







论文链接:https://arxiv.org/abs/2307.07697
项目链接:https://github.com/IDEA-FinAI/ToG
💡 文章信息
| Title | Think-on-Graph: Deep and Responsible Reasoning of Large Language Model on Knowledge Graph |
|---|---|
| Journal | () |
| Authors | Sun Jiashuo,Xu Chengjin,Tang Lumingyuan,Wang Saizhuo,Lin Chen,Gong Yeyun,Ni Lionel,Shum Heung-Yeung,Guo Jian |
| Pub.date | 2023/10/13 |
📕 研究动机
-
幻觉问题:生成与事实不符的答案,尤其是涉及领域知识和多跳推理的问题。
-
透明性不足:缺乏责任性和可解释性,难以追溯输出来源。
-
成本高昂:训练过程耗时且代价高,使得模型知识更新难以快速实现。
📜 研究内容
本文提出了一种新的紧耦合的LLM⊗KG范式,其中KG和LLM是串联工作的,在图推理的每一步中相互补充彼此的能力。
📊 研究方法
1. 实验设置
(1)数据集
对于GrailQA和Simple Questions这两个大数据集,为了节约计算成本,只随机选取1000个样本作为测试。
-
多跳任务:CWQ, WebQSP, GrailQA, QALD10-en
-
单跳任务:Simple Questions
-
其他任务:如开放域问答(WebQuestions)、槽填充(T-REx, Zero-Shot RE)以及事实验证(Creak)
(2)基座LLM
-
GPT-3.5-turbo、GPT-4 API
-
Llama2-70B-Chat
(3)参数设置
-
对于Llama2-70B-Chat
-
temperature:在探索阶段设置为0.4(增加多样性),在推理阶段设置为0(保证可重复性)
-
使用8张A100-40G跑8次,没有量化
-
-
其他共性设置
-
生成阶段最大token:256
-
beam search的N和Dmax:3
-
(4)知识图谱
-
Freebase:使用在CWQ, WebQSP, GrailQA, Simple Questions和Webquestions中
-
Wikidata:使用在QALD10-en, T-REx, Zero-Shot RE 和 Creak中
2. 实验模型:ToG
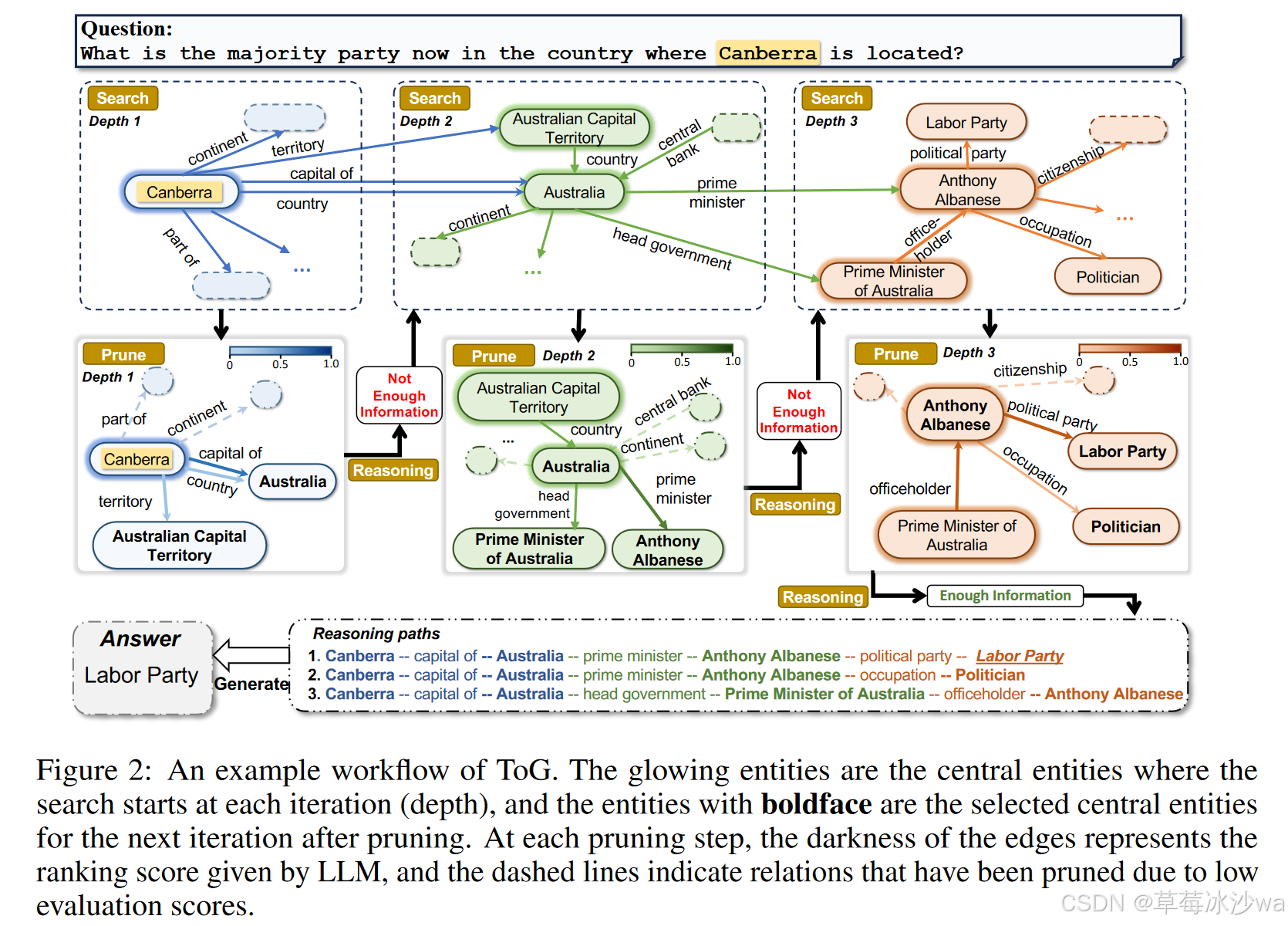
(1)初始化
-
从输入问题中提取主题实体(topic entities),作为推理路径的初始实体集合E0。
-
使用语言模型根据问题生成初始推理路径集合 P0。
-
如果问题中的主题实体较少,系统允许路径数量少于 N。
(2)探索
-
关系探索
-
搜索
-
第D次迭代开始时,会根据D-1次迭代的尾实体的链接,获得关系候选集
-
过程是执行了2条简单的预定义query查询,没有任何的训练成本
-
-
剪枝
-
利用LLM从候选集中挑选出top-N以尾关系RD结束的推理路径P
-
-
-
实体探索
-
搜索
-
根据第D-1次迭代检索出的尾实体和第D次迭代检索出的详细,进行查询,获得实体候选集
-
-
剪枝
-
利用LLM挑选出新的以为实体ED结束的top-N推理路径P
-
-
(3)推理
-
使用语言模型评估当前推理路径是否包含足够信息回答问题。
-
如果评估结果为“足够”,直接基于当前路径生成答案。
-
如果评估结果为“不足”,继续执行探索步骤,直至路径长度达到最大深度 Dmax。
-
-
若达到最大深度仍无法回答问题,基于语言模型的固有知识生成答案。
-
最多调用2ND+D+1次LLM,其中“2ND”表示D次探索(beam search为N,探索包括关系探索和实体探索两部分),“D”表示D次评价,“1”表示1次生成。
ToG优势
深度推理
ToG 从知识图谱中提取多样化和多跳推理路径,作为语言模型推理的基础,从而增强了语言模型在知识密集型任务中的深度推理能力。
负责任的推理
显式且可编辑的推理路径提升了语言模型推理过程的可解释性,同时支持对模型输出的来源进行追溯和校正。
灵活性和高效性
ToG 是一个即插即用的框架,可以无缝应用于各种语言模型和知识图谱。
在 ToG 框架下,知识可以通过知识图谱频繁更新,而无需更新语言模型,后者的知识更新代价昂贵且缓慢。
ToG 提升了小型语言模型(例如 LLAMA2-70B)的推理能力,使其可以与大型语言模型竞争。
3. 实验模型:ToG-R
-
与ToG一样,在每次迭代中依次进行关系搜索、关系剪枝和实体搜索。
-
不同之处是实体剪枝是随机从候选集中采样N个实体,而不是让LLM去选出Top-N。
-
需要调用ND+D+1次LLM(相较于ToG少了ND次实体剪枝的调用)
ToG-R优势
省去了使用LLM剪枝实体的过程,从而降低了总体成本和推理时间
主要强调关系的字面信息,缓解了当中间实体的字面信息缺失或对LLM不熟悉时误导推理的风险
4. 实验结果
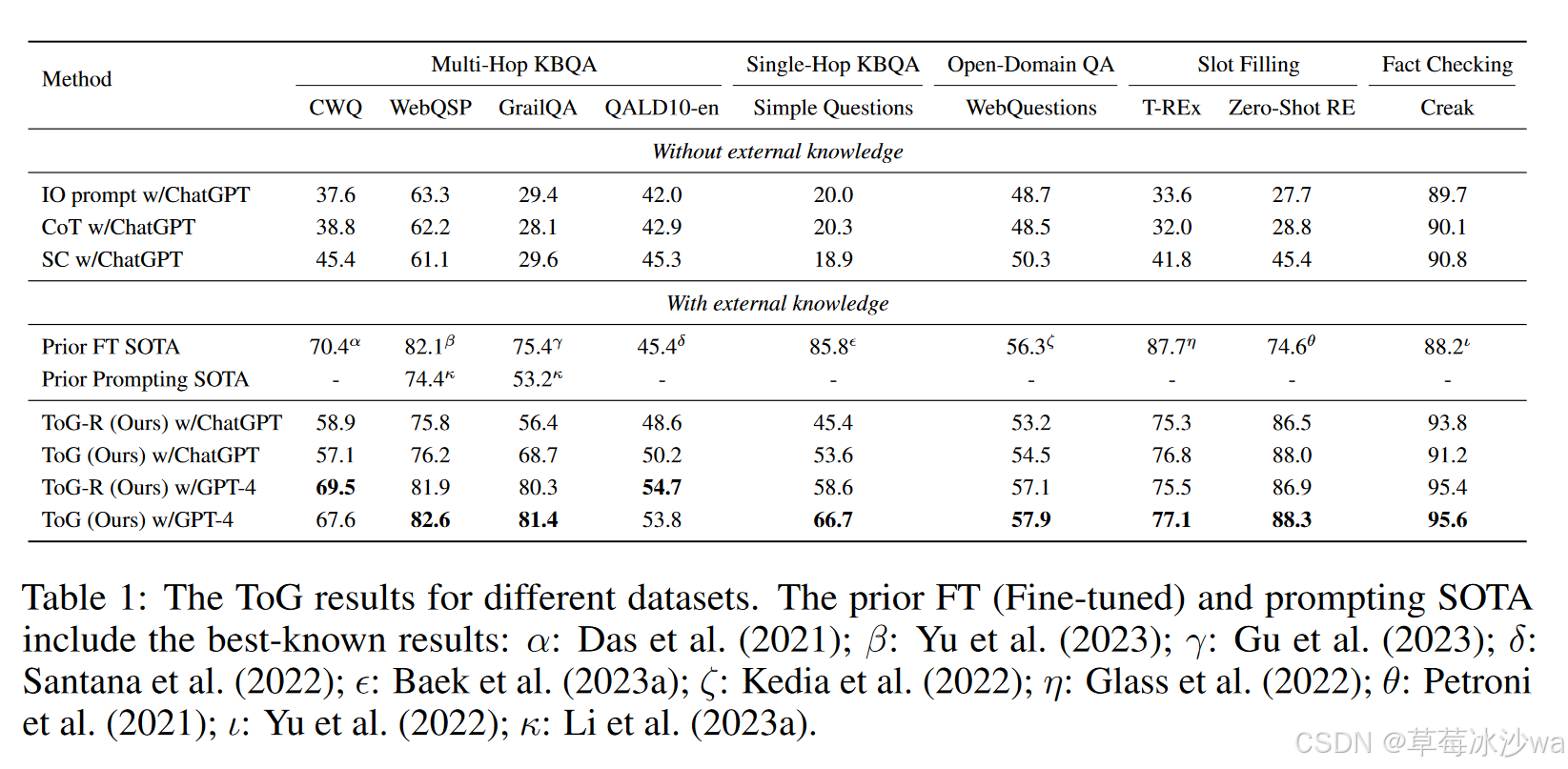
(1)ToG在不同数据集上的表现
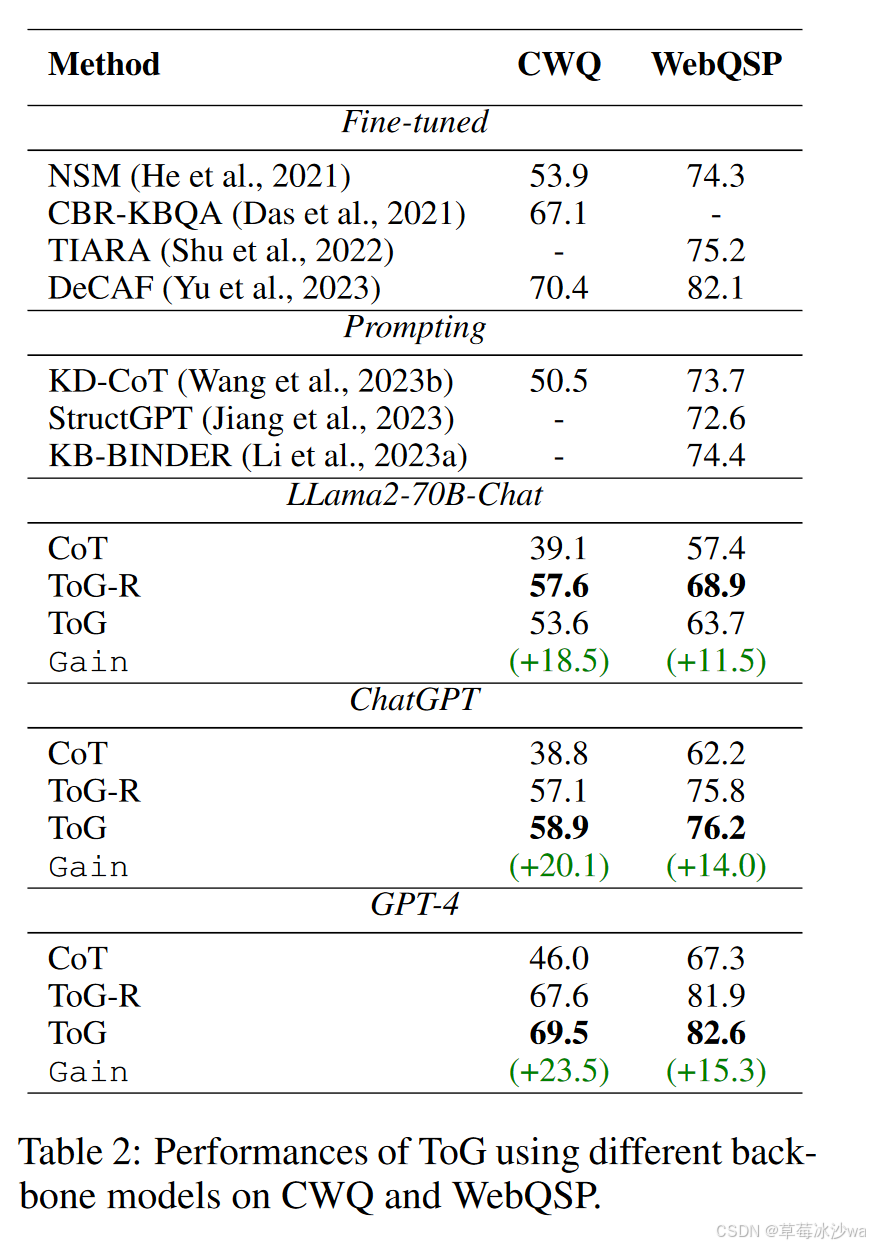
(2)ToG选用不同基座LLM的表现
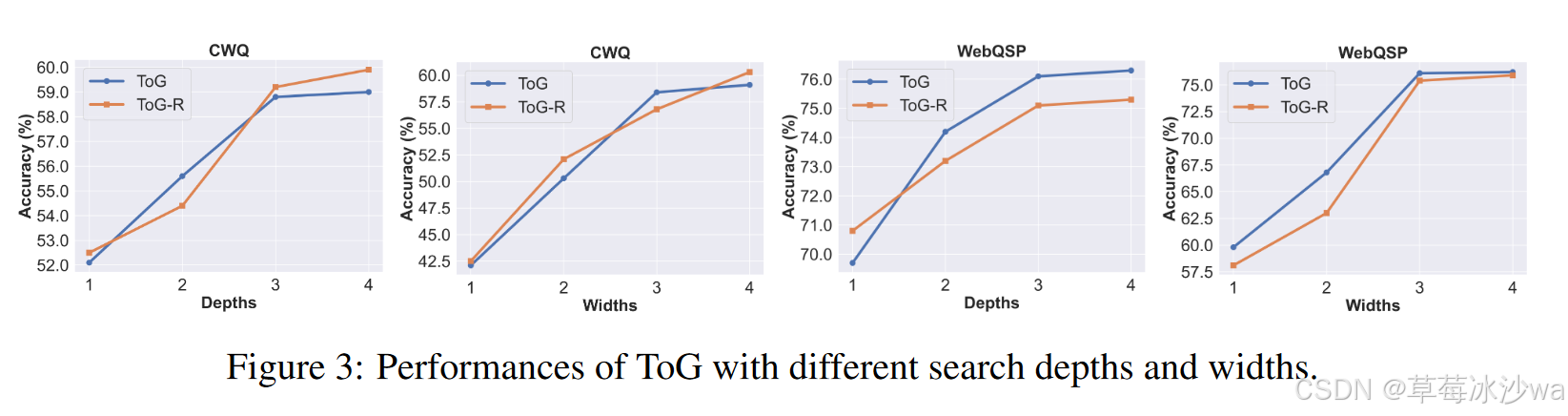
(3)消融实验
-
不同N和Dmax
-
不同KG

-
不同提示方法
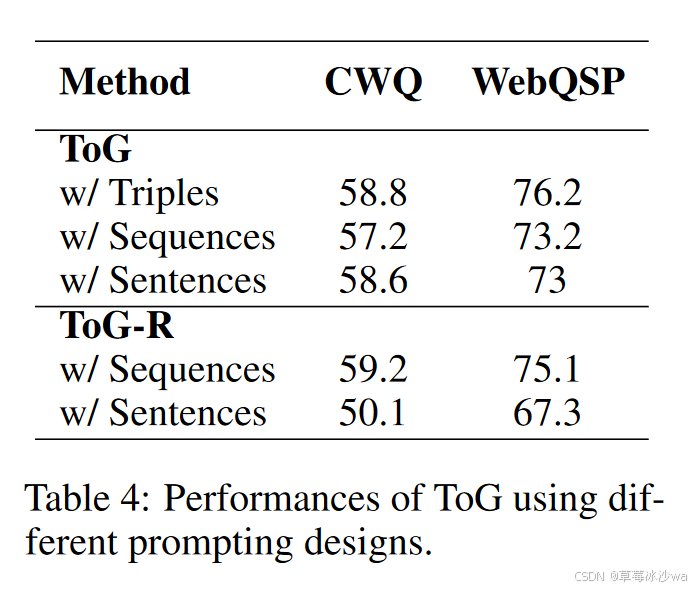
-
不同剪枝工具
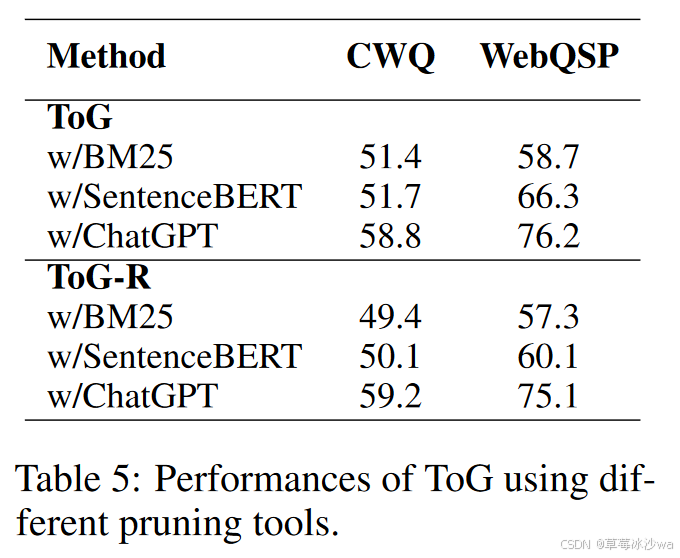
-
不同Beam Search算法
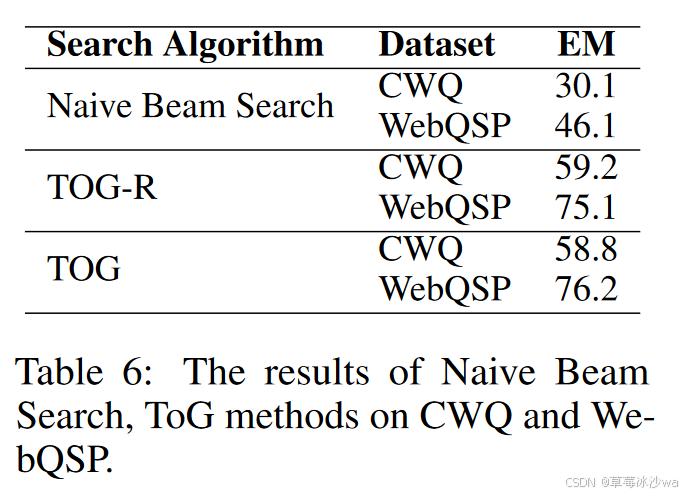
-
不同样本种子数量
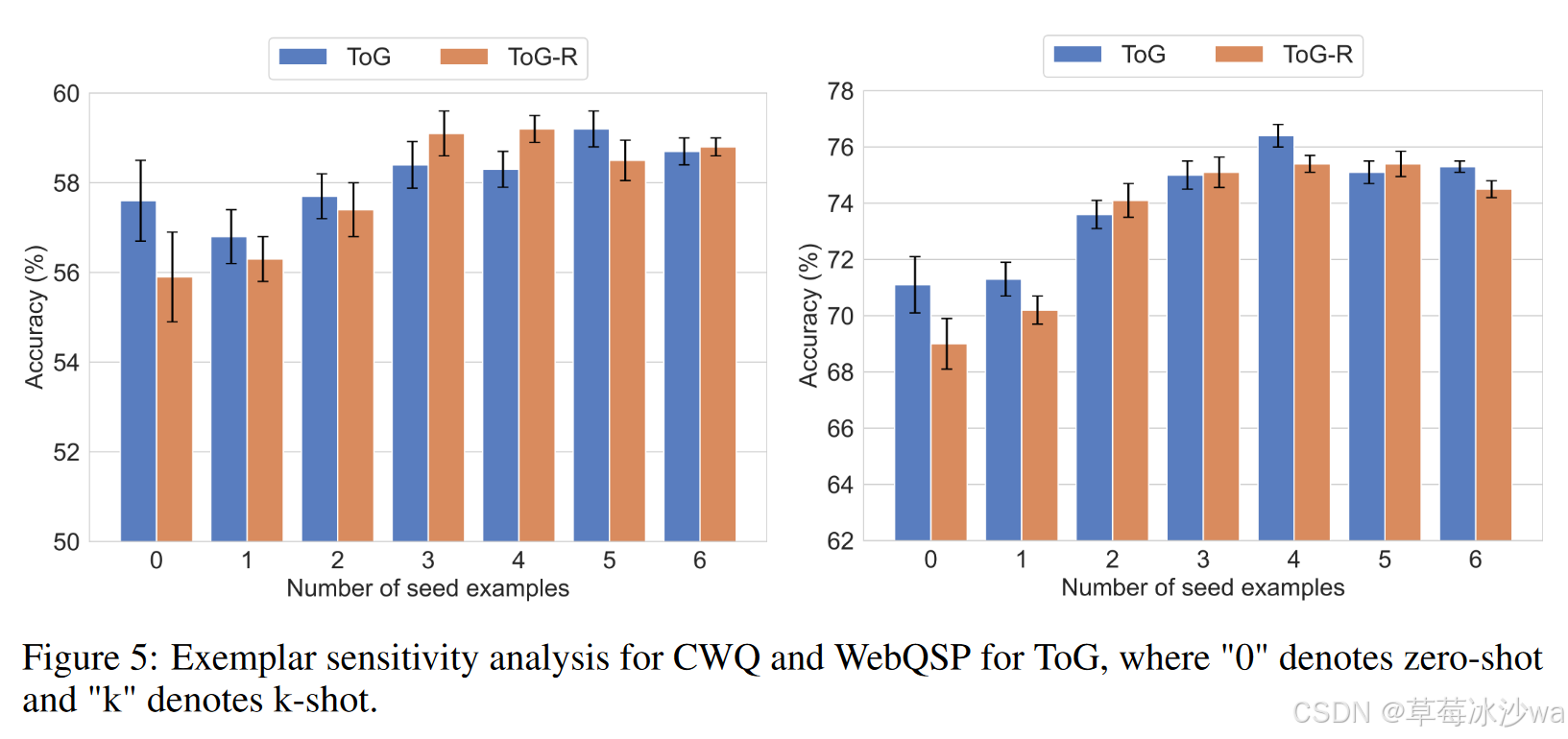
(4)结果分析
-
错误分析
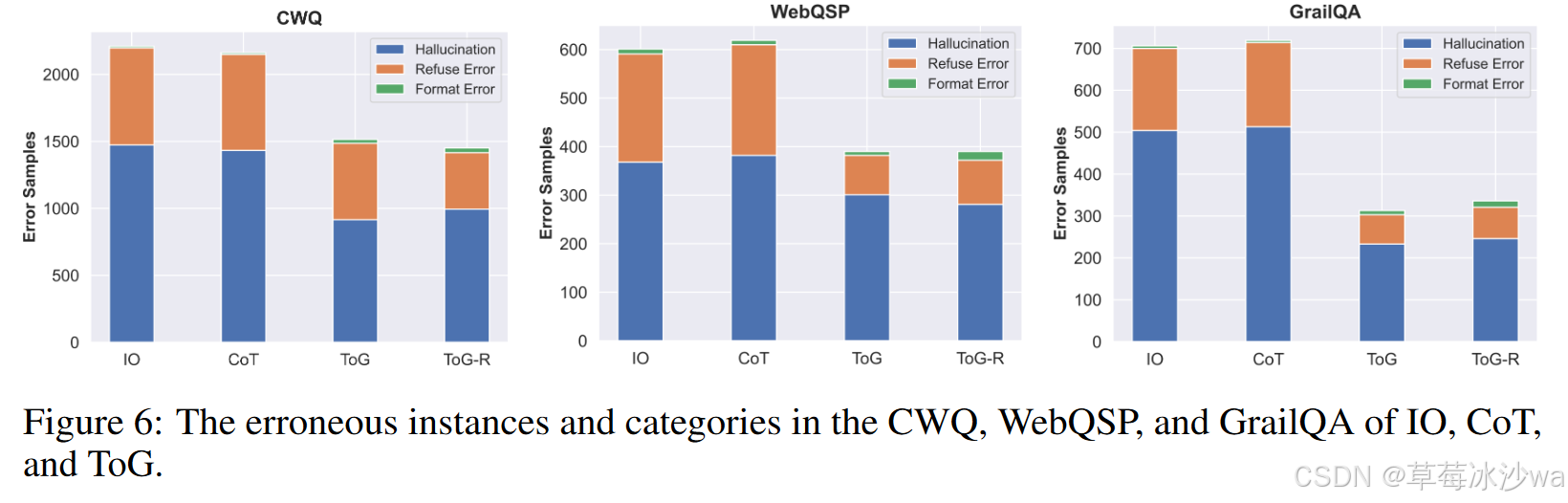
-
答案中的证据
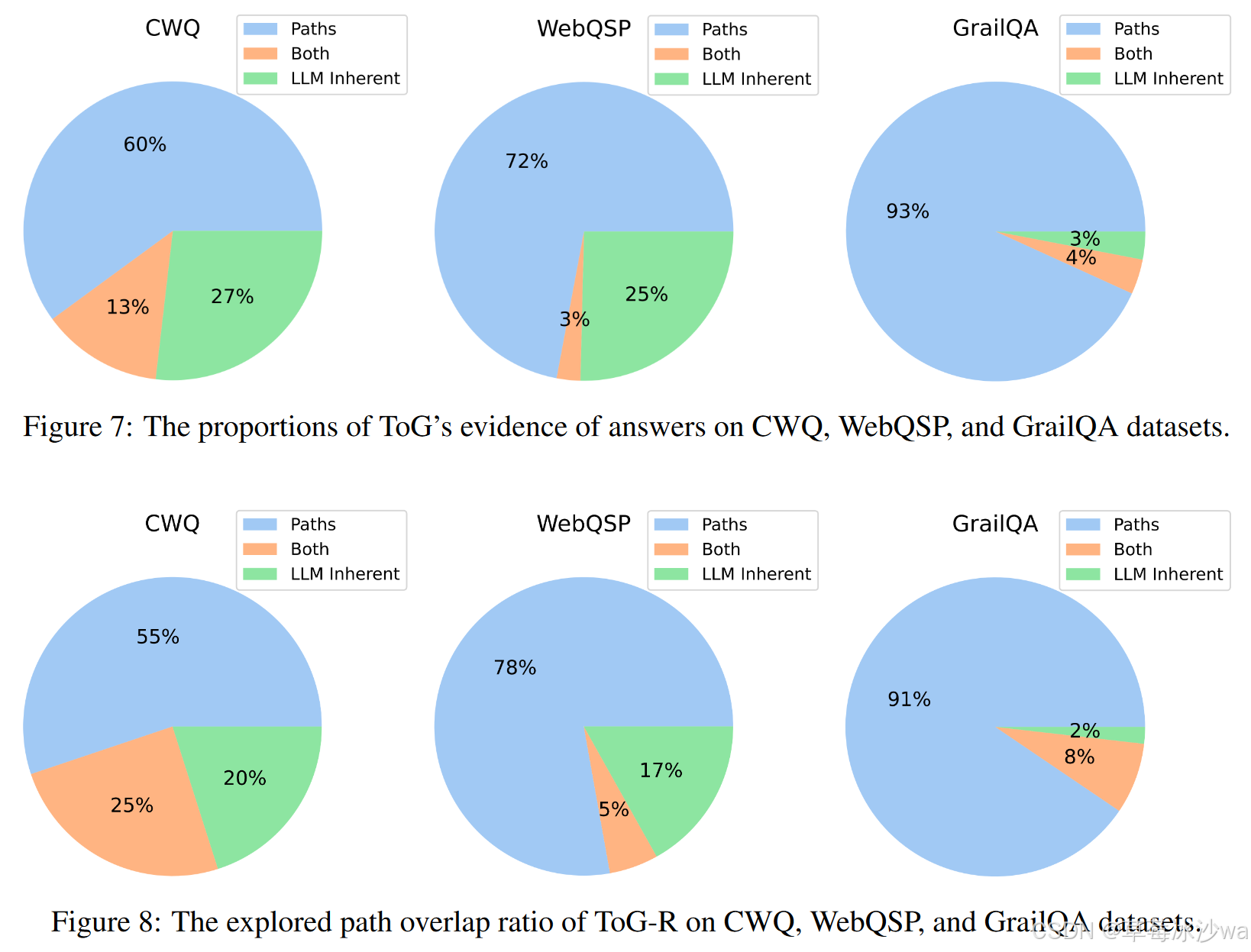
-
探索路径和真实路径的重叠率
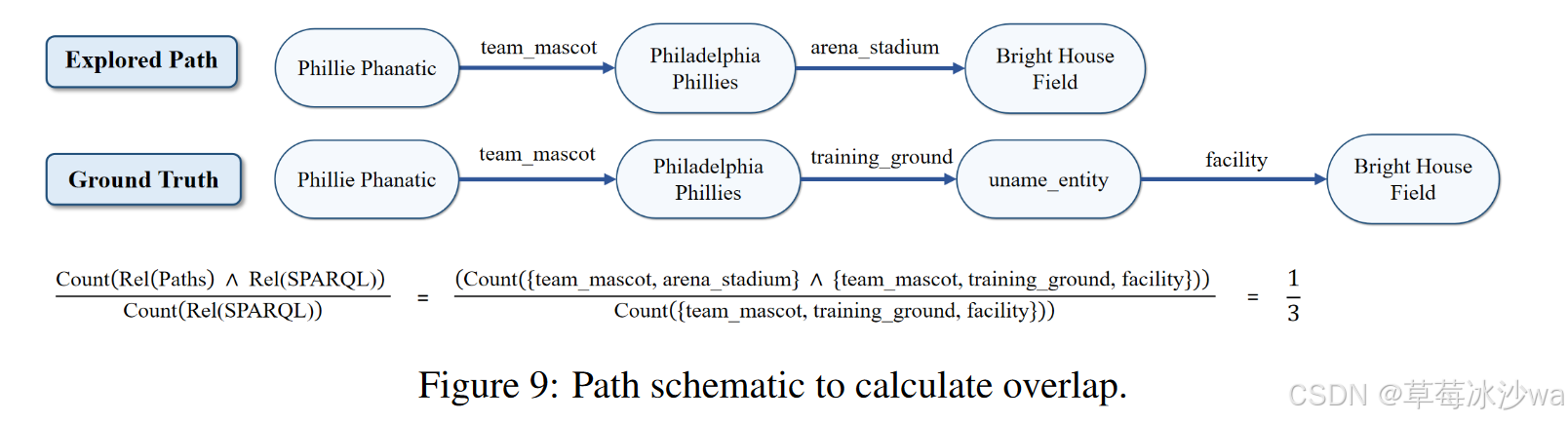
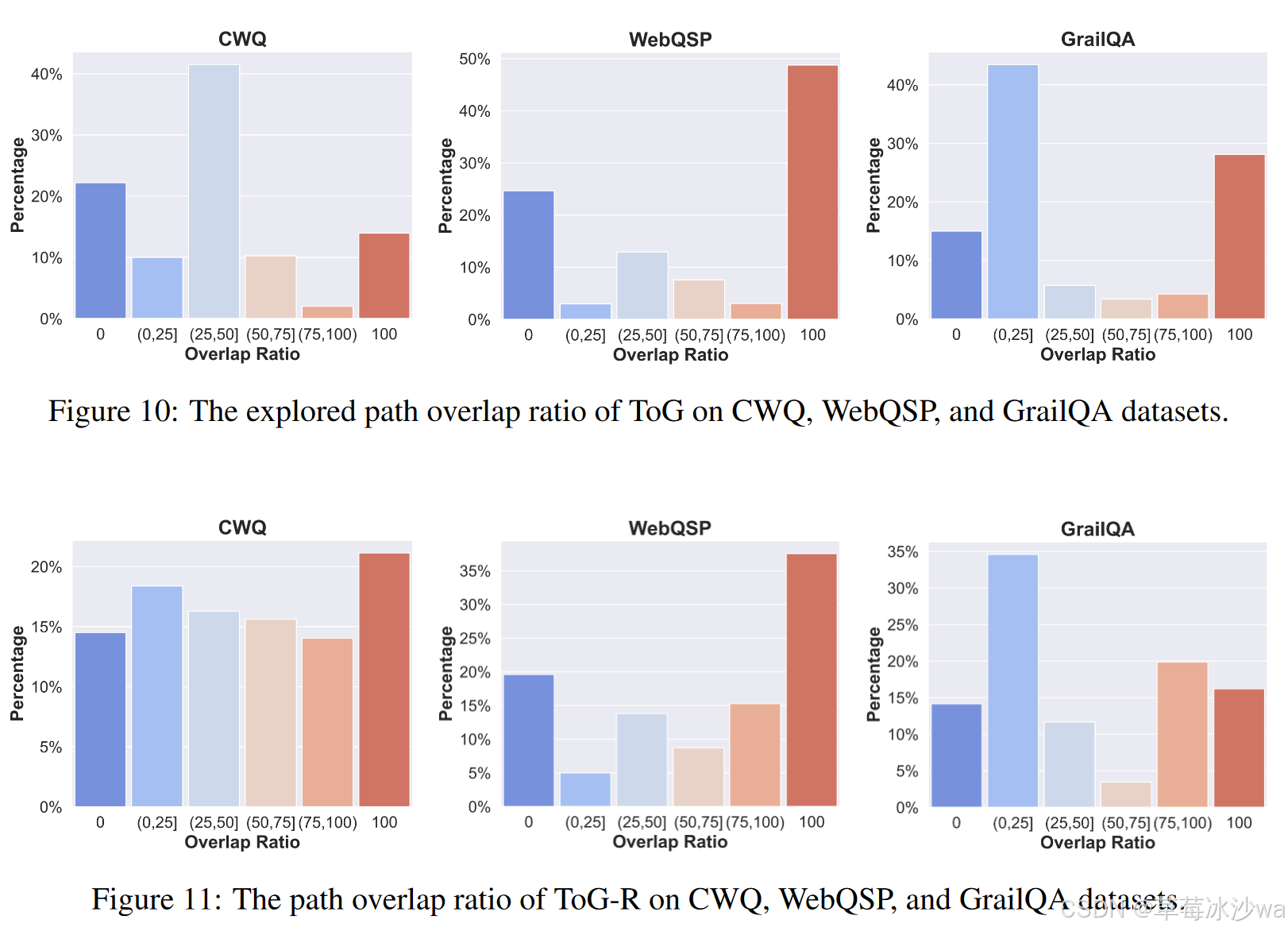
🚩 研究结论
1. 在不同数据集进行实验的结论
-
ToG在多跳任务上更为有效,可以增强LLM的深度推理能力
-
尽管ToG是一个基于提示工程的没有训练的方法,ToG选用GPT-4作为基座LLM时在6个数据集(总共9个)中达到了新的SOTA。如果仅仅和基于提示工程的方法比较,ToG选用GPT4和其更低版本在所有数据集中获胜。
-
ToG在开放领域的QA任务重具有通用性。
-
-
KG在推理过程中的重要性不容忽视。
2. 选用不同基座进行实验的结论
-
使用更强大的LLM来挖掘KG的更大潜力。
-
参数量较小的LLM的ToG可能可以替代参数量较大的LLM,特别是在外部KGs可以覆盖的垂直场景中。
3. 消融实验中的重要结论
-
相较于使用自然语言表示的句子,使用三元组表示推理路径具有最高的效率和优越的性能。
4. ToG对于知识的可回溯性和纠错性
-
ToG具有回溯和检查推理路径的能力,能够发现存在错误的可疑三元组,并对其进行纠正。
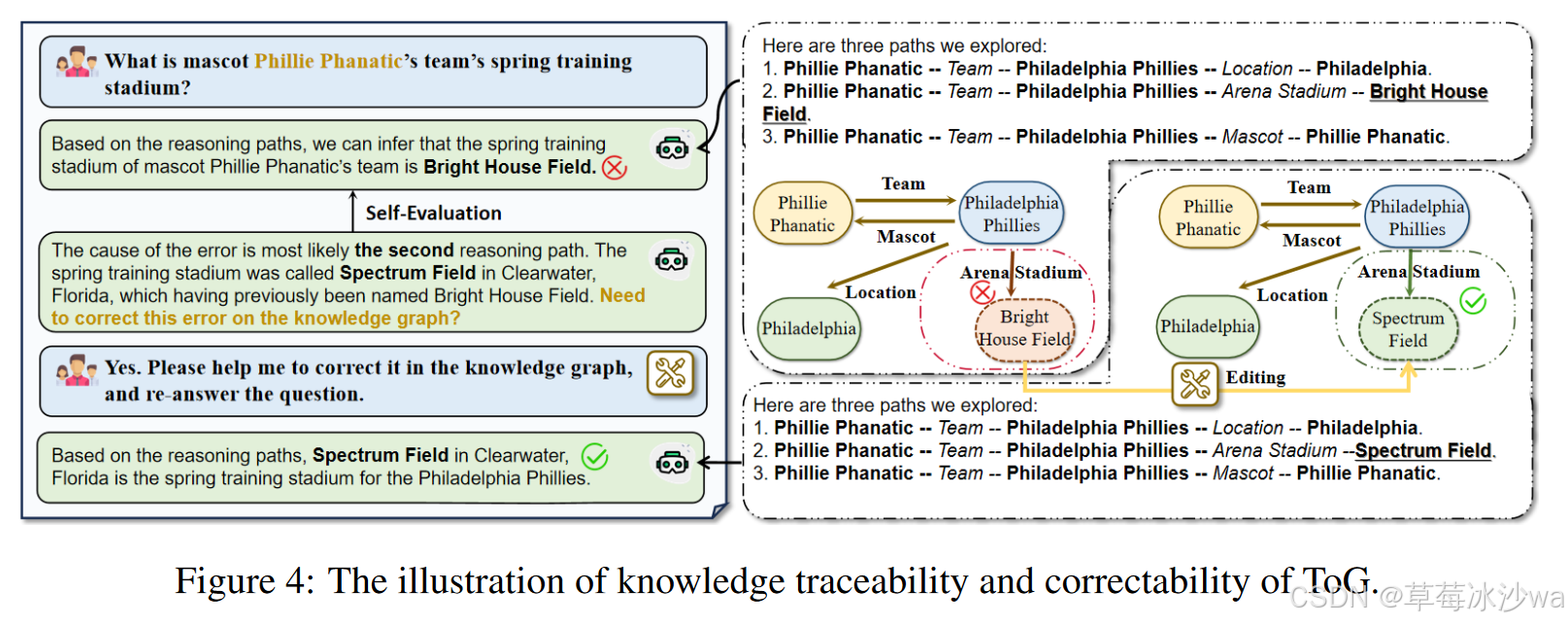
📌 思考体会
1. 创新点
-
使用显式的推理路径,提高了推理过程的可解释性和可校正性,能对知识进行回溯,发现错误并进行纠正
2. 不足之处
-
只适用于结构化知识图谱的问答


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









