







 本文提出了一种名为LoRA的方法,通过利用大模型的内在秩特性,仅对部分密集层进行低秩参数化更新,有效减少内存需求并提高适应下游任务的效率。实验在多个数据集和模型上展示了LoRA的优势,包括内存节省和快速任务切换。
本文提出了一种名为LoRA的方法,通过利用大模型的内在秩特性,仅对部分密集层进行低秩参数化更新,有效减少内存需求并提高适应下游任务的效率。实验在多个数据集和模型上展示了LoRA的优势,包括内存节省和快速任务切换。
<LoRA: Low-Rank Adaptation of Large Language Models>
💡 文章信息
Title | LoRA: Low-Rank Adaptation of Large Language Models |
|---|---|
Journal | () |
Authors | Hu Edward J.,Shen Yelong,Wallis Phillip,Allen-Zhu Zeyuan,Li Yuanzhi,Wang Shean,Wang Lu,Chen Weizhu |
Pub.date | 2021-10-16 |
📕 研究动机
1. 现有问题
将大模型应用于下游任务时,通常需要进行微调,即更新预训练模型的所有参数。微调的主要缺点是新模型包含的参数与原模型一样多。
存储和加载除预训练模型外的少量任务特定参数,现有技术通过扩展模型深度或减少模型可用序列长度会引入推理延迟。更重要的是,这些方法往往无法匹配微调基线,在效率和模型质量之间存在权衡。
2. 灵感来源
过度参数化模型实际上停留在较低的内在维度上,即使随机投影到较小的子空间,仍然可以有效地学习。论文假设模型适应过程中权重的变化也具有较低的"内在秩",从而提出了低秩适应( Low-Rank Adaptive,LoRA )方法。
过参数化模型是指模型参数数量远远超过训练数据的模型,通常认为它们容易过拟合。
📜 研究内容
提出了低秩适应( Low-Rank Adaptive,LoRA )方法。这个方法允许通过优化密集层在适应期间的秩分解矩阵间接训练一些密集层,同时保持预训练权重冻结。这意味着他们通过调整适应期间权重变化的秩分解矩阵来实现对神经网络中某些密集层的训练。
1. 低秩参数化更新矩阵
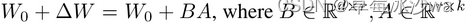
在训练过程中,W0被冻结,不接受梯度更新,而A和B包含可训练参数。
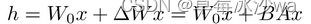
对A使用随机高斯初始化,对B使用零初始化,因此在训练开始时∆W = BA为零。然后用α/r对∆Wx进行标度,其中α为r中的常数。
-
全面微调的泛化
更一般的微调形式允许对预训练参数的子集进行训练。在对所有权重矩阵应用LoRA并训练所有偏差时,通过将LoRA秩r设置为预训练权重矩阵的秩,大致恢复了完全微调的表达能力。
-
没有额外的推断延迟
当我们需要切换到另一个下游任务时,我们可以通过减去BA,然后添加一个不同的B′A′来恢复W0,这种快速的操作只需要很少的内存开销,且不会引入额外的延迟。
2. 将Lora应用于Transformer
在Transformer架构中,自注意力模块( Wq , Wk , Wv , Wo)中有4个权重矩阵,MLP(多层感知机)模块中有2个权重矩阵。论文的研究仅限于调整下游任务的注意力权重,并冻结MLP模块。
📊 研究方法
1. 数据集
GLUE Benchmark、WikiSQL 、SAMSum、E2E NLG Challenge、DART、WebNLG
2. 基线
-
微调(FT)
在微调过程中,模型初始化为预训练的权重和偏置,所有模型参数进行梯度更新。一个简单的变体是只更新某些层,而冻结其他层。 -
Bias - only或BitFit
只训练偏置向量,而冻结其他所有向量。 -
Prefix-embedding tuning(PreEmbed)
在输入标记之间插入特殊标记,这些特殊标记具有可训练的词嵌入,并且通常不在模型的词汇表中。放置这些标记的位置可能会影响性能。 -
Prefix-layer tuning(PreLayer)
Prefix-embedding tuning的扩展,不仅学习特殊标记的词嵌入,还学习每个Transformer层之后的激活。 -
Adapter tuning
AdapterH、AdapterL、AdapterP、AdapterD -
LoRA
在现有权重矩阵的并行中添加可训练的秩分解矩阵对
3. 实验模型
-
ROBERTA BASE/LARGE(2019)
- 优化了最初BERT提出的预训练配置,并在不引入更多可训练参数的情况下提高了后者的任务性能
- RoBERTa base (125M);RoBERTa large (355M)
-
DEBERTa XXL(2021)
- 是BERT的一个较新的变种,它是在一个更大的规模上进行训练的,并在GLUE和Su- perGLUE等基准测试中表现非常有竞争力
-
GPT-2 MEDIUM/LARGE
- GPT-2 Medium(345M);GPT-2 LARGE(774M)
-
扩展到GPT-3 175B
4. 关键问题
-
应该将LoRA应用于转换器中的哪些权重矩阵?
只考虑自注意力模块中的权重矩阵。 -
LORA的最优秩r是什么?
- 增大r并不能覆盖更有意义的子空间,这表明低秩的适应矩阵是足够的
-
∆W 与 W 之间的关系如何?
- 低秩适应矩阵可能放大了特定下游任务的重要特征,这些任务在通用预训练模型中已经学习但没有强调
5. 实验结果
![[image]](https://i-blog.csdnimg.cn/blog_migrate/b0116235aa31aeaa7cfe8c8ed62076f7.png)
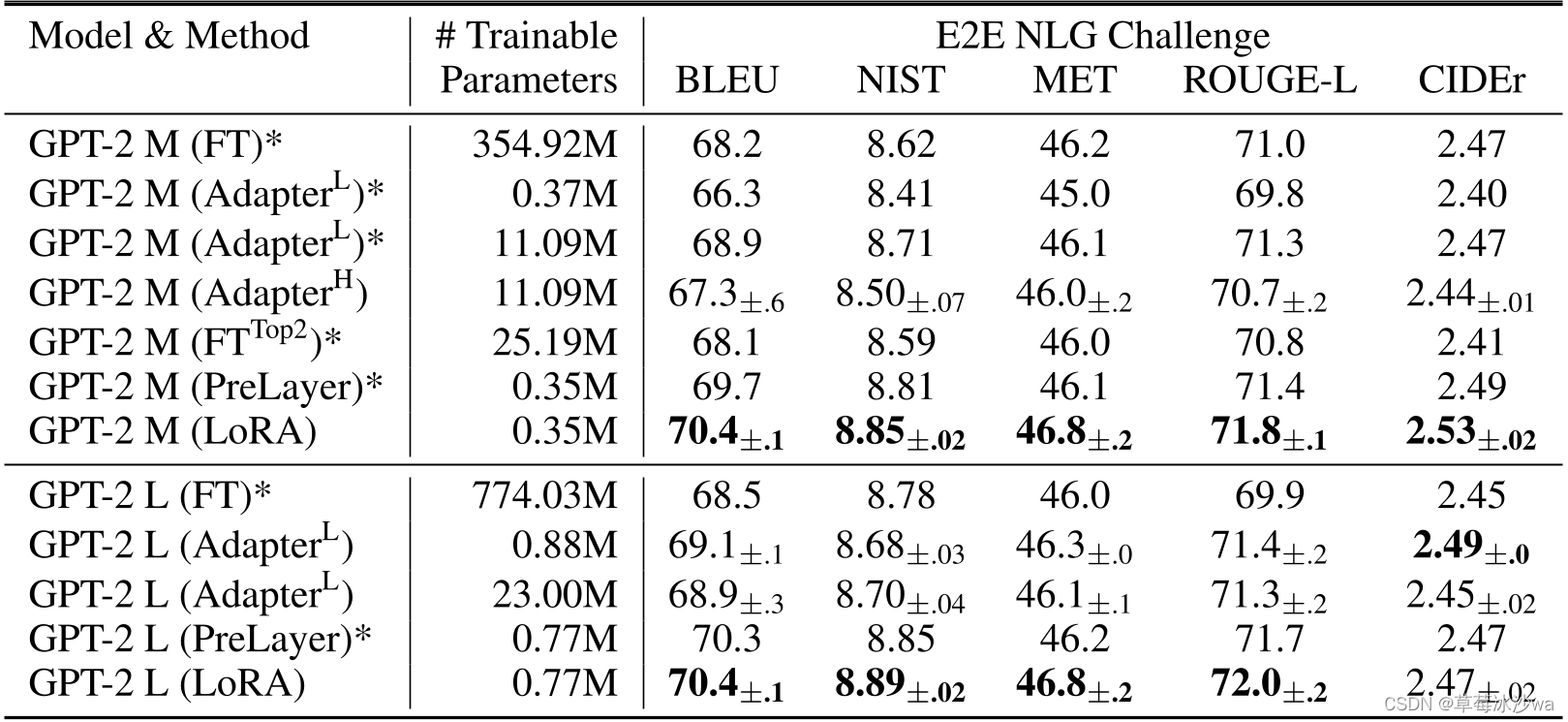
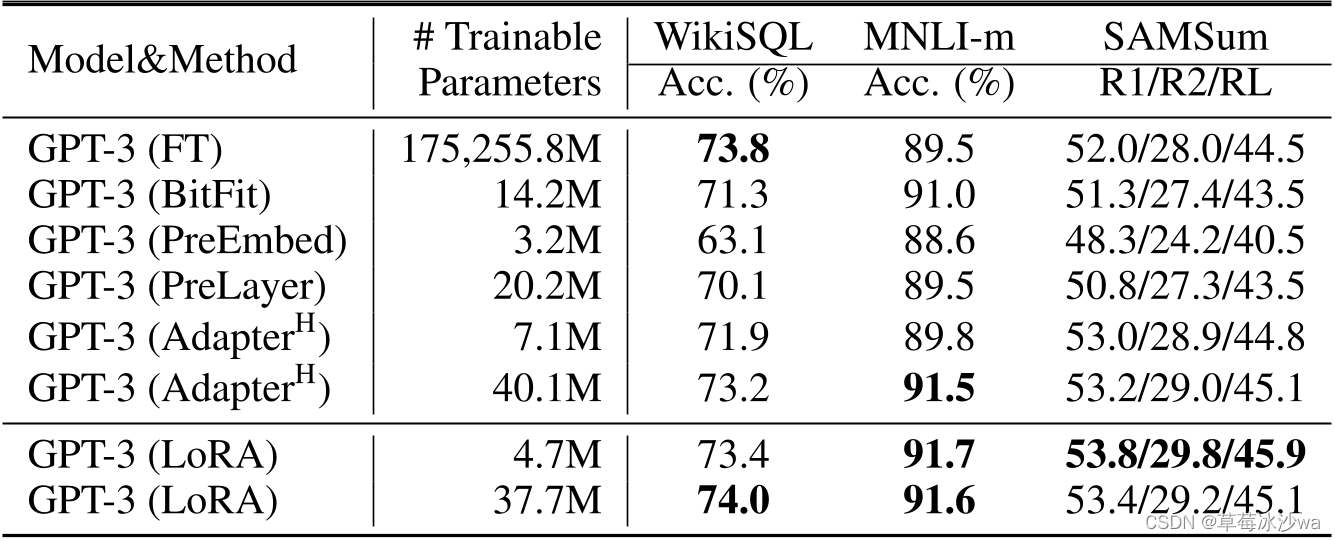
🚩 研究结论
1. 创新点
- 一个预训练好的模型可以被共享,用于为不同的任务构建许多小的LoRA模块
- 训练更加高效,在使用自适应优化器时,不需要对大多数参数进行梯度计算或保持优化器状态
- 简单线性设计允许在部署时将可训练矩阵与冻结权重合并,与完全微调的模型相比,没有引入推理延迟
- 与许多先验方法正交,并且可以与其中的许多方法相结合,例如前缀调优
2. LoRA优缺点
-
优点
- 内存和存储大大减少,对于使用Adam训练的大型Transformer,如果r<<dmodel内存将减少至原先的2/3。
- 仅交换LoRA权重而不是所有参数,以较低的成本在不同任务之间切换。
-
缺点
不同的任务,存在不同的参数 A 和 B。如果选择将 A 和 B 吸收到权重矩阵 W 中以消除额外的推理延迟,批处理操作比较复杂。如果对延迟不敏感,可以不合并权重,动态选择在批次中使用哪些 LoRA 模块。

















 645
645

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









