






问题描述:
在hadoop启动hdfs的之后,使用jps命令查看运行情况时发现hdfs的DataNode并没有打开。
笔者出现此情况前曾使用hdfs namenode -format格式化了hdfs
如有三个hadoop集群,分别为hadoop102,hadoop103,hadoop104 其问题情况如下
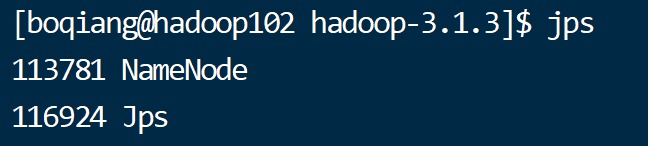

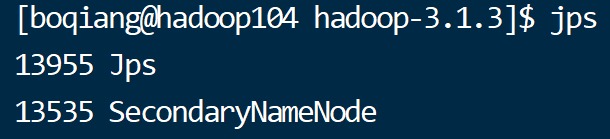
可见三个机器均没有将DataNode启动。
问题分析:
进入hadoop根目录的logs中查看DataNode的日志文件
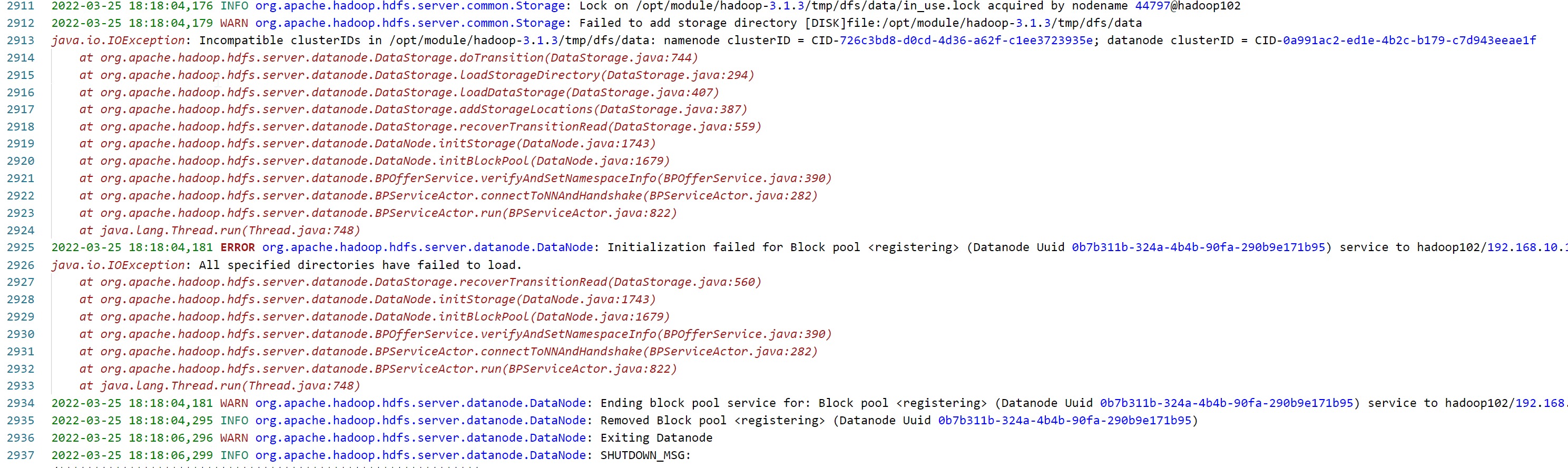
可以看见报错信息
java.io.IOException: Incompatible clusterIDs in /opt/module/hadoop-3.1.3/tmp/dfs/data: namenode clusterID = CID-726c3bd8-d0cd-4d36-a62f-c1ee3723935e; datanode clusterID = CID-0a991ac2-ed1e-4b2c-b179-c7d943eeae1f
这里显示NameNode的clusterID和DataNode的clusterID不一致,所以无法启动DataNode
这种情况可能时因为我们使用hdfs namenode -format的时候仅仅格式化了namenode的clusterID,没有同步格式化DataNode的clusterID。这就导致了二者的clusterID不一致从而无法启动DataNode。
解决方案:
方案一(简单):
删除NameNode所在机器的hadioop根目录etc/hadoop/core-site.xml文件中定义的hadoop.tmp.dir 文件夹。笔者这里设置的时hadoop根目录中的data目录。(有些人设置的时tmp目录,根据自己的配core-site.xml中配置的信息来)
删除NameNode之外的hadoop根目录的data文件夹。
重新格式化hdfs hdfs namenode -format
问题解决!
方案二:
观察刚刚的日志文件,可以知道NameNode的ClusterID为CID-726c3bd8-d0cd-4d36-a62f-c1ee3723935e我们只需要用这个clusterID去替换DataNode文件中的clusterID即可
在NameNode所在机器的hadioop根目录etc/hadoop/core-site.xml文件中定义的hadoop.tmp.dir 文件夹中一直进入到datanode文件中/opt/module/hadoop-3.1.3/tmp/dfs/data/current/VERSION 修改VERSION中的clusterID为刚刚NameNode的clusterID。
在其他机器中,修改data文件夹中的设置/opt/module/hadoop-3.1.3/data/dfs/data/current/VERSION
修改VERSION中的clusterID为刚刚NameNode的clusterID。
问题解决!

















 518
518

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









