







目录
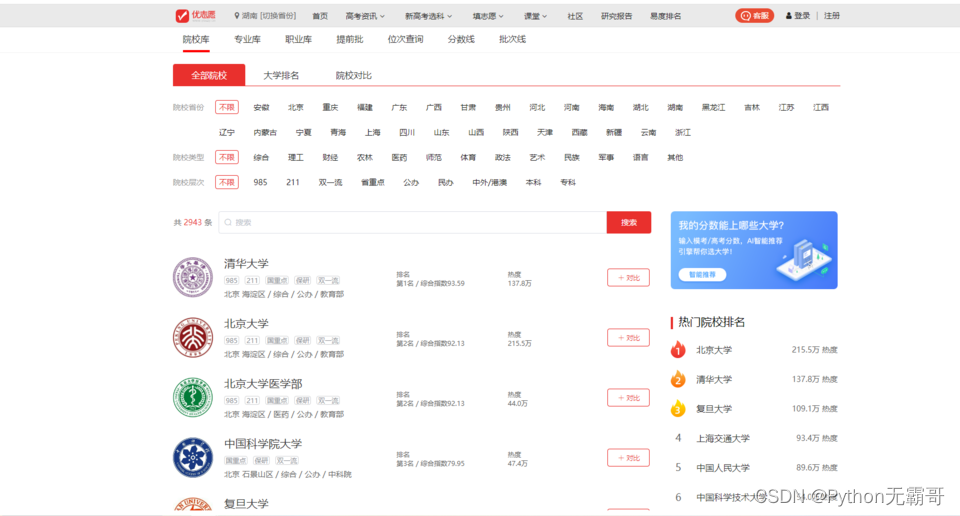
针对大学名称 大学排名, 综合指数,学校情况等数据进行爬取
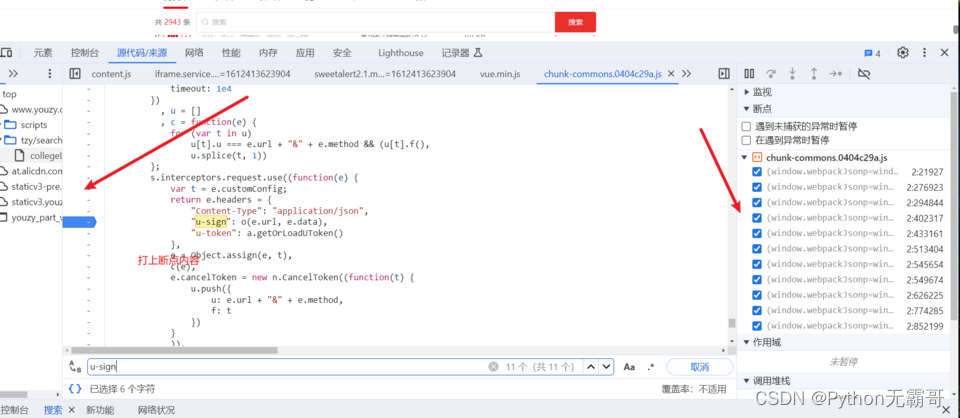
首先进行鼠标右键,进行数据抓包
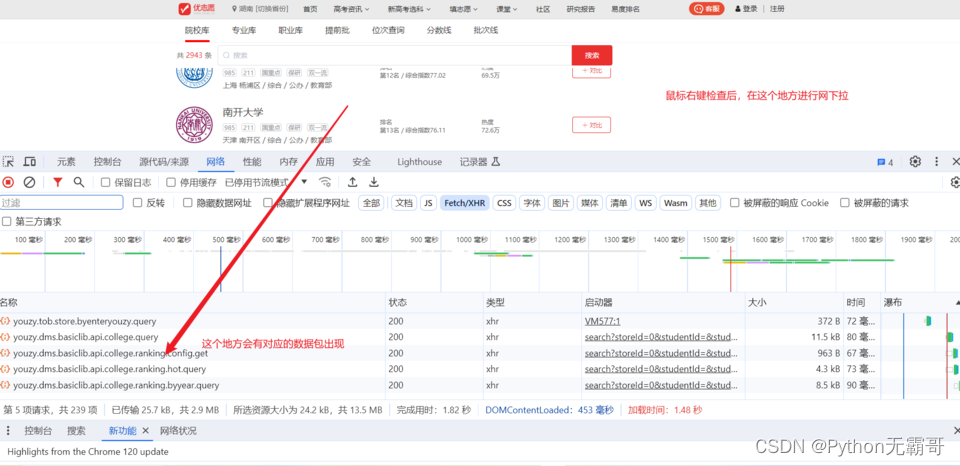
找对应得数据包
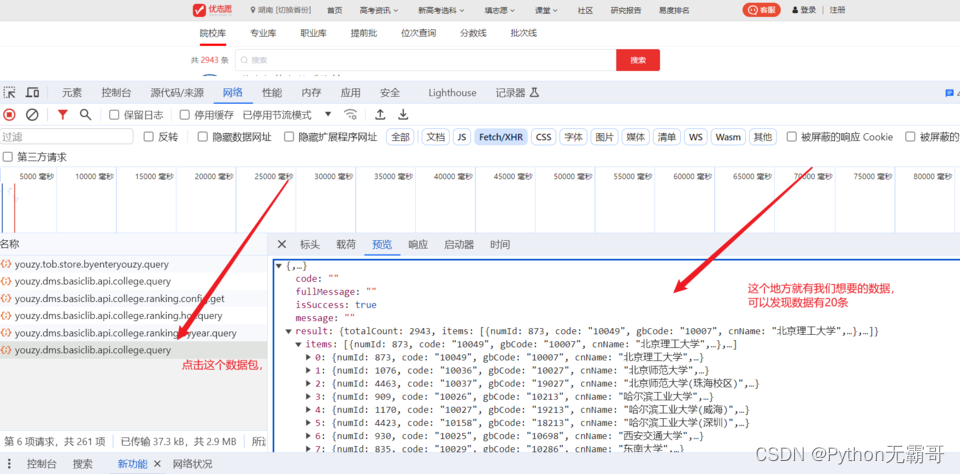
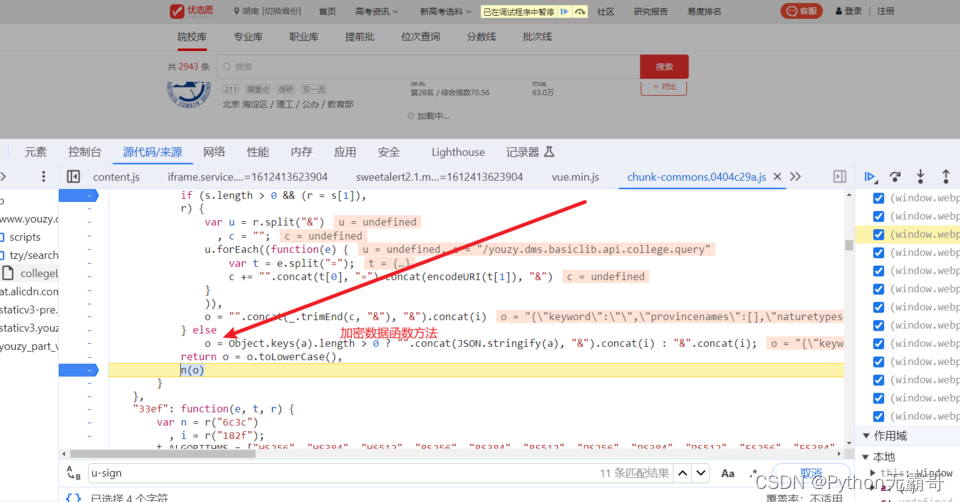
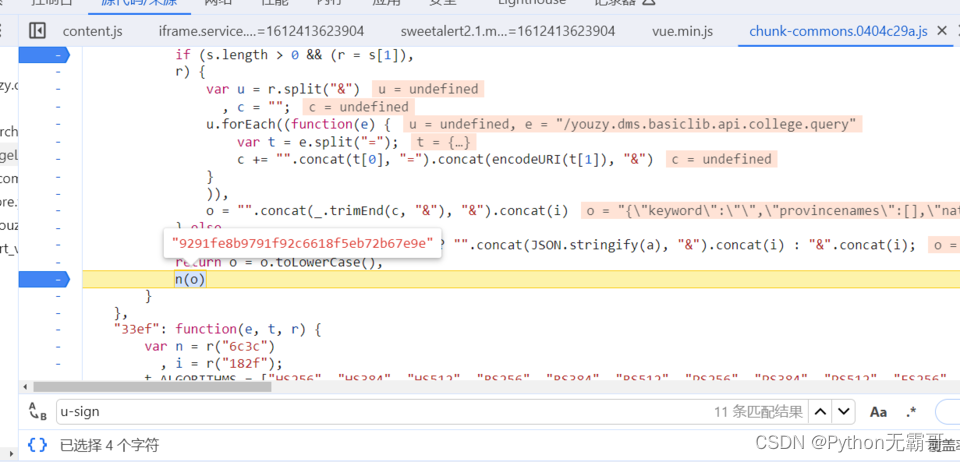
请求发现数据有加密
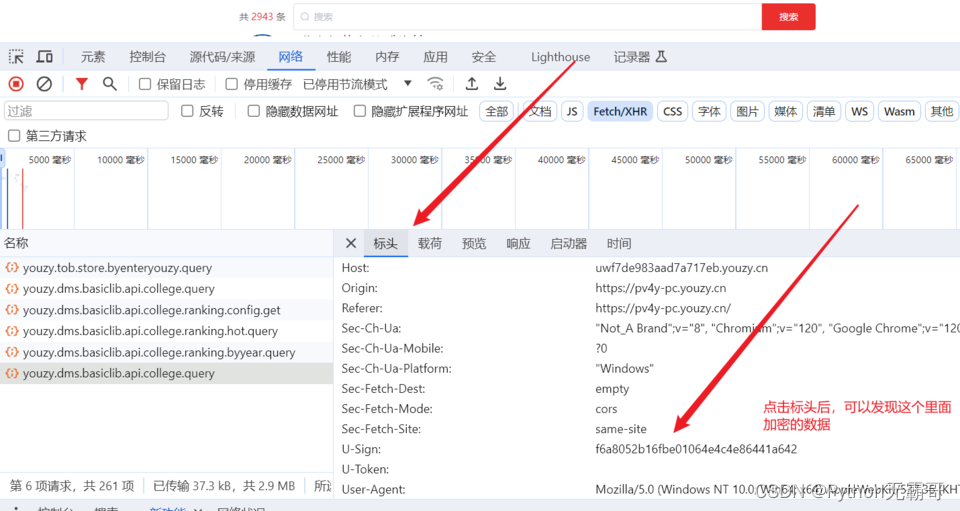
发现加密参数
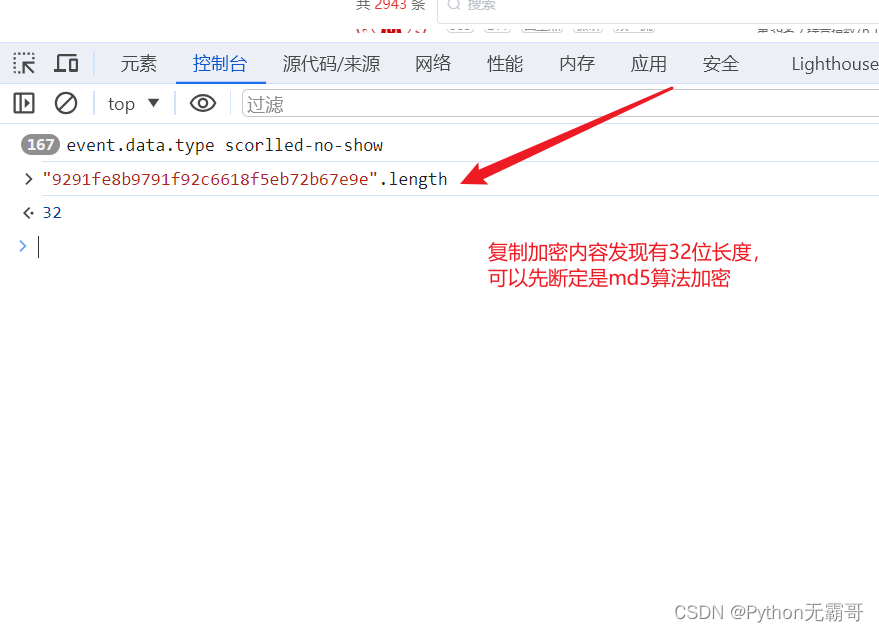
搜索加密参数,好进行分析
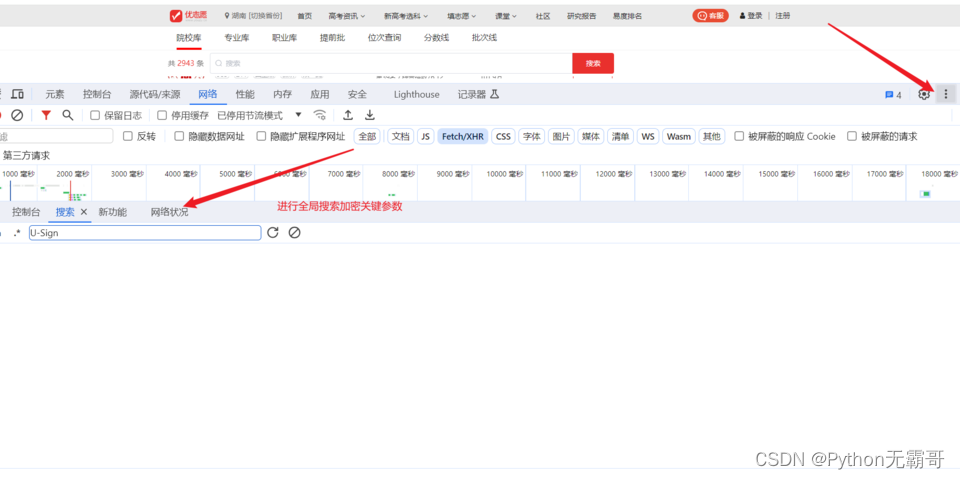
分析过程
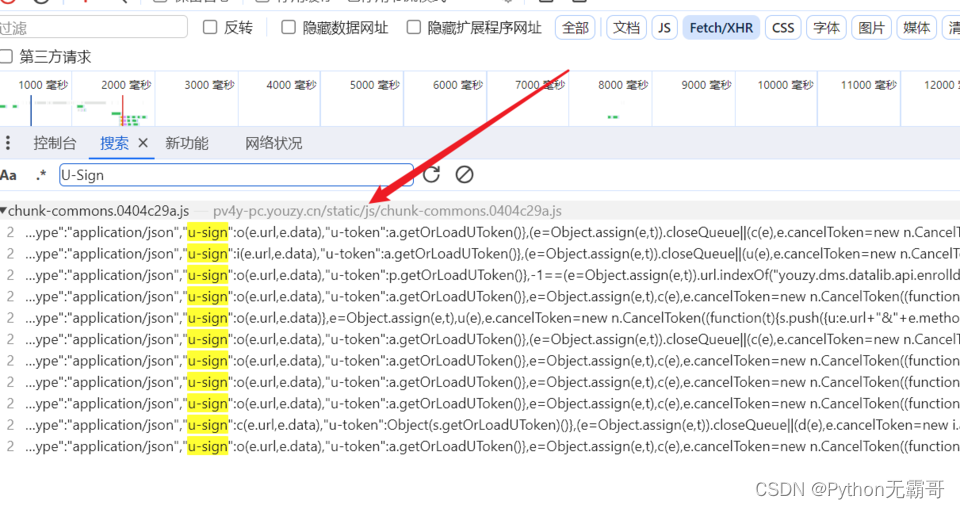
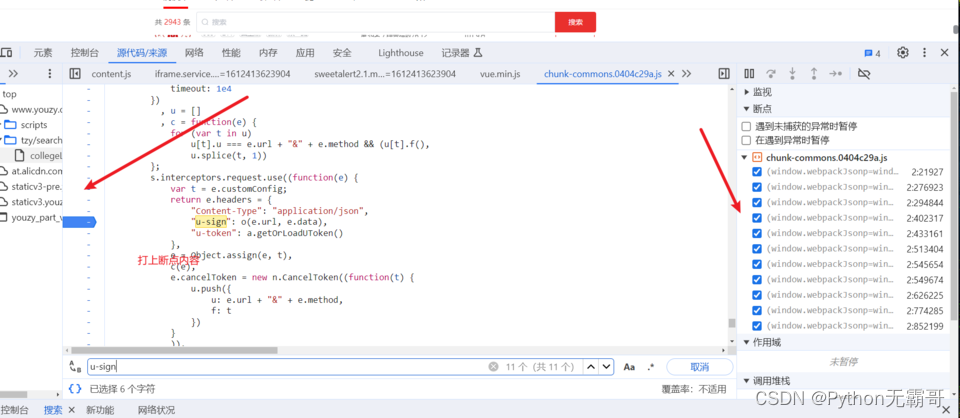
In [2]:
!pip install jsonpath
Collecting jsonpath
Downloading jsonpath-0.82.2.tar.gz (10 kB)
Preparing metadata (setup.py) ... done
Building wheels for collected packages: jsonpath
Building wheel for jsonpath (setup.py) ... done
Created wheel for jsonpath: filename=jsonpath-0.82.2-py3-none-any.whl size=6724 sha256=3db960d7ff6f0bb132346f0e72e00349a7f6156100fc98c35ffda5cee786b2bf
Stored in directory: /home/mw/.cache/pip/wheels/2c/2a/fa/87e26ec807b9a21dd0464eb1319cc3ad51b0c9e505fe6b7396
Successfully built jsonpath
Installing collected packages: jsonpath
Successfully installed jsonpath-0.82.2
import requests
import json
import hashlib
import jsonpath
import pandas as pd
for i in range(1, 2):
data = '{"keyword":"","provincenames":[],"naturetypes":[],"edulevel":"","categories":[],"features":[],"pageindex":%s,"pagesize":20,"sort":11}&9sasji5owng41irkisvtjhlxhmrysrp1' % i
md5 = hashlib.md5(data.encode())
# md5.update(content.encode('utf-8'))
sign = md5.hexdigest()
print(sign)
headers = {
"Accept": "*/*",
"Accept-Language": "zh-CN,zh;q=0.9,en;q=0.8",
"Connection": "keep-alive",
"Content-Type": "application/json",
"Origin": "https://pv4y-pc.youzy.cn",
"Referer": "https://pv4y-pc.youzy.cn/",
"Sec-Fetch-Dest": "empty",
"Sec-Fetch-Mode": "cors",
"Sec-Fetch-Site": "same-site",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36",
"sec-ch-ua": "\"Not_A Brand\";v=\"8\", \"Chromium\";v=\"120\", \"Google Chrome\";v=\"120\"",
"sec-ch-ua-mobile": "?0",
"sec-ch-ua-platform": "\"Windows\"",
"u-sign": sign,
"u-token": ""
}
url = "https://uwf7de983aad7a717eb.youzy.cn/youzy.dms.basiclib.api.college.query"
data = {"keyword":"","provinceNames":[],"natureTypes":[],"eduLevel":"","categories":[],"features":[],"pageIndex":i,"pageSize":20,"sort":11}
data = json.dumps(data, separators=(',', ':'))
response = requests.post(url, headers=headers, data=data).json()
# print(resps)
# 学校名称
data_name = jsonpath.jsonpath(response, '$..cnName')
print(data_name)
# 学校类型
data_shape = jsonpath.jsonpath(response, '$..categories')
# 综合指数
data_comScore = jsonpath.jsonpath(response, '$..comScore')
# 是不是本科
data_eduLevel = jsonpath.jsonpath(response, '$..eduLevel')
# 学校情况
data_features = jsonpath.jsonpath(response, '$..features')
# 排名
data_ranking = jsonpath.jsonpath(response, '$..ranking')
# 热度
data_hits = jsonpath.jsonpath(response, '$..hits')
# 部门
data_belong = jsonpath.jsonpath(response, '$..belong')
data = {'学校名称': data_name, '学校类型': data_shape, '综合指数': data_comScore, '学历': data_eduLevel,
'学校情况': data_features, '排名': data_ranking, '热度': data_hits,
'部门': data_belong}
df = pd.DataFrame(pd.DataFrame.from_dict(data, orient='index').values.T, columns=list(data.keys()))
print(df)
# df.to_csv("中国院校统计.csv",index=False)
643ff9499febb3ee34c95ffe0bb29cb0
['清华大学', '北京大学', '北京大学医学部', '中国科学院大学', '复旦大学', '复旦大学上海医学院', '上海交通大学', '上海交通大学医学院', '中国科学技术大学', '中国人民大学', '中国人民大学(苏州校区)', '浙江大学', '浙江大学医学院', '南京大学', '北京航空航天大学', '北京航空航天大学中法航空学院', '武汉大学', '同济大学', '南开大学', '中国人民解放军国防科技大学']
学校名称 学校类型 综合指数 学历 学校情况 排名 热度 \
0 清华大学 [综合] 93.59 ben [985, 211, 国重点, 保研, 双一流] 1 1378946
1 北京大学 [综合] 92.13 ben [985, 211, 国重点, 保研, 双一流] 2 2155577
2 北京大学医学部 [医药] 92.13 ben [985, 211, 国重点, 保研, 双一流] 2 439830
3 中国科学院大学 [综合] 79.95 ben [国重点, 保研, 双一流] 3 474549
4 复旦大学 [综合] 83.73 ben [985, 211, 国重点, 保研, 双一流] 4 1091717
5 复旦大学上海医学院 [医药] 83.73 ben [985, 211, 国重点, 保研, 双一流] 4 321950
6 上海交通大学 [综合] 84.72 ben [985, 211, 国重点, 保研, 双一流] 5 934308
7 上海交通大学医学院 [医药] 84.72 ben [985, 211, 国重点, 保研, 双一流] 5 306197
8 中国科学技术大学 [综合] 79.59 ben [985, 211, 国重点, 保研, 双一流] 6 540224
9 中国人民大学 [综合] 79.92 ben [985, 211, 保研, 国重点, 双一流] 7 895950
10 中国人民大学(苏州校区) [综合] 79.92 ben [985, 211, 保研, 双一流] 7 448989
11 浙江大学 [综合] 86.16 ben [985, 211, 国重点, 保研, 双一流] 8 1102871
12 浙江大学医学院 [医药] 86.16 ben [985, 211, 国重点, 双一流] 8 298237
13 南京大学 [综合] 80.51 ben [985, 211, 国重点, 保研, 双一流] 9 1068208
14 北京航空航天大学 [理工] 77.19 ben [985, 211, 保研, 双一流] 10 668746
15 北京航空航天大学中法航空学院 [] 77.19 ben [] 10 11630
16 武汉大学 [综合] 79.82 ben [985, 211, 国重点, 保研, 双一流] 11 1167221
17 同济大学 [综合] 77.02 ben [985, 211, 国重点, 保研, 双一流] 12 694969
18 南开大学 [综合] 76.11 ben [985, 211, 国重点, 保研, 双一流] 13 725994
19 中国人民解放军国防科技大学 [军事] 73.59 ben [985, 211, 国重点, 双一流] 14 717849
部门
0 教育部
1 教育部
2 教育部
3 中科院
4 教育部
5 教育部
6  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









