







文本增广是什么牛马,我只需要简单Dropout两下
Sentence Embeddings与对比学习
最近又又又又被对比学习刷爆了!抓紧时间蹭热度!
Sentence Embeddings:即能表征句子语义的特征向量,获取这种特征向量的方法有无监督和有监督两种,在无监督学习中,我们首先会考虑利用预训练好的大型预训练模型获取 [ C L S ] [CLS] [CLS]或对句子序列纬度做MeanPooling来得到一个输入句子的特征向量。在笔者之前的文章中就利用这一方法获取论文中所有句子的特征向量后传入DGCNN来抽取摘要。
但这种方法被证明了有一个致命的缺点即: Anisotropy(各向异性) - language models trained with tied input/output embeddings lead to anisotropic word embeddings. 通俗来说就是在我们熟悉的预训练模型训练过程中会导致word embeddings的各维度的特征表示不一致。导致我们获取的句子级别的特征向量也无法进行直接比较。
目前比较流行解决这一问题的方法有
- 线性变换:bert-flow 或 bert-whitening,无论是在bert中增加flow层还是对得到句子向量矩阵进行白化其本质都是通过一个线性变换来缓解Anisotropy。
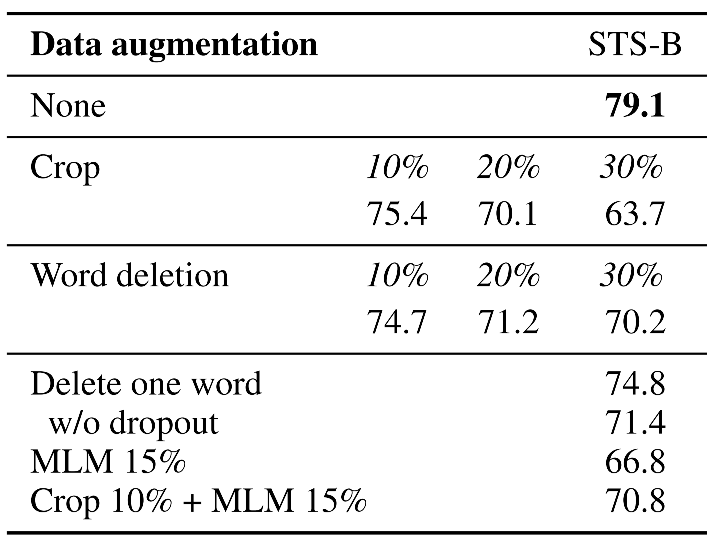
- 对比学习:先对句子进行传统的文本增广,如转译、删除、插入、调换顺序等等,再将一个句子通过两次增广得到的新句子作为正样本对,取其他句子的增广作为负样本,进行对比学习,模型的目标也很简单,即拉近正样本对的embeddings,同时增加与负样本的距离。
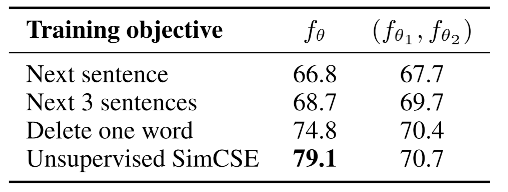
- 而本篇文章的主角 SimCSE: Simple Contrastive Learning of Sentence Embeddings,发现利用预训练模型中自带的Dropout mask作为“增广手段”得到的Sentence Embeddings,其质量远好于传统的增管方法,其无监督和有监督方法无监督语义上达到SOTA。
本文会简单分析论文的核心思想,并给出无监督与有监督方法的复现,以及其在中文数据集上的表现。
无监督代码参考了 https://github.com/bojone/SimCSE,笔者则是用pytorch进行复现。
SimCSE

无监督Dropout
- 利用模型中的Dropout mask,对每一个句子进行两次前向传播(论文中是从维基百科中随机选取了100w个句子进行训练),得到两个不同的embeddings向量,将同一个句子得到的向量对作为正样本对,对于每一个向量,选取其他句子产生的embeddings向量作为负样本,以此来训练模型。
- 训练损失函数为 l i = − l o g e s i m ( h i , h i + ) / r ∑ j = 1 N e s i m ( h i , h j + ) / r l_i =-log\frac{e^{sim(h_i,h_i^+)/r}} {\sum_{j=1}^Ne^{sim(h_i,h_j^+)/r}} li=−log∑j=1Nesim(hi,hj+)/resim(hi,hi+)/r, 其中 s i m ( h 1 , h 2 ) = h 1 T h 2 ∣ ∣ h 1 ∣ ∣ ⋅ ∣ ∣ h 2 ∣ ∣ sim(h_1,h_2)=\frac{h_1^Th2}{||h_1||·||h_2||} sim(h1,h2)=∣∣h1∣∣⋅∣∣h2∣∣h1Th2
- How to use Dropout mask? 对于带有Dropout的模型,在训练过程中Dropout都是打开的,且对于每个不同样本其在前向传播的过程中Dropout都不是固定一致的,因此我们不需要做其他额外的设置,只需要将每个句子copy两份传入模型即可。
- 如何采样负样本?论文采取了我们熟悉的In-batch training即将同一个batch中其他不同源句子产生的dropout 增广embedding作为负样本,即损失函数中的 h j + h_j^+ hj+
- 损失函数解读:
- 为什么在计算相似度时我们需要对句子向量做L2正则?张俊林:对比学习研究进展精要给出了一个非常形象的解释,这样做的目的是将所有的句子向量映射在一个半径为1的超球体上,一方面我们将所有向量统一至单位长度,去除了长度信息是为了让模型的训练更加稳定;另一方面如果模型的表示能力足够好,能够把相似的句子在超球面上聚集到较近区域,那么很容易使用线性分类器把某类和其它类区分开(参考下图)。当然在图像领域上很多实验也证明了,增加L2正则确实能提升模型效果。

- 为什么 s i m ( h i , h i + ) / r sim(h_i,h_i^+)/r sim(hi,hi+)/r中 温度超参 r r r 的作用:笔者调研到了两种解释:1. 如果直接使用sim相似度计算得到的值作为softmax的logist输入,由于其取值范围仅在[-1,1]之间, l o s s ( l o g i s t = [ − 1 , 1 , − 1 ] , y = [ 0 , 1 , 0 ] ) ! = 0 loss(logist=[-1,1,-1],y=[0,1,0]) !=0 loss(logist=[−1,1,−1],y=[0,1,0])!=0这显然是不合理的,且logist范围太小导致softmax对正负样本无法给出足够大的差距,模型训练不充分,所以我们需要对相似度值进行修正,除以一个足够小的温度参数进行放大。2. 温度参数会将模型更新的重点,聚焦到有难度的负例,并对它们做相应的惩罚,难度越大,也即是与 h i h_i hi距离越近,则分配到的惩罚越多。这其实也比较好理解,我们将 s i m ( h i , h j + ) / r sim(h_i,h_j^+)/r sim(hi,hj+)/r相当于同比例放大了负样本的logist值,如果r足够小,那么那些sim(h_i,h_j^+)越靠近1的负样本,其放大后会占主导(负样本间绝对差距在变大)。
- 为什么在计算相似度时我们需要对句子向量做L2正则?张俊林:对比学习研究进展精要给出了一个非常形象的解释,这样做的目的是将所有的句子向量映射在一个半径为1的超球体上,一方面我们将所有向量统一至单位长度,去除了长度信息是为了让模型的训练更加稳定;另一方面如果模型的表示能力足够好,能够把相似的句子在超球面上聚集到较近区域,那么很容易使用线性分类器把某类和其它类区分开(参考下图)。当然在图像领域上很多实验也证明了,增加L2正则确实能提升模型效果。
- 实验结果:SimCSE在STS-B数据集上的验证表现远好于传统的增广对比方法。
有监督对比学习
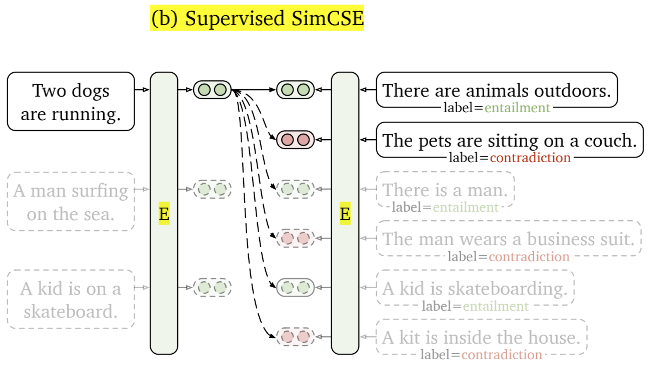
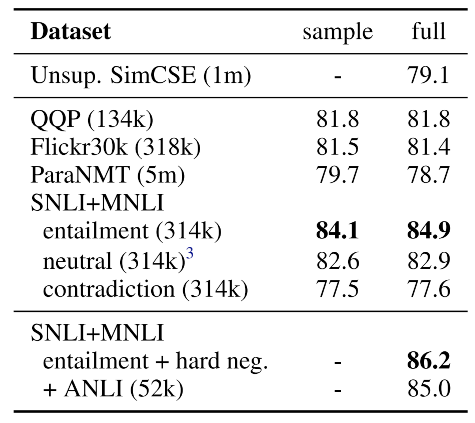
- 有监督对比学习最终选择了利用SNLI+MNLI数据集(For each premise and its entailment
hypothesis, there is an accompanying contradiction hypothesis) ,与无监督方法类似,将每一个premise和与其相对的entailment作为正样本对,把其对应的contradiction和同一个batch中其他premise的entailment和contradiction作为负样本训练即可。 - 训练损失函数为 l i = − l o g e s i m ( h i , h i + ) / r ∑ j = 1 N ( e s i m ( h i , h j + ) / r + e s i m ( h i , h j − ) / r ) l_i =-log\frac{e^{sim(h_i,h_i^+)/r}} {\sum_{j=1}^N(e^{sim(h_i,h_j^+)/r}+e^{sim(h_i,h_j^-)/r})} li=−log∑j=1N(esim(hi,hj+)/r+esim(hi,hj−)/r)esim(hi,hi+)/r
- 作者对比了在不同数据集上进行训练后在STS-B上的验证表现,并且实验结果表明引入hard neg能提高模型的效果。并且对于有多个contradiction的premise,作者只随机抽取了一个作为hard neg,使用多个hard neg对结果并没有提升。
- 并且作者在数学上证明了当负样本数量趋近于无限时,loss的分母限制了
S
u
m
(
W
W
T
)
Sum(WW^T)
Sum(WWT)的上限,而
S
u
m
(
W
W
T
)
Sum(WW^T)
Sum(WWT)又是相似度矩阵
W
W
W最大特征值的上限,因此起到了“flatten”的作用,可以缓解Anisotropy问题,“tackle the representation degeneration problem and improve the uniformity.”
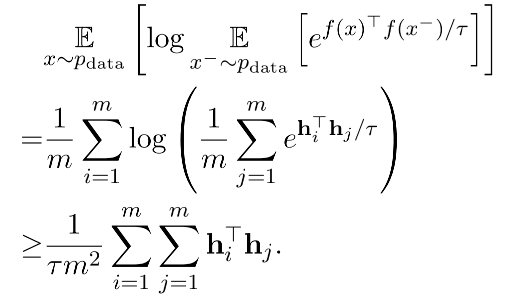
如何评判Sentence Embeddings的质量
对于分析Sentence Embeddings在空间上分布的质量,论文引用了 Wang and Isola (2020)的 Alignment and uniformity理论,引入了Alignment ,uniformity两个评价指标。
- Alignment:衡量相似样本对应的特征向量在空间上分布的距离是否足够近
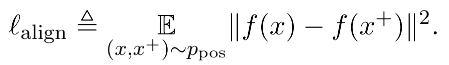
- Uniformity:衡量系统保留信息的多样性:映射到单位超球面的特征,尽可能均匀地分布在球面上,分布得越均匀,意味着保留的信息越充分。
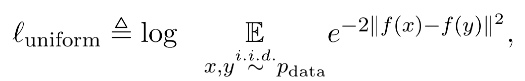
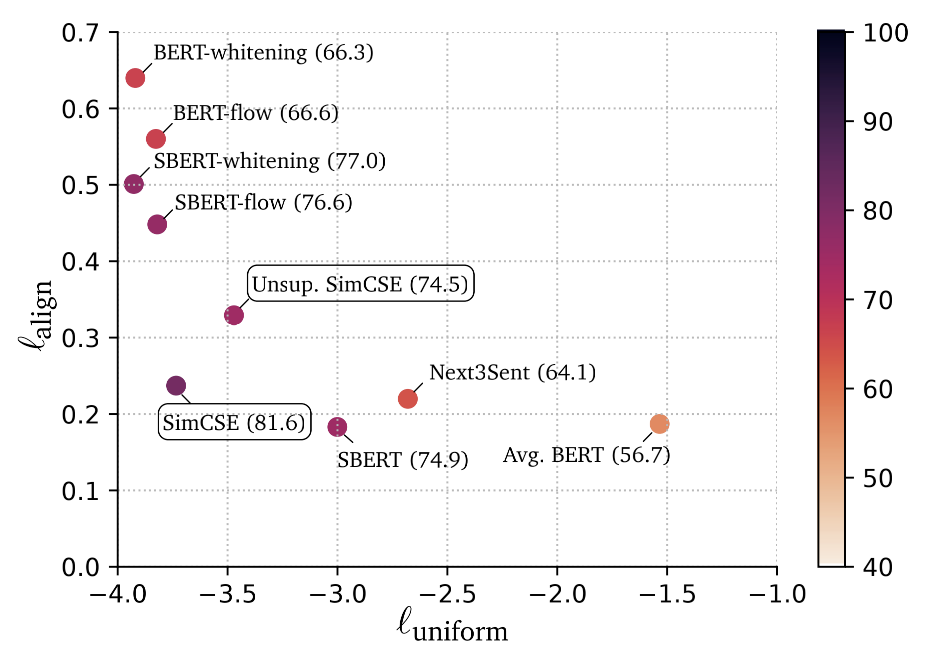
- 作者将不同方法得到的Sentence Embeddings空间的Alignment和Uniformity指标进行比对(两个指标均为越小越好),通过下图我们可以得到相比于直接使用预训练的Bert,SimCSE方法较大程度提升了uniformity,这与我们之前的论证符合。与Bert-flow和Bert-whitening这类线性变换方法相比,SimCSE则通过拉近相似句子之间的空间距离,在Alignment上有较大的优势。总体来说SimCSE通过无监督/有监督的对比训练方法在保持Alignment的同时提高了句子向量在特征空间分布的均匀性。
实验结果
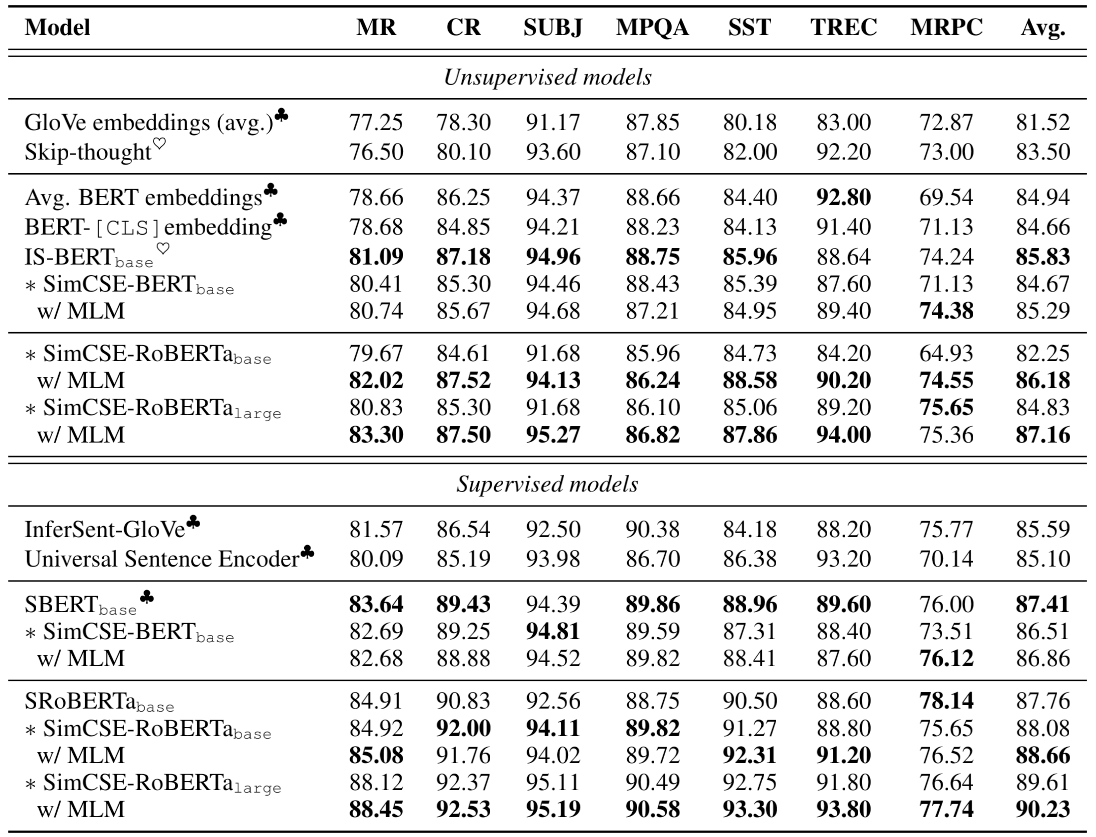
- 总体结果没有什么好分析的,通过数据对比图我们可以知道SimCSE在多个数据集上都达到了SOTA,并且作者发现,在原有的训练目标的基础上加入MLM预训练目标,将两个目标的loss按比例相加一起训练 l + λ ⋅ l m l m l+λ·l^{mlm} l+λ⋅lmlm (λ is a hyperparameter). 能够防止SimCSE忘记token级别的知识,从而提升模型效果。
复现
无监督Dropout
- 根据苏神的复现实验,调整了论文中的最优参数,即dropout_rate = 0.3, batch_size = 64, learning_rate = 1e-5。
- 训练数据来自中文SNLI和STS-B的训练集中的句子集,并且在STS-B的验证集和测试集上进行测试。
- 自定义损失函数,利用torch自带的cosine_similarity我们能快速实现句子相似度矩阵的计算,具体损失函数代码如下,与论文中的Loss公示保持一致
def compute_loss(y_pred,lamda=0.05):
idxs = torch.arange(0,y_pred.shape[0],device='cuda')
y_true = idxs + 1 - idxs % 2 * 2
similarities = F.cosine_similarity(y_pred.unsqueeze(1), y_pred.unsqueeze(0), dim=2)
#torch自带的快速计算相似度矩阵的方法
similarities = similarities-torch.eye(y_pred.shape[0],device='cuda') * 1e12
#屏蔽对角矩阵即自身相等的loss
similarities = similarities / lamda
#论文中除以 temperature 超参 0.05
loss = F.cross_entropy(similarities,y_true)
return torch.mean(loss)
- 通过阅读论文的源码,笔者发现原作者使用了预训练模型的 P o o l e r ( C L S + D e n s e ) Pooler(CLS+Dense) Pooler(CLS+Dense)作为句子的特征向量,因此笔者同时比较了 [ C L S ] [CLS] [CLS]和 P o o l e r Pooler Pooler的两种句子向量的方法的效果。
- 完整代码参考笔者Github https://github.com/zhengyanzhao1997/NLP-model/blob/main/model/model/Torch_model/SimCSE-Chinese/train_unsupervised.py代码整体比较简洁,可读性较强嘻嘻(自卖自夸一波)
有监督对比学习
- 有监督学习则利用中文SNLI数据集作为有监督训练,并同样在STS-B的验证集和测试集上进行测试。
- 笔者同样比较了不同batch_size以及选取 [ C L S ] [CLS] [CLS]或 P o o l e r Pooler Pooler的效果。
- 与无监督不同的是,在原论文中有监督学习是三个句子为一组 ( x , x + , x − ) (x,x^+,x^-) (x,x+,x−),并且 x x x只将 x + x^+ x+作为正样本,只将 x − x^- x−与其他句子的 x j + x_j^+ xj+和 x j − x_j^- xj−作为负样本,因此在处理相似度矩阵时,我们需要使用torch.index_select对矩阵进行切片操作。具体损失函数代码如下:
def compute_loss(y_pred,lamda=0.05):
row = torch.arange(0,y_pred.shape[0],3,device='cuda')
col = torch.arange(y_pred.shape[0], device='cuda')
col = torch.where(col % 3 != 0)[0].cuda()
y_true = torch.arange(0,len(col),2,device='cuda')
similarities = F.cosine_similarity(y_pred.unsqueeze(1), y_pred.unsqueeze(0), dim=2)
#torch自带的快速计算相似度矩阵的方法
similarities = torch.index_select(similarities,0,row)
# 按行选取 x
similarities = torch.index_select(similarities,1,col)
# 按列选取xj+ 与 xj-
similarities = similarities / lamda
#论文中除以 temperature 超参 0.05
loss = F.cross_entropy(similarities,y_true)
return torch.mean(loss)
- 完整代码参考笔者Github https://github.com/zhengyanzhao1997/NLP-model/blob/main/model/model/Torch_model/SimCSE-Chinese/train_supervised.py
测试结果
| 方法 | batch_size | 向量获取 | STS-B d e v _{dev} dev | STS-B t e s t _{test} test | 所需样本数 |
|---|---|---|---|---|---|
| Pre-trained Bert | \ | \ | 32.37 | \ | \ |
| Fine-tune Sup. Bert | \ | \ | 53.84 | 50.26 | \ |
| Bert-whitening | \ | \ | 61.19 | \ | \ |
| Unsup. SimCSE | 64 | CLS | 69.40 | 75.47 | 8960 |
| Unsup. SimCSE | 64 | Pooler | 49.02 | 53.03 | 8320 |
| Sup. SimCSE | 64 | CLS | 76.63 | 80.25 | 42880 |
| Sup. SimCSE | 128 | CLS | 77.72 | 80.55 | 24320 |
| Sup. SimCSE | 128 | Pooler | 76.05 | 79.23 | 67840 |
总结
- 相比于Pre-trained Bert, Fine-tune Sup. Bert, Bert-whitening等模型,SimCSE有极大程度的优势,可以说是碾压。
- 对于Unsup. SimCSE来说, C L S CLS CLS的效果远好于 P o o l e r Pooler Pooler,且Unsup. SimCSE只需要8000+个句子样本即可收敛,且多样本反而会使效果变差。
- 对于Sup. SimCSE来说, B a t c h s i z e 128 + C L S Batchsize_{128} + CLS Batchsize128+CLS 达到最好效果,尽管 P o o l e r Pooler Pooler最终能得到接近的效果,但需要的数据量是 C L S CLS CLS的三倍左右。
补充思考
- 今天突然在思考一个很蠢的问题,讲了这么久对比学习,这对比到底是在哪里体现的?是因为存在正负样本就是对比学习了吗?
- 答案是:对比体现在我们最后用的cross_entropy,cross_entropy_loss的意义在于让模型拉近正样本距离的同时,远离负样本。记住!是同时!
参考资料
- SimCSE: Simple Contrastive Learning of Sentence Embeddings https://arxiv.org/abs/2104.08821
- 苏剑林. (Apr. 26, 2021). 《中文任务还是SOTA吗?我们给SimCSE补充了一些实验 》[Blog post]. Retrieved from https://kexue.fm/archives/8348
- 张俊林:对比学习研究进展精要 https://mp.weixin.qq.com/s/xYlCAUIue_z14Or4oyaCCg
代码开源:https://github.com/zhengyanzhao1997/NLP-model/blob/main/model/model/Torch_model/SimCSE-Chinese/

















 762
762

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









