







面向预测的时空数据学习方法研究--《北京交通大学》2021年博士论文 (cnki.com.cn)
目录
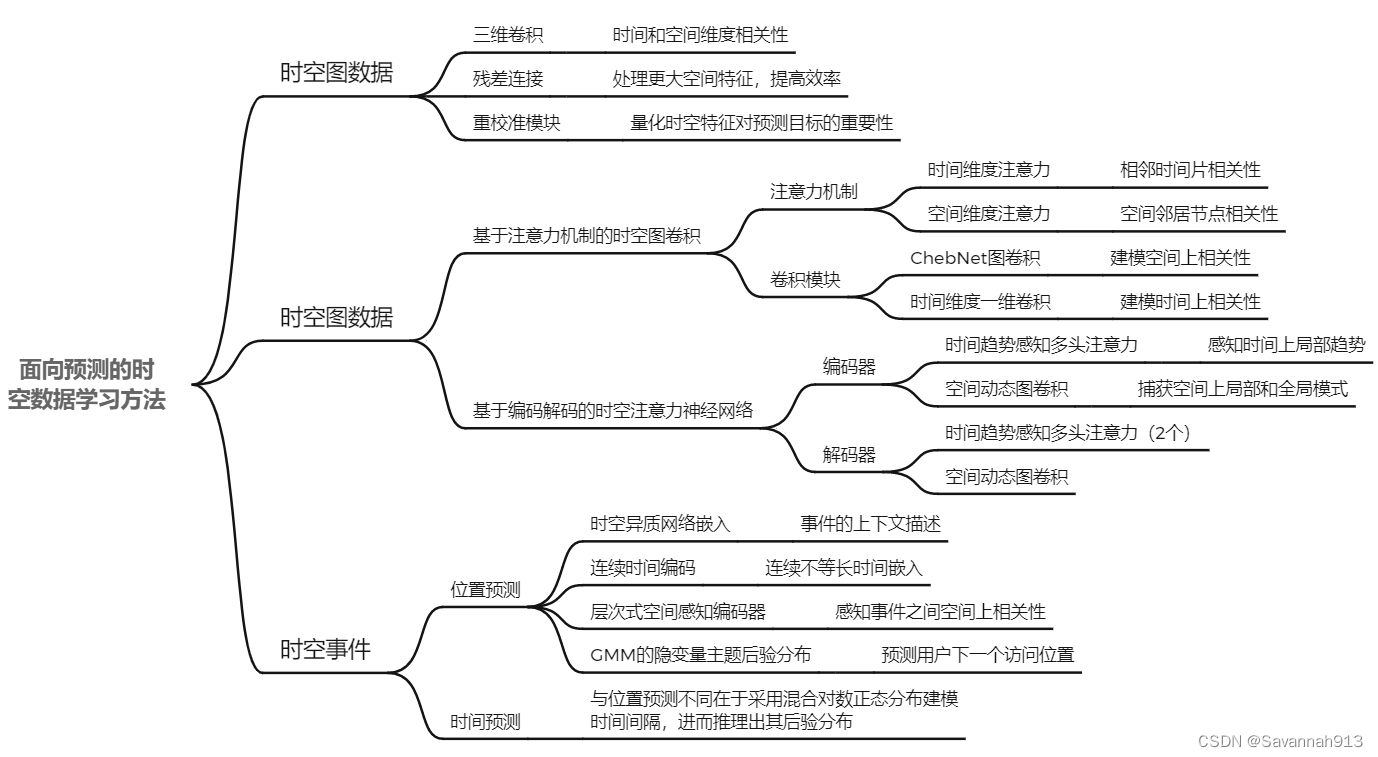
第3章面向时空网格数据预测的三维卷积神经网络模型
目标:基于历史的时空交通网格数据,预测未来一段时间内,全部区域范围内的交通情况。
时空网格数据特点:时间相关性、空间相关性、空间维度异质性、时间维度周期性,且均匀分布区域上以固定时间间隔统计的数据
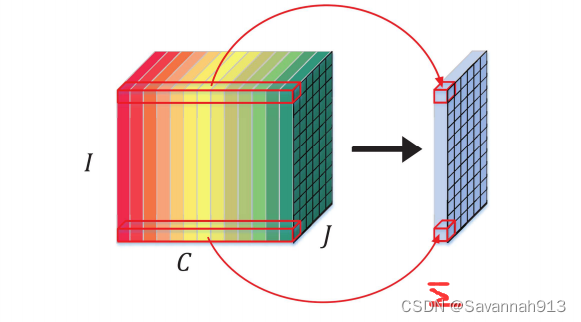
定义数据:根据经、纬度将连续区域划分为IxJ个大小相等的区域,每个小区域用Si,j表示,并以特定时间间隔对每个小区域的某些观测值进行 采样。
其中,表示在第t个时间步,区域(i,j)的第c类观测量的值。张量
表示在第t个时间步,所有IxJ区域的观测值。
定义问题:研究拥堵预测问题时,令C={0},那么表示在第t个时间步区域(i,j)的拥堵情况。
研究人流量预测问题时,C={0,1},那么和
分 别表示在第t个时间步区域(i,j)中的人群的流入流出量。
简述深度时空三维卷积神经网络模型
2个组件
①负责捕获交通网格数据的近期依赖(closeness)
交通数据在时间维度上呈现的局部模式。当前的交通数据与最近的历史数据密切相关。
②负责排获交通网格数据的周周期依赖(weekly Period)
交通数据在长时间范围内存在的周期性和趋势性。
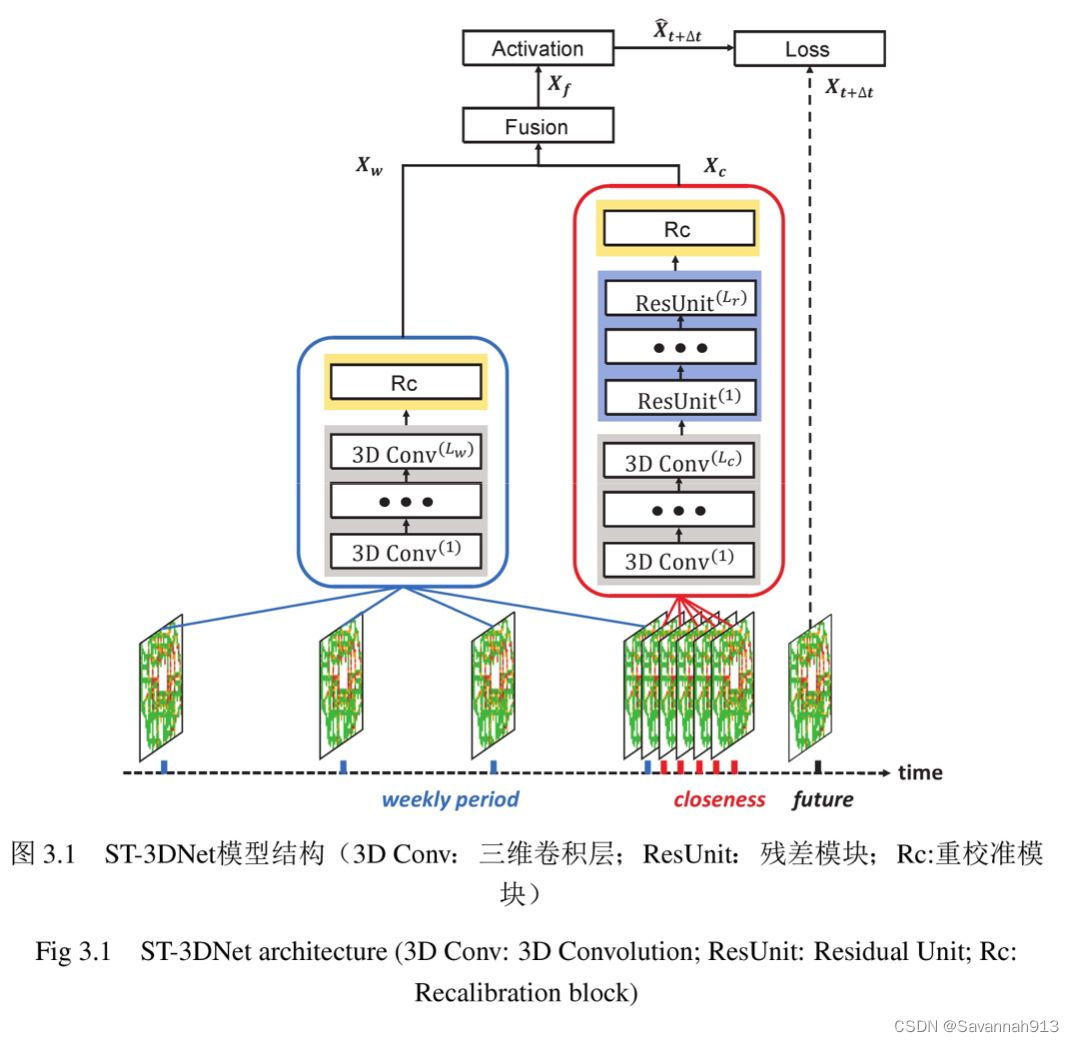
近期依赖组件(过去几天)
输入为近期历史子序列,其中,
为近期依赖序列的长度,每个时间步的数据特征
,C={0},表示区域(i,j)的拥堵情况,C={0,1},表示在第t个时间步区域(i,j)中的人群的流入流出量。
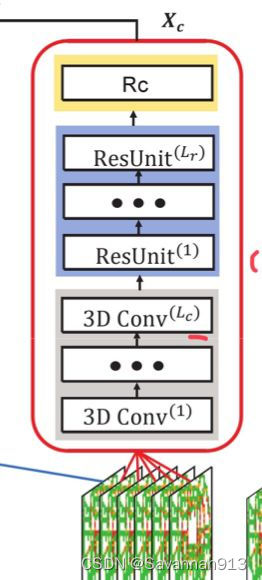
①3D Conv:处理输入数据,捕捉时空相关性。
(三维卷积)
②ResUnit:处理交通数据在更大空间范围的特征
(二维残差单元)
③重较准(RC):显示量化由上述神经网络学习到的时空特征对最终预测目标的重要性
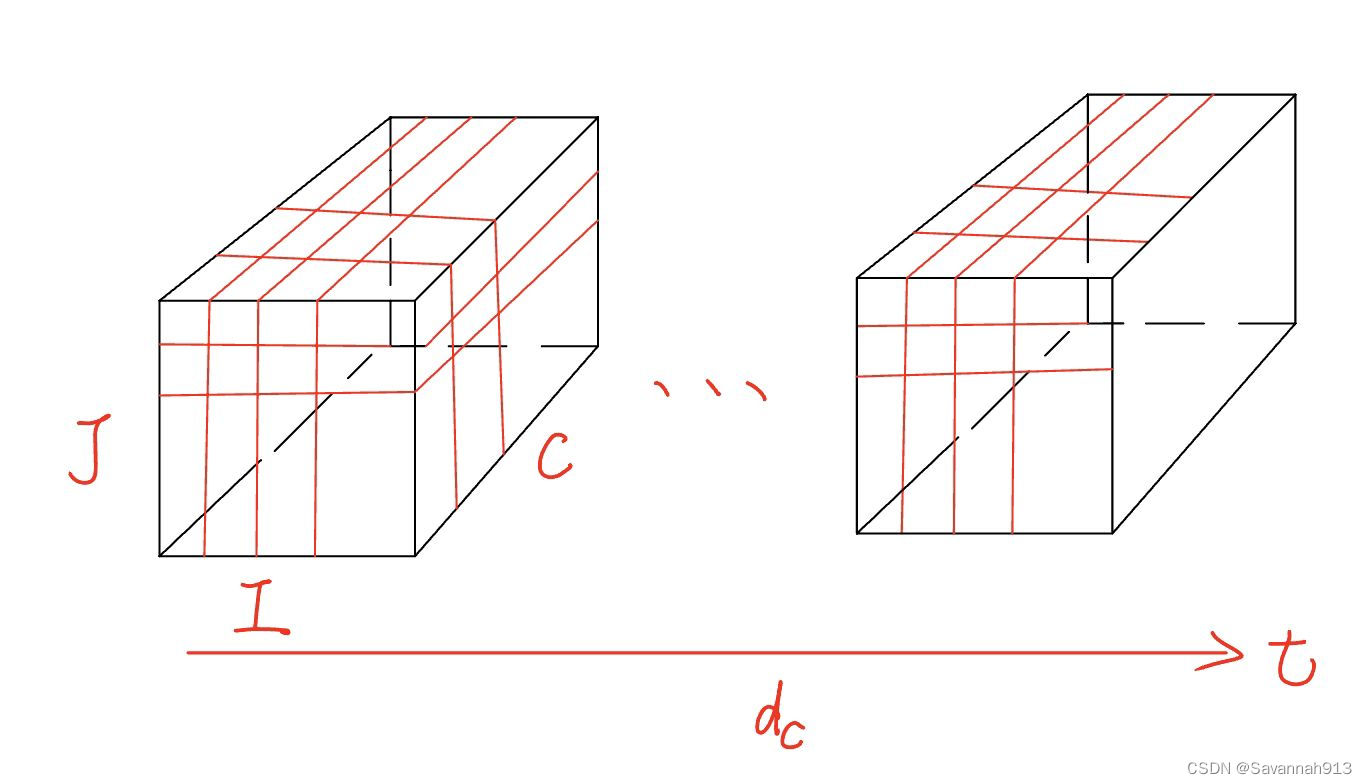
①三维卷积Con3D
在时空网格数据中,邻近位置和相邻时间步观测的值都是相关联的,所以需要三维卷积捕获这种相关性。
堆叠Lc个三维卷积层去同时捕获时空网格数据在时空数据上的相关性。
*卷积运算,是第l个三维卷积层的输入,
为通道数(不同通道一不同卷积核—不同特征),f表示激活函数,W和b是可学习参数。
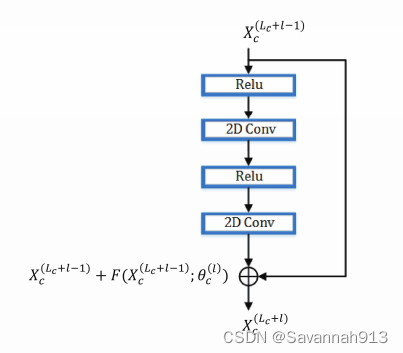
②残差单元
堆叠了Lc个三维卷积层后,时间维度上的特征得到了有效地挖掘。但是空间维度尺寸远大于时间尺寸,所以需要用二维卷积进一步探索空间上的模式。
一个二维卷积层仅能建模卷积核大小范围内的空间相关性为了扩大局部邻域范围内的空间相关性,需要连续堆叠多个 卷积层,此时需要残差连接来维持较好的训练效果。
在上述Lc个三维卷积层之后继续堆叠Lr个残差单元,其中,一个残差模块由两个激活层和两个二维卷积层顺序堆叠而成。
第l个残差单元可学习参数集合,
第l个参差单元的输入,
为通道数,当l=1时,为了对
进行二维卷积,需要将
重构→
,其中,
,才能对不同特征
的I*J进行二维卷积操作,捕捉空间上的相关性。
③重校准模块(RC)
时空交通网格数据中的不同网格区域有不同特点,RC可以充分考点这种特征重要程度的异质性。同一时空相关性的重要程度在空间维度是变化的。因此量化和调整同一特征对不同空间区域上的预测目标的重要程度是预测任务的关键环节。在最后一个残差单元ResUnit后堆叠一个Rc模块 。
o表示哈达玛积,量化各个通道级别的特征的重要性特征,通道特征的贡献度,增强有用特征贡献度,抑制无用特征贡献度。。
周周期依赖组件(过去几周)
输入为近期历史子序列,其中
固定为一星期,
表示周周期依赖序列长度,即考虑历史
个星期的信息。
周周期性组件首先利用卷积层捕获交通数据在时间维度存 在的周期模式,然后利用重校准模块来重新量化由底层神经网络学习到的时空特征对于每个网格区域最终预测目标的重要性。
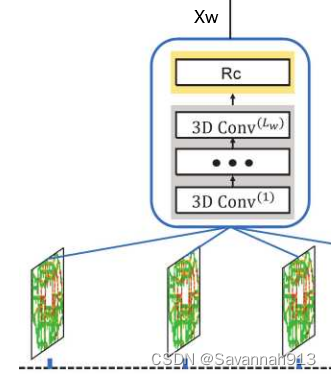
①三维卷积Con3D
使用三维卷积是为了捕获沿时间维度的周周期性和趋势模式,因此,三维卷积 中沿着时间维度的卷积核尺寸设置为大于1的正数,而沿着其他两个空间维度 的卷积核尺寸设置为1。卷积核大小n*1*1。
是第l个三维卷积层的输入,
为通道数f表示激活函数,W和b是可学习参数。
②重校准模块(RC)
为不同区域的不同特征分配不同权重。
o表示哈达玛积,量化各个通道级别的特征的重要性特征,通道特征的贡献度,增强有用特征贡献度,抑制无用特征贡献度。。
融合层
近期依赖组件和周周期依赖组件的输出分别表示为和
。近期依赖组件和周周期依赖组件的重要性程度在所有网格区域上并不是完全相同的。在将两个输出融合时,两种类型特征的重要程度需要从历史数据中学习得到。
将两个子组件的输出进行融合后,经过一个激活函数,得到最终的预测输出:(eg:Relu)
损失函数:均方误差(Mean Squared Error, MSE)
优化器:Adam算法
第4章面向时空图数据预测的时空注意力图神经网络模型
简介
①基于注意力机制的时空图卷积模型(ASTGCN)
将ChebNet图卷积与时间维度一维卷积相结合,用于解决时空交通图数据的预测问题。用时空注意力模块自适应地调节图信号序列在时间和空间维度上的相关性的强弱。提取了与预测目标处于相同时间段的三段子序列,并采用三个结构相同的子网络分别建模交通数据的周周期模式、天周 期模式和局部模式。
②时空注意力图神经网络模型(ASTGNN)
ASTGNN利用注意力机制充分建模了交通数据在时间和空间维度的动态性。时间维度的注意力机制使得输入序列中 的任意两个时间步的信息都可以进行直接交互而忽略他们之间的距离,这使 得ASTGNN拥有一个高效的全局感知域,从而保证其能够进行准确的长期预测。
在时间维度,设计了一种趋势感知自注意力模块,使自注意力能够感知时间序列的局部变化趋势;同时,提 出了一种新颖的动态图卷积模块,该模块可以有效捕获交通数据中动态的相关 性。
问题定义
交通网络:有向或者无向图G = (V,E)
图信号矩阵:第t个时间间隔内,交通网络G上的信号矩阵(N个图节点,每个节点C个特征观测值)
:在第t个时间间隔内节点v的C个观测值。
历史个时间片的时空图信号矩阵
,全局周 期序列
和局部周期序列
,预测
时间片内的图信号矩阵
。
基于注意力机制的时空图卷积神经网络
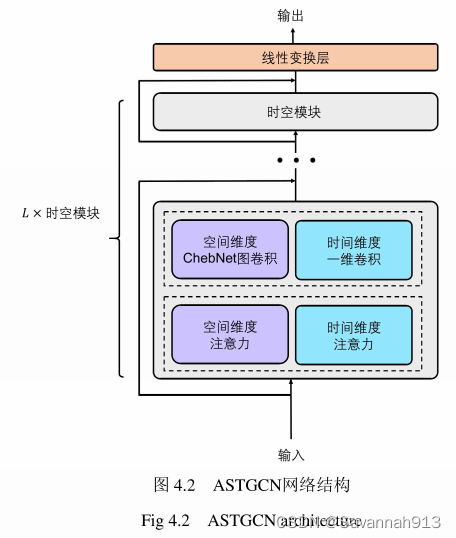
时空注意力模块
注意力机制
核心思想:突出对象的某些重要特征,根据对象的重要程度赋予权重重新分配资源。
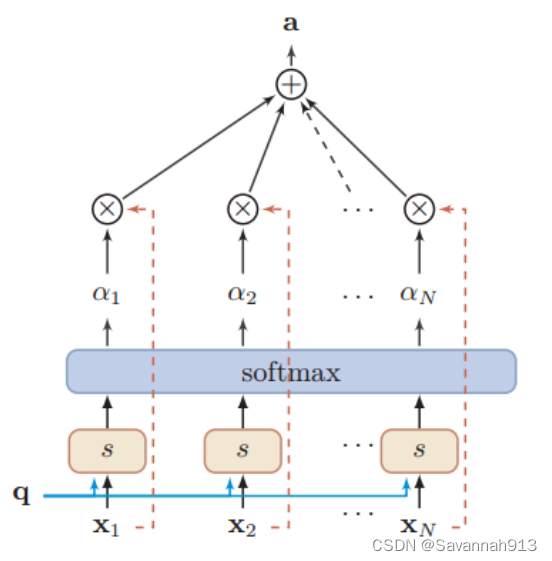
空间维度注意力
该模块的核心思想是根据输入数据自适应地计算空间邻居节点之间的相关性强弱。
表示sigmoid函数。
是第l个时空注意力模块的输入。矩阵
中的任意一个元素
表示了图中 节点i和节点j之间的相关性强弱。为了动态控制图卷积中信息聚合时邻居节点的重要程度,此处利用公式
实现对相关性的动态建模,其中
表示哈达玛乘积。
时间维度注意力
时间维度根据输入数据自适应地计算相邻时间片的数据点之 间的相关性强弱。
矩阵中的任意一个元素
表示了图中 节点i和节点j之间的相关性强弱,根据
对输入数据做出动态调整,形式化表示为
时空图卷积模块
采用ChebNet图卷积建模时空图数据在非欧空间上的相关性, 利用一维卷积捕获时空图数据在时间维度的相关性。
空间维度ChebNet图卷积
ChebNet利用切比雪夫多项式将图卷积的操作限制在了K阶邻域内(控制了卷积的感受野),在时空图数据上, 通过堆叠多层ChebNet图卷积就可以由近及远依次捕获图结构上节点之间的空间相关性了。
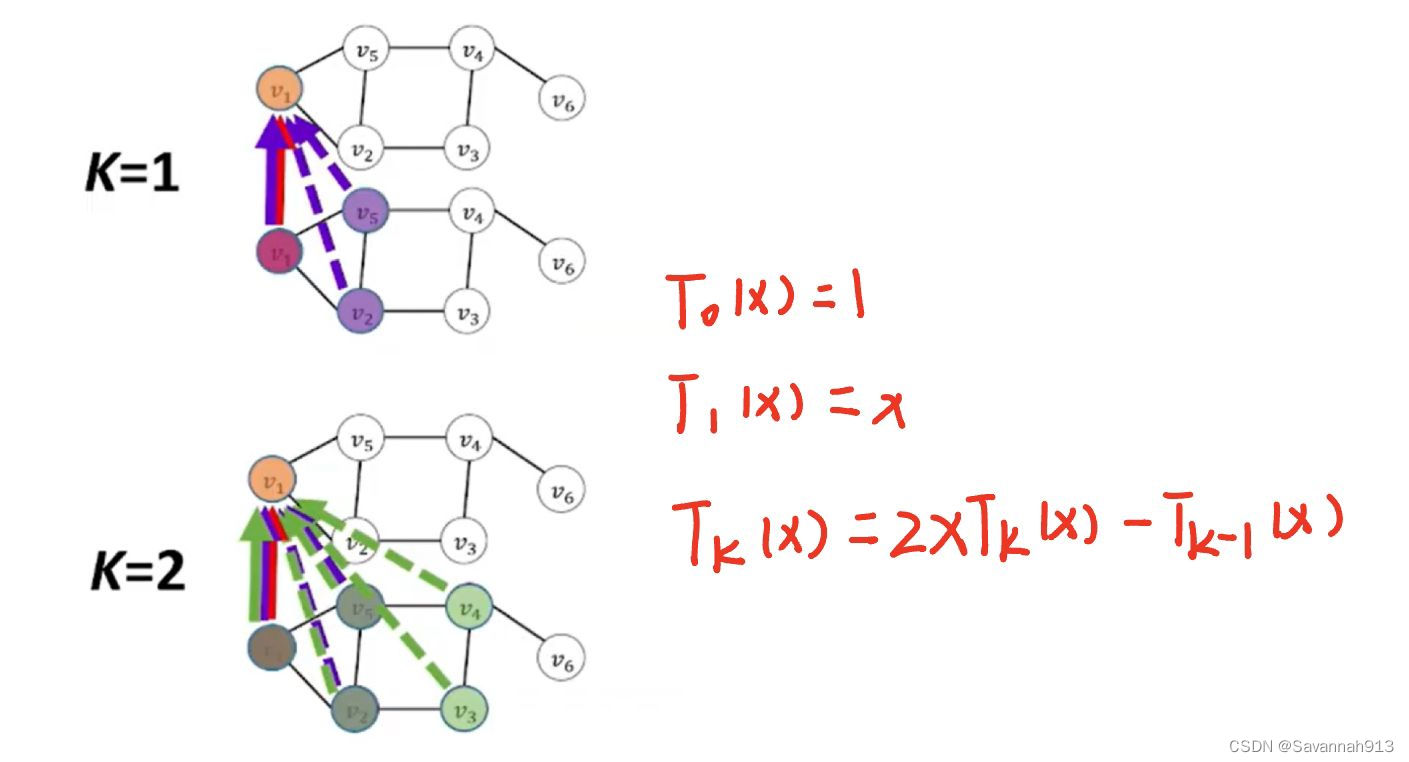
ChebNet形式化表示为
X是由之前的空间注意力机制计算出来的加权后的(
)。
是归一化的拉普拉斯矩阵
(
),
是L的最大特征值。
是待学习的参数,对应于契比雪夫多项式系数。
时间维度一维卷积
建模时空图数据在时间维度上的相关性,模型采用沿时间维度的一维卷积对数据进行处理。该一维卷积核1*n在每个节点上都是共享的。一维卷积的输入同样是经过了时间注意力机制之后的加权值。
ASTGCN与ASTGNN的区别
ASTGCN结合注意力机制和时空图卷积描述时空图数据的时空动态性,但是时间维度一维卷积受感受域大小的限制,无法有效建模时间维度任意两个时间步之间的相关性。此外ASTGCN没有对时空图数据的异质性进行建模。基于编码解码架构的时空注意力图神经网络ASTGNN利用自注意力机制建模时间维度动态性并遵循编码器 (encoder)-解码器(decoder)框架,可以实现任意两个时间步的相关性,对时空图数据的异质性进行充分建模。
基于编码解码架构的时空注意力图神经网络
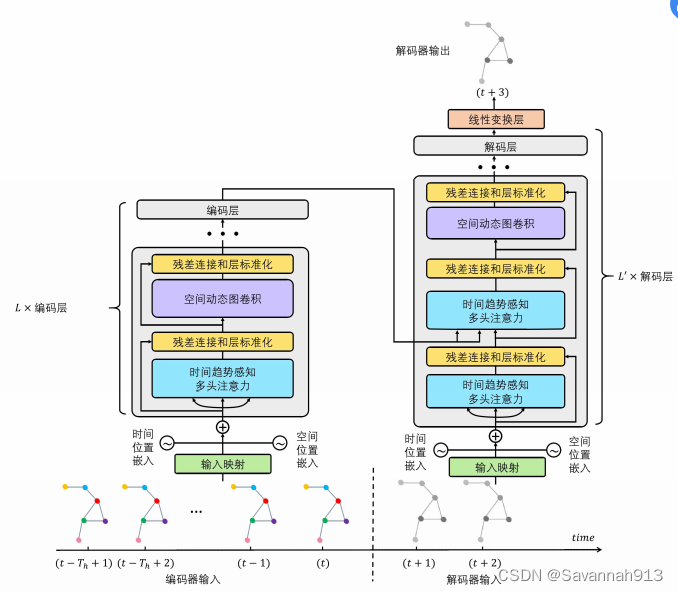
补充:
时间趋势感知多头自注意力
补充多头自注意力机制
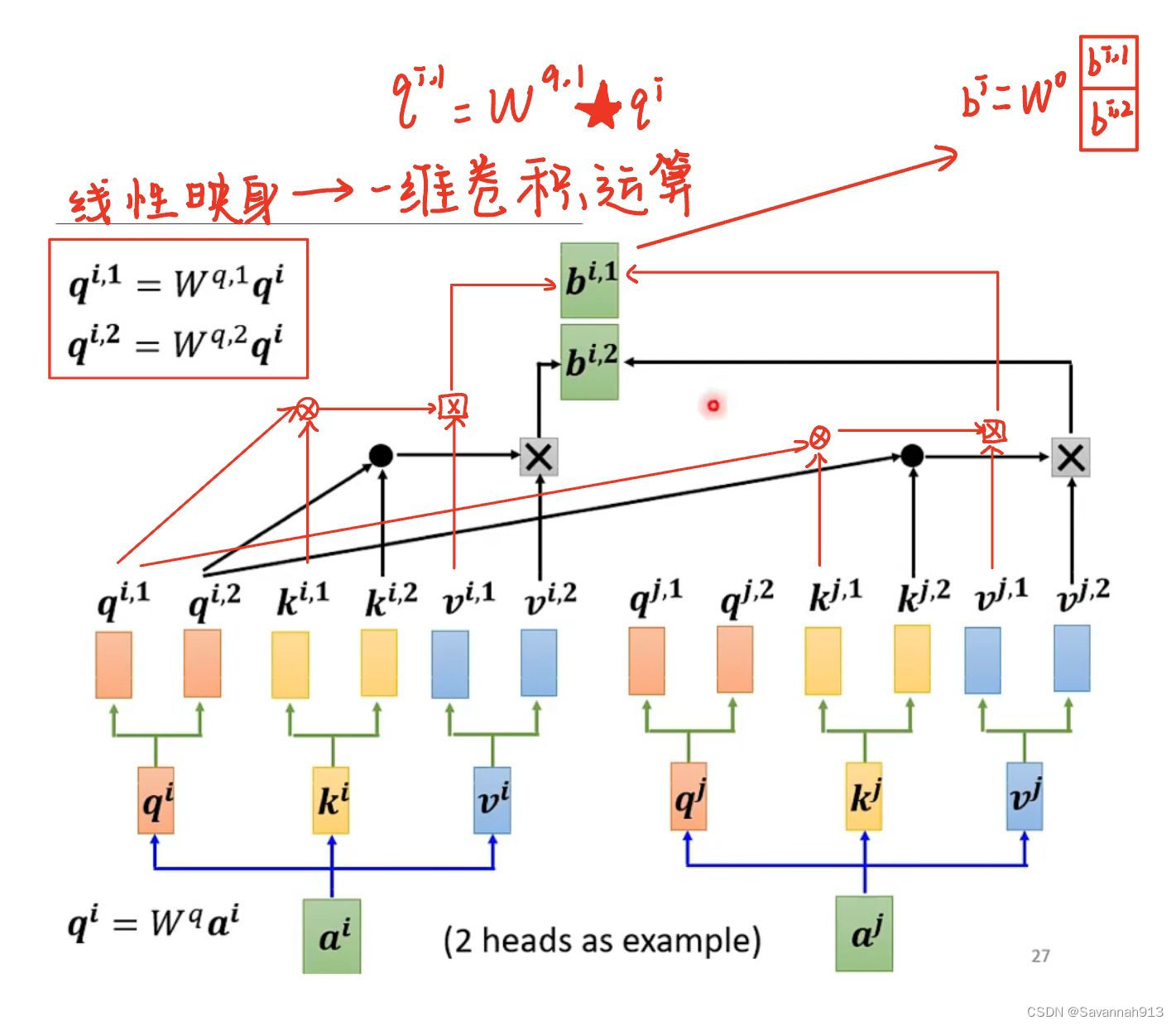
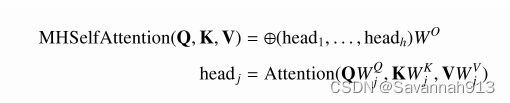
多头自注意力可以使模型直接建模序列中任意两个元素之间的相关性而无视 他们之间的距离,即多头自注意力机制使得ASTGNN模型在时间维度上具有全局感知域,但是连续数据预测中传统多头自注意力不可感知局部趋势,所以使用一维卷积运算代替了传统自注意力机制中的线性映射函数,即时间趋势感知自注意力机制

表示卷积操作,
表示卷积核,通过时间趋势感知自注意力机制,模型可以准确地建模交通数 据在时间维度的动态性,此时得到的中间表示为
空间动态图卷积
使用GCN捕获不规则的图数据中蕴含的局部和全局空间模式。图卷积的目的是让节点的信息沿着图结构由近及远进行传播,进而学习得到新的图节点表示。具体来说,给定一个节点,GCN首先聚合其邻居表示,得到融合了邻域信息的节点表示,然后再经过线性变化和非线性激活得到节点的最终表示。
如果说ChebNet图卷积是用K阶邻域来控制感受域,那么GCN就是用一阶邻居感受域通过叠加多层的方式实现节点信息的传播,一般叠加2~3层。
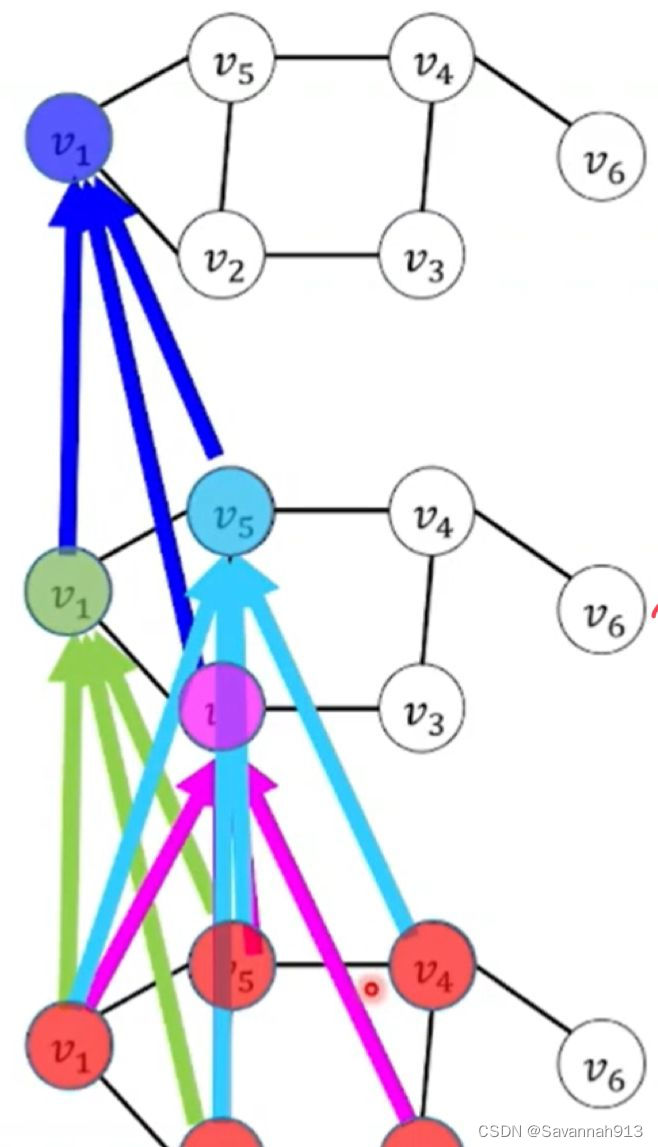
补充GCN:
思想:每层GCN的输入为邻接矩阵A和节点的特征矩阵H∈,现将A与H相乘在乘以参数矩阵W,最后对其应用激活函数,这就相当于一个简单的神经网络,由于邻接矩阵主对角线(描述节点自身关系)为0,在进行计算时会忽略节点本身,所以A+I,再对其进行标准化处理就会得到最后的
。

将GCN应用于交通图上,可以捕获节点间的空间相关性,但是无法捕获时间上相关性的动态变化,因为节点间相关强度的权重矩阵是固定的,结合之前的时间趋势感知多头自注意模块的输出
那么,空间相关性权重矩阵可以计算为
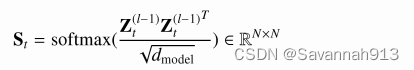
中的任意元素
反映了节点i,和节点j之间的关联性强度,即较大的值表示相关性强,较小的值表示相关性弱,这样就可以自适应地学习节点之间的动态性,那么动态图卷积就可以表示为:
经过如下所示L个编码层之后,就得到新的输出
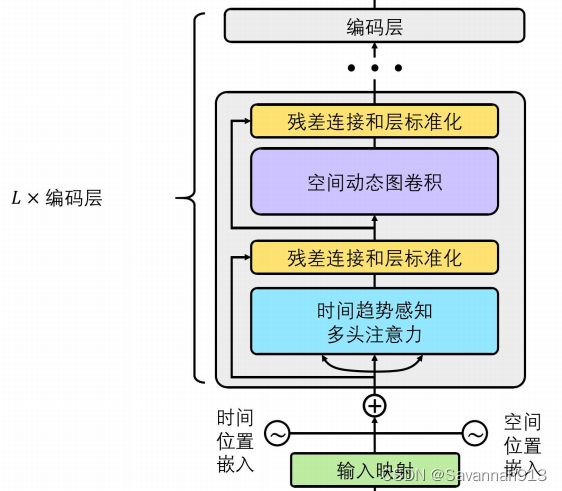
时空解码器
时空解码器以自回归方式进行数据序列的预测,每个解码器层均包含两个时间趋势感知多头注意力模块和一个空间动态图卷积模块。为了防止在解码器中做自注意力运算时利用到未来的信息,配合掩码机制,时间趋势感知多头自注意模块中的查询和键值上的一维卷积操作被替换成因果卷积。
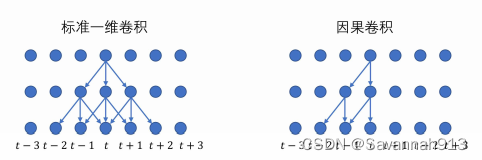
周期性
全局周期张量.为了捕获全局周期性,ASTGNN模型可以在输入数据中进一 步考虑了前w周内和预测目标具有相同星期属性且处于相同时间段的个时间步的交通图序列数据,用张量表示,即抽取前w周,每周Tp个小时。
局部周期张量.为了捕获局部周期性,需要考虑过去连续d天内每天与预测目标处于相同时间范围内的个交通图信号,
,即抽取前d天,每天Tp个小时。
将全局周期张量和局部周期张量
,拼接在一起,得到形状为
的张量作为输入。
位置编码
时间位置编码
为输入增加一个位置嵌入向量,保证相邻元素拥有相近嵌入,采用Sinusoidal位置编码,则处于位置t的元素的位置嵌入向量的每一维d,1<d<
的表示为:
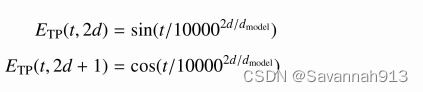
一文读懂Transformer模型的位置编码 - 知乎 (zhihu.com)
空间位置编码
图卷积(GCN)运算使邻居节点具有相似的表示,这样在节点表示中就蕴含了图结构信息。
①为每个节点分配一个嵌入向量,从而得到一个初始的空间位置嵌入矩阵 ②利用图卷积(GCN)对节点表示进行拉普拉斯平滑,得到最终的空间位置嵌入矩阵
。
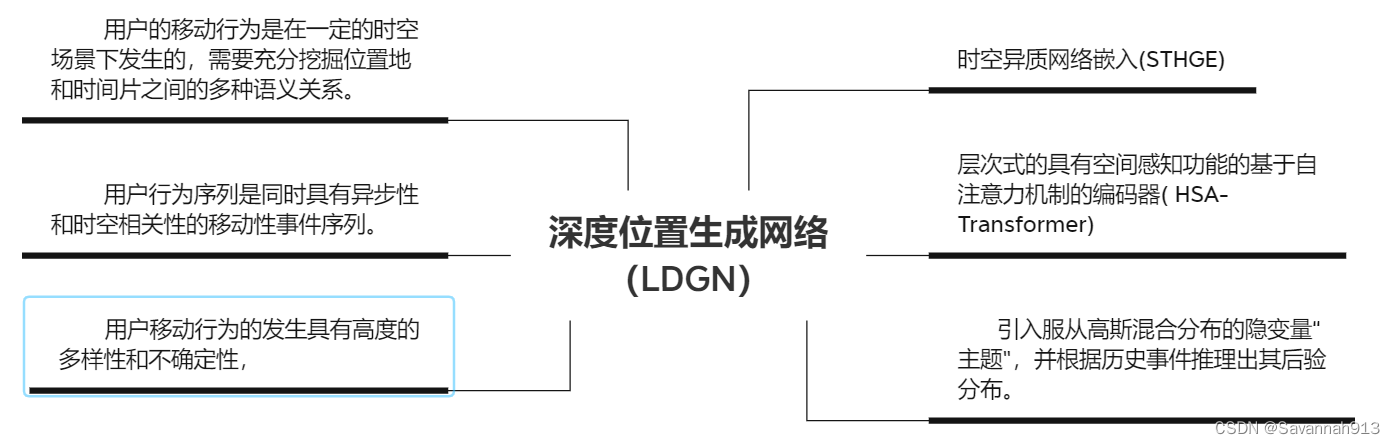
第5章面向时空事件发生位置预测的深度生成模型
目标:在已知用户历史移动行为的情况下,建模用户将要到访的下一个位置的生成过程。
用户移动事件序列中每个事件样本点是由时间特征(定位时间)和空 间特征(定位地点)唯一确定的。充分挖掘位置地和时间片之间的多种语义关系,有助于更全面地建模用户移动事件发生的时空上下文场景。
问题定义
用户集合U={},位置地点集合
= {
},每个位置的属性有位置地的经度、纬度和其所属的POI类型(lat,lng,cat),时间节点的特征:星期属性、时间片索引。历史事件序列
,事件的发生严格沿时间递增,
表示用户的一个移动事件。目标是预测下一个移动事件发生时用户将到访的位置
由于数据缺失等问题,记录中任意两个连续的移动事件之间的时间间隔可能会非常大,那么这样的两个连续的移动事件之间的因果关联关系将会很微弱。可以在每个会话窗口内任意两个连续的移动事件的发生时间间隔小于阈值,并且在预测时只对当前会话窗口内的用户将要到访的下一个位置进行预测。
模型整体结构
①从先验分布p(c)中选择一个主题类别c
②从第c个服从高斯分布的主题表示中生成一个该主题类别对应的主题表示向量,具体形式化描述如下:
其中,先验分布中的是一个超参。
是高斯混合分布中每个高斯先验分布的均值和方差,会随着模型进行端到端的训练。
③当得到了用户的主题需求后,就可以从下面的多项分布中生成下一个移动事 件发生时用户到访的位置:
其中,多项分布中的参数,由用户u,下一个移动事件的主题表示z及历史移动事件 序列
共同决定。
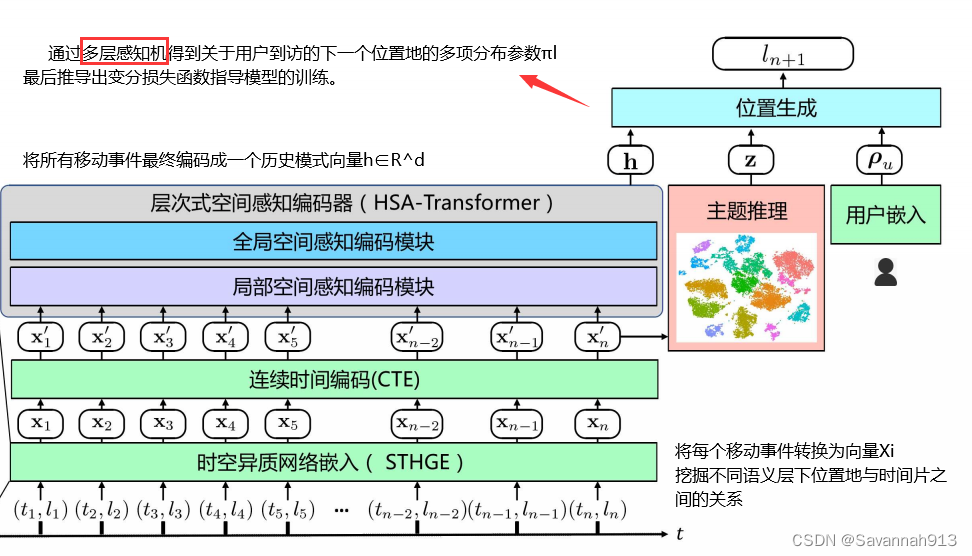
时空异质网络嵌入
构造时空异质图的目的是为移动事件发生时的时空上下文提供全面的描述, 这种全面的描述不仅仅包含对位置信息和时间信息的描述,还揭示了它们之间的关系,步骤如下:
①构造一个以位置地和时间片为节点的时空图分别为位置节点和时间节点定义两种类型的元路径。
②然后,采用一种基于注意力机制的层次式聚合方式,先将指定元路径下节点的邻居表示进行聚合,然后再将不同元路径下的节点表示进行聚合得到最终的节点表示。
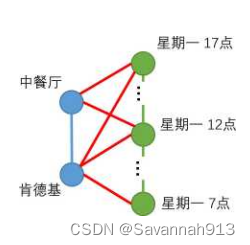
时空图的构造
时空异质网络图G = ,(点,边)
对于图的节点:时间维度离散化为大小相等的时间片,表示时间节点,
表示位置地点,
,使用T表示时间节点 的节点类型,用S表示空间节点的类型。
对于图的边:三种边
如下图所示,两种点,三种边:
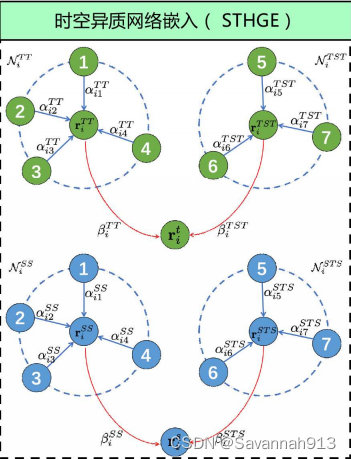
元路径
四种类型的元路径,包括为时间节点定义的两类元路 径中{TT,TST}和为空间节点定义的两类元路径中
:={SS,STS},则通过上述定义的元路径可以连接任意两个同类型节点以此来学习到时间节点的相似性和周期性、空间节点的邻近性和相似性。
节点表示学习
①得到时间(空间)初始向量表示
模型先为每类特征随机初始化一个维度为的嵌入矩阵,其中
表示该特征取值集合的势,
表示嵌入向量的维度,嵌入矩阵中每一行对应了特征的某个特定取值的向量表示。给定一个节点,将其原始特征的嵌入表示的拼接作为该节点的初始向量表示。
定义两个特征映射函数:
将一个时间片作为输入,输出该时间片节点的初始向量表示,即将该时间片的星期属性的表示和时间片索引的表示作拼接得到v ∈
。
将空间节点作为输入,输出该空间节点的初始向量表示,即将该空间节点的经度索引、维度索引、POI类别索引对应的向量表示作拼接得到v ∈
。
②将时间(空间)节点的初始向量表示作为输入,通过异质网络嵌入模块(STHGE)得到聚合了不同语义的邻居信息的时间(空间)节点表示
用r表示异质网络中的任意一个节点。给定一个时间节点的初始表示向量,
表示其在元路径
下的邻居节点的集合。
STHGE模块第一步先聚合元路径定义下的邻居节点表示生成该节点在元路径p下的节点中间表示。形式化定义如下:
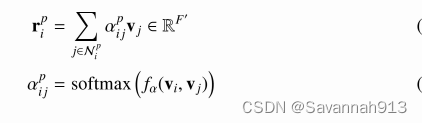
在实际计算中,本研究采用K'头注意力机制。即在执行元路径下的节点表示聚合前,
先将节点的初始表示通过线性变换映射到K'个不同的子空间,其中k= {1,2.... K'}。
然后在不同的子空间进行给定元路径下的节点表示的聚合操作。
最后再将不同子空间下得到的聚合后的节点表示拼接映射成最终节点中间表示
。
接下来,STHGE模块进一步采用注意力机制聚合不同元路径下的节点表示以得到最终的节点表示:
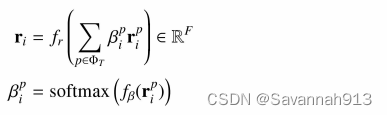
,
是三个多层感知机。
上述是对时间节点的聚合操作,空间节点的表示向量同上,最后,将STHGE输出的时间节点表示向量和空间节点表示向量进行拼接得到移动事件的表示向量
。
历史时空事件编码
从到历史模式向量表示h,利用连续时间嵌入模块的层次式空间感知编码器来捕获移动事件的异步性和时空相关性。
连续时间嵌入
对于连续事件之间的不等长的时间间隔信息,采用连续时间嵌入(CTE)的方式进行建模,即从连续1维时域到d维向量空间的函数映射,CTE与自注意机制相配合,使得模型在进行自注意的运算时可以感知到任意两个连续的事件之间不等长的时间间隔信息。

是模型的学习参数
W是为了将原始事件表示向量映射到与CTE表示向量同一个维度。
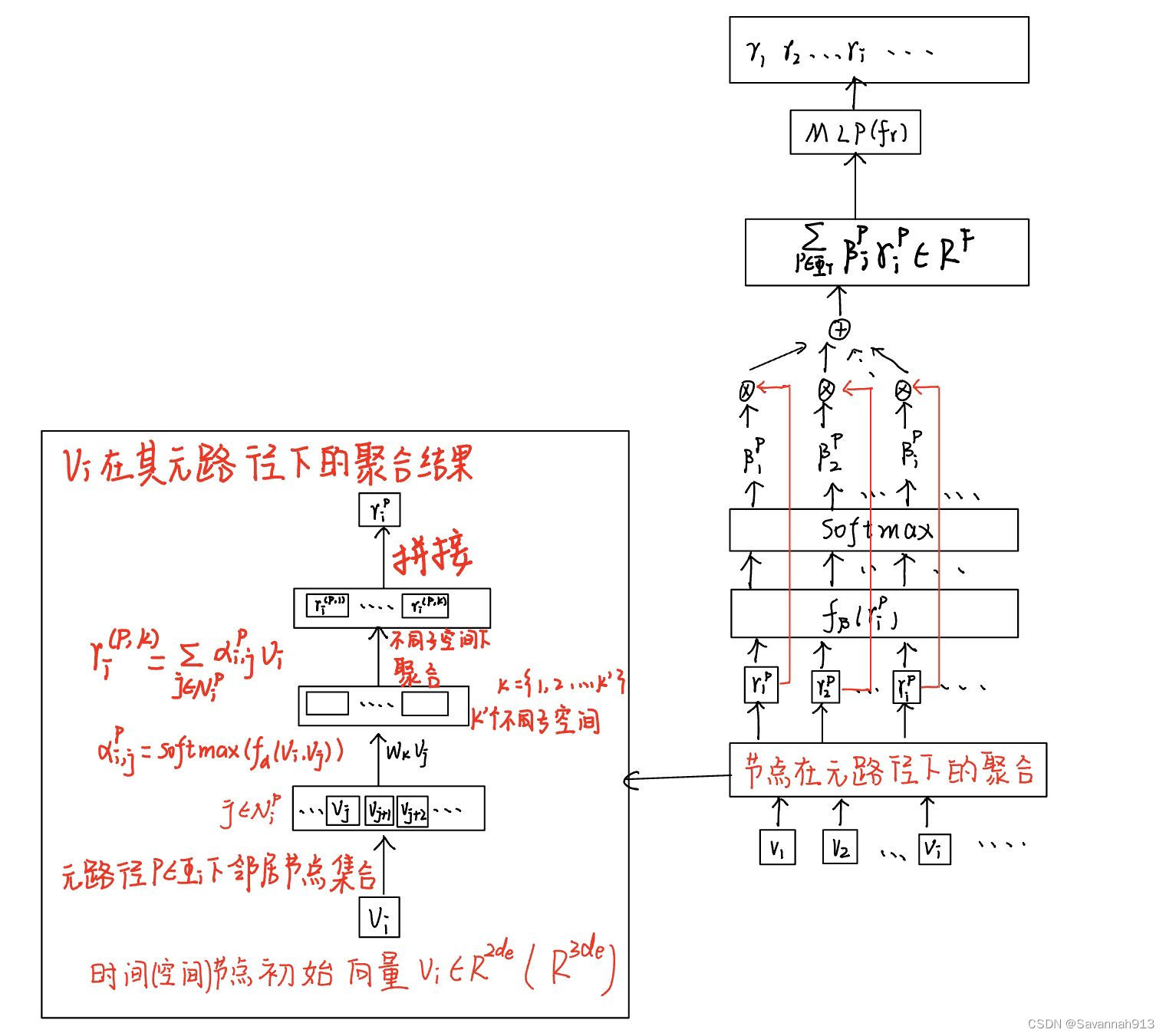
层次式空间感知编码器
主要任务就是得到整个历史事件序列的表示h
层次式空 间感知编码器由两个空间感知编码模块组成,其中第一个称为局部空间感知编码模块,它旨在学习每个会话内部的事件发生模式;第二个称为全局空间感知编码模块,它旨在捕获处于多个会话的事件之间的相关性。局部(全局)空间感知编 码模块分别由(
)个空间感知编码器单元组成。
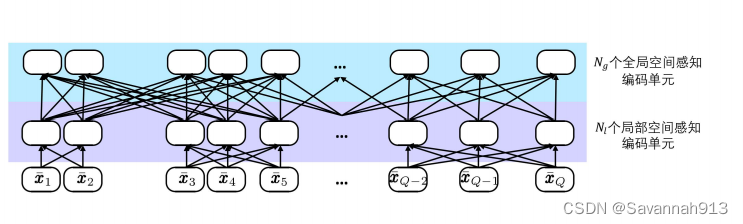
空间感知编码器单元由一个多头空间感知自注意力层和一个在不同位置上共享的前馈神经网络组成。此外,模型中为每层操作都加入了残差连接和层正则化操作以保证模型网络层数加深时的训练效率。
多头空间感知自注意力层(MHSA)
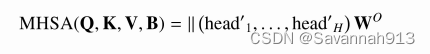
是空间距 离矩阵,其中任意一个元素
, dist(•, •)表示了任意两个 事件发生的位置地之间的地理距离。多头空间感知自注意力中,每个头的空间感知自注意力定义如下:
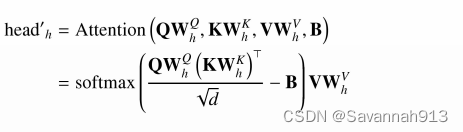
在进行两个移动事件的注意力分数的计算时减去了两个移动事件发生的距离偏置项,使得模型可以有效地感知空间信息,赋予近距离的位置地更大的权重。
模型推断
结合混合高斯分布(GMM)与变分自动编码器(VAE)的相关知识进行理解:
GMM中的不同高斯的权值是离散分布的,而VAE中的隐变量z是连续分布的,一般是一个高斯分布。那么x的分布情况:
在论文中,由于Z~,到访位置
~
,所以其分布表示为:
似然函数表示为,求似然函数最大值也就是求logP(x)的最大值,即:
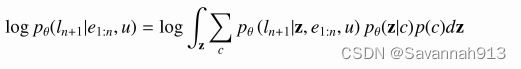
上述对连续高维变量z的积分无法计算,所以引入q(z|x)来帮助计算logP(x),对于q(z|x)的引入是通过乘以一个除以一个,再将两项分别计算,所以,对于原来的logP(x)来说,q(z|x)可以是任何分布,引入q(z|x)化简为:
![]()
论文中引入的q(z|x)如下:
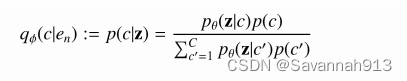
KL散度衡量两个分布的距离,所以KL(q,p)≥0,那么原式就可以写成:
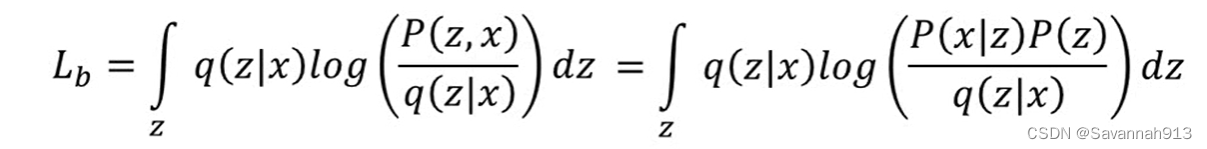
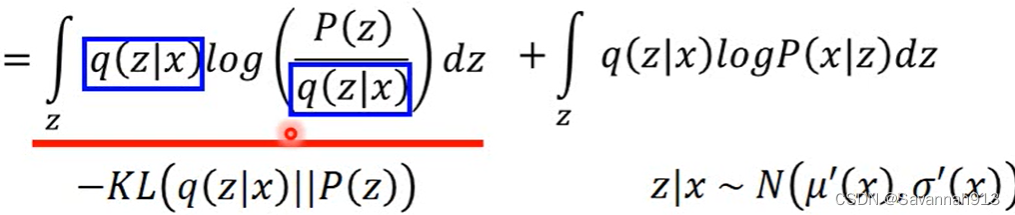
![]()
论文中的q分布如下:
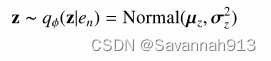
对于原来的似然函数,很大程度取决于Lb的值,如下化简利用了蒙特卡洛估计,即计算其后验分布的数学期望。
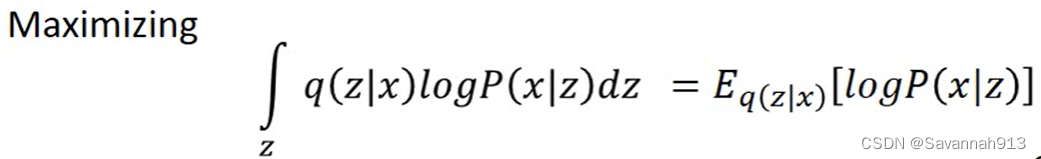
论文中的表示如下:
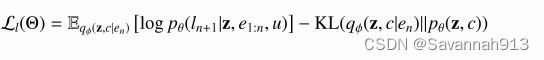
KL散度越小,似然函数越大,所以这里的q分布趋近于P(z,c)分布,似然函数的取值取决于前面的期望值。利用如下模型,论文采用多层感知机,反向传播梯度调整参数,使得似然函数最大化,优化编码器解码器中的参数,使μ(x)接近x,即得到。

左边是q(z|x)的过程,编码器的过程,右边是解码器的过程,即p(x|z)的过程。
第6章面向时空事件发生时间预测的深度生成模型
问题定义
数据定义同第五章表示 两个相邻发生的移动事件之间的时间间隔,目标是预测下一个移动事件发生的时间
。
模型整体结构
①从先验分布p(c)中选择一个主题类别c
②采样一个该主题类别对应的主题表示变量z~
③采样用户下一个移动事件发生的时间距当前时刻的时间间隔~
建模事件发生的时间间隔,采用包含K个组件的混合对数正态分布建模下一个事件发生的时间与当前事件发生的时间
之间的间隔
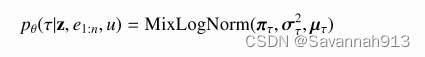
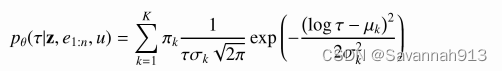
选择用混合对数正态分布建模时间间隔的优点:
①混合对数正态分布具有逼近任何函数的表示能力,可以充分学习人们复杂的移动行为模式。
②混合对数正态分布的期望有解析解,计算下一个事件发生的时间间隔的期望时会很高效。
(5条消息) 对数正态分布的期望方差_黎明的清新的博客-CSDN博客_对数正态分布的期望和方差
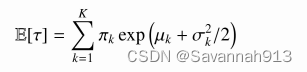
{
},
{
},
{
}
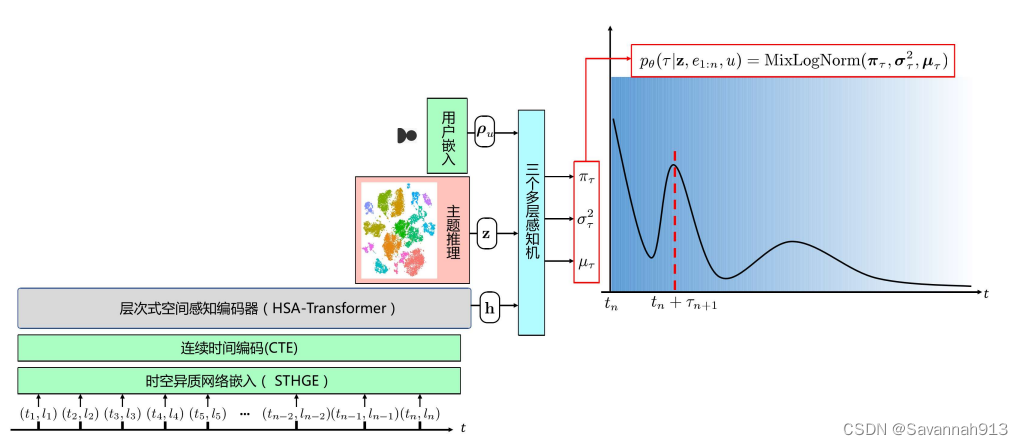
模型推断
与第5章不同在于,第6章对于时间间隔的建模采用的是混合对数正态分布MixLogNorm(),第5章对于位置点的建模采用的是混合高斯分布,但是对于参数的学习,求最大似然函数以及求,都同第5章一样。
总结















 3249
3249











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









