






决策树损失函数
在学习决策树的过程中,会存在损失函数。损失函数是什么呢?如何理解?
一.决策树的损失函数
为了避免出现过拟合的现象,我们要对决策树进行剪枝。
决策树的剪枝类似一种参数正则化的过程,其选择正则化的参数是树的叶子节点的个数。
设决策树 T 的叶子节点个数为 |T|,t 是树 T 的叶子节点,该叶节点有 Nt 个样本点,其中 k 类的样本点有 Ntk 个,Ht(T) 为叶节点 t 上的经验熵,α⩾0 为正则化系数,则包含剪枝的决策树的损失函数可以定义为:
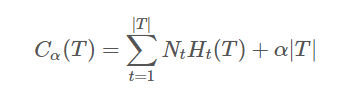
其中,经验熵为:
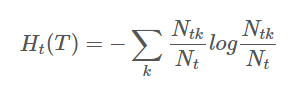
右边第一项表示误差大小,第二项表示模型的复杂度,也就是用叶节点表示,防止过拟化。
损失函数中的第一项表示模型对训练数据的预测误差,也就是模型的拟合程度,第二项表示模型的复杂程度,通过参数 α 控制二者的影响力。一旦 α 确定,那么我们只要选择损失函数最小的模型即可。
二.如何理解
损失函数第一项为什么要乘以Nt呢?
理解1
首先问一个问题,Ht(T)代表的是什么?你肯定会说是经验熵,那什么是经验熵,你肯定会说是不确定度,到这里都没错,那这个不确定度是什么的不确定度呢?
可以理解为,这个叶子节点内部取k个类的不确定度,注意是节点【内部】的不确定度,每个叶子节点可以看作是独立的,既然是内部的事情,凭什么暴力的将各个内部的不确定度相加,我们至少到同一个级别的平台再加吧。
不知道你现在有没有感觉暴力的相加确实少了点什么,我的理解是,少了该节点的样本数,也就是Nt。不知道你有没有注意到,信息熵只用到了概率,而忽略了样本数,也就是只关注内部各个类别的比例,而不在乎整体数量的多少,那么乘以Nt后,我们把它叫做不确定次数,不确定程度就是不确定次数归一化后的东西。
既然都这么暴力了,就更暴力一点,你把Ht(T)理解成频率,Nt*Ht(T)对应地理解成次数吧。比如有A股B股两支股票,A股买了10次,赚了7次,B股买了100次,赚了50次,赚的频率分别是0.7和0.5,那么计算你投资的能力,是0.7+0.5更有意义呢还是7+50更有意义呢?我觉得7+50更有意义吧。
虽然不确定性和不确定次数并非频率和次数,但它们的相对关系就这么理解吧。
理解2
对每个叶节点t来说,Ht(T)表示t的熵(也就是不确定性)的期望,针对的是t子节点中每个数据实例的熵的期望,t子节点中有Nt个实例,那么t子节点总的熵(不确定性)就是NtHt(T),整个树有∣T∣个叶节点,加起来就是整棵树的熵(不确定性,也可以理解成误差)。
可以看出,决策树的构建过程只考虑对于训练数据的拟合,每次特征选择也是考虑局部最优,而剪枝过程则是一个全局优化的过程,剪枝的过程利用验证集进行。














 4294
4294











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









