







目录
案例一
统计出出这些数据中不同类型的紧急情况的次数
现在我们有2015到2017年25万条911的紧急电话的数据,请统计出出这些数据中不同类型的紧急情况的次数, 数据来源:https://www.kaggle.com/mchirico/montcoalert/data
用np.zeros()来实现
import pandas as pd
import numpy as np
from matplotlib import pyplot as plt
#获取数据
df = pd.read_csv("./911.csv")
#获取分类
temp_list = df["title"].str.split(": ").tolist()
cate_list = list(set(i[0] for i in temp_list))
#print(cate_list) ['Fire', 'Traffic', 'EMS']
#构造全为0的数组
zeros_df = pd.DataFrame(np.zeros((df.shape[0],len(cate_list))),columns=cate_list)
#赋值方法一
for cate in cate_list:
zeros_df[cate][df["title"].str.contains(cate)] = 1
#print(zeros_df)
#df["title"].str.contains(cate)
# 0 False
# 1 False
# 2 True
# 3 False
# 4 False
#赋值方法二(时间复杂度太高,很慢,得到的结果与第一种方法一样)
# for i in range(df.shape[0]):
# zeros_df.loc[i,temp_list[i][0]]=1
# print(zeros_df)
#t统计
sum_ret = zeros_df.sum(axis=0)
print(sum_ret)
用gruopby来实现
import pandas as pd
import numpy as np
from matplotlib import pyplot as plt
#获取数据
df = pd.read_csv("./911.csv")
#获取分类
temp_list = df["title"].str.split(": ").tolist()
cate_list = list(i[0] for i in temp_list)
#print(cate_list)['EMS', 'EMS', 'Fire', 'EMS', .....]即一维列表
#将这个一维列表转换为DataFrame形式
# cate_df = pd.DataFrame(np.array(cate_list).reshape((df.shape[0],1)),columns=["cate"])
# print(cate_df)
# cate
# 0 EMS
# 1 EMS
# 2 Fire
# 3 EMS
# 4 EMS
#在原来df基础上添加一列“cate”
df["cate"] = pd.DataFrame(np.array(cate_list).reshape((df.shape[0],1)))
grouped = df.groupby(by="cate").count()["title"]
print(grouped)
pandas时间序列
生成一段时间范围
pd.date_range(start=None, end=None, periods=None, freq='D')
start和end以及freq配合能够生成start和end范围内以频率freq的一组时间索引
start和periods以及freq配合能够生成从start开始的频率为freq的periods个时间索引


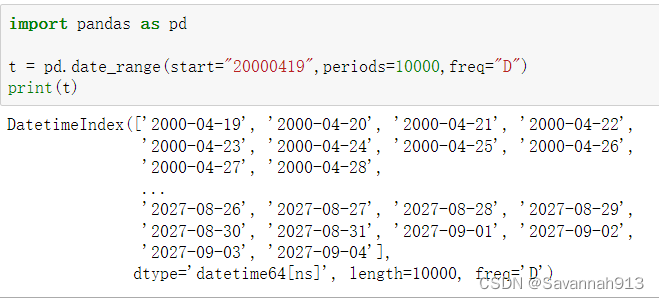

index=pd.date_range("20170101",periods=10)
df = pd.DataFrame(np.random.rand(10),index=index)
回到最开始的911数据的案例中,我们可以使用pandas提供的方法把时间字符串转化为时间序列
df["timeStamp"] = pd.to_datetime(df["timeStamp"],format="")
format参数大部分情况下可以不用写,但是对于pandas无法格式化的时间字符串,我们可以使用该参数,比如包含中文 那么问题来了: 我们现在要统计每个月或者每个季度的次数怎么办呢?

一般情况下以“-”,“/”等分割,能够直接识别,

显然,有时分秒也能够识别。
重采样
重采样:指的是将时间序列从一个频率转化为另一个频率进行处理的过程,将高频率数据转化为低频率数据为降采样,低频率转化为高频率为升采样。(比如:时分秒转化)
pandas提供了一个resample的方法来帮助我们实现频率转化。

统计出不同月份不同类型紧急电话的次数的变化情况
如果我们还想统计出不同月份不同类型紧急电话的次数的变化情况,应该怎么做呢?
统计出911数据中不同月份电话次数的变化情况
import pandas as pd
import numpy as np
from matplotlib import pyplot as plt
#获取数据
df = pd.read_csv("./911.csv")
df["timeStamp"] = pd.to_datetime(df["timeStamp"])
df = df.set_index("timeStamp")#原地操作
#统计出911数据中不同月份电话次数的变化情况
count_bymonth = df.resample("M").count()["title"]
#绘制条形图
plt.figure(figsize=(20,8),dpi=80)
_x = range(len(count_bymonth.index))
plt.plot(_x,count_bymonth.values)
plt.xticks(_x[::2],count_bymonth.index[::2],rotation=45)
plt.show()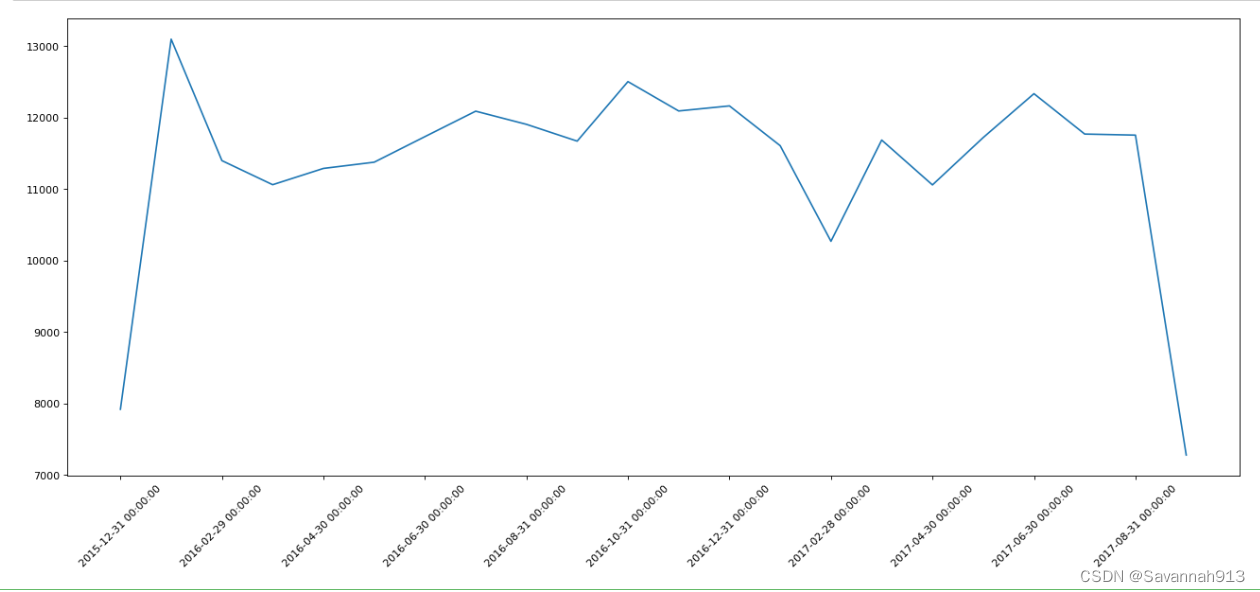
开始和最后一个月份次数很低的原因是,这两个月的信息不完整。
统计出911数据中不同月份不同类型的电话的次数的变化情况
注意事项:
①先添加列再改变索引
②groupby之后的可迭代对象!
groupby之后返回的是一个元组,元组中有两个数据,第一个数据是groupby中by对应的属性包含的各种值(即对哪个属性进行分组的),第二个数据是在第一个属性值之下的数据(DataFrame形式)。
#统计出911数据中不同月份不同类型的电话的次数的变化情况
import pandas as pd
import numpy as np
from matplotlib import pyplot as plt
#获取数据
df = pd.read_csv("./911.csv")
#需要先添加列再改变索引,因为根据时间索引来添加列的话会出现列的行数不匹配的情况,添加新的列就会不成功。
#添加列,表示索引
temp_list = df["title"].str.split(": ").tolist()
cate_list = [i[0] for i in temp_list]
df["cate"] = pd.DataFrame(np.array(cate_list).reshape((df.shape[0],1)))
#把时间字符串转为时间类型设置为索引
df["timeStamp"] = pd.to_datetime(df["timeStamp"])
df = df.set_index("timeStamp")
#按照不同类型进行分组
grouped = df.groupby(by="cate")
plt.figure(figsize=(20,8),dpi=80)
for group_name,group_data in grouped:
#对不同分类根据时间绘制折线图
count_by_month = group_data.resample("M").count()["title"]
_x = count_by_month.index
_y = count_by_month.values
#_x时间转换类型
_x = [i.strftime for i in _x]
plt.plot(range(len(_x)),_y,label=group_name)
plt.legend()
plt.show() 














 1275
1275











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









