







目录
梯度消失与梯度爆炸(Vanishing/Exploding gradients)
梯度消失与梯度爆炸(Vanishing/Exploding gradients)
训练神经网络,尤其是深度学习所面临的一个问题就是梯度消失与梯度爆炸,即梯度有时非常大(小),甚至以指数级别的速度,可以通过更好地选择随机初始化权重来避免这个问题。
极深的神经网络
假设我的网络每层只有两个隐藏单元,每层的激活函数采用 g(z) = z 这种线性激活函数,且,那么将会输出
,显然每层的输出
,即
作为
值

假设每个权重矩阵带入上述
之后可以得到
,最后计算的结果
就等于
,对于比较深的神经网络,
将会很大,指数级爆炸式增长。同样地,如果将1.5换为0.5,那么
激活函数将会以指数级别递减。
权重值w比1略大一点,神经网络很深时,激活函数将会爆炸式增长;权重值w比1略小一点,神经网络很深时,激活函数将会以指数级别递减。这导致训练难度上升,梯度下降算法的步长将会非常小,梯度下降算法将会花费很长时间来学习。
深度神经网络的梯度爆炸和梯度消失问题很长时间内都是训练神经网络的阻力,虽然不能彻底解决,但是在初始化权重上提供了很多帮助。
神经网络的权重初始化
有n个输入的神经网络,如果只有一个神经元,那么它经过 a=g(z) 的处理得到,
,b=0,可以看到,当n越大,希望
越小,因为z是
的和,把所有项相加,希望每项值更小,最合理的方式就是设置
,其中n表示神经单元的输入特征数量,需要做的就是设置某层权重矩阵
,
就是给第l层的神经元数量。
如果激活函数使用的是relu,那么用的效果更好,relu激活函数取决于对变量的熟悉程度。如果激活函数的输入被均值和方差标准化,虽然不能解决梯度消失和爆炸问题,但是起到了缓解作用,因为它给权重设置了合理的值,不能比1大很多或者小很多,所有梯度没有爆炸或者消失得过快。
对于tanh激活函数来说,使用也被称为Xavier初始化(Xavier初始化的一个目的就是使前向传播和反向传播过程中每一层的输入和输出都具有相似的分布,即输入和输出的方差相同。),当然relu函数使用的是
。这些公式只是给出一个起点,给出初始化权重矩阵的方差的默认值,如果添加方差,那么方差将是另一个需要调整的超级参数。
梯度值逼近
梯度检验的目的是确保backprop的正确实施。
如何计算梯度的数值逼近
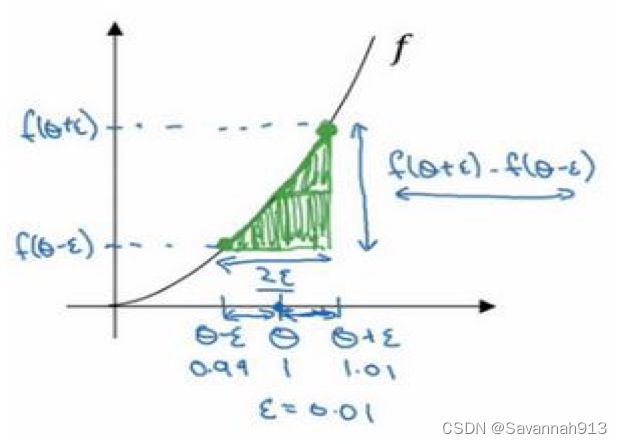
假设函数,在θ的左侧有θ-
,右侧有θ+
,对于图中的三角形,高宽比值接近θ
处的导数。即,令θ=1,
=0.01,代入计算得到最终值,误差接近0.03,所以使用双边误差的方法计算结果逼近导数值,在梯度检验和反向传播中使用该方法时,最终,它与运行两次单边公差的速度一样。使用双边误差可以判断g(θ)是否正确实现了f(θ)的偏导。
梯度检验
梯度检验可以调试或者检验backprop的实施是否正确。
两个梯度
假设网络中含有这些参数,、
......
、
,为了执行梯度检验,首先要把所有参数转换成一个巨大的向量,将所有W矩阵转换成向量之后,做连接运算,得到一个巨型向量θ,代价函数是所有W和b的函数,即J(θ),同样地,可以把
、
......
、
转换成一个新的向量,用他们来初始化大向量dθ,它与θ具有相同的维度。
J是超参数θ的一个函数,可以将J展开为J(,
,
......)不论超参数θ的维度是多少,为了实施梯度检验,要做的就是循环执行,即根据i遍历每个θ求导数,使用双边误差:
我们知道
应该逼近
,dθ[i]是代价函数的偏导数,需要对每个i对应的值都进行上述两种运算,最后得到两个向量,他们有相同的维度,要做的就是看他们是否接近。
梯度是否接近
定义两个梯度是否彼此接近,一般会计算欧几里得范数,即,求误差平方和,再求平方根,得到欧氏距离,然后用向量长度归一化,使用向量长度的欧几里得范数。
分母用来预防这些向量太小或者太大,分母使得这个方程式变成比率,如果这个结果小于等于,那意味着导数逼近有可能是正确的;如果这个结果在
与
之间,也许没问题,但是通常会再次检查这个向量的所有项,确保没有一项误差过大;如果结果到达
,这时需要仔细检查所有θ项,看是否有个具体的值,使得
与dθ[i]大不相同,并用它来追踪一些求导计算是否正确,经过一系列调试,最终结果达到
,那么就可能是正确的。
在实施神经网络时,需要经常执行foreprop和backprop,可能会发现梯度检验有一个较大值,那么就会开始调试,一段时间后,得到一个很小的梯度检验值,那么可以很自信地说,神经网络的实施是正确的。
梯度检验的注意事项
第一,不要在训练时使用梯度检验,它只用于调试,计算所有i值的是一个非常漫长的过程,必须使用W和b进行backprop来计算dθ,使用backprop计算导数,只有调试的时候才会计算它,确认数值是否接近dθ。完成后,就会关闭梯度检验。
第二,如果算法梯度检验失败,需要检查每一项,试着找出bug,即看看哪个与dθ[i]差那么多。
第三,实施梯度检验时,如果使用正则化,需要注意正则项,dθ等于与θ相关的J函数的梯度,包括这个正则项。必须包括这个正则项。
第四,梯度检验不能和dropout同时使用,每次迭代,dropout会随机消除隐藏层单元不同的子集,难以计算dropout在梯度下降的代价函数J。如果必须同时使用,可以将dropout的参数keepprob设置为1.0。
第五,在随机初始化时,w和b接近0,梯度下降算法的实施是正确的,随着梯度下降的实施,w和b有所增大,也许你的反向传播算法在w和b接近0的时候是正确的,但是w和b增大时,精度有所下降,可以尝试的一个方法是,在随机初始化时进行梯度检验,然后训练网络一段时间,那么w和b将会在0附近摇摆一段时间,即很小的随机初始值,在进行几次训练的迭代后,再运行梯度检验。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









