



在 Doris 场景里通常有以下几类原因
🧩 一、存储不均匀的常见原因与解决方案
① 分桶(buckets)不合理
-
问题:分桶字段选择不当,导致某些值的数据量特别大(例如按
acct_day分桶,而某几天数据特别多)。 -
现象:部分 BE 存储占用 80%+,其他仅 20%。
-
解决方案:
-
检查表的分桶方式:
SHOW CREATE TABLE db.table_name;优化:
-
若当前是
DISTRIBUTED BY HASH(acct_day) BUCKETS 4,建议改为业务层分布更均衡的字段,例如HASH(device_id)或HASH(user_id)。 -
若使用聚合模型(Aggregate Key),可适度增加 BUCKET 数量(如 16、32、64),再重新导入数据(可使用
INSERT INTO new_table SELECT * FROM old_table)。
-
② Tablet(分片)迁移未完成或失衡
-
Doris 会自动平衡 Tablet,但如果:
-
某些 BE 容量已接近满;
-
集群负载高;
-
tablet_scheduler参数太保守;
则迁移可能停滞。 -
排查:
SHOW PROC '/cluster_balance';或查看:
SHOW PROC '/backends';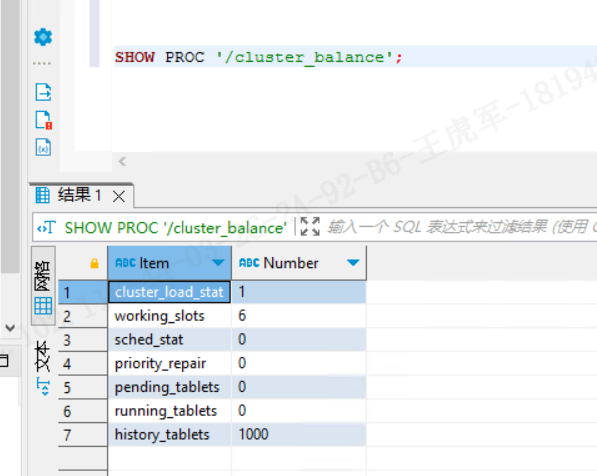
-
字段含义详解
| 字段 | 含义 | 当前值解读 |
|---|---|---|
| cluster_load_stat | 当前集群的负载状态(0 表示空闲,1 表示正在调度) | 1 → 正在执行负载均衡任务(Tablet 迁移中) |
| working_slots | 当前正在执行的平衡任务数量(并发调度线程数) | 6 → 表示目前有 6 个平衡任务同时运行,调度压力较大 |
| sched_stat | 调度状态(0 表示正常,>0 表示异常) | 0 → 调度模块工作正常 ✅ |
| priority_repair | 高优先级修复任务数量(比如副本缺失、损坏) | 0 → 当前没有损坏副本任务 ✅ |
| pending_tablets | 待调度的 Tablet 数量(待迁移、待修复) | 1 → 仅剩 1 个 Tablet 待调度,说明几乎完成均衡 ✅ |
| running_tablets | 当前正在迁移的 Tablet 数量 | 0 → 目前没有迁移任务正在执行,可能刚完成一次调度 ✅ |
| history_tablets | 历史上调度过的 Tablet 数量 | 1000 → 表示曾经平衡过 1000 个 Tablet(正常) |
输出看:
✅ 集群调度器是 健康的,没有出现调度挂死或异常;
⚙️ 系统刚刚或正在进行 少量 rebalance 操作;
⚠️ 但这并不能解释 “存储不均匀 + BE 节点频繁挂” 的根因。
因为这条命令只反映 调度状态,还需要结合 SHOW PROC '/backends'; 才能看出:
-
哪个 BE 存储量明显过高;
-
哪个 BE 经常掉线;
-
数据分布是否极度倾斜。
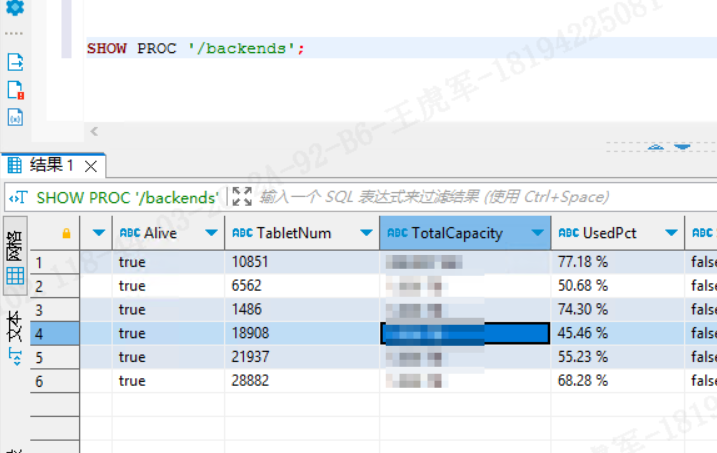
分析:
-
哪些节点磁盘占用高(例如 85%+);
-
哪些节点频繁掉线(Alive=false);
-
是否存在严重的 tablet 不均衡(TabletNum 差异很大);
-
是否需要手动触发 rebalance 或重新分桶建表。
🧠 二、主要问题诊断
✅ 1. Tablet 分布极不均衡
-
Tablet 数量差距:从 1,821 → 29,020,差距约 16 倍。
-
这说明 数据分桶非常不均匀,自动平衡也没能完全修复。
📍可能原因:
-
分桶字段选得不合理(例如按
acct_day或某个低基数字段分桶)。 -
建表时部分 BE 未加入集群或容量不同,导致 Tablet 初始分配倾斜。
-
历史上有节点挂过,自动迁移导致 Tablet 聚集。
⚠️ 2. 磁盘空间差异过大
-
173.11只有 390GB 总容量,而其他节点是 1TB。
这说明你的节点硬件 容量不一致。
Doris 默认 不感知磁盘大小差异,会尝试“均分 Tablet 数量”,不是“均分容量”。
因此小盘节点(173.11、173.13)很容易被写满,最终导致挂掉。
📍典型结果:
-
小盘节点 compaction 时 I/O 压力大;
-
WAL 或 tmp 目录撑爆 → BE 进程崩溃;
-
FE 检测到挂点后触发副本迁移,形成恶性循环。
⚙️ 3. 部分 BE compaction 压力过高
-
173.16Tablet 量最高(29k),磁盘占用高(67%); -
这类节点 compaction 线程持续占用 CPU 与 IO。
📍验证方法:
SHOW PROC '/compactions';
若 running 持续较多或某些表 compaction backlog 高,说明瓶颈在这里。
⚙️ 二、BE 节点频繁宕机的原因与排查
① 内存不足或 OOM
-
现象:BE 日志(
be.INFO)中出现:Memory limit exceeded killed by OOM killer -
排查:
grep -i "oom" be.INFO dmesg | grep -i kill # 1. 检查系统是否因 OOM Killer 杀掉 BE sudo dmesg | grep -i "killed process" # 2. 检查 BE 是否报内存分配错误 grep -iE "Out of memory|std::bad_alloc|Cannot allocate memory" /data/doris/be/log/be.INFO* # 3. 查看 BE 当前的内存使用率 curl http://127.0.0.1:8040/api/metrics | grep memory # 4.更精准地检测 Doris BE 是否出现 OOM grep -iE "Out of memory|Killed process|Cannot allocate memory|std::bad_alloc" be.INFO be.WARNING be.ERROR -
优化方案:
-
调整内存限制(
be.conf):mem_limit = 70%若是查询或导入高峰导致,建议使用 查询并发控制:
SET global exec_mem_limit=4G;② 磁盘 I/O 异常
-
问题:Doris BE 写入磁盘压力大(特别是 Compaction 阶段)。
-
排查:
iostat -x 1 10查看是否存在单盘
%util长时间 100%。 -
优化方案:
-
增加磁盘或采用 RAID10;
-
-
调整 Compaction 参数:
disable_auto_compaction = true然后手动触发:
SHOW PROC '/compactions';
③ 网络波动或心跳超时
-
现象:
fe.warn.log出现:backend heartbeat timeout -
原因:FE <-> BE 心跳包延迟超时(默认 5s)。
-
优化:
-
网络带宽 >= 10Gbps;
-
-
在
fe.conf调整:heartbeat_interval_second = 10
④ Doris 版本 bug 或存储引擎问题
-
某些 Doris 版本(尤其是 1.2.x 早期)存在 TabletMeta 或 Compaction 崩溃 bug。
-
建议:
-
升级至 Apache Doris 2.1+(推荐 2.1.6 或更高);
-
并执行:
ADMIN SHOW FRONTENDS; ADMIN SHOW BACKENDS;
-
🔧 三、建议的诊断命令组合
| 目标 | 命令 |
|---|---|
| 查看节点状态 | SHOW PROC '/backends'; |
| 查看负载均衡情况 | SHOW PROC '/cluster_balance'; |
| 查看磁盘使用 | SHOW PROC '/disks'; |
| 查看 Compaction 状态 | SHOW PROC '/compactions'; |
| 查看内存情况 | curl http://BE_IP:8040/api/show_proc?path=/mem_tracker |
🧠 四、自动检测脚本的实现
自动检测 Doris 集群负载不均衡 的 SQL 脚本,用来定时监控(比如通过 Crontab 执行),如果发现有节点存储使用率过高或 Tablet 分布过于倾斜,就触发报警(例如打印告警信息或写入日志表)。
🧩 一、核心思路
监控的关键指标来自:
SHOW PROC '/backends';
我们只需要从中提取以下列进行分析:
-
Host -
TabletNum -
CapacityUsedPct -
Alive -
DataUsedCapacity -
TotalCapacity
然后计算:
-
存储占用方差(判断空间不均)
-
Tablet 数量方差(判断分片不均)
-
离线节点(Alive = false)
一旦满足如下任意条件,即触发报警:
| 条件 | 含义 |
|---|---|
max(CapacityUsedPct) - min(CapacityUsedPct) > 30 | 存储空间差距超过 30% |
max(TabletNum) / min(TabletNum) > 3 | tablet 分布差距超过 3 倍 |
存在 Alive = false 节点 | 节点掉线 |
max(CapacityUsedPct) > 85 | 某节点磁盘使用超过 85% |
🧠 二、SQL 检测脚本(适合在 FE 控制台或定时任务中执行)
-- Doris 集群节点负载检测脚本
-- 执行方式:在 FE 上运行,或用 MySQL 客户端连接执行
-- 建议配合 cron 每隔 30 分钟执行一次
WITH backend_stats AS (
SELECT
BackendId,
Host,
Alive,
TabletNum,
CAST(SPLIT_PART(CapacityUsedPct, ' ', 1) AS DOUBLE) AS used_pct
FROM
(SHOW PROC '/backends')
)
SELECT
NOW() AS check_time,
COUNT(*) AS total_nodes,
SUM(CASE WHEN Alive = 'true' THEN 1 ELSE 0 END) AS alive_nodes,
ROUND(MAX(used_pct) - MIN(used_pct), 2) AS capacity_diff,
ROUND(MAX(used_pct), 2) AS max_used_pct,
ROUND(MIN(used_pct), 2) AS min_used_pct,
ROUND(MAX(TabletNum) / GREATEST(MIN(TabletNum), 1), 2) AS tablet_ratio,
CASE
WHEN SUM(CASE WHEN Alive = 'false' THEN 1 ELSE 0 END) > 0 THEN '❌ 有节点掉线'
WHEN MAX(used_pct) > 85 THEN '⚠️ 磁盘占用过高'
WHEN (MAX(used_pct) - MIN(used_pct)) > 30 THEN '⚠️ 存储分布不均'
WHEN (MAX(TabletNum) / GREATEST(MIN(TabletNum), 1)) > 3 THEN '⚠️ Tablet 分布不均'
ELSE '✅ 集群负载均衡正常'
END AS status_desc
FROM backend_stats;
🧾 示例输出:
| check_time | total_nodes | alive_nodes | capacity_diff | max_used_pct | tablet_ratio | status_desc |
| ------------------- | ----------- | ----------- | ------------- | ------------ | ------------ | -------------- |
| 2025-10-11 10:20:00 | 6 | 6 | 34.64 | 75.08 | 15.93 | ⚠️ Tablet 分布不均 |
🔧 三、自动报警思路(扩展)
你可以:
-
在 Doris 里建一个日志表 保存每次检测结果;
-
用外部脚本(如 Shell/Python)读取结果,检测到 “⚠️ 或 ❌” 自动发邮件/钉钉消息。
例:创建日志表
CREATE TABLE IF NOT EXISTS monitor.doris_balance_log (
check_time DATETIME,
total_nodes INT,
alive_nodes INT,
capacity_diff DOUBLE,
max_used_pct DOUBLE,
min_used_pct DOUBLE,
tablet_ratio DOUBLE,
status_desc VARCHAR(100)
) ENGINE=OLAP
DUPLICATE KEY(check_time)
DISTRIBUTED BY HASH(check_time) BUCKETS 1
PROPERTIES("replication_num"="1");
插入检测结果
INSERT INTO monitor.doris_balance_log
WITH backend_stats AS (
SELECT
BackendId,
Host,
Alive,
TabletNum,
CAST(SPLIT_PART(CapacityUsedPct, ' ', 1) AS DOUBLE) AS used_pct
FROM
(SHOW PROC '/backends')
)
SELECT
NOW(),
COUNT(*),
SUM(CASE WHEN Alive = 'true' THEN 1 ELSE 0 END),
ROUND(MAX(used_pct) - MIN(used_pct), 2),
ROUND(MAX(used_pct), 2),
ROUND(MIN(used_pct), 2),
ROUND(MAX(TabletNum) / GREATEST(MIN(TabletNum), 1), 2),
CASE
WHEN SUM(CASE WHEN Alive = 'false' THEN 1 ELSE 0 END) > 0 THEN '❌ 有节点掉线'
WHEN MAX(used_pct) > 85 THEN '⚠️ 磁盘占用过高'
WHEN (MAX(used_pct) - MIN(used_pct)) > 30 THEN '⚠️ 存储分布不均'
WHEN (MAX(TabletNum) / GREATEST(MIN(TabletNum), 1)) > 3 THEN '⚠️ Tablet 分布不均'
ELSE '✅ 集群负载均衡正常'
END
FROM backend_stats;
🕒 四、自动化执行(推荐方式)
Linux 定时任务(crontab)
*/30 * * * * mysql -h fe_host -P9030 -uroot -p'password' -Dmonitor \
-e "INSERT INTO monitor.doris_balance_log ... (上面的SQL脚本)"
再结合公司的数据库,将告警发送到手机上
五、Doris BE 集群自动监控脚本
功能目标
-
检测每个 BE 节点的 磁盘使用率 与 内存使用率
-
扫描 BE 日志是否有 OOM / 内存分配失败
-
生成报警信息(打印在终端或写入日志文件)
-
可选:发送邮件或钉钉通知(可扩展)
脚本示例(Shell + curl + grep)
保存为 doris_be_monitor.sh 并给执行权限 chmod +x doris_be_monitor.sh
#!/bin/bash
##############################################
# Doris BE 自动监控脚本
# 功能:
# 1. 检测每个 BE 节点磁盘/内存使用率
# 2. 扫描 OOM 错误
# 3. 打印报警日志,可扩展邮件/钉钉告警
##############################################
# 配置区
FE_HOST="fe_host_ip" # FE 地址
FE_PORT=9030 # FE SQL端口
BE_LIST=("173.11" "173.12" "173.13" "173.14" "173.15" "173.16") # 所有 BE IP
BE_WEB_PORT=8040 # BE Web 端口
LOG_DIR="/home/doris/monitor_logs"
MAIL_TO="ops@example.com" # 邮件收件人
THRESHOLD_CAPACITY=85 # 磁盘使用率报警阈值 %
THRESHOLD_MEM=85 # 内存使用率报警阈值 %
mkdir -p $LOG_DIR
LOG_FILE="$LOG_DIR/doris_be_monitor_$(date +%F).log"
echo "================ Doris BE Monitor Start $(date) ================" | tee -a $LOG_FILE
# 1. 获取各 BE 磁盘和内存使用率
echo ">> 检查 BE 磁盘和内存使用率" | tee -a $LOG_FILE
for BE in "${BE_LIST[@]}"; do
METRICS=$(curl -s http://$BE:$BE_WEB_PORT/api/metrics)
# 提取磁盘占用百分比
DISK_USED=$(echo "$METRICS" | grep 'disk_usage' | awk '{print $2}')
MEM_USED=$(echo "$METRICS" | grep 'process_resident_memory_bytes' | awk '{printf "%.0f\n",$2/1024/1024/1024}') # GB
MEM_TOTAL=$(echo "$METRICS" | grep 'mem_limit' | awk '{printf "%.0f\n",$2/1024/1024/1024}') # GB
MEM_PCT=$(( MEM_USED*100 / MEM_TOTAL ))
ALERTS=""
if [ "$DISK_USED" -ge "$THRESHOLD_CAPACITY" ]; then
ALERTS+="⚠️ 磁盘使用过高 "
fi
if [ "$MEM_PCT" -ge "$THRESHOLD_MEM" ]; then
ALERTS+="⚠️ 内存使用过高 "
fi
echo "BE $BE | DiskUsed=$DISK_USED% | MemUsed=$MEM_PCT% | $ALERTS" | tee -a $LOG_FILE
done
# 2. 扫描 OOM 错误
echo ">> 扫描 BE 日志 OOM 错误" | tee -a $LOG_FILE
for BE in "${BE_LIST[@]}"; do
BE_LOG_DIR="/data/doris/be/log" # 如果 BE 日志路径不同,请修改
OOM_COUNT=$(grep -iE "Out of memory|Killed process|Cannot allocate memory|std::bad_alloc" $BE_LOG_DIR/be.INFO* | wc -l)
if [ "$OOM_COUNT" -gt 0 ]; then
echo "❌ BE $BE 发现 $OOM_COUNT 条 OOM / 内存错误!" | tee -a $LOG_FILE
else
echo "BE $BE 无 OOM 错误" | tee -a $LOG_FILE
fi
done
# 3. 可选:邮件告警
ALERT_FLAG=$(grep -E "⚠️|❌" $LOG_FILE)
if [ ! -z "$ALERT_FLAG" ]; then
echo -e "$ALERT_FLAG" | mail -s "[Doris BE Monitor] 警报 $(date)" $MAIL_TO
fi
echo "================ Doris BE Monitor End $(date) ================" | tee -a $LOG_FILE
🔹 使用方法
-
将脚本保存到 Doris FE 或管理服务器
-
配置:
-
BE_LIST→ 所有 BE IP -
BE_LOG_DIR→ BE 日志路径 -
MAIL_TO→ 告警邮箱
-

















 2486
2486

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









