







数据定义
数据定义
1.SQL的数据定义功能:模式定义、表定义、视图和索引的定义。
2.现代关系数据库管理系统提供了一个层次化的数据库对象命名机制。
①一个关系数据库管理系统的实例(Instance)中可以建立多个数据库。
②一个数据库中可以建立多个模式。
③一个模式下通常包括多个表、视图和索引等数据库对象。
一.模式的定义与删除
1.定义模式
CREATE SCHEMA <模式名> AUTHORIZATION <用户名> [<表定义子句> | <视图定义子句> | <授权定义子句>]
(1)定义模式实际上定义了一个命名空间。
(2)在这个空间中可以定义该模式包含的数据库对象,例如基本表、视图、索引等。
(3)在CREATE SCHEMA中可以接受CREATE TABLE,CREATE VIEW和GRANT子句。
(4)例子:为用户ZHANG创建一个模式TEST,并且在其中定义一个表TAB1。
CREATE SCHEMA TEST AUTHORIZATION ZHANG
CREATE TABLE TAB1(COL1 SMALLINT,
COL2 INT,
COL2 CHAR(20)
);
2.删除模式
DROP SCHEMA <模式名> <CASCADE | RESTRICT>
(1)CASCADE(级联)
删除模式的同时把该模式中所有的数据库对象全部删除。
(2)RESTRICT(限制)
①如果该模式中定义了下属的数据库对象(如表、视图等),则拒绝该删除语句的执行。
②仅当该模式中没有任何下属的对象时才能执行。
(3)例子:删除模式ZHANG
DROP SCHEMA ZHANG CASCADE; //删除模式ZHANG,同时该模式中定义的表TAB1也被删除。
二.基本表的定义、删除与修改
1.定义基本表
CREATE TABLE <表名>
(
<列名> <数据类型> [列级完整性约束条件],
…
[,<表级完整性约束条件>]
);
(1)表名:所要定义的基本表的名字。
(2)列名:组成该表的各个属性(列)。
(3)列级完整性约束条件:涉及相应属性列的完整性约束条件。(主键、外键等条件)
(4)表级完整性约束条件:涉及一个或多个属性列的完整性约束条件。
(5)如果完整性约束条件涉及到该表的多个属性列,则必须定义在表级上,否则既可以定义在列级也可以定义在表级。
(6)例子:建立一个课程表Course
CREATE TABLE Course
(
Cno CHAR(4) PRIMARY KEY, //主键
Cname CHAR(40),
Cpno CHAR(4),
FOREIGN KEY (Cpno) REFERENCES Course(Cno) //设置外键为先修课程Cpno
);
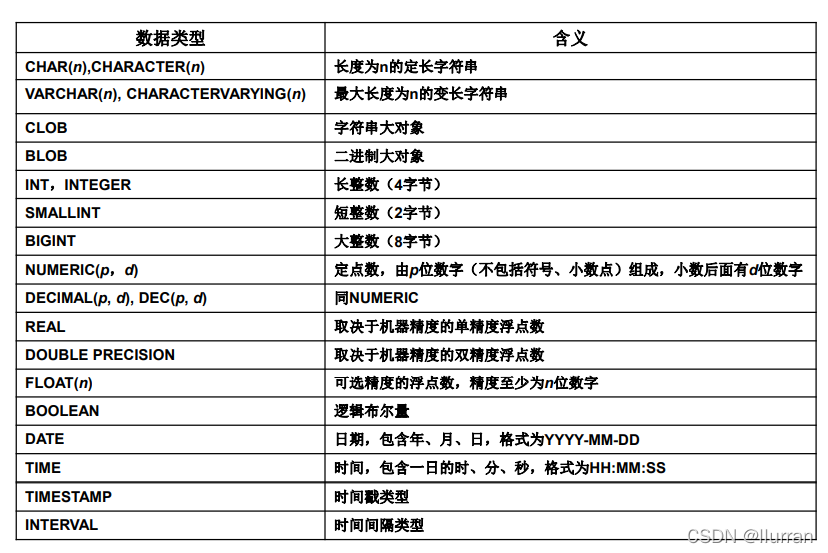
2.数据类型
3.模式与表
(1)每一个基本表都属于某一个模式。
(2)一个模式包含多个基本表。
(3)定义基本表所属模式
①方法1:在表名中明显地给出模式名。
CREATE TABLE “S-T” .Student(…);
CREATE TABLE “S-T”.Course(…);
②方法2:在创建模式语句中同时创建表。
如上述创建模式的例子所示。
③方法3:设置所属的模式。
(4)创建基本表时,若没有指定模式,系统根据搜索路径来确定该对象所属的模式。
(5)关系数据库管理系统会使用模式列表中第一个存在的模式作为数据库对象的模式名。
(6)若搜索路径中的模式名都不存在,系统将给出错误。
①显示当前的搜索路径:
SHOW search_path;
②搜索路径的当前默认值是:
$user,PUBLIC
(7)数据库管理员用户可以设置搜索路径,然后定义基本表
SET search_path TO “S-T”,PUBLIC;
CREATE TABLE Student(…);
2.修改基本表
ALTER TABLE <表名>
[ADD [COLUMN] <新列名> <数据类型> <完整性约束>]
[ADD <表级完整性约束>]
[DROP [COLUMN] <列名> [CASCADE | RESTRICT]]
[DROP CONSTRAINT <完整性约束名> [RESTRICT | CASCADE]]
[ALTER COLUMN <列名> <数据类型>];
(1)表名:要修改的基本表。
(2)ADD子句:用于增加新列、新的列级完整性约束条件和新的表级完整性约束条件。
(3)DROP COLUMN 子句:用于删除表中的列。
①如果指定了CASCADE短语,则自动删除引用了该列的其他对象。
②如果指定了RESTRICT短语,则如果该列被其他对象引用,关系数据库管理系统将拒绝删除该列。
(4)DROP CONSTRAINT子句:用于删除指定的完整性约束条件。
(5)ALTER COLUMN子句:用于修改原有的列定义,包括修改列名和数据类型。
5.删除基本表
DROP TABLE <表名> [RESTRICT | CASCADE];
(1)RESTRICT:删除表是有限制的。
①要删除的表不能被其他表的约束所引用。
②若存在依赖该表的对象,则此表不能被删除。
(2)CASCADE:删除该表没有限制。
在删除基本表的同时,相关的依赖对象一起删除。
三.索引的建立与删除
(1)建立索引的目的:加快查询速度(当数据量特别大的时候)。
(2)关系数据库管理系统中常见索引:
①顺序文件上的索引;
②B+树索引;
③散列(hash)索引;
④位图索引。
(3)特点
①B+树索引具有动态平衡的优点;
②HASH索引具有查找速度快的特点。
(4)索引
①谁可以创建索引
数据库管理员或表的属主(即建立表的人)
②谁维护索引
关系数据库管理系统自动完成
③使用索引
关系数据库管理系统自动选择合适的索引作为存取路径,用户不必也不能显示地选择索引。
1.建立索引
CREATE [UNIQUE] [CLUSTER] INDEX <索引名> ON <表名> (<列名> [<次序>] [,<列名>[<次序>]]…);
(1)<表名>:要建索引的基本表的名字;
(2)索引:可以建立在该表的一列或多列上,各列名之间用逗号分隔;
(3)<次序>:指定索引值的排列次序,升序:ASC,降序:DESC,默认升序;
(4)UNIQUE:此索引的每一个索引值只对应唯一的数据记录;
(5)CLUSTER:表示要建立的索引是聚簇索引。
聚簇:一组表有一些共同的列,或相关的数据存储在同一个数据块上,在聚簇索引下,数据在物理上按顺序排在数据页上,重复值也排在一起;一旦找到第一个键值,具有后续索引值毗连在一起而不必进一步搜索,避免了大范围扫描。
(6)例子:
为学生-课程数据库中的Student,Course,SC三个表建立索引。Student表按学号升序建立唯一索引,Course表按课程号升序建立唯一索引,SC表按学号升序和课程号降序建立唯一索引。
CREATE UNIQUE INDEX Stusno ON Student (Sno);
CREATE UNIQUE INDEX Coucno ON Course(Cno);
CREATE UNIQUE INDEX SCno ON SC(Sno ASC,Cno DESC);
2.查看索引
SHOW INDEX FROM 表名;
3.修改索引
ALTER INDEX <旧索引名> RENAME TO <新索引名>
4.删除索引
DROP INDEX <索引名>;
删除索引时,系统会从数据字典中删去有关该索引的描述。
四.数据字典
(1)数据字典是关系数据库管理系统内部的一组系统表,它记录了数据库中所有定义信息:
①关系模式定义;
②视图定义;
③索引定义;
④完整性约束定义;
⑤各类用户对数据库的操作权限;
⑥统计信息等。
(2)关系数据库管理系统在执行SQL的数据定义语句时,实际上就是在更新数据字典表中的相应信息。















 1121
1121











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











