LSA潜在语义分析算法
import numpy as np
import jieba
import collections
class LSA:
def __init__(self,text_list):
self.text_list = text_list
self.text_num = len(text_list)
self.get_X()
def get_X(self):
self.cuted_text = [jieba.lcut(text,cut_all=True) for text in self.text_list]
self.word_all = []
for i in self.cuted_text:
self.word_all.extend(i)
self.word_set = list(set(self.word_all))
self.word_num = len(self.word_set)
self.word_dict = {}
for index,word in enumerate(self.word_set):
self.word_dict[word] = index
self.X = np.zeros((self.word_num,self.text_num))
self.word_IDF = {word:0 for word in self.word_set}
for i in self.cuted_text:
for word in set(i):
self.word_IDF[word] += 1
for i in range(self.text_num):
count_ = collections.Counter(self.cuted_text[i])
tf_sum = len(self.cuted_text[i])
for k, v in count_.items():
self.X[self.word_dict[k],i] = v/tf_sum * np.log(self.text_num/self.word_IDF[k])
def norm_w(self):
norm = 1 / np.array([np.sqrt(np.sum(self.W[:, x] ** 2)) for x in range(self.k)])
for i in range(self.k):
self.W[:, i] = self.W[:, i] * norm[i]
def SVD(self,k):
u,s,v = np.linalg.svd(self.X)
return u[:,:k],s[:k].dot(v[:,:k].T)
def nonegetive(self,k,max_iter,way='MES'):
self.k = k
self.W = np.random.random((self.word_num, self.k))
self.H = np.random.random((self.k, self.text_num))
if way == 'MES':
for iter in range(max_iter):
self.norm_w()
n_w = (self.X.dot(self.H.T))
m_w = (self.W.dot(self.H).dot(self.H.T))
n_h = (self.W.T.dot(self.X))
m_h = self.W.T.dot(self.W).dot(self.H)
for j in range(self.k):
for i in range(self.word_num):
self.W[i,j] = self.W[i,j] * n_w[i,j]/m_w[i,j]
for i in range(self.text_num):
self.H[j,i] = self.H[j,i] * n_h[j,i]/m_h[j,i]
self.norm_w()
if way == 'DIV':
for iter in range(max_iter):
self.norm_w()
W = self.W
for k_ in range(self.k):
for i in range(self.word_num):
self.W[i,k_] = self.W[i,k_]*np.sum(self.H[k_].dot(self.X[i])\
/(self.W.dot(self.H)[i]))/np.sum(self.H[k_])
for k_ in range(self.k):
for j in range(self.text_num):
self.H[k_,j] = self.H[k_,j]*np.sum(W[:,k_].dot(self.X[:,j])\
/(W.dot(self.H)[:,j]))/np.sum(W[:,k_])
self.norm_w()
def main():
text_list = [……]
lsa = LSA(text_list)
lsa.nonegetive(2,100,way='MES')
print(lsa.W)
print(lsa.H)
if __name__ == '__main__':
main()
散度损失非负矩阵分解算法推导

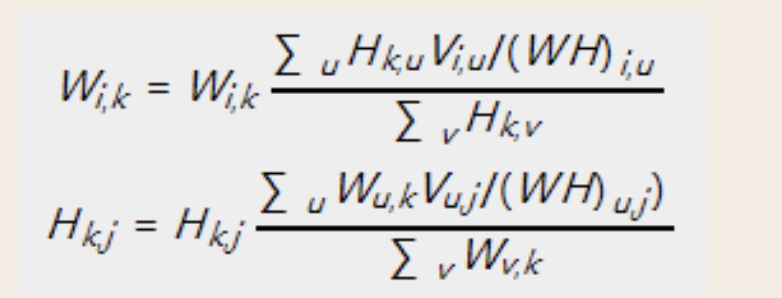























 176
176











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









