







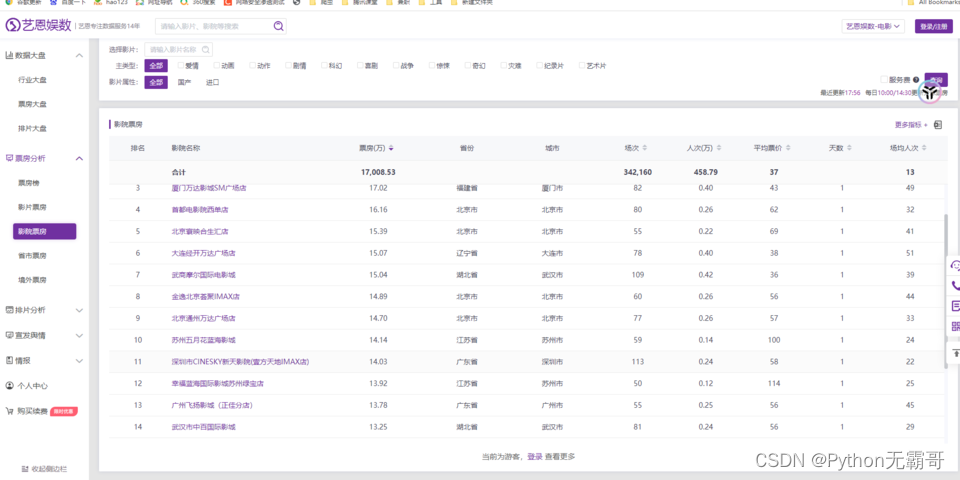
这个里面的影院名称,省份,城市,票房,场次,人次,平均票价,天数,场均人次这些数据都是我们需要的。
一、记得登入才能看到所有的数据
示例:pandas 是基于NumPy 的一种工具,该工具是为了解决数据分析任务而创建的。
二、使用步骤
进行数据抓包
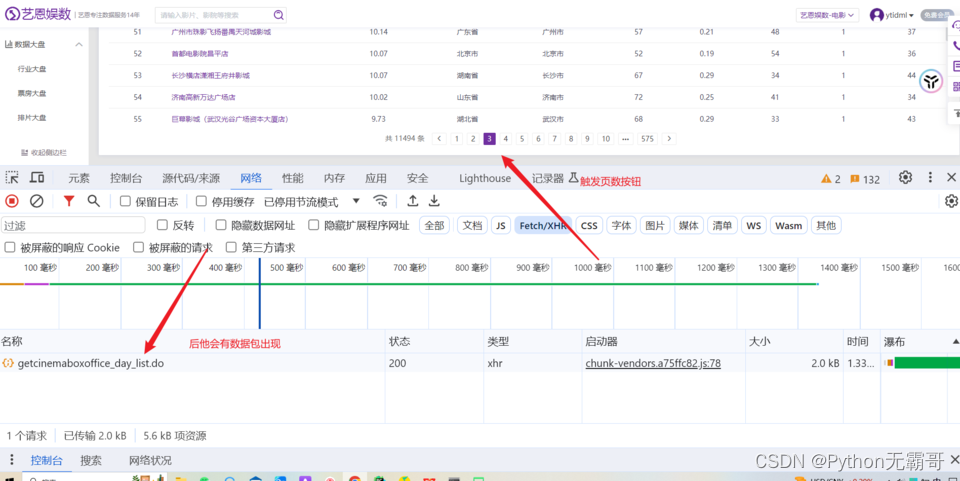
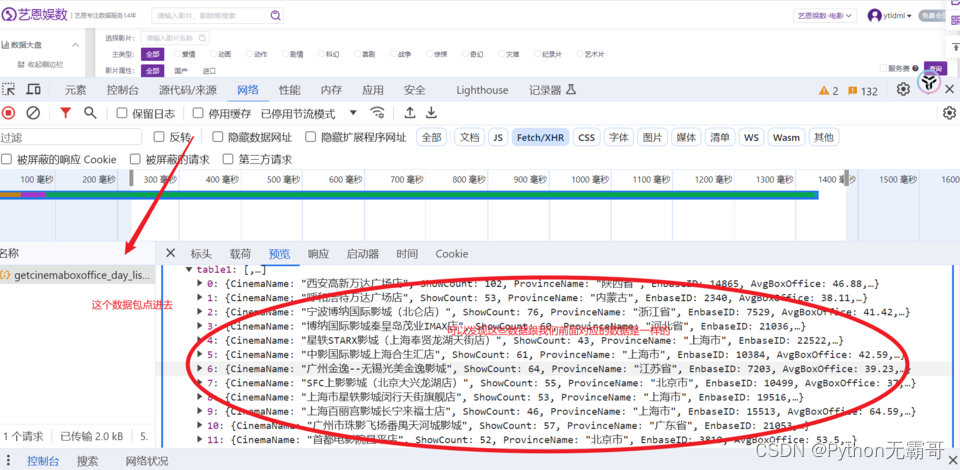
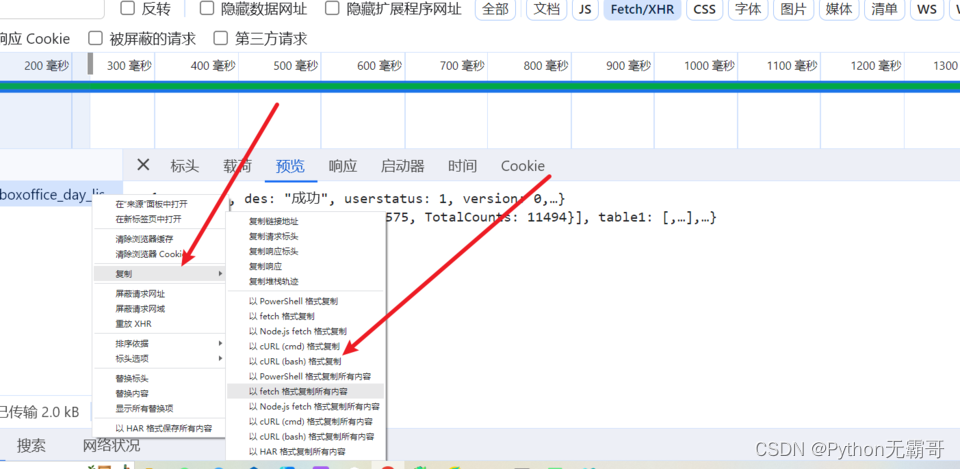
点击数据包,找我们需要的数据
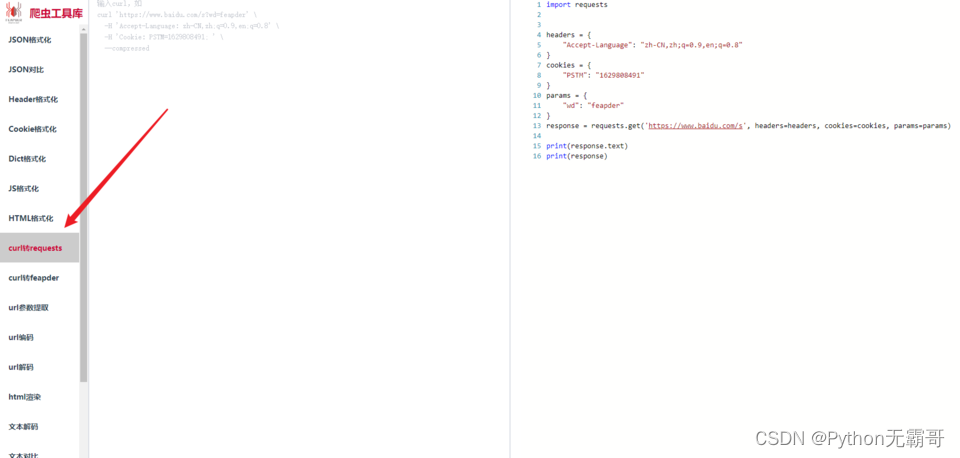
借用一个工具
https://spidertools.cn/#/unQuoteUrl
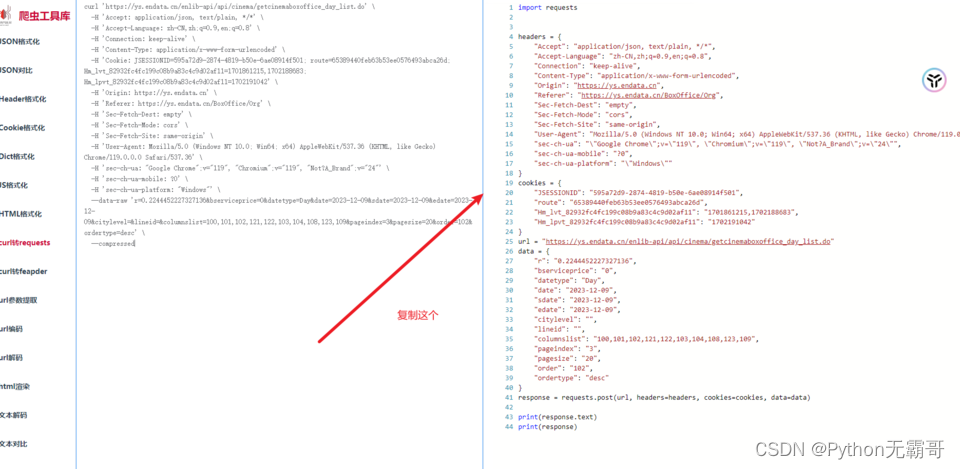
import requests
headers = {
"Accept": "application/json, text/plain, */*",
"Accept-Language": "zh-CN,zh;q=0.9,en;q=0.8",
"Connection": "keep-alive",
"Content-Type": "application/x-www-form-urlencoded",
"Origin": "https://ys.endata.cn",
"Referer": "https://ys.endata.cn/BoxOffice/Org",
"Sec-Fetch-Dest": "empty",
"Sec-Fetch-Mode": "cors",
"Sec-Fetch-Site": "same-origin",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36",
"sec-ch-ua": "\"Google Chrome\";v=\"119\", \"Chromium\";v=\"119\", \"Not?A_Brand\";v=\"24\"",
"sec-ch-ua-mobile": "?0",
"sec-ch-ua-platform": "\"Windows\""
}
cookies = {
"JSESSIONID": "595a72d9-2874-4819-b50e-6ae08914f501",
"route": "65389440feb63b53ee0576493abca26d",
"Hm_lvt_82932fc4fc199c08b9a83c4c9d02af11": "1701861215,1702188683",
"Hm_lpvt_82932fc4fc199c08b9a83c4c9d02af11": "1702191042"
}
url = "https://ys.endata.cn/enlib-api/api/cinema/getcinemaboxoffice_day_list.do"
data = {
"r": "0.2244452227327136",
"bserviceprice": "0",
"datetype": "Day",
"date": "2023-12-09",
"sdate": "2023-12-09",
"edate": "2023-12-09",
"citylevel": "",
"lineid": "",
"columnslist": "100,101,102,121,122,103,104,108,123,109",
"pageindex": "3",
"pagesize": "20",
"order": "102",
"ordertype": "desc"
}
response = requests.post(url, headers=headers, cookies=cookies, data=data)
print(response.text)
print(response)
{
"status":1,"des":"成功","userstatus":1,"version":0,"data":{
"table2":[{
"TotalPage":575,"TotalCounts":11494}],"table1":[{
"CinemaName":"西安高新万达广场店","ShowCount":102,"ProvinceName":"陕西省","EnbaseID":14865,"AvgBoxOffice":46.88,"CinemaID":12109,"BoxOffice":105954.52,"AudienceCount":2260,"AvgShowAudienceCount":22,"CityName":"西安市","Irank":41,"ShowDay":1},{
"CinemaName":"呼和浩特万达广场店","ShowCount":53,"ProvinceName":"内蒙古","EnbaseID":2340,"AvgBoxOffice":38.11,"CinemaID":1022,"BoxOffice":105916.87,"AudienceCount":2779,"AvgShowAudienceCount":52,"CityName":"呼和浩特市","Irank":42,"ShowDay":1},{
"CinemaName":"宁波博纳国际影城(北仑店)","ShowCount":76,"ProvinceName":"浙江省","EnbaseID":7529,"AvgBoxOffice":41.42,"CinemaID":6026,"BoxOffice":104799.56,"AudienceCount":2530,"AvgShowAudienceCount":33,"CityName":"宁波市","Irank":43,"ShowDay":1},{
"CinemaName":"博纳国际影城秦皇岛茂业IMAX店","ShowCount":60,"ProvinceName":"河北省","EnbaseID":21036,"AvgBoxOffice":41.18,"CinemaID":16711,"BoxOffice":104507.85,"AudienceCount":2538,"AvgShowAudienceCount":42,"CityName":"秦皇岛市","Irank":44,"ShowDay":1},{
"CinemaName":"星轶STARX影城(上海奉贤龙湖天街店)","ShowCount":43,"ProvinceName":"上海市","EnbaseID":22522,"AvgBoxOffice":44.63,"CinemaID":18208,"BoxOffice":103412.53,"AudienceCount" 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









