







SVM损失函数
在机器学习中,SVM(支持向量机)是非常重要的,在处理模型过程中,SVM中在利用损失函数计算经验风险的时候起到了很大的作用,接下来我们来看一下SVM的损失函数。
一、什么是SVM
SVM即支持向量机(Support Vector Machine, SVM) 是一类按监督学习(supervised learning)方式对数据进行二元分类的广义线性分类器(generalized linear classifier),其决策边界是对学习样本求解的最大边距超平面(maximum-margin hyperplane)。
在分类问题中给定输入数据和学习目标:
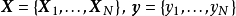
其中输入数据的每个样本都包含多个特征并由此构成特征空间(feature space): ,而学习目标为二元变量 表示负类(negative class)和正类(positive class)。
我们来给个图看一下:

若输入数据所在的特征空间存在作为决策边界(decision boundary)的超平面将学习目标按正类和负类分开,并使任意样本的点到平面距离大于等于1:
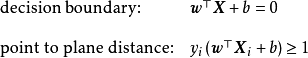
则称该分类问题具有线性可分性,参数 w , b w,b w,b分别为超平面的法向量和截距。
满足该条件的决策边界实际上构造了2个平行的超平面作为间隔边界以判别样本的分类:
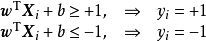
所有在上间隔边界上方的样本属于正类,在下间隔边界下方的样本属于负类。
两个间隔边界的距离 d = 2 / ∣ ∣ w ∣ ∣ d=2/||w|| d=2/∣∣w∣∣被定义为边距(margin),位于间隔边界上的正类和负类样本为支持向量(support vector)。
二、SVM的损失函数
首先我们来看一下什么是损失函数:
定义: 是用来衡量一个预测器在对输入数据进行分类预测时的质量好坏。损失值越小,分类器的效果越好,越能反映输入数据与输出类别标签的关系;相反,损失值越大,我们需要花更多的精力来提升模型的准确率。
1.第一种理解
Hinge Loss 是机器学习领域中的一种损失函数,可用于“最大间隔(max-margin)”分类,其最著名的应用是作为SVM的目标函数。
在二分类的情况下,公式如下:
L(y) = max(0 , 1 – t⋅y)
其中,y是预测值(-1到1之间),t为目标值(1或 -1)。其含义为,y的值在 -1到1之间即可,并不鼓励 |y|>1,即让某个样本能够正确分类就可以了,不鼓励分类器过度自信,当样本与分割线的距离超过1时并不会有任何奖励。目的在于使分类器更专注于整体的分类误差。
变种
在实际应用的时候,一方面,预测值y并不总是属于[-1,1],也可能属于其他的取值范围;另一方面,很多时候我们希望训练的是两个元素之间的相似关系,而非样本的类别得分。
下面公式可能会更为常用:
- L( y, y′) = max( 0, margin – (y–y′) )
-
= max( 0, margin + (y′–y) ) -
= max( 0, margin + y′ – y)
其中,y是正确预测的得分,y′是错误预测的得分,两者的差值可用来表示两种预测结果的相似关系。
margin是一个由自己指定的安全系数。我们希望正确预测的得分高于错误预测的得分,且高出一个边界值 margin,换句话说,y越高越好,y′ 越低越好,(y–y′)越大越好,(y′–y)越小越好,但二者得分之差最多为margin就足够了,差距更大并不会有任何奖励。这样设计的目的在于,对单个样本正确分类只要有margin的把握就足够了,更大的把握则不必要,过分注重单个样本的分类效果反而有可能使整体的分类效果变坏。分类器应该更加专注于整体的分类误差。
优化
hinge loss 函数是凸函数,因此机器学习中很多的凸优化方法同样适用于 hinge loss。
然而,因为 hinge loss 在t⋅y=1的时候导数是不确定的,所以一个平滑版的 hinge loss 函数会更加有助于优化,它由Rennie and Srebro提出:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









