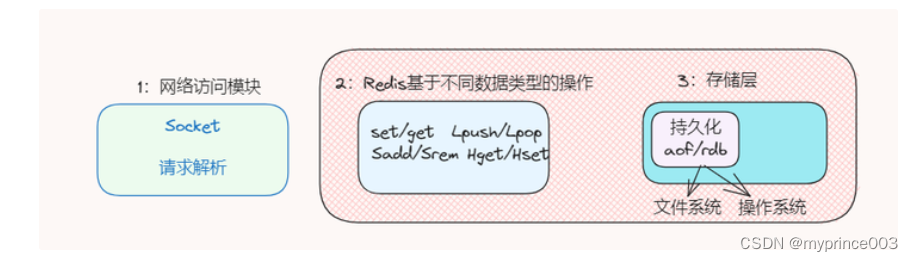
在排除了网络因素之后,可以归纳为Redis自身命令操作、文件系统和操作系统三个大因素可能导致Redis性能存在问题。
接下来的文章将围绕这几个要素出发排查和解决性能影响问题
Redis性能问题分析
慢日志分析
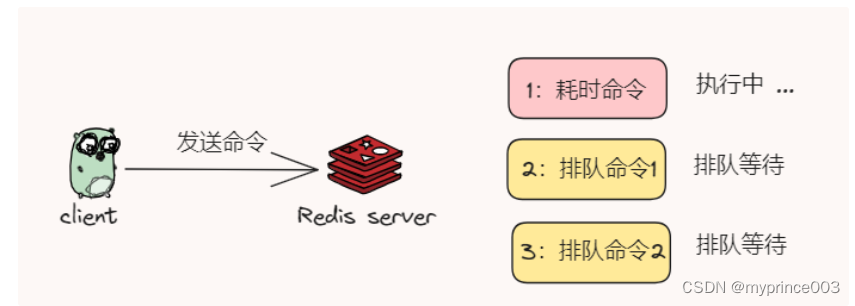
日志是个好东西,分析Mysql是否变慢我们可以通过查看慢日志的,同样的分析Redis慢,同样可以先看是否也存在慢日志 slowlog,这是基础和直观的方式。
Redis 提供的慢日志命令的统计功能,记录了有哪些命令在执行时耗时比较长,快速定位问题。
需要配置的参数:
• slowlog-log-slower-than 配置对执行时间大于多少微秒(microsecond, 1秒=10^6微秒) 的命令进行记录。线上可以设置为1000微秒,也就是1毫秒。
• slowlog-max-len 设置最大考验记录多少条记录。slow log 本身是一个先进先出(FIFO) 队列,当队列大小超过该配置的值时,最旧的一条日志将被删除。线上可以设置为1000以上。
配置如下:
//命令执行耗时超过 10 毫秒,记录慢日志
CONFIG SET slowlog-log-slower-than 10000
//只保留最近 500 条慢日志
CONFIG SET slowlog-max-len 500
我们看下慢日志如何查询
127.0.0.1:6379> SLOWLOG get 3
1) (integer) 32693 # 慢日志ID
2) (integer) 1593763337 # 执行时间戳
3) (integer) 5299 # 执行耗时(微秒)
4) 1) "LRANGE" # 具体执行的命令和参数
2) "user_list:2000"
3) "0"
4) "-1
注意慢日志功能比较粗糙简单,没有持久化记录能力,都是记录在内存中,没有持久化到文件中,所以一般都是设置保留有限的慢命令条数,如果慢命令比较多,会存在不能全部记录的情况
常见集中导致Redis变慢不合理的命令使用方式:
• 获取Redis中的key时,避免使用keys *
• 高频使用了 O(N) 及以上复杂度的命令,例如:SUNION、SORT、ZUNIONSTORE、ZINTERSTORE 聚合类命令
• O(N) 复杂度的命令,但 N 的值非常大,比如:hgetall、smembers、lrange、zrange等命令
这种情况下我们可以将复杂的聚合放在业务端处理,并且每次尽量少获取大量数据
BigKey问题
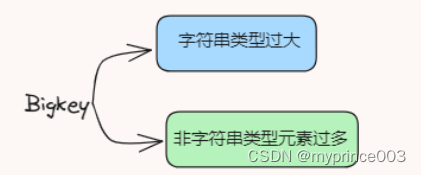
分析慢日志时发现很多请求并不是复杂度高的命令,都是一些del、set、hset等的低复杂度命令,那么就要评估是否写入了大key,也就是BigKey。
Bigkey 是指当 Redis 的字符串类型过大,非字符串类型元素过多 (hash,list,set等存储中value值过多)
bigkey会带来如下问题:

1.数据请求大量超时:
redis是单线程的,当一个key数据响应的久一点,就会造成后续请求频繁超时。如果服务容灾措施考虑得不够,会引发更大的问题。
2.侵占带宽网络拥堵:
当一个key所占空间过大,多次请求就会占用较大的带宽,直接影响服务的正常运行。
3.内存溢出或处理阻塞:
当一个较大的key存在时,持续新增,key所占内存会越来越大,严重时会导致内存数据溢出;当key过期需要删除时,由于数据量过大,可能发生主库较响应时间过长,主从数据同步异常(删除掉的数据,从库还在使用)。
此时我们可以回想和检查业务代码,查看是否存在写入bigkey的情况,评估好单个key的数据大小,避免存在过大数据。
除了代码自查之外,可以使用命令查,如下:
# redis-cli -h 127.0.0.1 -p 6379 --bigkeys
-------- summary -------
Sampled 15 keys in the keyspace!
Total key length in bytes is 162 (avg len 10.80)
//最大的数据值
Biggest string found 'page4:20230921' has 12304 bytes
Biggest list found 'article:100' has 8 items
Biggest set found 'union:65:67' has 7 members
Biggest hash found 'page2:20230921' has 2 fields
Biggest zset found 'likeTopList' has 2 members
//平均值
6 strings with 24778 bytes (40.00% of keys, avg size 4129.67)
1 lists with 8 items (06.67% of keys, avg size 8.00)
6 sets with 24 members (40.00% of keys, avg size 4.00)
1 hashs with 2 fields (06.67% of keys, avg size 2.00)
1 zsets with 2 members (06.67% of keys, avg size 2.00)
–i 参数,降低扫描的执行速度,比如 --i 0.1 表示 100 毫秒执行一次,降低扫描过程中对 Redis运行实例的影响。
–bigkeys命令原理解析
Redis 在内部执行了 SCAN 命令,遍历整个实例中所有的 key 然后针对 key 的类型,分别执行 STRLEN、LLEN、HLEN、SCARD、ZCARD 命令,来获取 String 类型的长度、容器类型(List、Hash、Set、ZSet)的元素个数
面对bigkey问题,我们可以这些方面下手去处理:
-
对大Key进行拆分
-
优化使用删除Key的命令,可使用异步删除 unlink 命令删除缓存
-
尽量不写入大Key
-
合理使用批处理命令
key集中过期
不知道大家是否遇到过,在某个时间点Redis突然出现一波延时,而且报慢的,有时候超时还有时间规律
如果出现这种情况,就需要考虑是否存在大量key集中过期的情况,因为大量的key在某个固定时间点集中过期,在这个时间点访问Redis时,就有可能导致延迟增加。
如果出现了这种情况,那么需要从两个方面排查一下:
• 业务逻辑是否有定时任务的脚本程序,定期操作key
• Redis的Key数量出现集中过期清理
程序层面这个我们自己排查就好了,这里主要看下为什么Key数量集中过期,集中过期为啥造成了Redis访问变慢
Redis的Key过期策略是怎样的?
被动过期:只有应用发起访问某个key 时,才判断这个key是否已过期,如果已过期,则从Redis中删除
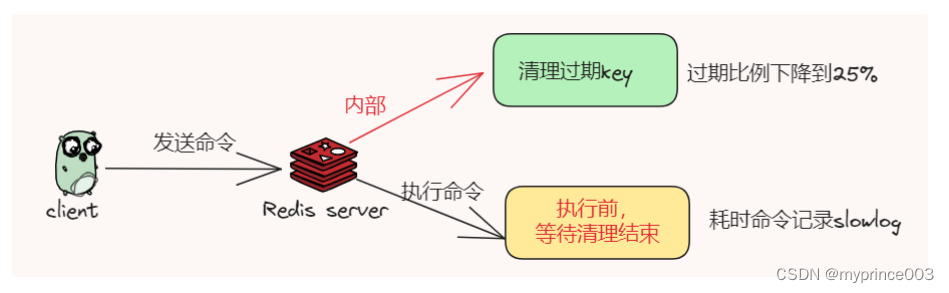
主动过期:在Redis 内部维护了一个定时任务,默认每隔 100 毫秒(1秒10次)从全局的过期哈希表中随机取出 20 个 key,判断然后删除其中过期的 key,如果过期 key 的比例超过了 25%,则继续重复此过程,直到过期 key 的比例下降到 25% 以下,或者这次任务的执行耗时超过了 25 毫秒,才会退出循环
注意,这个主动过期 key 的定时任务,是在 Redis 主线程中执行的
这也是我们主要关注的问题 【主动过期清理】,那为什么会导致Redis延时呢?
因为主动过期是在Redis 主线程中执行的,也就意味着会阻塞正常的请求命令。
进一步说就是如果在执行主动过期的过程中,出现了需要大量删除过期 key 的请求,那么此时应用程序在访问 Redis 时,必须要等待这个过期任务执行结束,Redis 才可以继续处理新请求,这也就是为什么此时访问Redis会突然出现延迟。
即使删除过期key是耗时的,也不会记录在slowlog慢日志中哦!
这里大家估计又有疑惑了,这不是慢了吗?
别急,这是因为slowlog记录的是Redis服务端在命令执行前后计算每条命令的执行时长,而过期清理的时候Redis是登录状态,还不能处理客户端发过来的请求,也就是在命令执行之前进行的。
这种情况我们可以这样处理:
• 业务Key设置过期时间时,加上一个随机过期时间段,比如1分钟
• 通过执行info命令获取过期Key数量【expired_keys】的统计值
• Redis 4.0以上版本,开启 lazy-free 机制,把释放内存的操作放到后台线程中执行,避免阻塞主线程
预估内存不足
我们知道服务器的内存是有限的,这个是既定事实,而且使用Redis时都会配置当前实例可用的最大内存maxmemory和数据自动淘汰策略
maxmemory : 默认为0 不限制。
//获取maxmemory配置的大小
127.0.0.1:6379> config get maxmemory
1) "maxmemory"
2) "0" //默认值是0
//可以在redis.conf中配置
maxmemory 1024mb
当使用的内存达到了 maxmemory 后,即使配置了自动淘汰策略,仍然会在之后每次写入新数据时,操作延迟都会变长。
原因在于,当 Redis 内存达到 maxmemory 后,每次写入新的数据之前,Redis 必须先从实例中踢出一部分数据,让整个实例的内存维持在 maxmemory 之下,然后才能把新数据写进来。
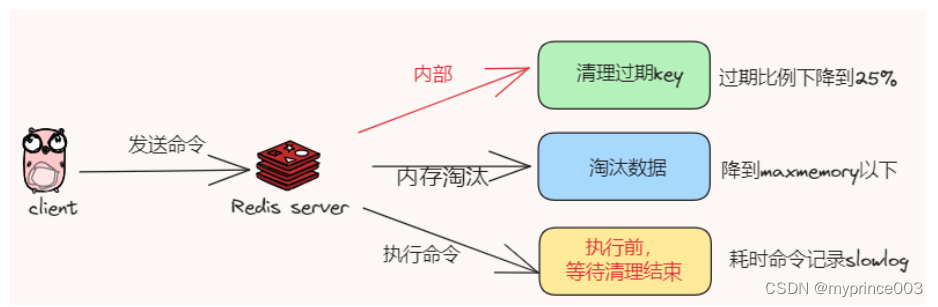
Redis的常用 allkeys-lru / volatile-lru 的淘汰策略
volatile-lru :利用LRU算法移除设置过过期时间的key
allkeys-lru :利用LRU算法移除任何key (和上一个相比,删除的key包括设置过期时间和不设置过期时间的)
Redis采用近似LRU算法,实现逻辑是什么样的?
1:每次从实例中随机选择一个key (样本集),并从样本集中挑选最长时间未使用的 key 淘汰,剩下的放入待淘汰池
2:再次随机获取一批样本集,并与第一步池子的key比较,进而进行淘汰最少访问的key,剩下的放入待淘汰池
3:循环往复上面两个操作步骤,直到实例内存降到maxmemory值为止
假如我们淘汰策略删除的是 bigkey,那么耗时还更久,可想而知 bigkey对Redis的危害应该很大
不过针对内存不足问题,我们也可以进行一个优化措施:
1:避免存储 bigkey,降低释放内存的耗时
2:合理预估内存占用,避免达到内存的使用上限
• 根据写入Key的类型、数量及平均大小计算预估
• 写入一小部分比例的真实业务数据,然后进行预估
3:Redis 4.0 及以上版本,开启 layz-free 机制,把淘汰 key 释放内存的操作放到后台线程中执行
实际请求量超预期
一个系统处理请求是有上限的。Redis虽然处理速度很快,但是也有上限。因此在流量暴增的时候,会比较快达到Redis的处理瓶颈,这个时候整个系统也会变慢,出现slowlog等。
这个现象也比较好观察,可以看看实例的cpu情况,如果持续100%,基本可以判定达到处理上限了。
这种情况最好我们要结合云监控,对CPU使用率、访问的QPS进行监控,发现系统瓶颈,看是否进行扩容和调整。

















 443
443











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











