







 本文比较了P-tuning和Conditional Layer Normalization在搜狐文本匹配大赛中的应用,探讨了这两种方法在多任务语义匹配中的效果。实验结果显示,Conditional_LN在性能上略微优于P-tuning,两者都提供了一种不改变模型结构的微调预训练模型的方式。
本文比较了P-tuning和Conditional Layer Normalization在搜狐文本匹配大赛中的应用,探讨了这两种方法在多任务语义匹配中的效果。实验结果显示,Conditional_LN在性能上略微优于P-tuning,两者都提供了一种不改变模型结构的微调预训练模型的方式。
语义匹配(二)搜狐文本匹配大赛BaseLine比较:P-tuning和Conditional_LN实现多任务文本匹配
比赛简介
- 关键词:文本匹配、多任务匹配
- 与我们接触的文本语意匹配任务相似:给定两个句子,判断两个句子语义是否相似。
- 本次比赛在原本的语义匹配的基础上将语义是否相似分成了【主题】一致判断、【事件】一致判断,并针对这两种判断标准给出了短文-短文、短文-长文、长文-长文匹配三种类型的语料。
数据样例
{
"source": "英国伦敦,20/21赛季英超第20轮,托特纳姆热刺VS利物浦。热刺本赛季18轮联赛是9胜6平3负,目前积33分排名联赛第5位。利物浦本赛季19轮联赛是9胜7平3负,目前积34分排名联赛第4位。从目前的走势来看,本场比赛从热刺的角度来讲,是非常被动的。最终,本场比赛的比分为托特纳姆热刺1-3利",
"target": " 北京时间1月29日凌晨4时,英超联赛第20轮迎来一场强强对话,热刺坐镇主场迎战利物浦。 热刺vs利物浦,比赛看点如下: 第一:热刺能否成功复仇?双方首回合,热刺客场1-2被利物浦绝杀,赛后穆里尼奥称最好的球队输了,本轮热刺主场迎战利物浦,借着红军5轮不胜的低迷状态,能否成功复仇? 第二:利物浦近",
"labelA": "1"
}
{
"source": "英国伦敦,20/21赛季英超第20轮,托特纳姆热刺VS利物浦。热刺本赛季18轮联赛是9胜6平3负,目前积33分排名联赛第5位。利物浦本赛季19轮联赛是9胜7平3负,目前积34分排名联赛第4位。从目前的走势来看,本场比赛从热刺的角度来讲,是非常被动的。最终,本场比赛的比分为托特纳姆热刺1-3利",
"target": " 北京时间1月29日凌晨4时,英超联赛第20轮迎来一场强强对话,热刺坐镇主场迎战利物浦。 热刺vs利物浦,比赛看点如下: 第一:热刺能否成功复仇?双方首回合,热刺客场1-2被利物浦绝杀,赛后穆里尼奥称最好的球队输了,本轮热刺主场迎战利物浦,借着红军5轮不胜的低迷状态,能否成功复仇? 第二:利物浦近",
"labelB": "0"
}
任务解读
- 如苏神在其博客中理解:一般来说,完成这个任务至少需要两个模型,毕竟A、B两种类型的分类标准是不一样的,如果要做得更精细的话,应该还要做成6个模型。但问题是,如果独立地训练6个模型,那么往往比较费力,而且不同任务之间不能相互借鉴来提升效果,所以很自然地我们应该能想到共享一部分参数变成一个多任务学习问题。
- 如果通过构建一个模型来提取文本语义,并将不同判断条件甚至是不同长度匹配作为额外的信息加入到模型中去来控制模型的判断标准。
即插即用的多任务模块
- 本文意在探索目前比较流行的基于P-tuning的任务提示模块,和苏神在其博客中介绍的Conditional Layer Normalization,探究这两个模块在文本多任务分类中的指挥作用,并进行比较。
- WHY P-tuning/Conditional LN: 作为两个可在任何语言模型中即插即用的辅助模块,P-tuning 和 Conditional LN可以让我们快速实现指挥模型并且可以完整利用预训练模型权重,只需要经过简单的微调即可。(这让我想到了关于可控文本生成中PPLM的图,我们的两个模块就像大象头上的那只老鼠,牵引着模型向我们期望的方向前进)

P-tuning
相关论文链接:GPT Understands, Too
- P-tuning,原本用于解决 传统的人工提示(prompt) 来控制GPT的生成文本,无法随着模型训练进行独立优化,而且依赖大量的人工设计和尝试。P-tuning将传统的人工提示Token替换为可训练的独立的Embedding,使其可以随着模型训练进行优化。这相当于让模型在训练的过程中自动计算最优的Prompt,从而在提高生产效果的同时减少了人工的实验成本。
- 对于BERT等MLM模型,我们可以利用其预训练预测掩码的任务特性,同样达到一些zero-shot的效果。如下图,我们通过设置“下面是MM新闻”作为人工提示,让模型对文本生产文本的类别名称,从而实现文本分类。
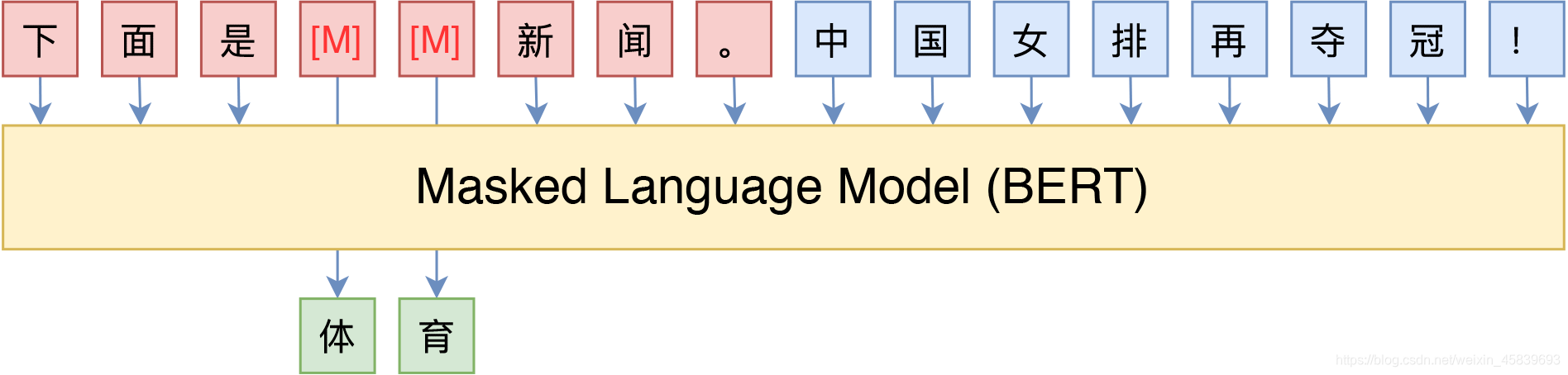
- 我们同样可以使用P-tuning的方法,如下图我们设置了u1-u6六个提示token,来替换上述的人工提示token,并在微调时同时对这6个token进行更新,从而最大化 m a x p r o m p t P ( x 分 类 ∣ p r o m p t , t e x t ) max_{prompt}P(x_{分类}|prompt,text) maxpromptP(x分类∣prompt,text)。
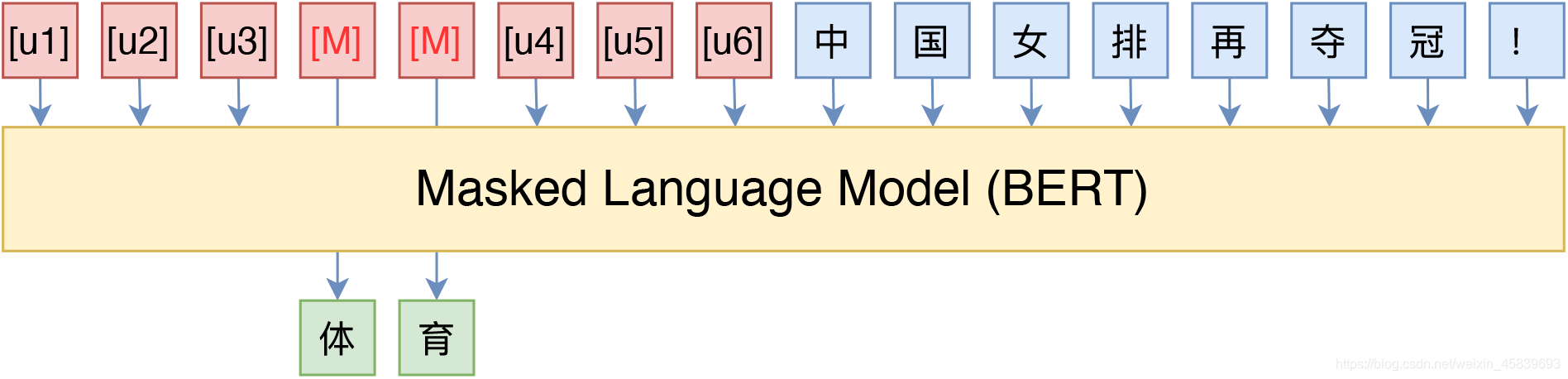
P-tuning多任务分类实现
- 根据不同的分类标准我们设置不同的prompt,目前开放的中文预训练模型bert-base,bert-wwm等都提供了多个 [ u n u s e d ] [unused] [unused] 的备用token,这类token在模型预训练时并未参与训练,利用这类token我们可以根据不同的分类标准构建不同的任务前缀token
{
"短短匹配A类": [1, 2, 3, 4, 9, 9],
"短短匹配B类": 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









