






假设你有一个句子,'你是人',现在要求翻译‘是’这个字,那在注意力机制中这三个字分别代表什么呢?
q:query ,也就是目标词,是
k:key,目标词周围的词,也可以说是上下文,你,人
v:value,目标词输出的向量,在自注意力机制中和k维度相同,你,人
自注意力机制,就是一个句子中的每一个词都当成,q,k,v参与计算,假设你输入的句子通过word embedding层得到了I矩阵,由a1,a2....ai组成,其中a1,a2....ai都是词向量。
qi = Wq * ai
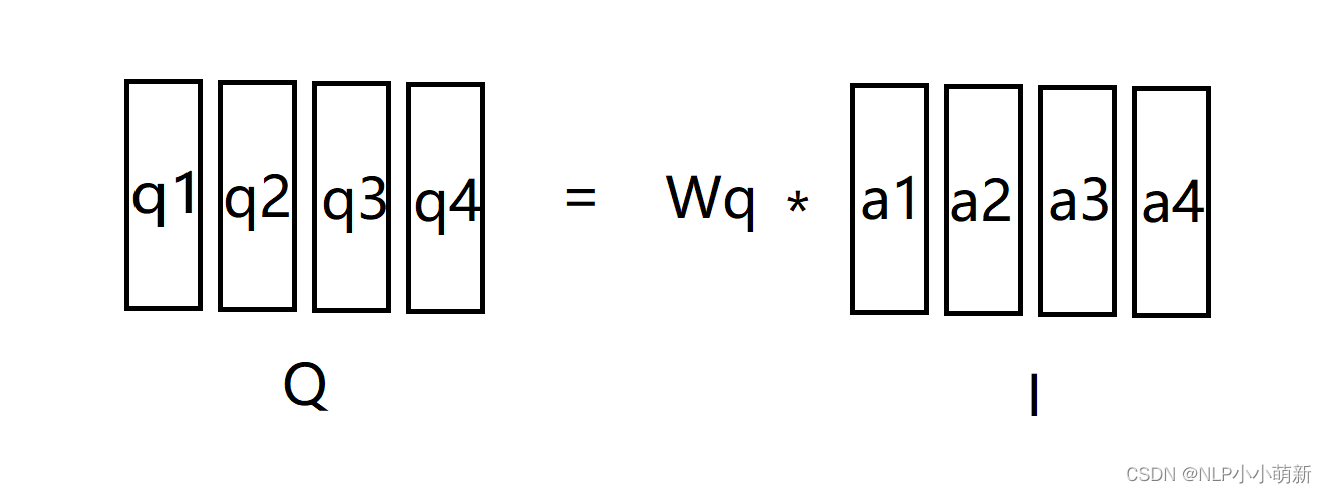
同理ki = Wk * ai,vi = Wv * ai。
由此我们得到了三个矩阵Q = Wq * I, K = Wk * I, V = Wv * I
各个矩阵的维度:
I : (batch_size, sentence_len, embedding_size)
Q:(batch_size, sentence_len, q_size)
K:(batch_size, sentence_len, k_size = q_size)
V:(batch_size, sentence_len, v_size)
由Q * KT得到的矩阵A我们称为Attention块,再通过一个激活函数得到矩阵A'
A,A':(batch_size, sentence_len, sentence_len)
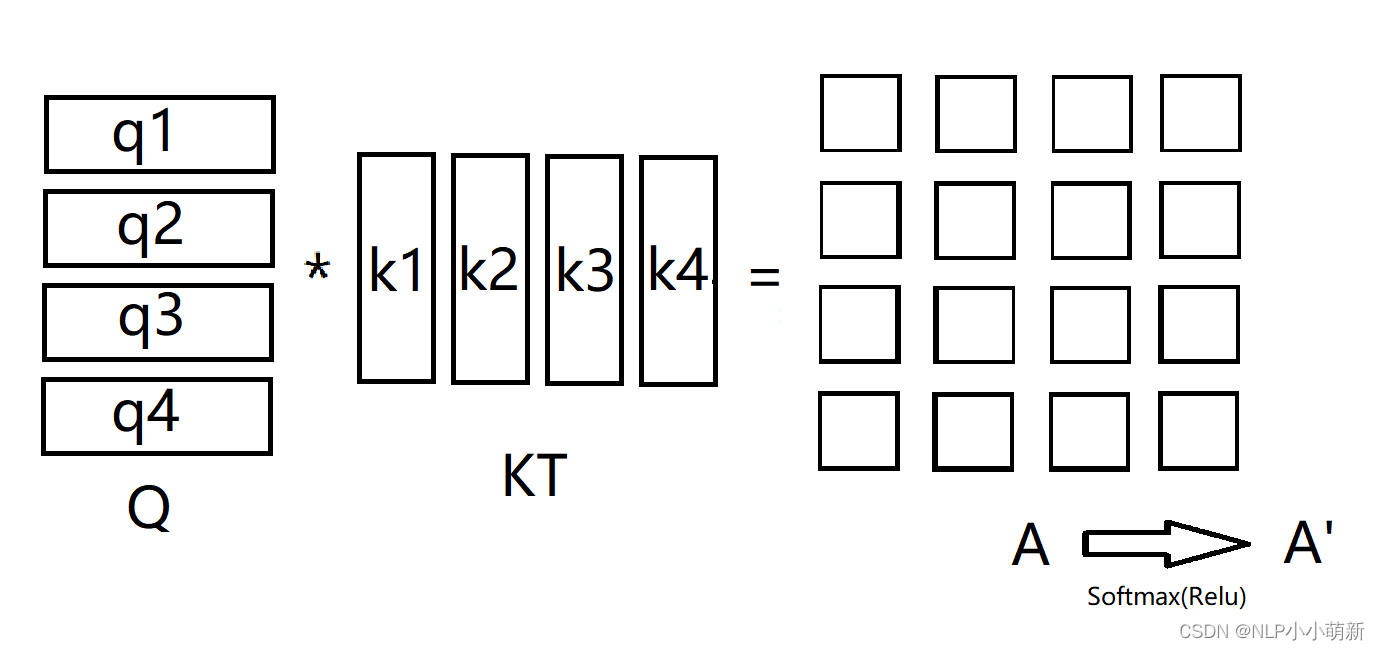
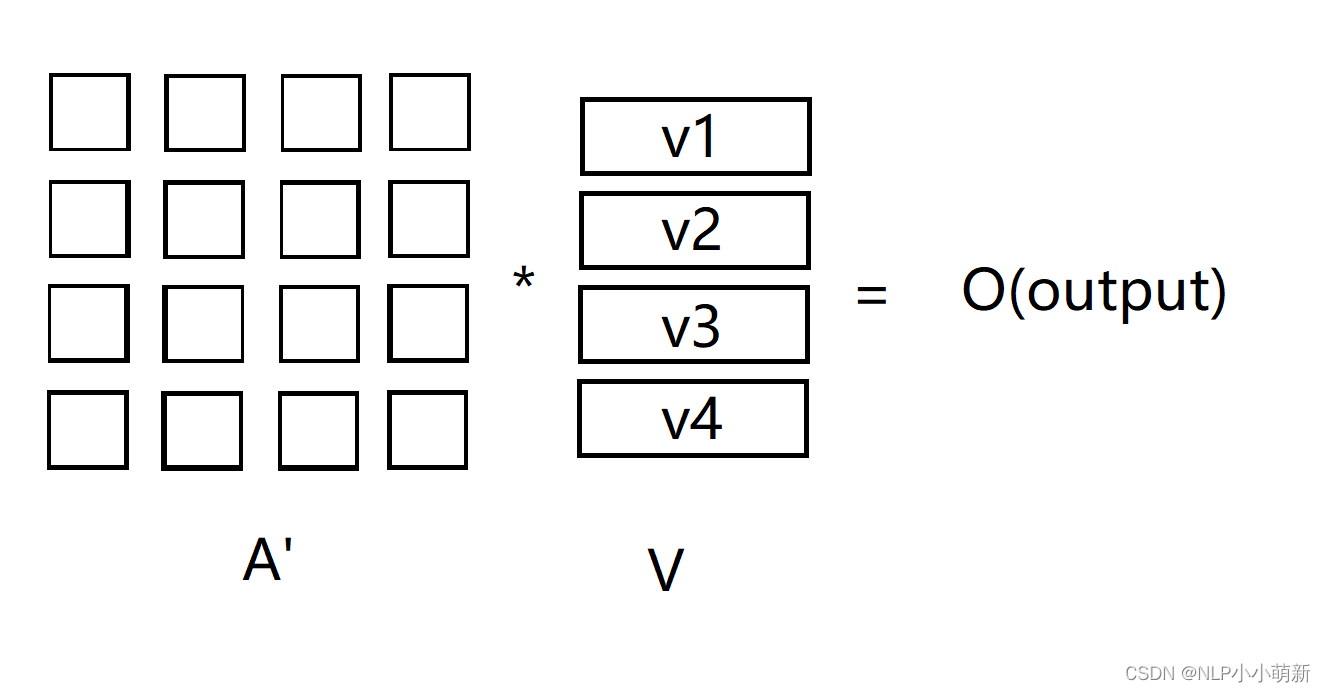
由上图的过程,我们可以推得公式:
有些人可能要问了,这个是什么意思呢,在Q*KT这一步中,假设q与k的原分布是均值为0方差为1的分布,那A = Q* KT这一步中就把方差扩大成了dk,则需要除以
来维持正态分布,使得softmax的梯度更加平缓,反向传播时候的参数更替没有那么剧烈。
pytorch代码
class SelfAttention(nn.Module):
def __init__(self):
super().__init__()
def forward(self, Q, K, V, attn_mask):
'''
Q: [batch_size, n_heads, len_q, d_k]
K: [batch_size, n_heads, len_k, d_k]
V: [batch_size, n_heads, len_v(=len_k), d_v]
attn_mask: [batch_size, n_heads, seq_len, seq_len]
'''
scores = torch.matmul(Q, K.transpose(-1, -2)) / np.sqrt(d_k) # scores : [batch_size, n_heads, len_q, len_k]
scores.masked_fill_(attn_mask, -1e9) # Fills elements of self tensor with value where mask is True.
attn = nn.Softmax(dim = - 1)(scores)
context = torch.matmul(attn, V) # [batch_size, n_heads, len_q, d_v]
return context代码里面有一个attn_mask,
上面 Self Attention 的计算过程中,我们通常使用 mini-batch 来计算,也就是一次计算多句话,即 X的维度是 [batch_size, sequence_length],sequence_length是句长,而一个 mini-batch 是由多个不等长的句子组成的,我们需要按照这个 mini-batch 中最大的句长对剩余的句子进行补齐,一般用 0 进行填充,这个过程叫做 padding
但这时在进行 softmax 就会产生问题。回顾 softmax 函数,e0 是 1,是有值的,这样的话 softmax 中被 padding 的部分就参与了运算,相当于让无效的部分参与了运算,这可能会产生很大的隐患。因此需要做一个 mask 操作,让这些无效的区域不参与运算,一般是给无效区域加一个很大的负数偏置,即-1e9.
def get_attn_pad_mask(seq_q, seq_k):
batch_size, len_q = seq_q.size()
batch_size, len_k = seq_k.size()
# eq(zero) is PAD token
pad_attn_mask = seq_k.data.eq(0).unsqueeze(1) # [batch_size, 1, len_k], True is masked
return pad_attn_mask.expand(batch_size, len_q, len_k) # [batch_size, len_q, len_k]这样我们就完成了一个简单的单头注意力机制.
多头注意力机制,嗯~~,原理其实和单头一样,唯一不同的就是把embedding_size进行了拆分,使得模型可以提取多重语义,然后增加了一个超参数n_heads,其他没什么特别的,代码也贴一下吧.
class MultiHeadAttention(nn.Module):
def __init__(self):
super().__init__()
self.W_Q = nn.Linear(embeding_size, d_k * n_heads, bias=False)
self.W_K = nn.Linear(embeding_size, d_k * n_heads, bias=False)
self.W_V = nn.Linear(embeding_size, d_k * n_heads, bias=False)
self.fc = nn.Linear(n_heads * d_k, embeding_size, bias=False)
self.ln = nn.LayerNorm(embeding_size)
self.attn = SelfAttention()
def forward(self, input_Q, input_K, input_V, attn_mask):
'''
input_Q: [batch_size, len_q, d_model]
input_K: [batch_size, len_k, d_model]
input_V: [batch_size, len_v(=len_k), d_model]
attn_mask: [batch_size, seq_len, seq_len]
'''
residual, batch_size = input_Q, input_Q.size(0)
# (B, S, D) -proj-> (B, S, D_new) -split-> (B, S, H, W) -trans-> (B, H, S, W)
Q = self.W_Q(input_Q).view(batch_size, -1, n_heads, d_k).transpose(1,2) # Q: [batch_size, n_heads, len_q, d_k]
K = self.W_K(input_K).view(batch_size, -1, n_heads, d_k).transpose(1,2) # K: [batch_size, n_heads, len_k, d_k]
V = self.W_V(input_V).view(batch_size, -1, n_heads, d_k).transpose(1,2) # V: [batch_size, n_heads, len_v(=len_k), d_v]
attn_mask = attn_mask.unsqueeze(1).repeat(1, n_heads, 1, 1) # attn_mask : [batch_size, n_heads, seq_len, seq_len]
# context: [batch_size, n_heads, len_q, d_v], attn: [batch_size, n_heads, len_q, len_k]
context = self.attn(Q, K, V, attn_mask)
context = context.transpose(1, 2).reshape(batch_size, -1, n_heads * d_k) # context: [batch_size, len_q, n_heads * d_v]
output = self.fc(context) # [batch_size, len_q, d_model]
return self.ln(output + residual)














 2029
2029











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









