









MongoDB知识点总结
文章目录
一、MongoDB服务
启动MongoDB服务
net start MongoDB //启动
net stop MongoDB //关闭
C:\mongodb\bin\mongod.exe --remove //删除
连接MongoDB
-
连接MongoDB:
mongo localhost:27022 -
连接MongoDB的Return:
方案 返回 连接本机服务 mongodb://admin:123456@localhost/ 连接本机服务数据库 mongodb://admin:123456@localhost/test 连接服务器 mongodb://localhost,localhost:27018,localhost:27019
二、数据库操作
1、增删改
①数据库
- 创建/使用数据库:
use DATABASE_NAME(创建后不能立即查看,要先插数据才能看到) - 查看现在的数据库:
db - 查看所有数据库:
show dbs - 删除数据库:
db.dropDatabase()(先use切换数据库后再删除)
②集合
-
创建集合:
db.createCollection(name, options)参数说明:
name: 要创建的集合名称options: 可选参数, 指定有关内存大小及索引的选项
实例:
//创建固定集合 mycol,整个集合空间大小 6142800 B, 文档最大个数为 10000 个 db.createCollection("mycol", { capped : true, autoIndexId : true, size : 6142800, max : 10000 } ) -
查看当前数据库已有集合:
show collections / show tables在 MongoDB 中,你不需要创建集合。当你插入一些文档时,MongoDB 会自动创建与当前数据库名称相同的集合
-
删除集合:
db.collection.drop()
③文档内
-
插入一条
db.COLLECTION_NAME.insert(document)/db.COLLECTION_NAME.save(document)3.2版本后新增了
db.collection.insertOne()和db.collection.insertMany()示例:
db.col.insert({title: 'MongoDB 教程', description: 'MongoDB 是一个 Nosql 数据库', by: '菜鸟教程', url: 'http://www.runoob.com', tags: ['mongodb', 'database', 'NoSQL'], likes: 100 }) -
一次插入多条数据
1、先创建数组
2、将数据放在数组中
3、一次 insert 到集合中
var arr = []; for(var i=1 ; i<=20000 ; i++){ arr.push({num:i}); } db.numbers.insert(arr); -
更新:
updata()语法:
db.collection.update( <query>, <update>, { upsert: <boolean>, multi: <boolean>, writeConcern: <document> } )- query : update的查询条件,类似sql update查询内where后面的。
- update : update的对象和一些更新的操作符(如$inc…)等,也可以理解为sql update查询内set后面的
// $inc操作符将quantity减2,metrics.orders内嵌文档字段加1 db.products.update( { sku: "abc123" }, { $inc: { quantity: -2, "metrics.orders": 1 } } )- upsert : 可选,这个参数的意思是,如果不存在update的记录,是否插入objNew,true为插入,默认是false,不插入。
- multi : 可选,mongodb 默认是false,只更新找到的第一条记录,如果这个参数为true,就把按条件查出来多条记录全部更新。
- writeConcern :可选,抛出异常的级别。
实例:
// 修改 学号为2019000000的学生的电话号码为19912345678 var 查询条件 = {'sno':2019000000} var 更新操作 = { $set:{phone:'19912345678'} } // $set操作符,有这个字段就修改,没有这个字段就新增 db.students.update(查询条件,更新操作) db.students.find(查询条件) // 修改学号为2019000000 的学生, 删除role字段 var 查询条件 = {'sno':2019000000} var 更新操作 = { $unset:{'role':1} } // $unset 删除字段,删除操作不关心字段值是什么 db.students.update(查询条件,更新操作) db.students.find(查询条件) -
删除操作
db.collection.remove( <query>, <justOne> )- query :(可选)删除的文档的条件。
- justOne : (可选)如果设为 true 或 1,则只删除一个文档,如果不设置该参数,或使用默认值 false,则删除所有匹配条件的文档。
实例:
//条件删 >db.col.remove({'title':'MongoDB 教程'}) //justone删 >db.COLLECTION_NAME.remove(DELETION_CRITERIA,1) //全删 >db.col.remove({})
2、查询
//一般查询
db.collection.find(query, projection)
//漂亮查询
db.collection.find().pretty()
-
query :可选,使用查询操作符指定查询条件
第一个 {} 放 where 条件,为空表示返回集合中所有文档。
-
projection :可选,使用投影操作符指定返回的键。查询时返回文档中所有键值, 只需省略该参数即可(默认省略)
第二个 {} 指定那些列显示和不显示 (0表示不显示 1表示显示)。
query使用:
| 条件 | 语句 |
|---|---|
| and条件 | db.col.find({key1:value1, key2:value2}).pretty() |
| or条件 | db.col.find( { $or: [ {key1: value1}, {key2:value2} ] } ).pretty() |
| 操作 | 格式 | 范例 |
|---|---|---|
| 等于 | {<key>:<value>} | db.col.find({"by":"菜鸟教程"}).pretty() |
| 小于 | {<key>:{$lt:<value>}} | db.col.find({"likes":{$lt:50}}).pretty() |
| 小于或等于 | {<key>:{$lte:<value>}} | db.col.find({"likes":{$lte:50}}).pretty() |
| 大于 | {<key>:{$gt:<value>}} | db.col.find({"likes":{$gt:50}}).pretty() |
| 大于或等于 | {<key>:{$gte:<value>}} | db.col.find({"likes":{$gte:50}}).pretty() |
| 不等于 | {<key>:{$ne:<value>}} | db.col.find({"likes":{$ne:50}}).pretty() |
####limit() 的使用(限制查看几条)
db.COLLECTION_NAME.find().limit(NUMBER)
####sort() 的使用(排序)
db.COLLECTION_NAME.find().sort({KEY:1}) //1为升序,-1为降序
查询内嵌文档
用“.”表示法是查询文档区别于其他文档的主要特点。查询文档可以包含点,来表示深入内嵌文档内部。点表示法也是待插入的文档不能包含"."的原因。
> db.food.insert({"_id":4,"fruit":{"apple":"good","banana":"good"}});
> db.food.insert({"_id":5,"fruit":{"apple":"best","banana":"good"}});
> db.food.find({"fruit.apple":"good"});
{ "_id" : 4, "fruit" : { "apple" : "good", "banana" : "good" } }
> db.food.find({"fruit.apple":"best"});
{ "_id" : 5, "fruit" : { "apple" : "best", "banana" : "good" } }
3、Indexes() 集合索引
1、查看集合索引
db.col.getIndexes()
2、查看集合索引大小
db.col.totalIndexSize()
3、删除集合所有索引
db.col.dropIndexes()
4、删除集合指定索引
db.col.dropIndex("索引名称")
4、正则表达式
以下命令使用正则表达式查找包含 runoob 字符串的文章:
Document=
{
"post_text": "enjoy the mongodb articles on runoob",
"tags": [
"mongodb",
"runoob"
]
}
//查询,两者等价
db.posts.find({post_text:{$regex:"runoob"}})
db.posts.find({post_text:/runoob/})
不区分大小写的正则表达式:
db.posts.find({post_text:{$regex:"runoob",$options:"$i"}})
数组元素使用正则表达式:
我们还可以在数组字段中使用正则表达式来查找内容。 这在标签的实现上非常有用,如果你需要查找包含以 run 开头的标签数据(ru 或 run 或 runoob), 你可以使用以下代码:
db.posts.find({tags:{$regex:"run"}})
5、aggragate操作
在MongoDB中,有两种方式计算聚合:Pipeline 和 MapReduce。Pipeline查询速度快于MapReduce,但是MapReduce的强大之处在于能够在多台Server上并行执行复杂的聚合逻辑。MongoDB不允许Pipeline的单个聚合操作占用过多的系统内存,如果一个聚合操作消耗20%以上的内存,那么MongoDB直接停止操作,并向客户端输出错误消息。
①Pipline aggragate
MongoDB 中聚合(aggregate)主要用于处理数据(诸如统计平均值,求和等),并返回计算后的数据结果。
有点类似 SQL 语句中的 count(*)。
语法:
db.COLLECTION_NAME.aggregate(AGGREGATE_OPERATION)
先来看一个分组的例子,本例中$group是一个管道操作符,获得的结果可以接着输出到下一个管道,而内部的$sum是一个表达式操作符:
将document分组,用作统计结果
db.Ubisoft.aggregate([ // aggregate方法接收的是一个数组
{
$group: {
_id: '$time',
num: {$sum: 1}
}
}
])
// 这里的_id字段表示你要基于哪个字段来进行分组(即制定字段值相同的为一组),这里的$time就表示要基于time字段来进行分组
// 下面的num字段的值$sum: 1表示的是获取满足time字段相同的这一组的数量乘以后面给定的值(本例为1,那么就是同组的数量)。
mongoDB中还有其他的一些管道操作符和表达式操作符:
管道操作符:
| 常用管道 | 含义 |
|---|---|
| $group | 将collection中的document分组,可用于统计结果 |
| $match | 过滤数据,只输出符合结果的文档 |
| $project | 修改输入文档的结构(例如重命名,增加、删除字段,创建结算结果等) |
| $sort | 将结果进行排序后输出 |
| $limit | 限制管道输出的结果个数 |
| $skip | 跳过制定数量的结果,并且返回剩下的结果 |
| $unwind | 将数组类型的字段进行拆分 |
表达式操作符:
| 常用表达式 | 含义 |
|---|---|
| $sum | 计算总和,{$sum: 1}表示返回总和×1的值(即总和的数量),使用{$sum: ‘$制定字段’}也能直接获取制定字段的值的总和 |
| $avg | 平均值 |
| $min | min |
| $max | max |
| $push | 将结果文档中插入值到一个数组中 |
| $first | 根据文档的排序获取第一个文档数据 |
| $last | 同理,获取最后一个数据 |
####②pipline实例
组合查询:
Document =
//新建一个集合grade_1_4,记录一年级四班在期中考试时的成绩;
for (var i = 1; i <= 10; i++) {
db.grade_1_4.insert({
"name": "zhangsan" + i,
"sex": Math.round(Math.random() * 10) % 2,
"age": Math.round(Math.random() * 6) + 3,
"score": {
"chinese": 60 + Math.round(Math.random() * 40),
"math": 60 + Math.round(Math.random() * 40),
"english": 60 + Math.round(Math.random() * 40)
}
});
}
//统计每名男生在考试中的总分和平均分
db.grade_1_4.aggregate([{$match: {sex: 1}}, {$group: {_id: '$name',sum_score: {$sum: {$sum: ["$score.chinese", "$score.math", "$score.english"]}},
avg_score: {$avg: {$avg: ["$score.chinese", "$score.math", "$score.english"]}}}}])
//统计每名男生在考试中的总分, 总分降序
db.grade_1_4.aggregate([{$match: {sex: 1}}, {$group: {_id: '$name',sum_score: {$sum: {$sum: ["$score.chinese", "$score.math", "$score.english"]}}}}, {
$sort: {sum_score: - 1}}])
组合更改并显示:
那么我们现在如果想拿到所有time>=20的document的name字段的话,可以把管道搭配起来用:
db.Ubisoft.aggregate([
{
$match: {
time: {$gte: 20}
}
},
{
$project: {
_id: 0, // _id不显示
name: 1 // name是要显示的
}
},
{
$group: {
_id: null,
name: {$push: '$name'}
}
}
])
数组展开并查询:
$unwind管道可以document中的数组类型的字段进行拆分,每条包含数组中的一个值。
Document =
{
"_id" : ObjectId("5b0e242ed85f6f9cc56da7cc"),
"name" : "gameList",
"list" : [
"dota2",
"csgo",
"ow"
]
}
//拆开:
db.Ubisoft.aggregate([
{
$unwind: '$list' // 指定list字段
}
])
//output:
/* 1 */
{
"_id" : ObjectId("5b0e242ed85f6f9cc56da7cc"),
"name" : "gameList",
"list" : "dota2"
}
/* 2 */
{
"_id" : ObjectId("5b0e242ed85f6f9cc56da7cc"),
"name" : "gameList",
"list" : "csgo"
}
/* 3 */
{
"_id" : ObjectId("5b0e242ed85f6f9cc56da7cc"),
"name" : "gameList",
"list" : "ow"
}
③MapReduce
使用MapReduce方式计算聚合,主要分为三步:Map,Shuffle(拼凑)和Reduce,Map和Reduce需要显式定义,shuffle由MongoDB来实现。
- Map:将操作映射到每个doc,产生Key和Value,例如,Map一个doc,产生(female,{count:1}),female是Key,value是{count:1}
- Shuffle:按照Key进行分组,并将key相同的Value组合成数组,例如,产生(female,[{count:1},{count:1},{count:1},{count:1},])
- Reduce:把Value数组化简为单值,例如,产生(femal,{count:21})
④MapReduce示例:
统计集合foo中不同age的数量
step1,定义Map 和 Reduce函数
Map函数的作用是对每个doc进行一次映射,返回age 和 {count:1};
经过Shuffle,每个age都有一个列表:[{count:1},{count:1},{count:1},{count:1},],有多少个不同的age,MongoDB都会调用多少次Reduce函数,每次调用时,Key值是不同的。
Reduce函数的作用:对MongoDB的一次调用,对age对应的列表进行聚合运算。
map=function ()
{
emit(this.age,{count:1});
}
reduce= function (key,emits)
{
total=0;
for(var i in emits)
{
total+=emits[i].count;
}
return {"age":key,count:total};
}
step2,执行MapReduce聚合运算
mr=db.runCommand(
{
"mapreduce":"foo",
"map":map,
"reduce":reduce,
out:"Count Doc"
})
step3,查看聚合运算的结果
db[mr.result].find()

统计每名男生在考试中的总分(展开数组并求和):
db.grade_1_4.mapReduce(function(){emit(this.name,this.score.chinese+this.score.math+this.score.english)},function(key,values){return Array.sum(values)},
{query:{"sex":1},out:"sum_score"})
db.sum_score.find()
7、游标遍历&循环遍历
游标:db.collection.find()
定义一个变量来保存这个游标:var cursor=db.items.find()
用一个变量来保存游标,不会自动输出数据的,需要我们自己实现这个查询结果的游标进行遍历。
对游标进行遍历
var cursor=db.items.find()
while(cursor.hasNext()){
var doc = cursor.next();
printjson(doc);
};
forEach()循环遍历:
cursor.forEach( function(doc) { printjson(doc);});
遍历实例:
//统计每名学生在考试中的总分 ,要求在显示
// 姓名:总分
db.grade_1_4.find().forEach(function(item) {
// Array_score = item.score.toArray()
print("姓名:总分")
print(item.name + ": " + (item.score.chinese + item.score.math + item.score.english))})
value:遍历的数组内容;index:对应的数组索引,array:数组本身
8、Pymongo
①创建数据库
#!/usr/bin/python3
//判断指定的数据库是否存在
import pymongo
myclient = pymongo.MongoClient('mongodb://localhost:27017/')
dblist = myclient.list_database_names()
# dblist = myclient.database_names()
if "runoobdb" in dblist:
print("数据库已存在!")
//判断集合是否已存在
#!/usr/bin/python3
import pymongo
myclient = pymongo.MongoClient('mongodb://localhost:27017/')
mydb = myclient['runoobdb']
collist = mydb. list_collection_names()
# collist = mydb.collection_names()
if "sites" in collist: # 判断 sites 集合是否存在
print("集合已存在!")
②添加文档
//插入多个文档
#!/usr/bin/python3
import pymongo
myclient = pymongo.MongoClient("mongodb://localhost:27017/")
mydb = myclient["runoobdb"]
mycol = mydb["sites"]
mylist = [
{ "name": "Taobao", "alexa": "100", "url": "https://www.taobao.com" },
{ "name": "QQ", "alexa": "101", "url": "https://www.qq.com" },
{ "name": "Facebook", "alexa": "10", "url": "https://www.facebook.com" },
{ "name": "知乎", "alexa": "103", "url": "https://www.zhihu.com" },
{ "name": "Github", "alexa": "109", "url": "https://www.github.com" }
]
x = mycol.insert_many(mylist)
# 输出插入的所有文档对应的 _id 值
print(x.inserted_ids)
//插入指定 _id 的多个文档
#!/usr/bin/python3
import pymongo
myclient = pymongo.MongoClient("mongodb://localhost:27017/")
mydb = myclient["runoobdb"]
mycol = mydb["site2"]
mylist = [
{ "_id": 1, "name": "RUNOOB", "cn_name": "菜鸟教程"},
{ "_id": 2, "name": "Google", "address": "Google 搜索"},
{ "_id": 3, "name": "Facebook", "address": "脸书"},
{ "_id": 4, "name": "Taobao", "address": "淘宝"},
{ "_id": 5, "name": "Zhihu", "address": "知乎"}
]
x = mycol.insert_many(mylist)
# 输出插入的所有文档对应的 _id 值
print(x.inserted_ids)
####③查询
#!/usr/bin/python3
import pymongo
myclient = pymongo.MongoClient("mongodb://localhost:27017/")
mydb = myclient["runoobdb"]
mycol = mydb["sites"]
myquery = { "name": { "$regex": "^R" } }
mydoc = mycol.find(myquery)
for x in mydoc:
print(x)
9、ACID性质
1、A (Atomicity) 原子性
原子性很容易理解,也就是说事务里的所有操作要么全部做完,要么都不做,事务成功的条件是事务里的所有操作都成功,只要有一个操作失败,整个事务就失败,需要回滚。
比如银行转账,从A账户转100元至B账户,分为两个步骤:1)从A账户取100元;2)存入100元至B账户。这两步要么一起完成,要么一起不完成,如果只完成第一步,第二步失败,钱会莫名其妙少了100元。
2、C (Consistency) 一致性
一致性也比较容易理解,也就是说数据库要一直处于一致的状态,事务的运行不会改变数据库原本的一致性约束。
例如现有完整性约束a+b=10,如果一个事务改变了a,那么必须得改变b,使得事务结束后依然满足a+b=10,否则事务失败。
3、I (Isolation) 独立性
所谓的独立性是指并发的事务之间不会互相影响,如果一个事务要访问的数据正在被另外一个事务修改,只要另外一个事务未提交,它所访问的数据就不受未提交事务的影响。
比如现在有个交易是从A账户转100元至B账户,在这个交易还未完成的情况下,如果此时B查询自己的账户,是看不到新增加的100元的。
4、D (Durability) 持久性
持久性是指一旦事务提交后,它所做的修改将会永久的保存在数据库上,即使出现宕机也不会丢失。
三、Shard切片操作
1、MongoDB复制原理
mongodb的复制至少需要两个节点。其中一个是主节点,负责处理客户端请求,其余的都是从节点,负责复制主节点上的数据。
mongodb各个节点常见的搭配方式为:一主一从、一主多从。
主节点记录在其上的所有操作oplog,从节点定期轮询主节点获取这些操作,然后对自己的数据副本执行这些操作,从而保证从节点的数据与主节点一致。
MongoDB复制结构图如下所示:
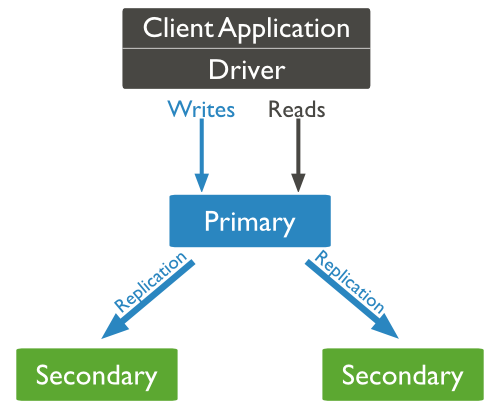
以上结构图中,客户端从主节点读取数据,在客户端写入数据到主节点时, 主节点与从节点进行数据交互保障数据的一致性。
副本集特征:
- N 个节点的集群
- 任何节点可作为主节点
- 所有写入操作都在主节点上
- 自动故障转移
- 自动恢复
2、MongoDB分片
在Mongodb里面存在另一种集群,就是分片技术,可以满足MongoDB数据量大量增长的需求。
当MongoDB存储海量的数据时,一台机器可能不足以存储数据,也可能不足以提供可接受的读写吞吐量。这时,我们就可以通过在多台机器上分割数据,使得数据库系统能存储和处理更多的数据。
下图展示了在MongoDB中使用分片集群结构分布:
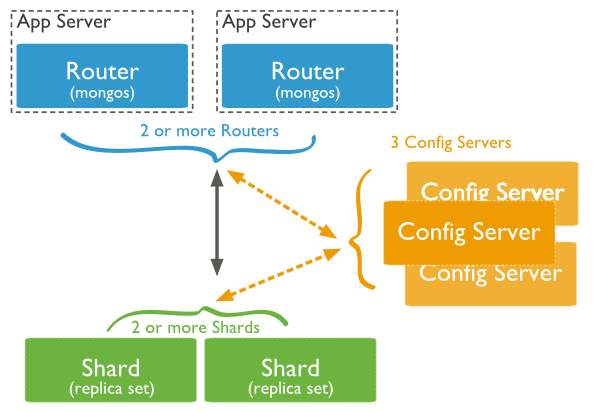
上图中主要有如下所述三个主要组件:
-
Shard:
用于存储实际的数据块,实际生产环境中一个shard server角色可由几台机器组个一个replica set承担,防止主机单点故障
-
Config Server:
mongod实例,存储了整个 ClusterMetadata,其中包括 chunk信息。
-
Query Routers:
前端路由,客户端由此接入,且让整个集群看上去像单一数据库,前端应用可以透明使用。
为什么使用分片:
- 复制所有的写入操作到主节点
- 延迟的敏感数据会在主节点查询
- 单个副本集限制在12个节点
- 当请求量巨大时会出现内存不足。
- 本地磁盘不足
- 垂直扩展价格昂贵
以上结构图中,客户端从主节点读取数据,在客户端写入数据到主节点时, 主节点与从节点进行数据交互保障数据的一致性。
副本集特征:
- N 个节点的集群
- 任何节点可作为主节点
- 所有写入操作都在主节点上
- 自动故障转移
- 自动恢复














 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









