







声明:本次利用cookies,跳过登录功能进行数据获取,功能点很简单;用于个人笔记而已。
一、开发思路
1 通过cookies进行模拟登录
2 通过对界面的请求分析确定所抓取数据的对应位置
3 抓取出来的数据可能是json字符串,所有需要使用json.loads()方法对json字符串转对象
4 解析json,写入数组即完成
(可能没有很多异常处理,后期自己实际开发的时候,进行异常的处理,确保代码成功率)
二、涉及模块
import json #用于将json字符串转换为json对象
import requests # 用于对网页进行发起请求
三、各个功能
1 cookies处理
# 重新组装cookies
def deal_cookies(cookies_str):
cookiesA = {}
for line in cookie_str.split(';'):
key, value = line.split('=', 1)
cookiesA[key] = value
return cookiesA
2 数据获取
# post 请求数据的获取 cookies需必传
def deal_post(url,cookies,headers=None):
req = requests.post(url, headers=headers,cookies = cookies)
json_Data = req.content.decode('utf-8')
return json_Data
3 数据整合
def deal_json_data(data): # 数据的整合
deal_data_all = []
json_type = type(data)
# print(json_type)
data = json.loads(data)
for i in data['data']:
arr = []
print(i)
arr.append(i['ContentID'])
arr.append(i['Cover'])
arr.append(i['ContentName'])
arr.append(i['PersonNum'])
deal_data_all.append(arr)
return deal_data_all
4 调用
if __name__ == '__main__':
# 未处理的cookies
cookie_str = 'XXXXXXXXXXXX' #自行在网页中进行获取
# 准备UA和SID
headers = {
'User-Agent': 'XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX', #自行在网页中进行获取
'SessionId': 'XXXXXXXXXXXXXXXXXXXXXXXXXXX' #自行在网页中进行获取
}
# 被访问url地址
url = 'http://cqcvc.iflysse.com/net-api/excitation/sign/getWeekSign'
adrees_url = 'http://cqcvc.iflysse.com/net-api/bosiplatform/StudentHome/GetRecommendCourse'
# 调用函数对cookies进行处理
cookieStr = deal_cookies(cookie_str)
print(cookieStr)
print('================================================================================================================================================================================')
data = deal_post(adrees_url,headers=headers,cookies=cookieStr)
print(data)
print('================================================================================================================================================================================')
deal_data_all = deal_json_data(data)
print(deal_data_all)
print('================================================================================================================================================================================')
for i in deal_data_all:
print(i)
print('===============================================================================================================================')
四、最后获取到的数据
红色为所有数据,黄色为遍历后的数据,地址为网页中图片的地址
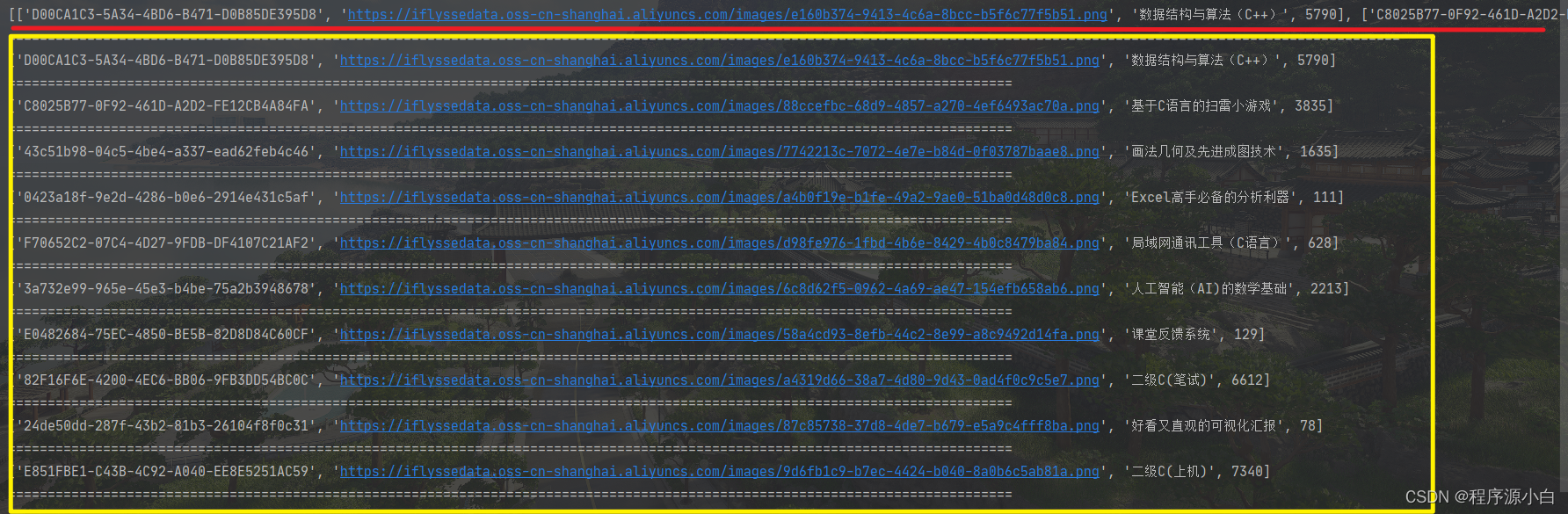
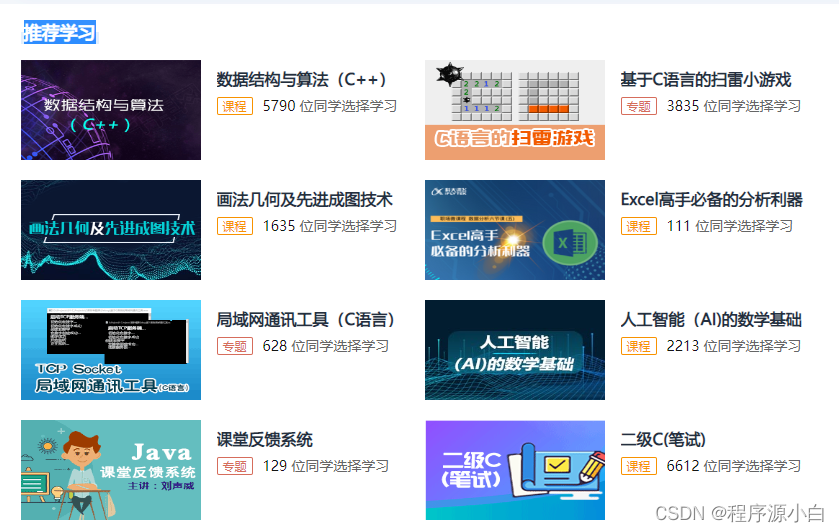
五、网页上的样子















 1576
1576











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









