








安装瀚高数据库(银河麒麟/windows)数据迁移
一、前言
windows都是简单的安装,如果不想要特别繁琐,点击跳转windows的7、修改数据库配置信息
windows解决本地计算机 上的 hgdb-enterprise-6.0.4 服务启动后停止。某些服务在未由其他服务或程序使用时将自动停止。问题跳转11、解决问题
linux安装三、linux安装
如果要外部访问数据库四、外部连接数据库
数据迁移五、数据迁移
突逢变故,说信创只是以后计划支持达梦,目前只支持瀚高,我****,刚部署完的。

| 名称 | 网址 |
|---|---|
| 瀚高官网 | https://www.highgo.com/ |
| 瀚高下载 | https://www.highgo.com/down_main.html |
| 瀚高迁移工具 | https://gitcode.com/open-source-toolkit/de013/overview |
| 瀚高技术文档 | https://www.highgo.com/document/zh-cn/application/jdbc.html |
HighgoDB瀚高数据库管理系统V9.0有
Windos系统和Linux系统的包(有效期默认一年)
HighgoDB瀚高安全版数据库系统V4.5只有Linux的包(这个需要进行申请,有些人申请慢的话就打电话400-708-8006听到语音提示按4【也可以自己听一听根据需求选择】)(有效期默认一个月)
二、windows安装
这里使用Windows Server 进行测试的
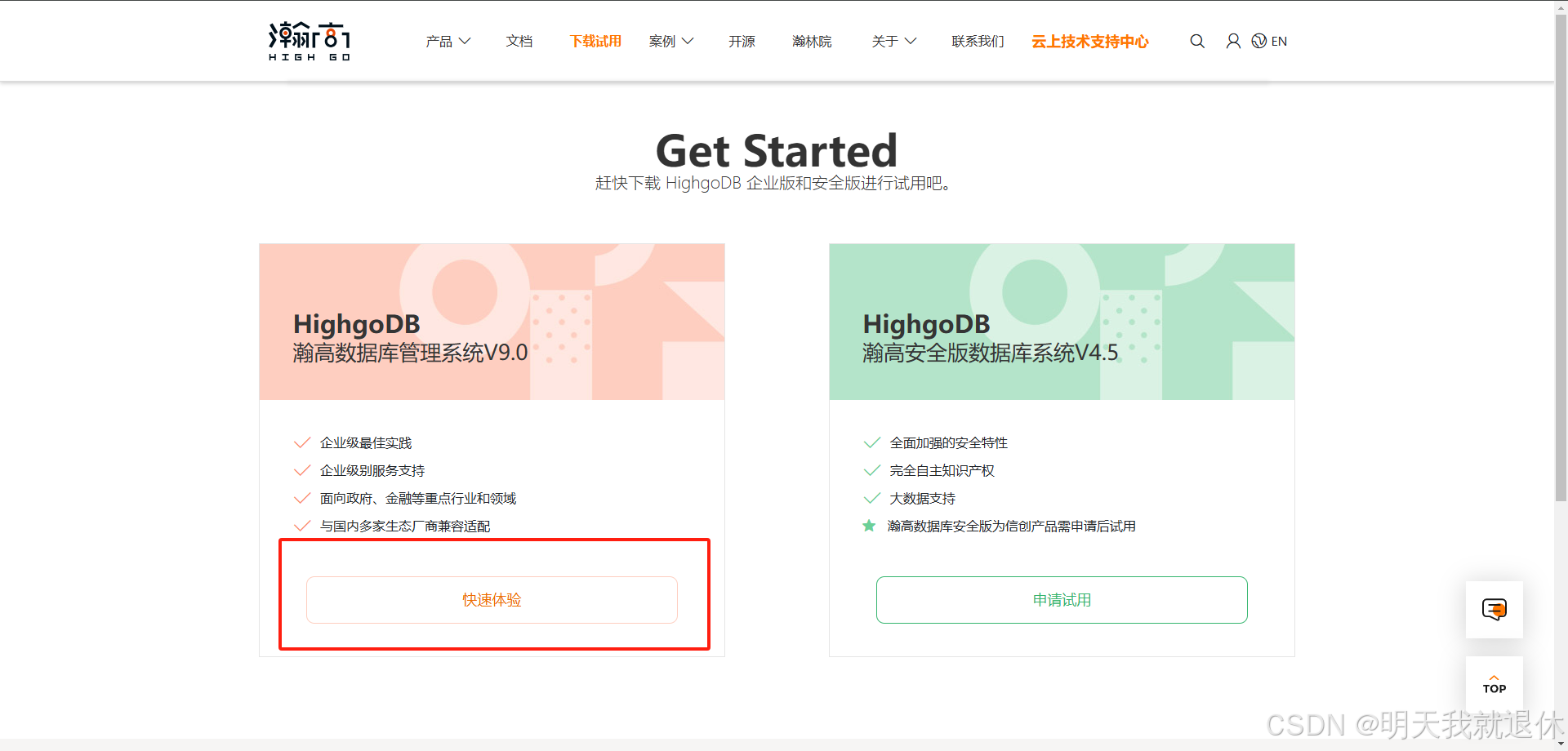
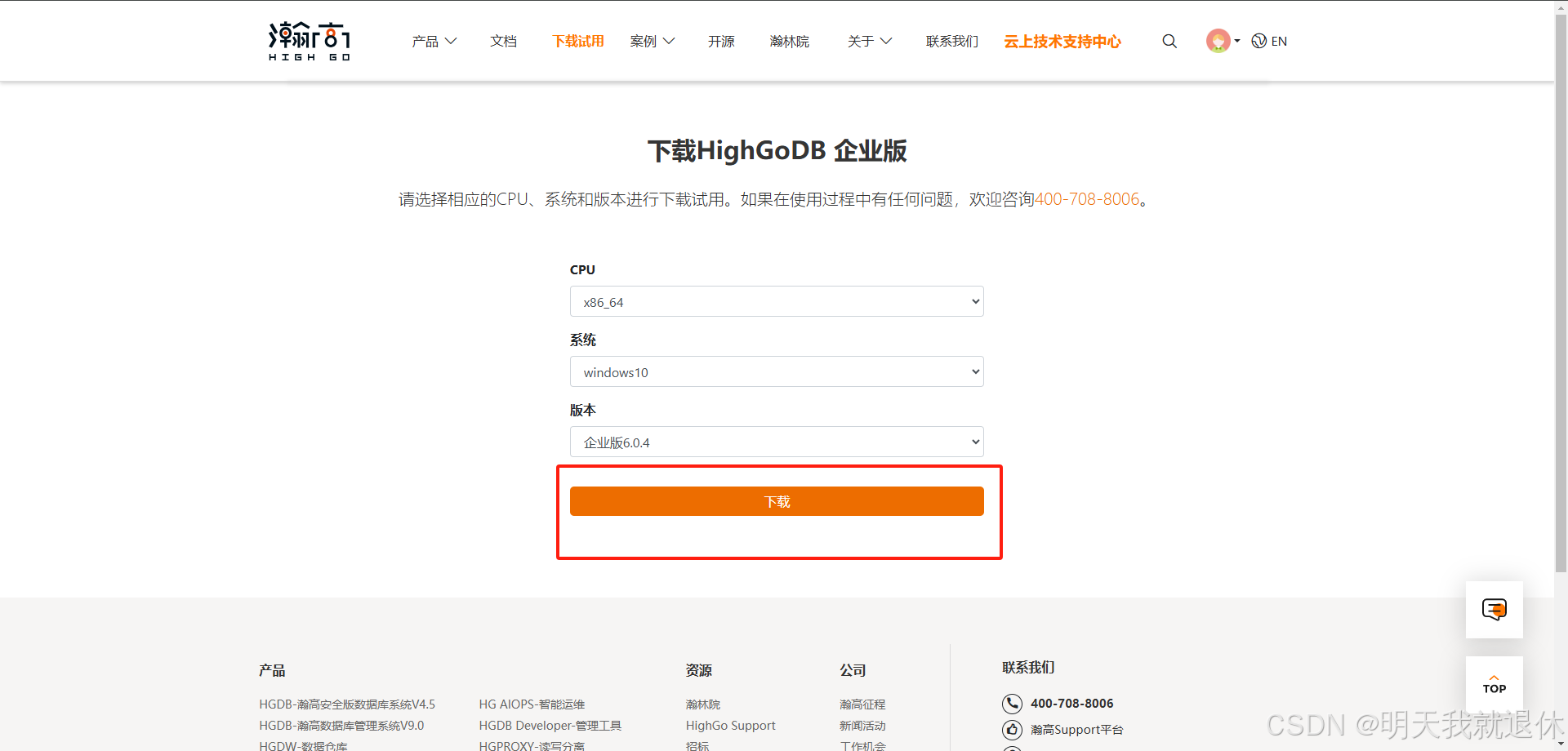
1、下载
登录瀚高官网可以直接进行下载:https://www.highgo.com/down_main.html
点击下载即可
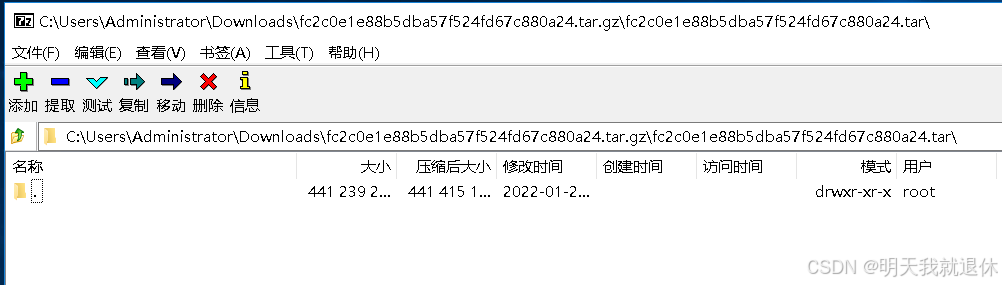
2、解压
下载完成之后是这样子,他的是那种linux系统的压缩包,不是win的zip压缩包,不过一样解压,就是要解压两次(或者进入文件两次)了
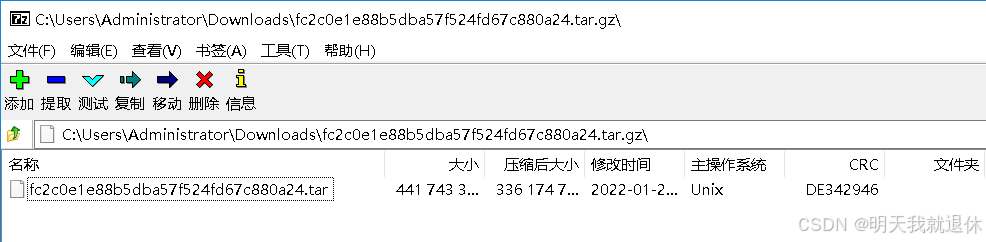
双击找个解压软件进行解压,这里用的7z
可以直接点击提取,解压出xxx.tar文件,然后在对其进行解压,或者可以继续点击
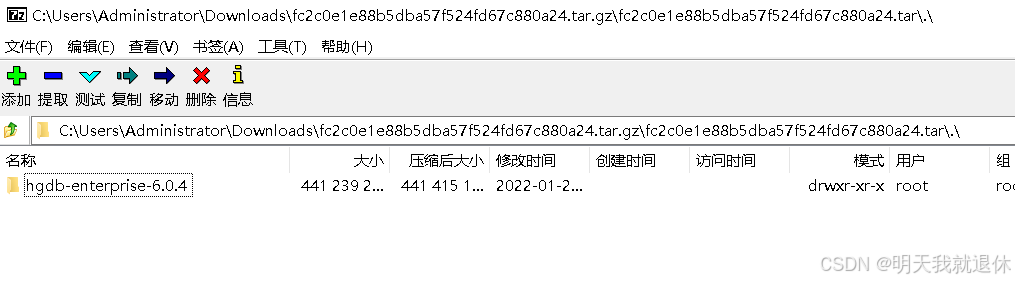
等待他加载完成进入目录就可以直接点击提取进行解压(因为.不能做文件目录所以他会默认解压到下一层文件)
也就是解压到这里(也可以进入这个目录进行解压)
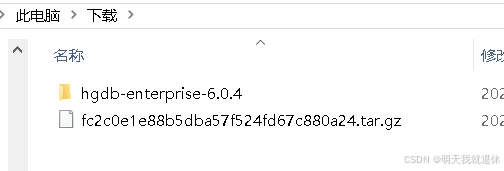
解压完成如下
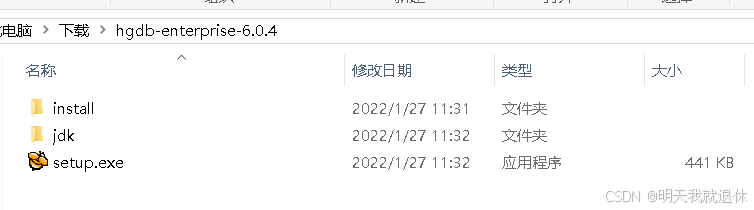
2、双击安装包,开始安装
进入
hgdb-enterprise-6.0.4文件夹双击setup.exe开始安装
3、点击下一步
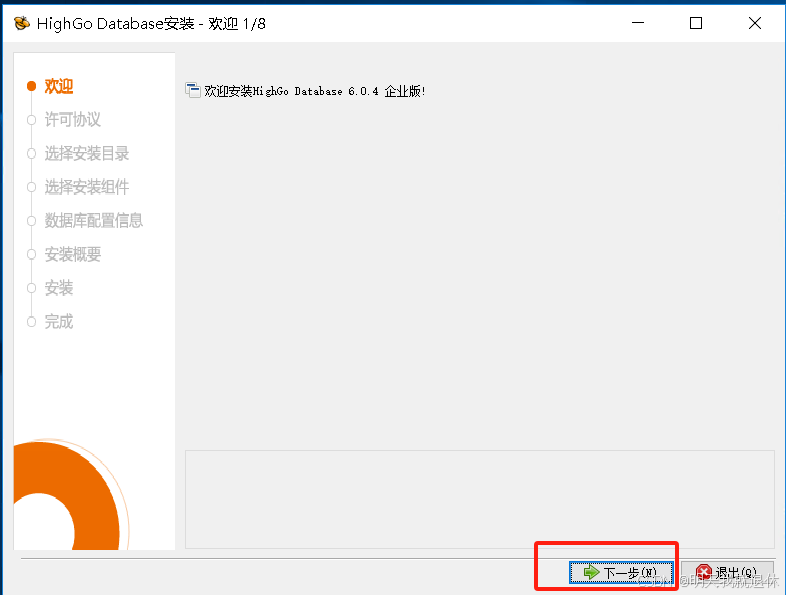
4、选择我接受协议,点击下一步
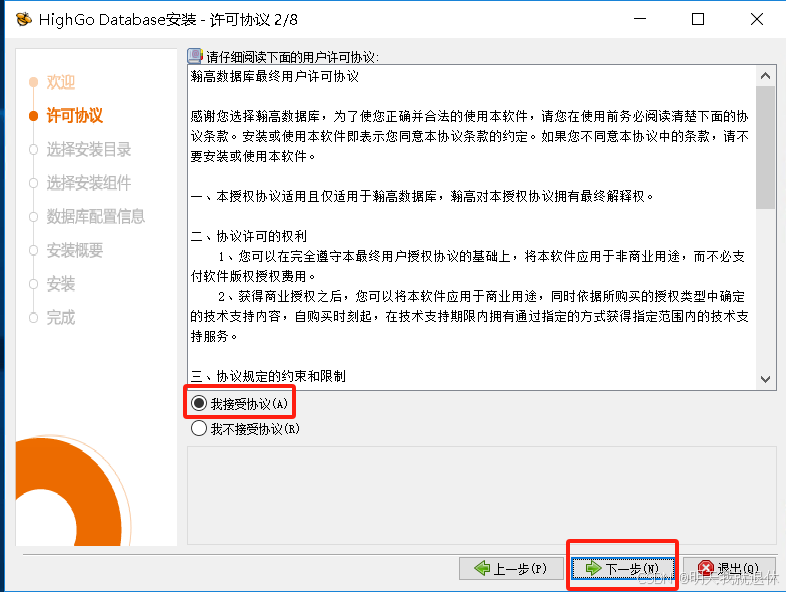
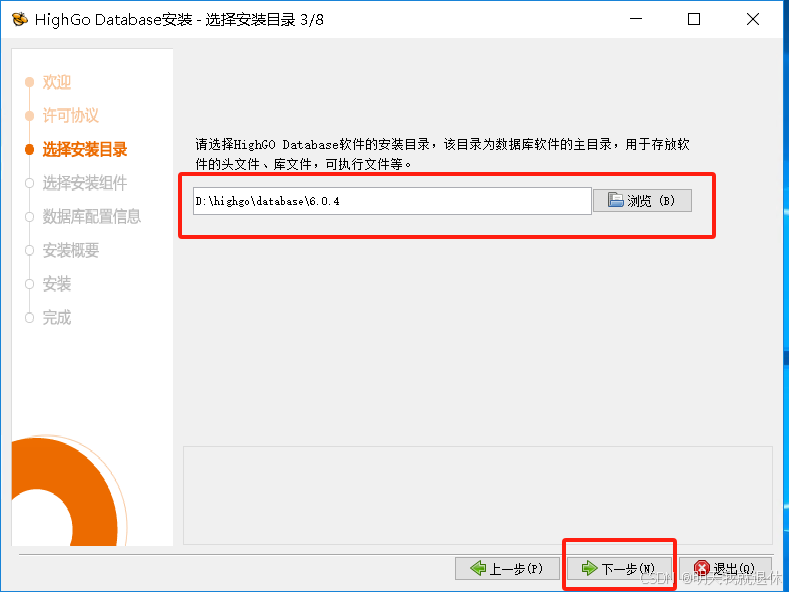
5、选择安装目录,下一步,确定
注:这里目标最好不要喊有标点符号中文汉字什么的,避免出问题,如果不想修改目录,建议将
6.0.4修改为604
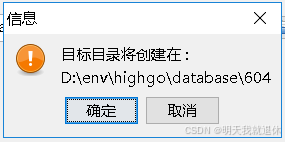
下一步之后会弹出提示框,点击确定就可以了
6、选择组件,下一步
这里的组件,根据自己的需求进行选择即可(点击对应组件会有提示的)
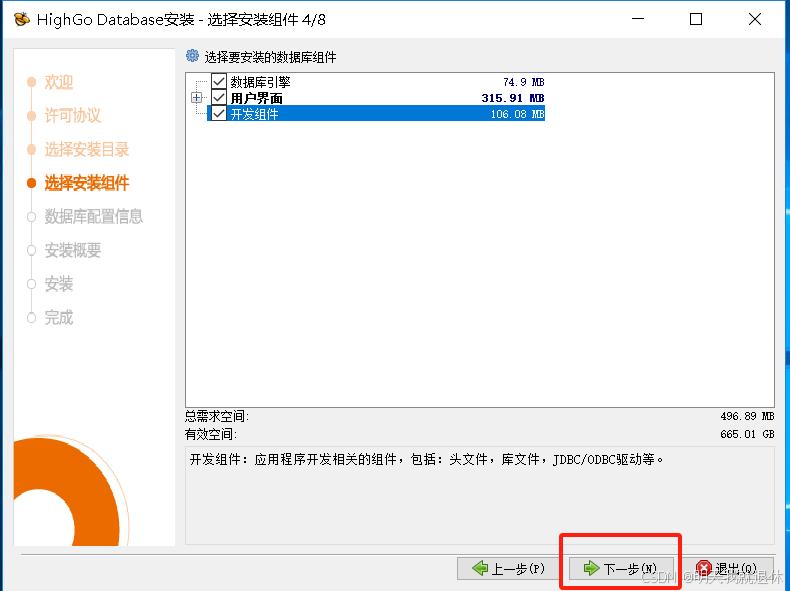
7、修改数据库配置信息,下一步
基本信息:这里了可以进行修改数据目录(也可以使用默认,一般都是安装目录下面的
/data)
可以更换端口和用户名称
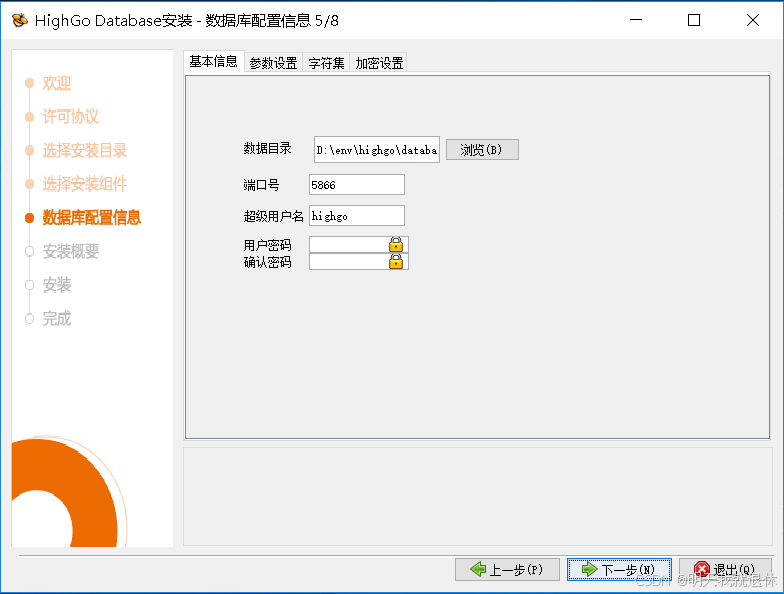
密码必须由大小写字母符号以及数字组成,且长度至少为8位。
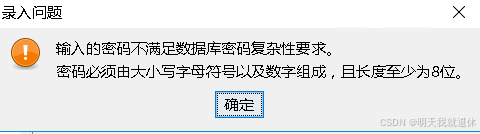
参数设置:可以根据自己的需求进行选择更改参数
字符集:没有特殊需求默认就好了。
加密设置:没有特殊需求默认就好了。
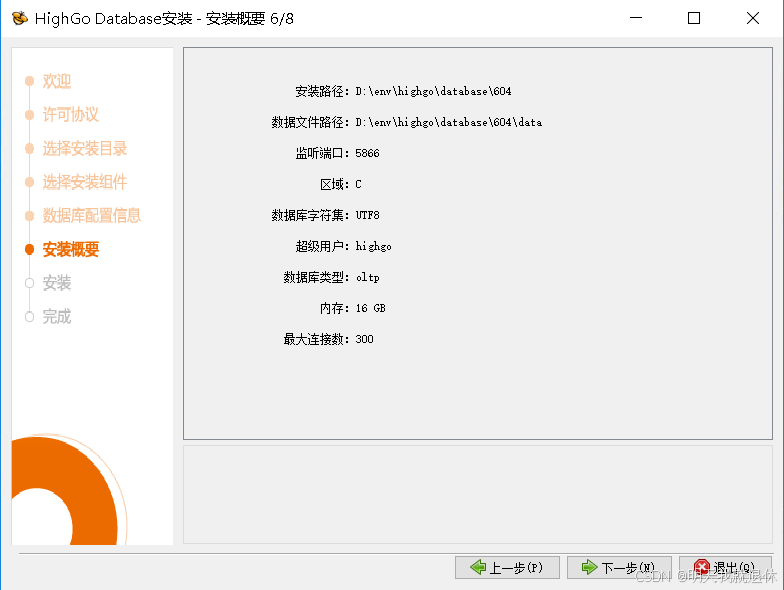
8、查看安装摘要,下一步
查看自己之前选择的,没有问题直接下一步就OK了
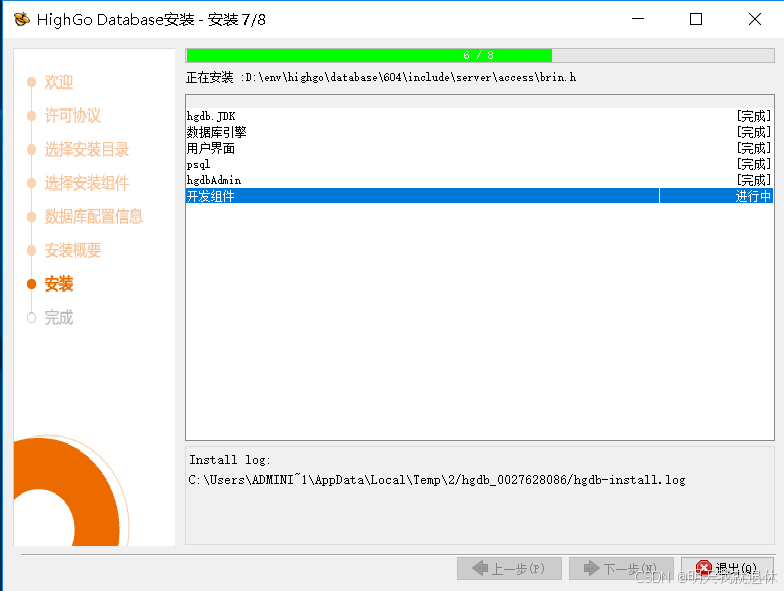
9、安装
然后就等着安装
安装成功后点击下一步
点击完成,直接结束
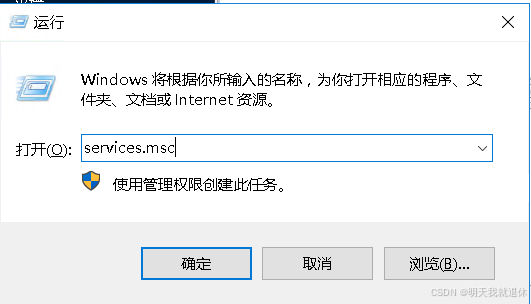
10、启动进程
services.msc
使用快捷键
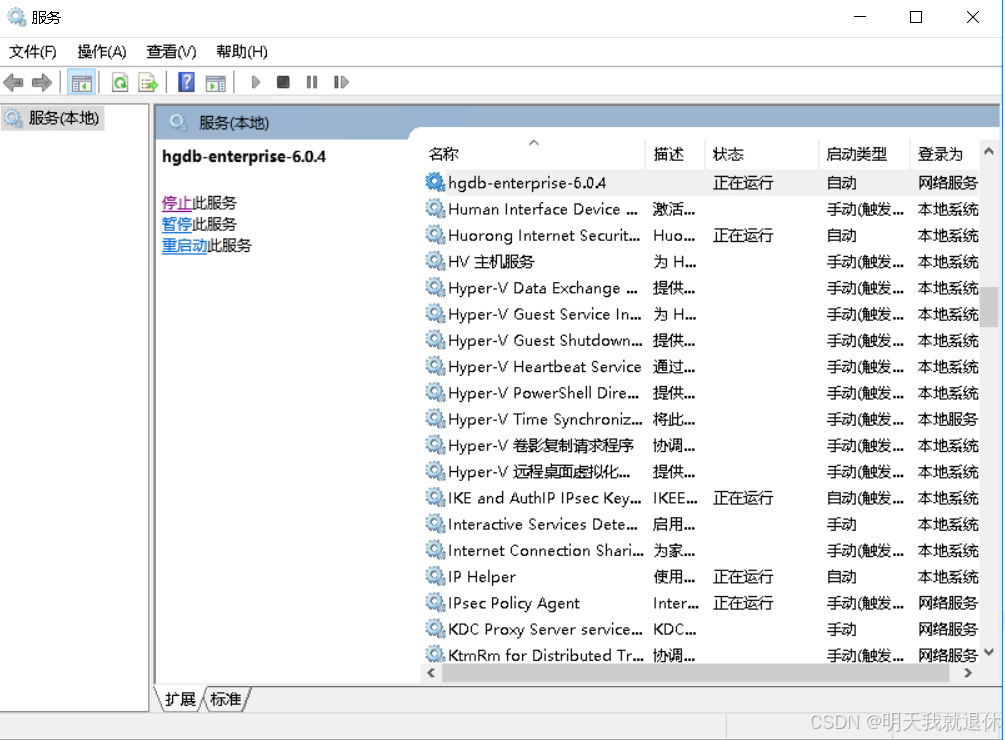
win+r打开命令窗口,输入services.msc回车或点击确认打开windows服务
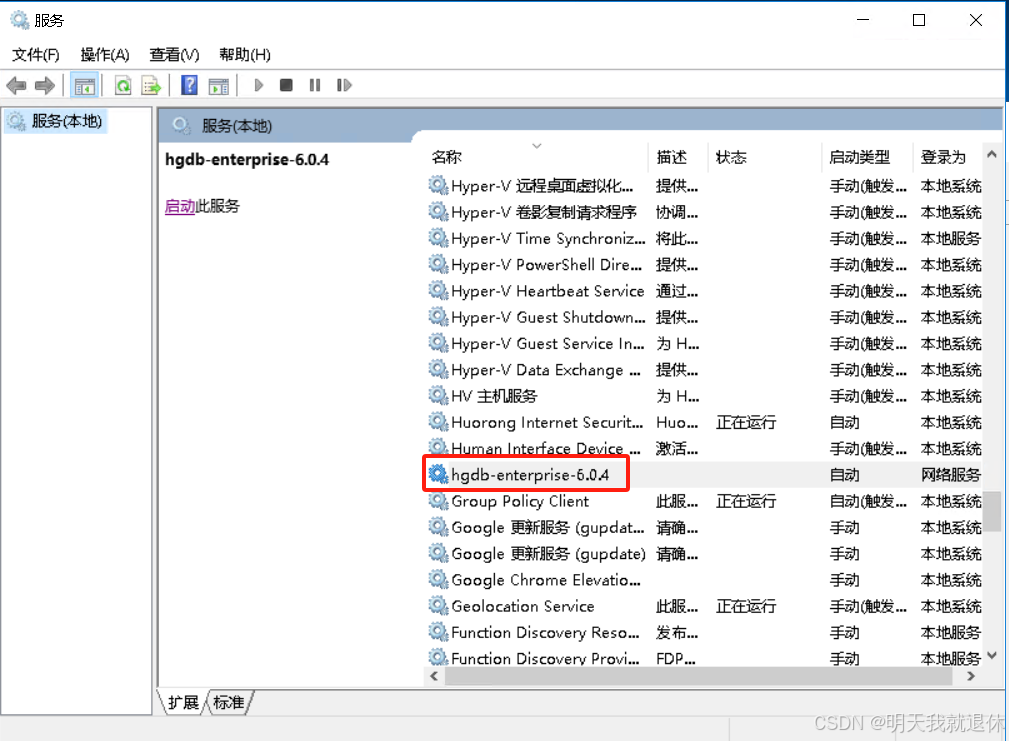
找到highgo-enterprise-6.0.4(鼠标焦点在服务窗口,键盘输入hg可以直接来到这个服务,如果是中文,需要点个回车),点击启动
11、解决问题
大概率会出现以下的问题,由于内存配置过大了

找到
7、修改数据库配置信息配置的数据目录,如果是默认的就是安装目录下的/data目录
找到postgresql.conf文件

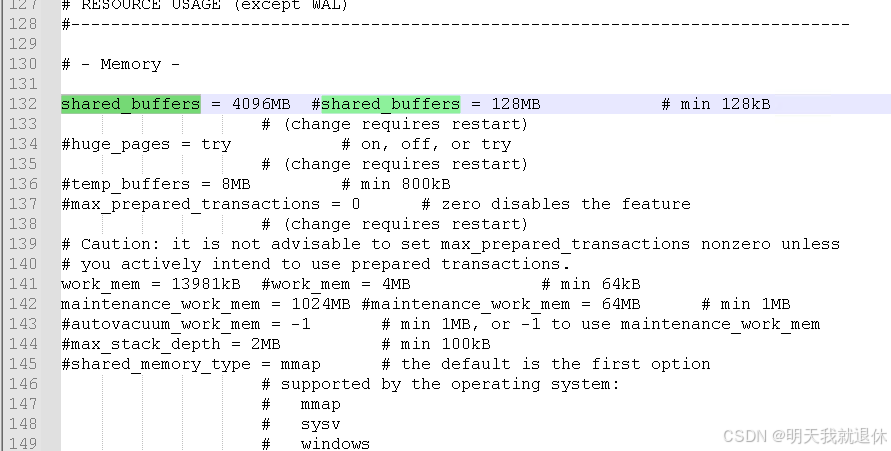
编辑该文件,搜索
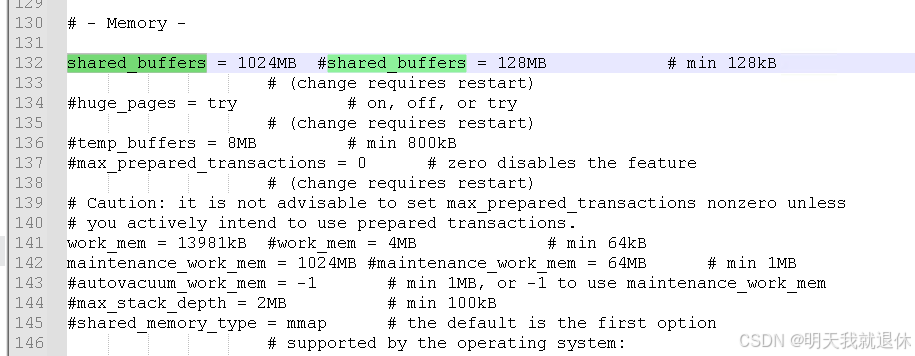
shared_buffers参数(大概是130行左右)
shared_buffers是物理内存的1/4,例如我的这个电脑是16GB的这里就是4GB也就是4096MB
问题就是这里设置的太大了,电脑给不了,设置小一些就可以了,这里修改成1024MB
保存后重启启动服务,发现就可以启动成功了
12、测试连接
双击启动
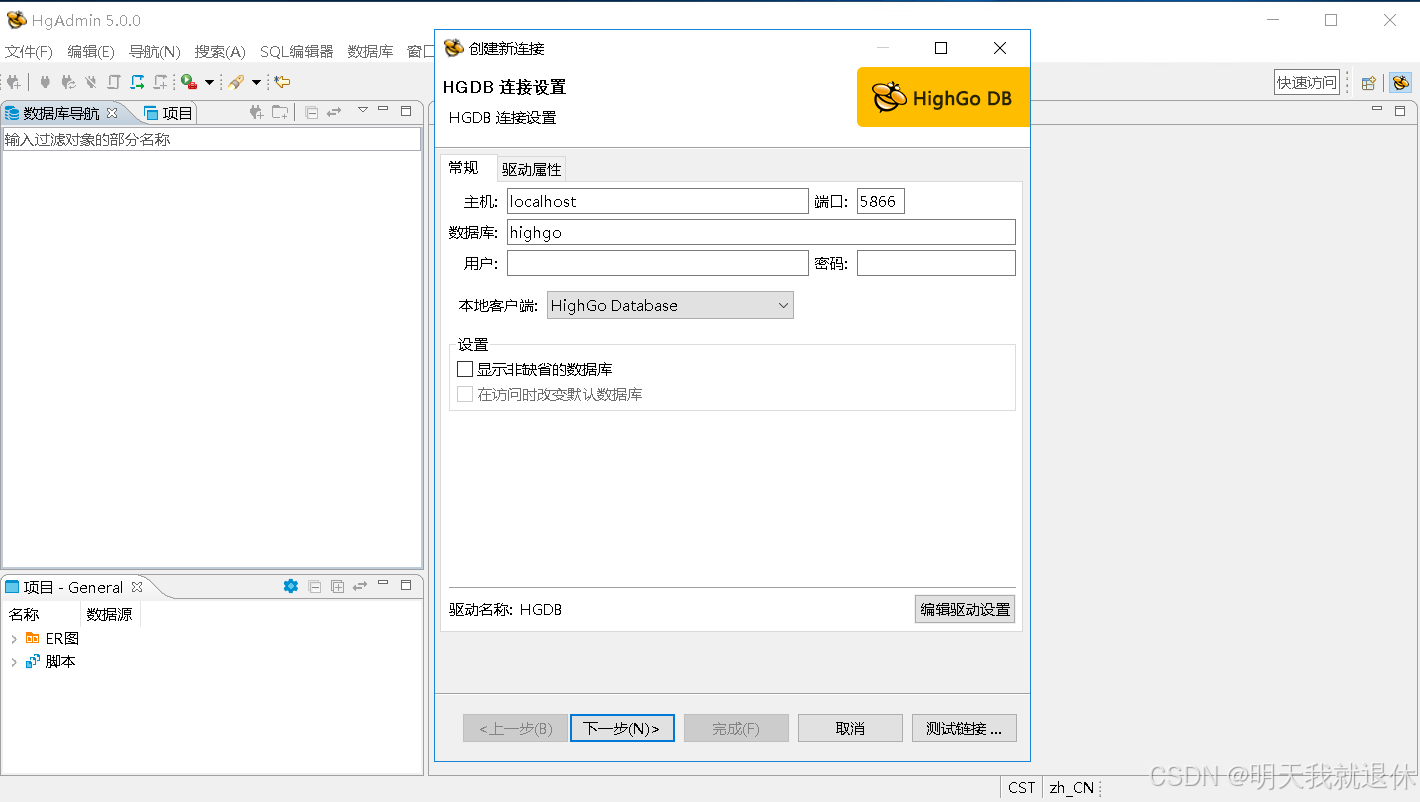
输入7、修改数据库配置信息设置的账号密码,进行登录,数据库默认为highgo就OK了
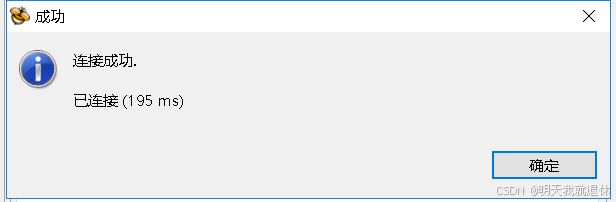
点击测试连接,直接成功
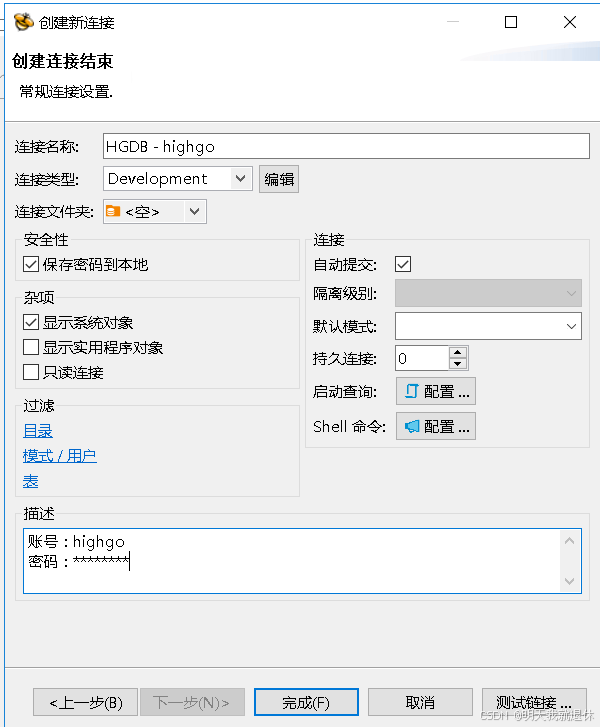
直接一直下一步,最后点击完成就可以了(为了防止忘记密码,我一般都在描述里面写密码)。
13、直接成功
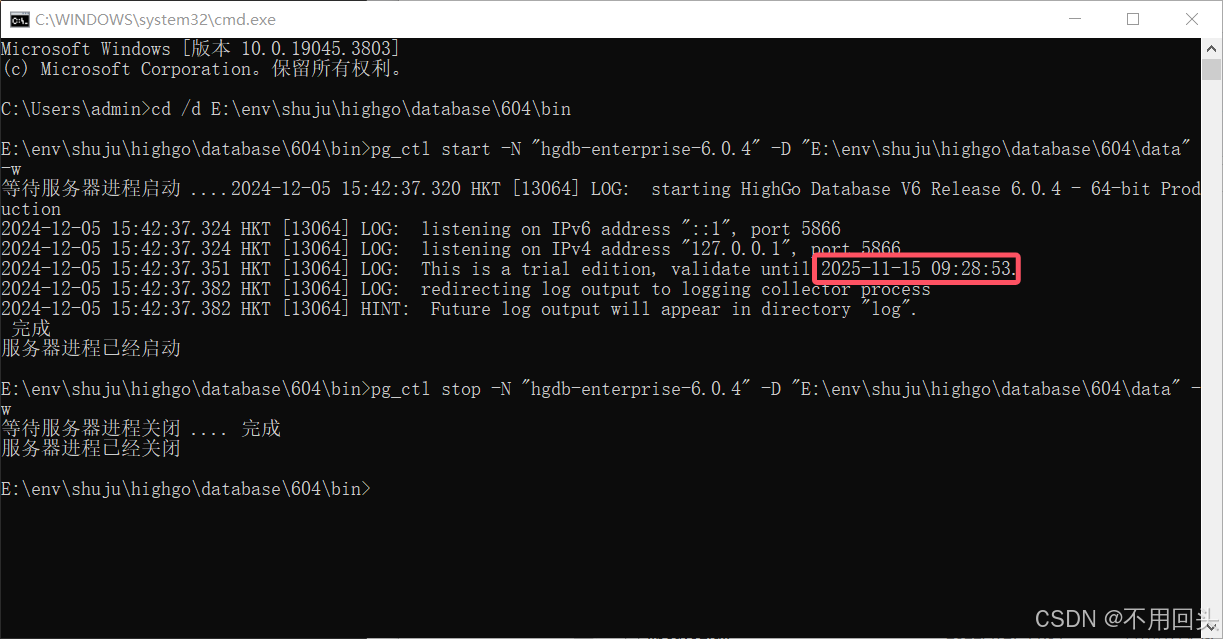
14、查看到期时间
进入安装bin目录(可以直接到该目录使用cmd命令,或者直接使用cmd)
cd /d E:\env\shuju\highgo\database\604\bin
pg_ctl start -N "hgdb-enterprise-6.0.4" -D "E:\env\shuju\highgo\database\604\data" -w
这里 -N 指定服务名称,-D 指定数据目录,-w 表示等待服务器启动完成。(目录根据实际情况来)
下面就是基本信息,显示启动ip端口和到期时间等
三、linux安装
linux目前应该可以安装两种,一种安装数据库管理系统V9.0(根据win安装来看,安装完成自带数据库系统),另一种是安装数据库系统V4.5(需要进行申请适用,前言或者官网都有电话,可以打电话申请更迅速)。
一)、瀚高安全版数据库系统V4.5
1、联系下载
通过联系之后,一般会给你发送一个安装包(含GIS插件),还有好多个使用手册,下面都是解压之后的(目前只用
hgdb-see-4.5.10-a64a611-20240426.x86_64.rpm和hgdb-see-4.5.10-a64a611-20240426.x86_64.rpm.md5)

2、上传
将文件上传到linux(这里使用虚拟机搭建了一个银河麒麟的系统,下面都用linux替代),可以使用
Xftp进行上传,如果没有也可以使用命令进行上传
我一般存放在/opt文件夹下面
查看linux是否安装lrzsz(银河麒麟一般自带)|
rpm -qa lrzsz
没有的话可以进行安装
yum -y install lrzsz
上传文件
rz -y
输入命令就可以进行选择文件上传操作了

验证安装包完整性
md5sum -c hgdb-see-4.5.10-a64a611-20240426.x86_64.rpm.md5
结果如下

3、开始安装
安全版 V4.5.7 以及之前的版本默认安装路径为:/opt/
安全版 V4.5.8 以及后续版本默认安装路径为:/opt/highgo/
(这里安装的是V4.5.10版本)
rpm -ivh hgdb-see-4.5.10-a64a611-20240426.x86_64.rpm
安装过程和安装之后的目录如下
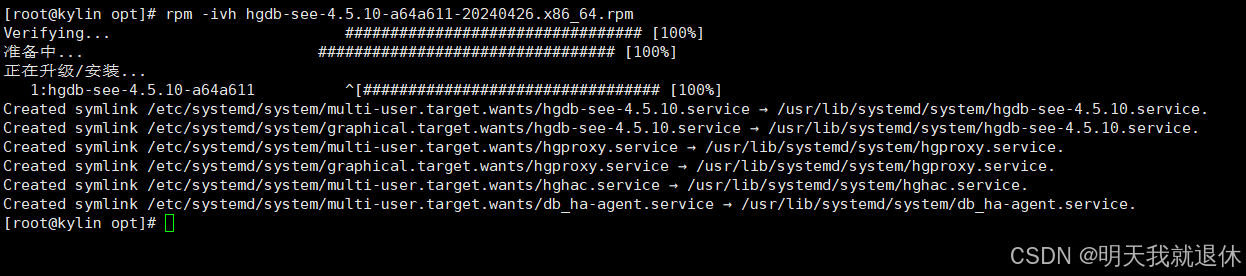

可以使用
rm -rf命令进行删除文件
rm -rf hgdb-see-4.5.10-a64a611-20240426.x86_64.rpm
rm -rf hgdb-see-4.5.10-a64a611-20240426.x86_64.rpm.md5
4、环境变量
安全版 V4.5.7 以及之前的版本,安装完毕后会在/opt/HighGo4.5.2-see/etc 目录下生成一个名为 highgodb.env 的文件,内容如下所示,执行source 命令使之生效。
安全版 V4.5.8 以及后续版本,数据库安装完毕后会在/opt/highgo/hgdb-see4.5.8/etc 目录下生成一个名为 hgdbenv.sample 的环境变量示例文件,您可根据需要修改该示例文件,并使其生效

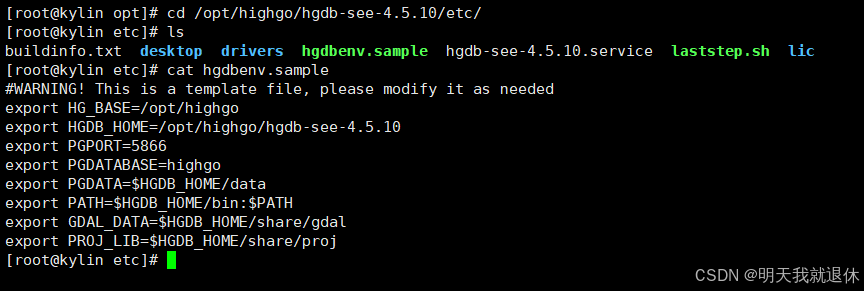
进入highgo下的
etc目录
cd /opt/highgo/hgdb-see-4.5.10/etc
查看文件
cat hgdbenv.sample
让配置文件生效
source hgdbenv.sample
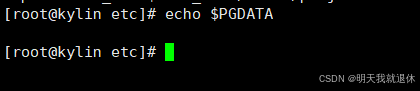
检查是否生效
echo $PGDATA
没有生效之前显示
让其生效之后

5、初始化数据库
手动初始化数据库设置三权用户口令时需要注意:安全版V4.5.8 以及之前的版本, 口令长度要求至少为 8 位。安全版 V4.5.9 以及之后的版本,口令长度要求至少为 10 位。
密码必须由大小写字母符号以及数字组成。
进入highgo下的
bin目录
cd /opt/highgo/hgdb-see-4.5.10/bin
5.1、手动初始化
开始初始化
需要输入sysdba(系统管理员)、syssao(安全保密管理员)和syssso(安全审计员)的密码(先输入密码,在确认一遍密码)
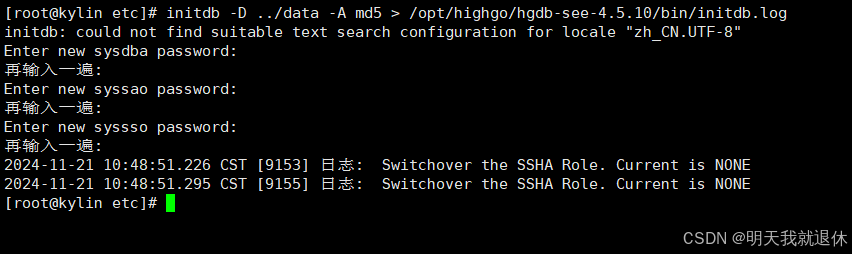
initdb -D ../data -A md5 > /opt/highgo/hgdb-see-4.5.10/bin/initdb.log
5.2、文件初始化
编辑
pwfile文件(这里随便定义名称,只要下面的命令对上)
vi passwdfile
输入i进入编辑模式,分别输入 sysdba、syssao、syssso 三个用户的密码,对应三行记录
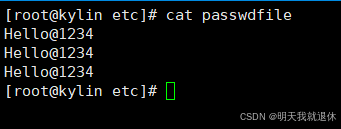
Hello@1234
Hello@1234
Hello@1234
开始初始化(这里
--pwfile=后面的参数就是上面编辑的文件,按照自己的进行填写即可)

initdb -D ../data -A md5 --pwfile=passwdfile > /opt/highgo/hgdb-see-4.5.10/bin/initdb.log
| 命令 | 解释 |
|---|---|
initdb -D ../data | initdb是初始化数据库的命令,-D参数后面跟的是数据库的数据存放目录。这里指定的是../data,表示数据库的数据文件将被存放在上级目录下的data文件夹中。 |
-A md5 | 这个参数指定了认证方法。-A是--authe的简写(例如:--auth md5),用于设置数据库的认证方式。在这里,md5表示使用MD5密码认证机制。这意味着在初始化数据库时,会配置数据库使用MD5算法来存储密码。 |
--pwfile=passwdfile | 这个参数指定了一个文件,该文件中包含了新超级用户的密码。–pwfile 用于从文件中读取数据库超级用户的密码,而不是在命令行中直接输入,这样可以提高安全性。 |
/opt/highgo/hgdb-see-4.5.10/bin/initdb.log | 这个部分是将initdb命令的输出重定向到一个日志文件中。>是重定向操作符,表示将命令的输出保存到指定的文件中。这里的路径/opt/highgo/hgdb-see-4.5.10/bin/initdb.log是日志文件存放的位置,即在/opt/highgo/hgdb-see-4.5.10/bin/目录下创建一个名为initdb.log的文件,用于记录初始化数据库的过程和结果。 |
总结:在上级目录的data文件夹中初始化一个新的瀚高数据库实例,并且将初始化过程中的所有输出保存到/opt/highgo/hgdb-see-4.5.10/bin/initdb.log日志文件中,同时指定使用MD5算法进行密码认证,并从 passwdfile 文件中读取超级用户的密码
| 用户 | 作用 |
|---|---|
| sysdba(系统管理员) | 1、负责安装和升级瀚高安全数据库管理系统。2、配置瀚高安全数据库参数。3、创建数据库对象。4、数据库的备份和恢复(表级)。5、可以创建、删除用户,可以查看用户属性,但没有修改用户安全属性的权限。6、可以创建、删除角色。7、管理表空间。8、没有审计权限和自主访问控制权限。 |
| syssso(安全保密管理员) | 1、负责用户权限设定(包含自主访问权限的分配)。2、安全策略配置管理。3、用户和表的安全标记配置。4、能够对数据库管理系统中所有主体和客体进行标记。5、负责系统日志、普通用户和安全审计员日志的审查分析。6、能配置自主访问控制。7、不能创建用户,但在sysdba创建完用户后,需要安全员给普通用户创建第一次的密码。 |
| syssao(安全审计员) | 1、负责对普通用户、系统管理员、安全审计员和安全保密管理员的操作行为进行审计。2、负责审计策略的设置和审计记录的查询与分析。3、不能创建用户。4、负责对系统管理员和安全保密管理员的日志进行审查分析。 |
6、拷贝 ssl 证书
该过程会将
$HGDB_HOME/etc下的server.crt、server.key文件拷贝到data 目录下并修改文件权限为 600。该命令不支持使用$PGDATA方式指定数据目录。也可手动拷贝这两个文件并修改权限。
进入highog下的
bin目录
cd /opt/highgo/hgdb-see-4.5.10/bin
生成SSL证书相关的文件
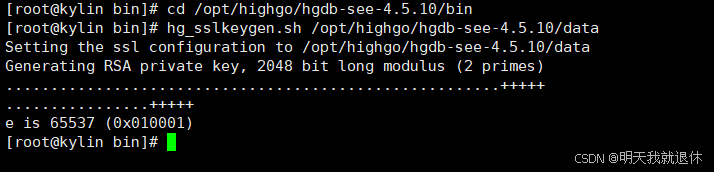
hg_sslkeygen.sh /opt/highgo/hgdb-see-4.5.10/data
7、启动数据库
进入highog下的
data目录
cd /opt/highgo/hgdb-see-4.5.10/data
启动数据库

pg_ctl start
或者使用
systemctl命令启动(一般都会新建相关服务)
systemctl status hgdb-see-4.5.10.service
注意:请勿同时使用 pg_ctl start/stop 和 systemctl start/stop 命令启停数据库,会造成 systemctl 异常。例如:systemctl stop 命令无法关停由pg_ctlstart 命令启动的数据库进程。
| 作用 | 命令 | 图示 |
|---|---|---|
| 查看数据库状态 | systemctl status hgdb-see-4.5.10.service | 如下 |
| 开启数据库 | systemctl start hgdb-see-4.5.10.service | 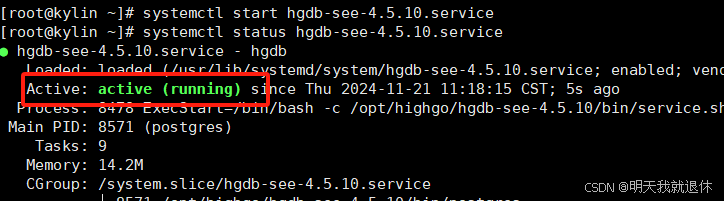 |
| 关闭数据库 | systemctl stop hgdb-see-4.5.10.service | 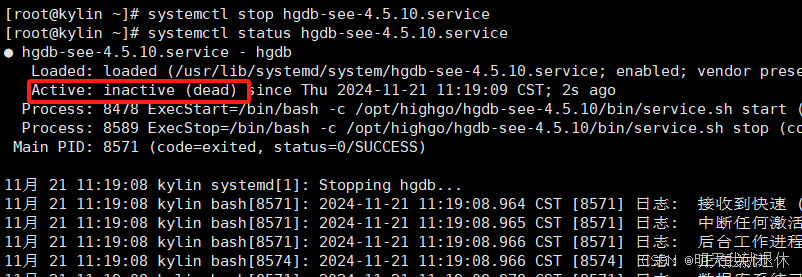 |
登录数据库
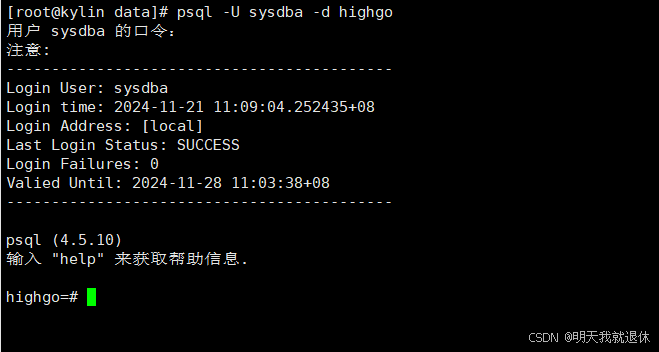
psql -U sysdba -d highgo
有些人可能重启服务器导致使用该命令无法进行再次登录,可以使用以下命令,或者下一步配置环境变量
/opt/highgo/hgdb-see-4.5.10/bin/psql -U sysdba -d highgo
这里登录的是
sysdba用户,输入刚才设置的密码
8、配置环境变量
编辑文件
vi /etc/profile
输入i进入编辑模式,在文件最后面加入下面的语句
然后按esc,在输入:wq!
HGDB_HOME=/opt/highgo/hgdb-see-4.5.10
PATH=$PATH:$HGDB_HOME/bin
export HGDB_HOME PATH
让刚才的配置生效
source /etc/profile
输入命令查看当前的PATH设置,发现highgo被加入了环境。

echo $PATH
然后在输入以下命令可以正常访问数据库了就
psql -U sysdba -d highgo
9、基本设置==>成功
可以跳转到四、外部连接继续进行设置
二)、瀚高数据库管理系统V9.0
1、下载
登录瀚高官网可以直接进行下载:https://www.highgo.com/down_main.html
选择centos7点击下载即可
下载完成之后如下
我给他修改个名字,方便使用(因为下载的是6.0.4版本的,这里就这样修改了一下)
2、上传
将文件上传到linux(这里使用虚拟机搭建了一个银河麒麟的系统,下面都用linux替代),可以使用
Xftp进行上传,如果没有也可以使用命令进行上传
我一般存放在/opt文件夹下面
查看linux是否安装lrzsz(银河麒麟一般自带)|
rpm -qa lrzsz
没有的话可以进行安装
yum -y install lrzsz
上传文件
rz -y
输入命令就可以进行选择文件上传操作了

3、开始安装
直接开始安装
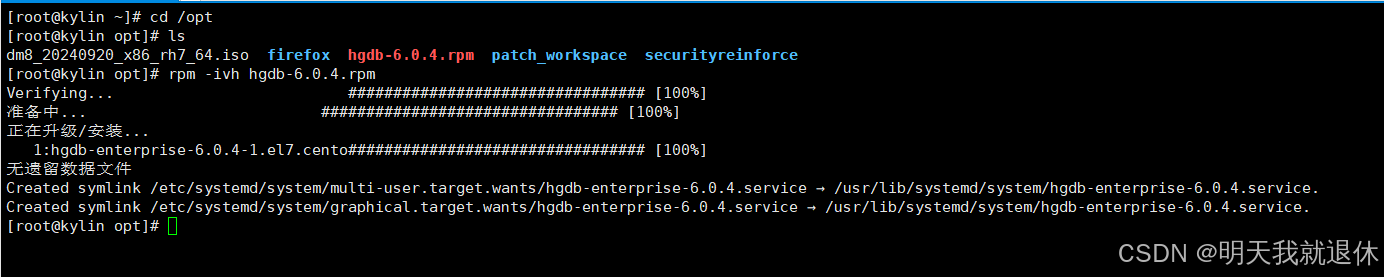
rpm -ivh hgdb-6.0.4.rpm
4、初始化用户密码
上一步安装中,用户组和用户就自动给创建了
这里进行初始化密码
passwd highgo
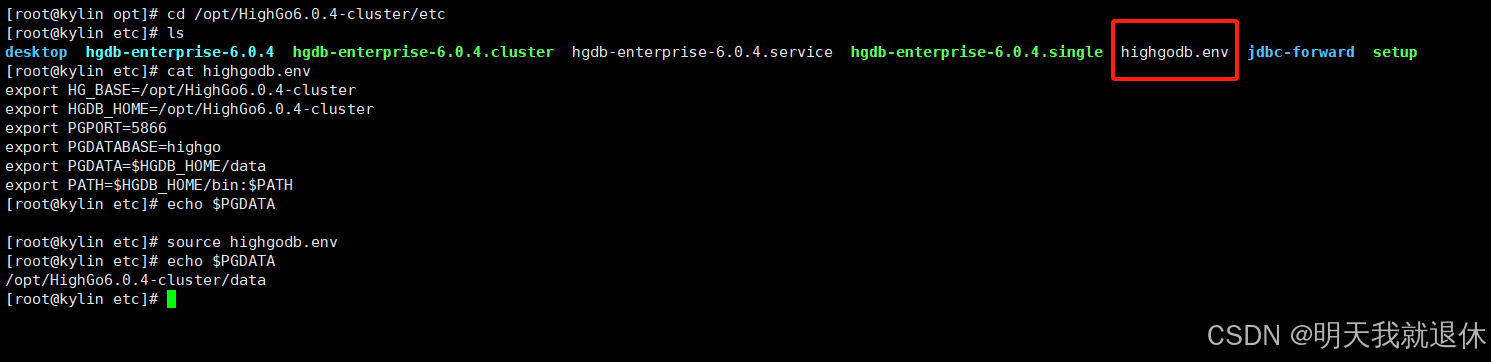
5、环境变量
切换用户
su - highgo
进入highgo下的
etc目录
cd /opt/HighGo6.0.4-cluster/etc
查看文件
cat highgodb.env
让配置文件生效
source highgodb.env
检查是否生效
echo $PGDATA
直接成功
6、初始化数据库
这里需要切换highgo用户进行操作
su - highgo
进入highgo下的
bin目录
cd /opt/HighGo6.0.4-cluster/bin
开始初始化(先输入密码,在确认一遍密码)
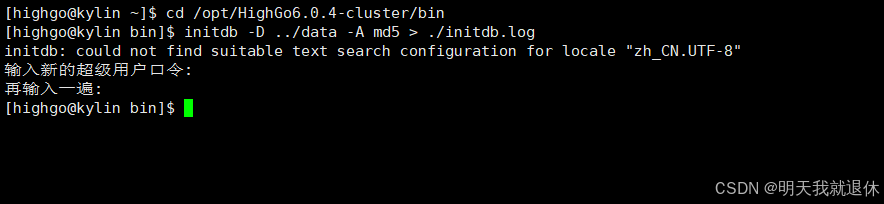
initdb -D ../data -A md5 > ./initdb.log
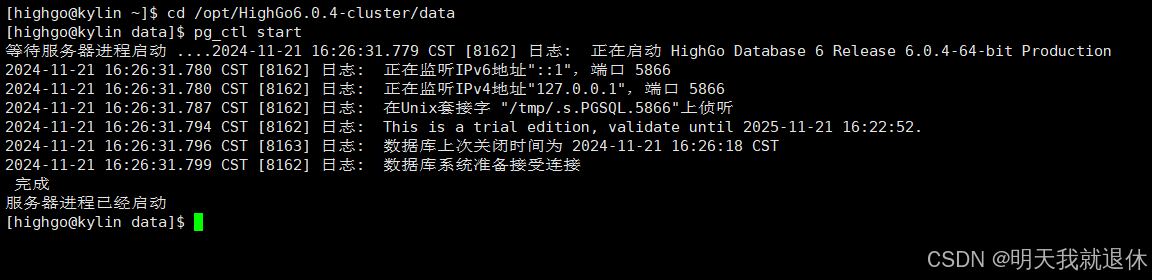
7、启动数据库
进入highog下的
data目录
cd /opt/HighGo6.0.4-cluster/data
启动数据库
pg_ctl start
如图
登录数据库,输入命令后输入账号密码进行登录
psql -U highgo -d highgo
8、配置环境变量
编辑文件
vi /etc/profile
输入i进入编辑模式,在文件最后面加入下面的语句
然后按esc,在输入:wq!
HGDB_HOME=/opt/HighGo6.0.4-cluster
PATH=$PATH:$HGDB_HOME/bin
export HGDB_HOME PATH
让刚才的配置生效
source /etc/profile
9、基本设置==>成功
可以跳转到四、外部连接继续进行设置
四、外部连接数据库
为了避免繁琐,这边Linux和Windows操作就放在一起写了,没有区分的就是都可以进行使用的(Windows又包括Windows server的)
1、修改pg_hba.conf文件
1.1 Linux
1)、进入highgo下的
data目录
(这里根据自己安装的那个进行判断,后续就不多写了)
cd /opt/highgo/hgdb-see-4.5.10/data
或者
cd /opt/HighGo6.0.4-cluster/data
如果配置环境变量可以使用一下代码
cd ${HGDB_HOME}/data
2)、修改
pg_hba.conf文件

vi pg_hba.conf
输入i进入编辑模式,将
127.0.0.1/32修改为0.0.0.0/0或者在最后一行加入以下文本,进行最后执行的覆盖,都可以
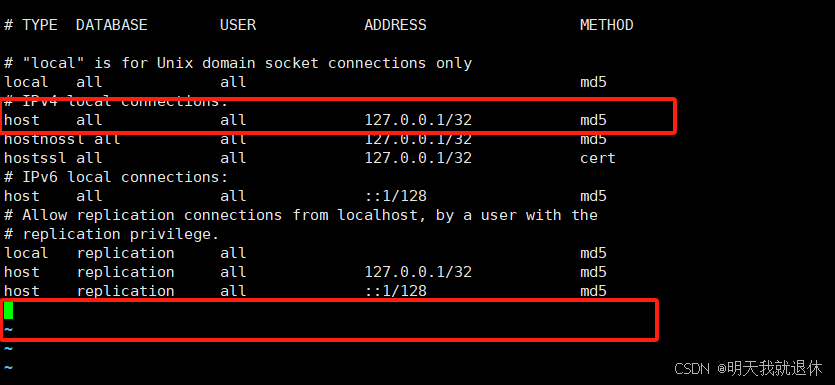
host all all 0.0.0.0/0 md5
1.2 Windows
1)、进入安装目录下的
/data目录,编辑pg_hba.conf文件

2)、打开文件,将# IPv4 local connections:的IP地址修改为
0.0.0.0/0(127.0.0.1/32==>0.0.0.0/0)
如果不想修改,也可以在最下方加入如下代码,读取配置的时候都是使用最下面的设置

host all all 0.0.0.0/0 md5
2、执行SQL语句
注:设置完记得重启数据库才能生效。
*设置sql兼容
-- 这里进行适配的mysql,根据需求进行修改,设置一个即可,默认为none,不进行兼容
alter system set compatible_db =mysql;
-- 这个是适配的oracle
alter system set compatible_db =oracle;
2.1 允许任何连接(设置这里就可以进行访问)
以下一下参数根据个人业务需求进行修改即可
--查询信息,show X;例如,下面就是查询listen_addresses
show listen_addresses ;
--设置*表示允许数据库服务器监听来自任何主机的连接请求
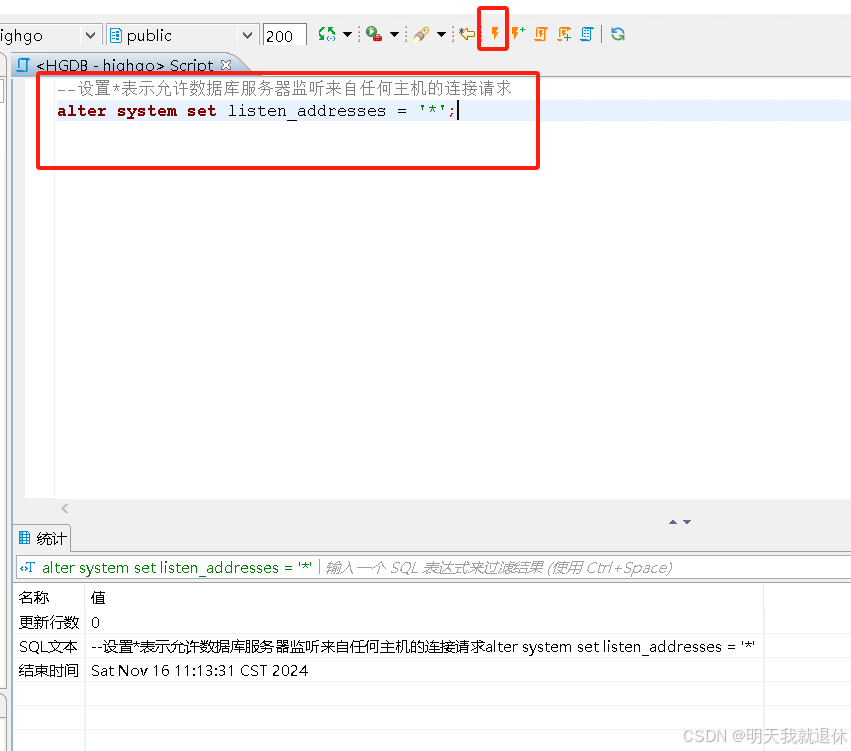
alter system set listen_addresses = '*';
2.2 设置数据库连接内存配置
--修改数据库的最大连接数,一般都是300(可以根据需求进行修改)
alter system set max_connections = 2000;
--修改 shared_buffers,建议设置为物理内存的 25%,最大不超过40%,通用机一般为 32G,设置为 10G(这里我就设置成1024M了)
alter system set shared_buffers = '1024MB';
-- 操作之间的最大时间间隔,(一般默认为5min)
alter system set checkpoint_timeout=1800;
--检查点操作的完成速度,(一般默认为0.9)
alter system set checkpoint_completion_target = 0.8;
| 参数 | 解释 |
|---|---|
| checkpoint_timeout | 参数控制自动检查点操作之间的最大时间间隔。检查点操作是PostgreSQL中用于确保数据完整性和一致性的机制,它会将缓冲区中的脏页刷新到磁盘上。设置为30分钟意味着数据库服务器会至少每30分钟执行一次检查点操作,以确保数据的持久性。 |
| checkpoint_completion_target | 参数控制检查点操作的完成速度。它定义了检查点操作应该在下一个检查点之前完成的百分比。例如,如果设置为0.8,那么数据库会尝试在距离下一个检查点时间的80%之前完成当前检查点的所有写入操作。这个参数用于平衡检查点操作对系统I/O的影响,避免因为检查点操作而导致的I/O高峰,从而影响用户查询的性能。 |
2.3 设置数据库日志信息
--设置 hgdb 生成的日志格式,(默认的一般是stderr)
alter system set log_destination = 'csvlog';
--开启日志,(一般都是开启的,为了万一,在执行操作)
alter system set logging_collector = on;
--修改日志存放路径,(一般默认为log)
alter system set log_directory = 'hgdb_log';
--修改日志文件名称格式,(一般默认为 postgresql-%Y-%m-%d_%H%M%S.log)
alter system set log_filename = 'highgodb_%d.log';
--设置使用单个日志文件的最大时间量(这里设置成每天生成一个新的日志文件,一般默认也是1天)
alter system set log_rotation_age = '1d';
--不限制单个日志文件大小(一般默认为10MB)
alter system set log_rotation_size = 0;
--覆盖同名文件(一般默认为off,避免过多站用存储,这里进行开启)
alter system set log_truncate_on_rotation = on;
--设置记录 ddl 语句
alter system set log_statement = 'ddl';
| 参数 | 解释 |
|---|---|
| stderr | 这种方式的日志格式不是结构化的,通常不适合直接导入到程序中进行分析 |
| csvlog | 日志将以逗号分隔值(CSV)格式输出,这对于将日志导入到程序中非常方便。 |
| shared_buffers | 建议设置为物理内存的 25%,最大不超过40%。(过大就是windows安装启动不起来的原因,在二、11步骤) |
| log_filename | 修改日志文件名称格式,与下方面定义的log_truncate_on_rotation 参数配合使用 |
| log_truncate_on_rotation | 这里开启之后,上方定义的log_filename 文件名最多存在31天的周期,这里可以根据实际需求进行修改操作 |
| 参数 | 解释 |
|---|---|
| log_statement = none | 不记录任何SQL语句。 |
| log_statement = ddl | 仅记录数据定义语言(DDL)语句,如CREATE、ALTER、DROP等。 |
| log_statement = mod | 记录所有修改数据的语句,即DML语句,如INSERT、UPDATE、DELETE等。 |
| log_statement = all | 记录所有SQL语句。 |
这里使用ddl
1、记录DDL语句:当log_statement设置为’ddl’时,数据库将记录所有数据定义语言(DDL)语句,例如CREATE、ALTER和DROP等操作。这些操作通常用于定义或修改数据库结构,如创建或删除表、索引、视图等。
2、不记录DML语句:与’mod’和’all’选项不同,'ddl’不会记录数据操纵语言(DML)语句,如INSERT、UPDATE和DELETE等,这些操作用于修改数据库中的数据。
3、性能影响较小:相比于记录所有DML语句(‘mod’)或所有SQL语句(‘all’),仅记录DDL语句对数据库性能的影响较小,因为DDL语句通常较少,且对性能的影响有限。
2.4 设置归档信息
--开启归档(启用WAL(Write-Ahead Logging)归档模式。WAL归档是PostgreSQL数据库中的一个重要特性,它允许数据库将WAL文件复制到一个安全的位置,以便进行备份和灾难恢复)
alter system set archive_mode = on;
--设置归档存放路径,需提前创建对应目录,(默认位置一般在/data/pg_wal)
--(Linux中)
alter system set archive_command = 'cp %p /opt/highgo/hgdb-see-4.5.10/archive/%f'
--(windows中)
alter system set archive_command = 'copy %p D:\env\highgo\database\604\archive\%f'
| 参数 | 解释 |
|---|---|
| archive_mode = off | 不归档, |
| archive_mode = on | 启用归档,只有在archive_command参数非空时,归档才会实际执行,这是开启归档的常规模式,只在主库上备份归档,备库不会进行归档。 |
| archive_mode = always | 始终归档,从PostgreSQL 9.5版本开始新增的模式,无论主库还是备库都会进行WAL文件的归档。在always模式下,所有节点(包括主库和备库)都会保留完整的历史归档,这意味着即使在备库上,WAL文件也会被归档。 |
2.5 设置连接信息
--设置用户连接与断开数据库的信息
alter system set log_connections=on;
alter system set log_disconnections=on;
alter system set maintenance_work_mem='1GB';
--如果第三方应用不支持 ssl,使用如下命令关闭。关闭后可能会导致无法使用 hgdbadmin 连接,请谨慎操作。
alter system set ssl=off;
| 参数 | 解释 |
|---|---|
| log_connections | 开启记录数据库连接日志的功能。当设置为on时,每当有新的客户端连接到数据库时,系统会在日志中记录这些连接事件。这有助于监控和审计谁以及何时连接到数据库。 |
| log_disconnections | 开启记录数据库断开连接日志的功能。当设置为on时,每当客户端断开与数据库的连接时,系统会在日志中记录这些断开连接的事件。这对于跟踪会话的生命周期和识别可能的连接问题非常有用。 |
| maintenance_work_mem | 设置数据库执行维护任务时可以使用的工作内存量。maintenance_work_mem参数控制诸如VACUUM、CREATE INDEX、ALTER TABLE等维护操作的内存使用。将这个值设置为1GB意味着在执行这些操作时,数据库可以为每个维护任务使用最多1GB的内存。增加这个值可以提高维护操作的性能,特别是在处理大型数据库或复杂查询时。 |
2.6、密码有效期
新建用户的密码有效期为七天,七天之后就需要重新修改密码了(假设这里的用户为root),根据需求进行修改即可
--查询所有用户有效期
select rolname, rolvaliduntil from pg_authid;
--修改有效期(里面的时间自己定义,格式可以是20250101或者2025-01-01或者2025-1-1)
alter user root with valid until '2025-12-31';
--设置密码永不过期
alter user root with valid until 'infinity';
--修改密码
alter user root with password 'xxx';
--删除用户
drop role root;
注:设置完记得重启数据库才能生效。
如果是win安装的,打开
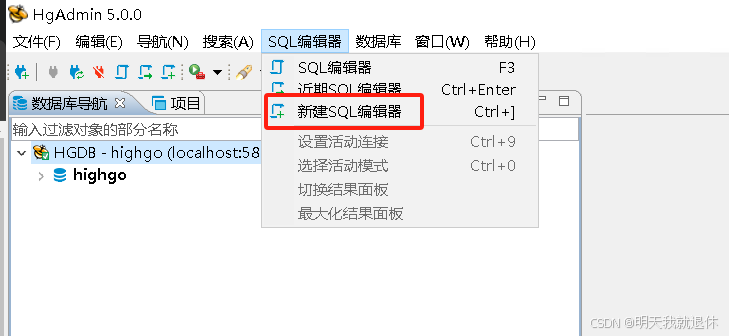
hgdb-enterprise-6.0.4软件
点击SQL编辑器,选择新建SQL编辑器
输入命令点击上方黄色小闪电开始执行(执行SQL快捷键ctrl+enter)
你说怎么看运行成功,只要没有报错提示就代表运行成功了,就是下面的东西
3、重启服务
3.1 Linux
输入命令,需要在文件夹下
cd /opt/highgo/hgdb-see-4.5.10/data
pg_ctl restart
或者使用服务进行重启
systemctl restart hgdb-see-4.5.10.service
3.2 Windows
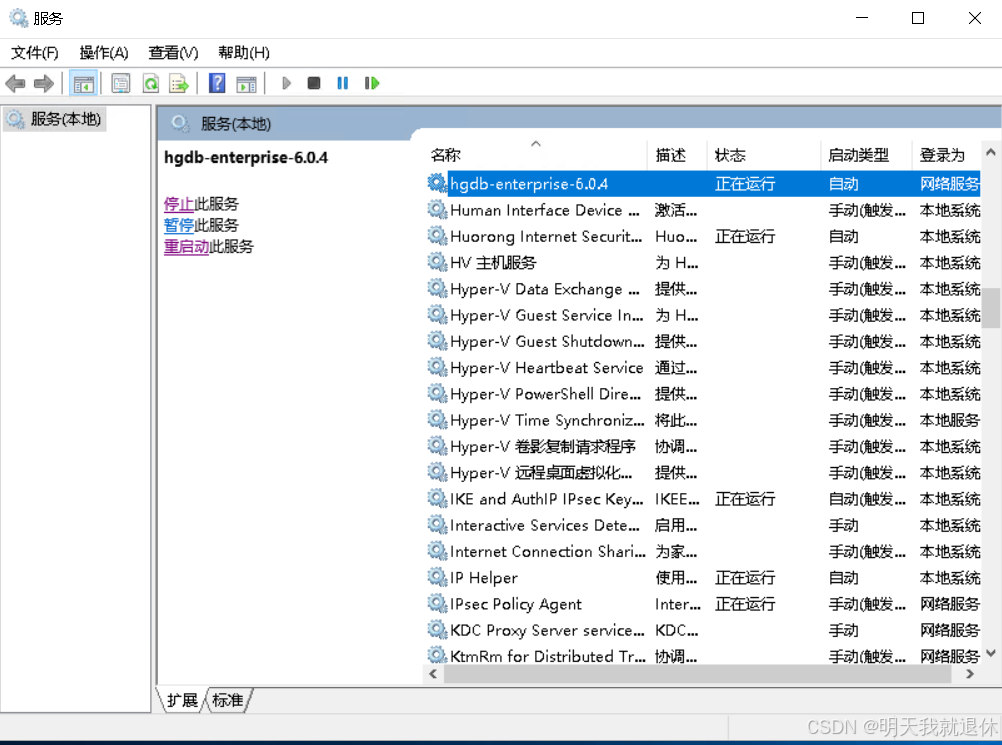
打开服务,找到
hgdb点击重启动等待重启就欧克了。
4、防火墙
4.1、Linux
如果想让外部访问要么关闭防火墙,要么开放端口,这里只演示开放端口(如果需要其他的可以去这篇文章:
银河麒麟系统安装达梦数据库的七、外部访问进行查看)。https://blog.csdn.net/weixin_45853881/article/details/143701478
| 操作 | 命令 |
|---|---|
| 查询端口开放状态 | firewall-cmd --query-port=xxxx/tcp |
| 开放端口 | firewall-cmd --permanent --add-port=xxxx/tcp |
| 移除端口 | firewall-cmd --permanent --remove-port=xxxx/tcp |
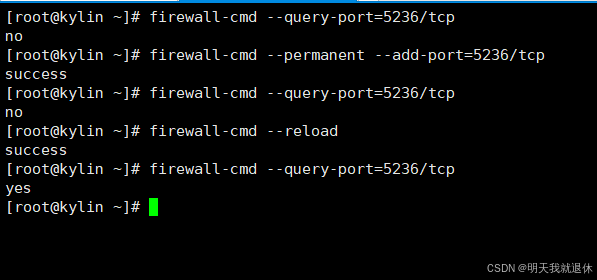
这里进行开放端口(根据自己上方开放的端口进行填写,这里使用的是5236),开放完端口后需要重启防火墙才能生效
firewall-cmd --permanent --add-port=5866/tcp
firewall-cmd --reload
firewall-cmd --query-port=5866/tcp
4.2 Windows
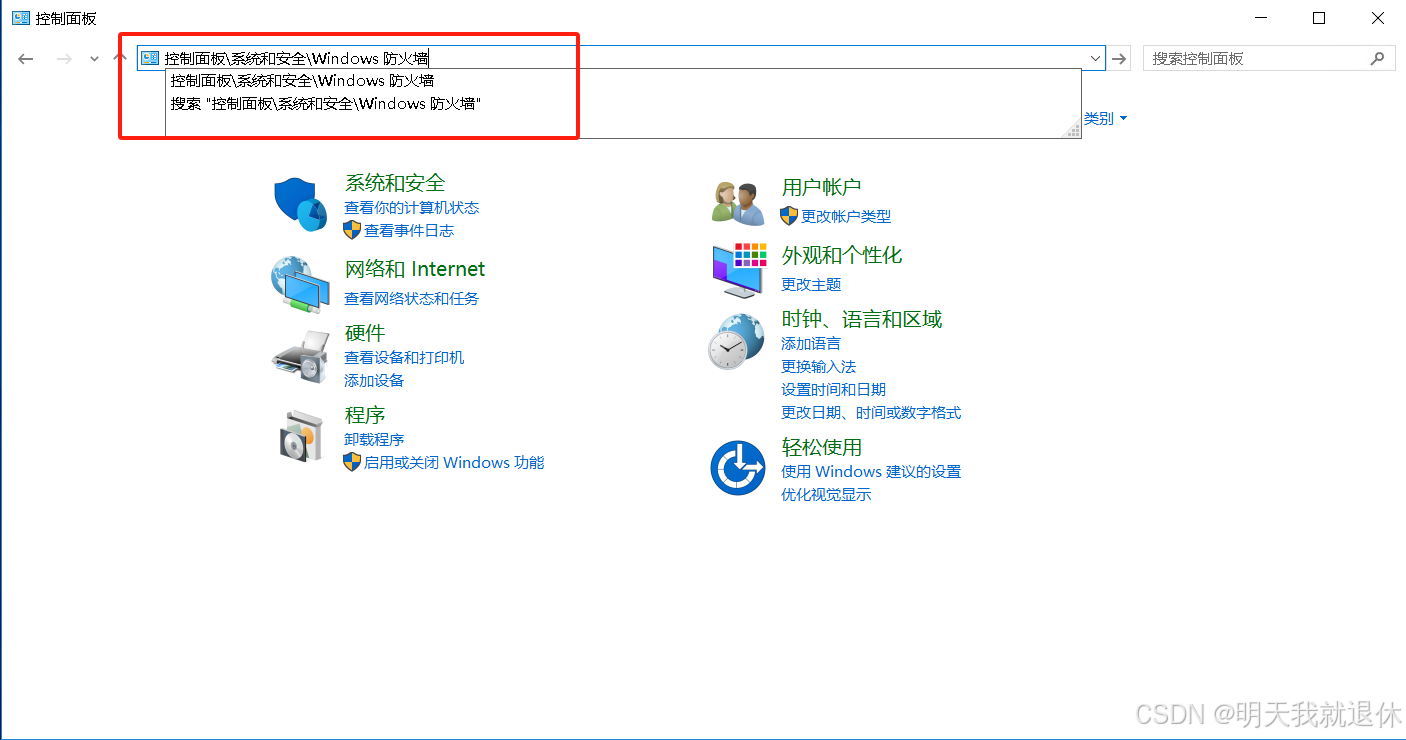
如果是Windows server输入:
控制面板\系统和安全\Windows 防火墙
如果是Windows 输入:控制面板\系统和安全\Windows Defender 防火墙
打开控制面板,直接在这里输入路径回车就到了
1)、开放端口
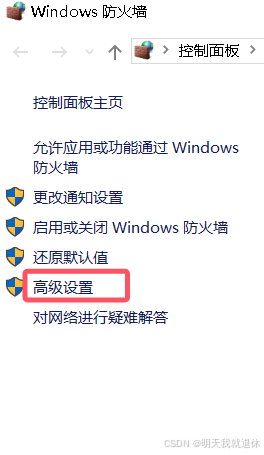
点击高级设置
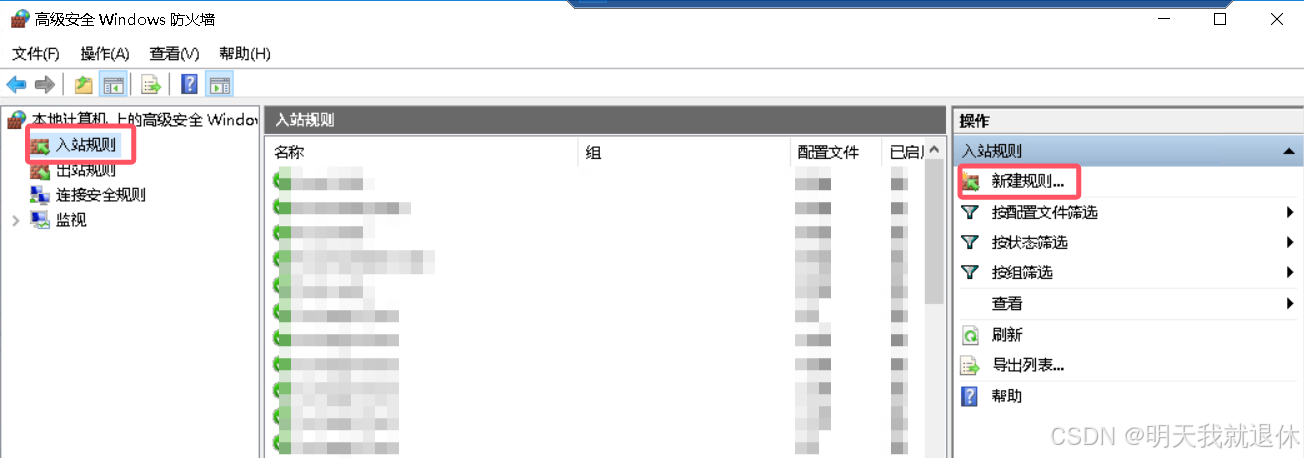
选择入站规则,点击新建规则
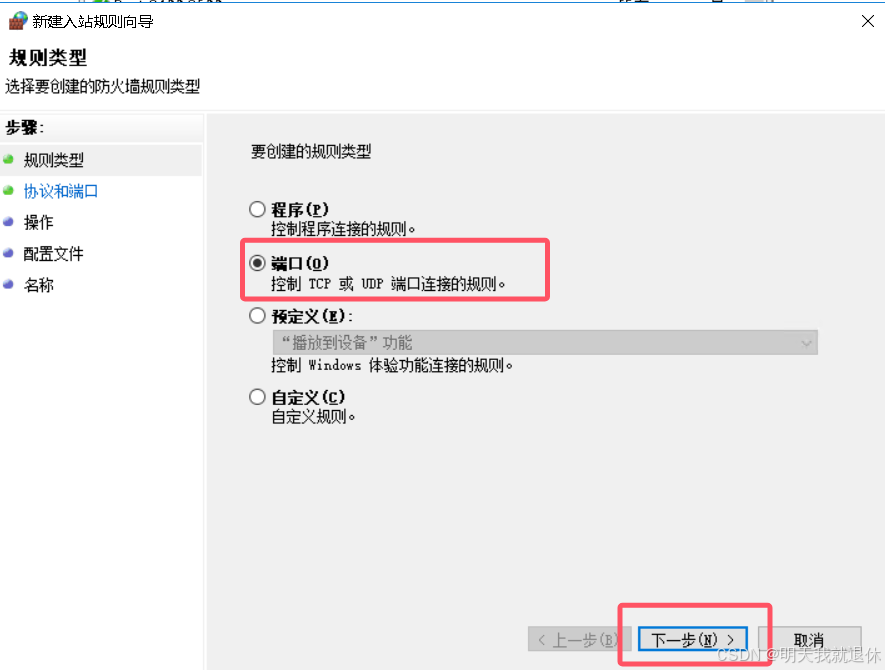
选择端口,下一步
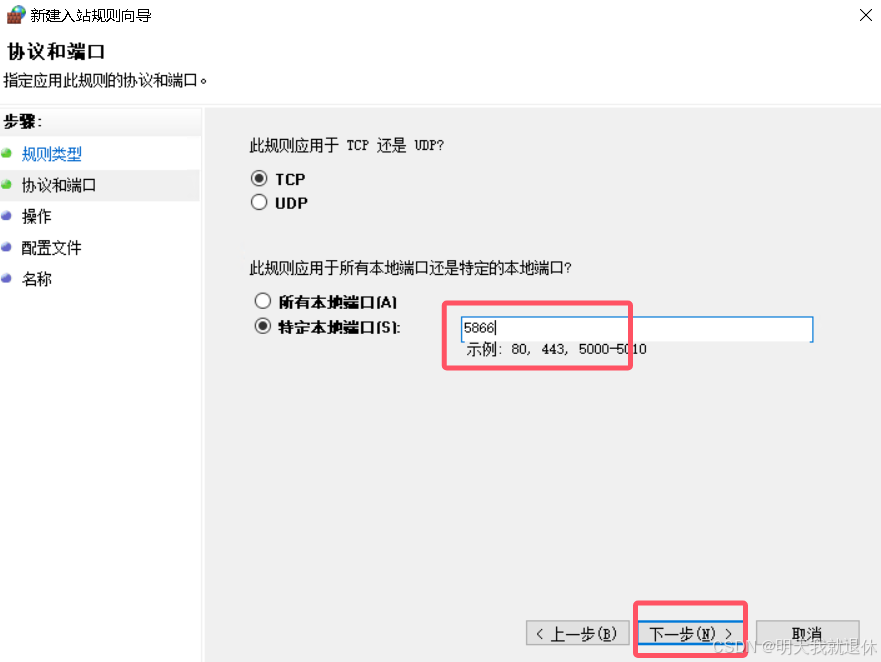
输入瀚高的端口(如果没有进行修改,默认的为5866),下一步
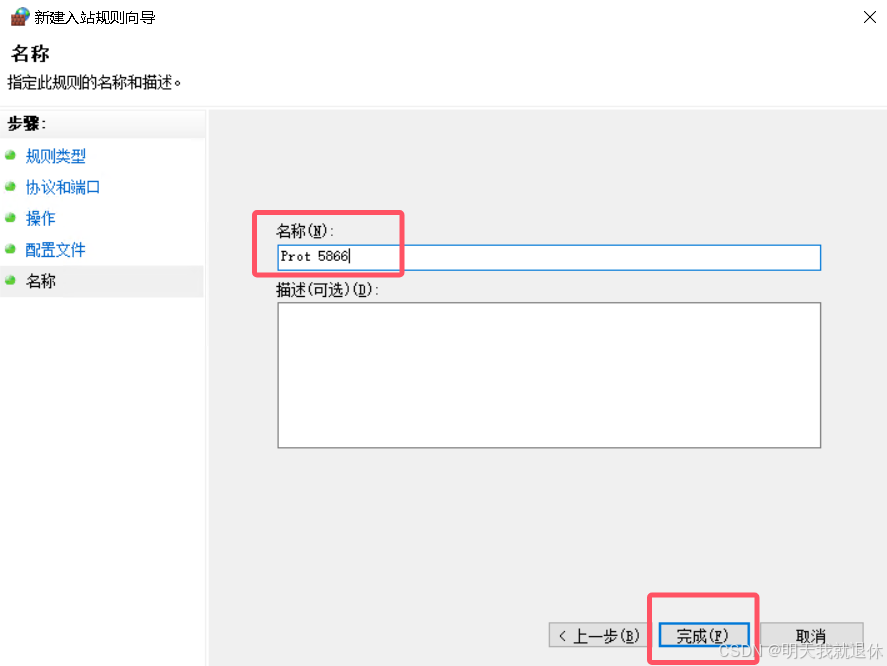
连续下一步,一直到名称这里,输入名称和描述,点击完成
2)、关闭防火墙(内网可以搞一下,一劳永逸,服务器就算了,不太安全)
点击启用或关闭Windows防火墙,将其关闭即可(不推荐)
5、测试连接
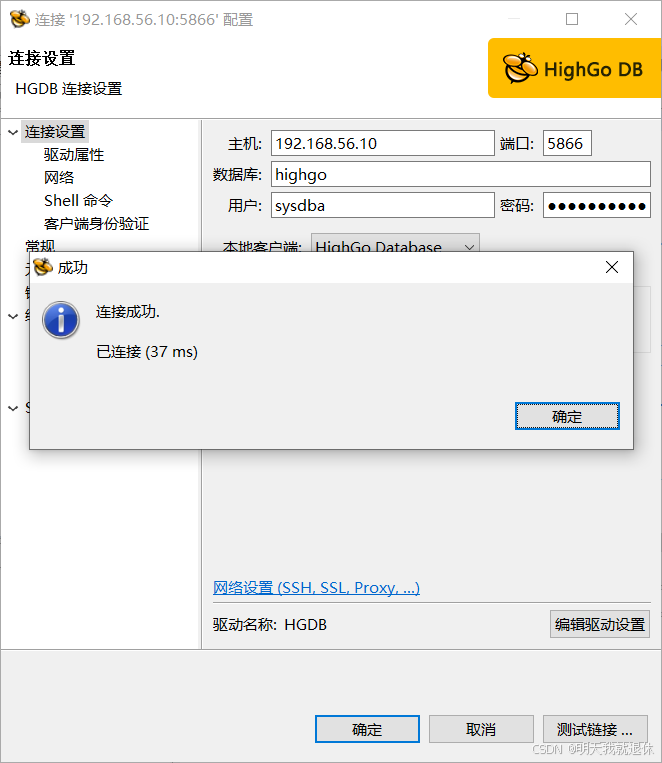
5.1、 Linux
这里远程连接直接成功了也是
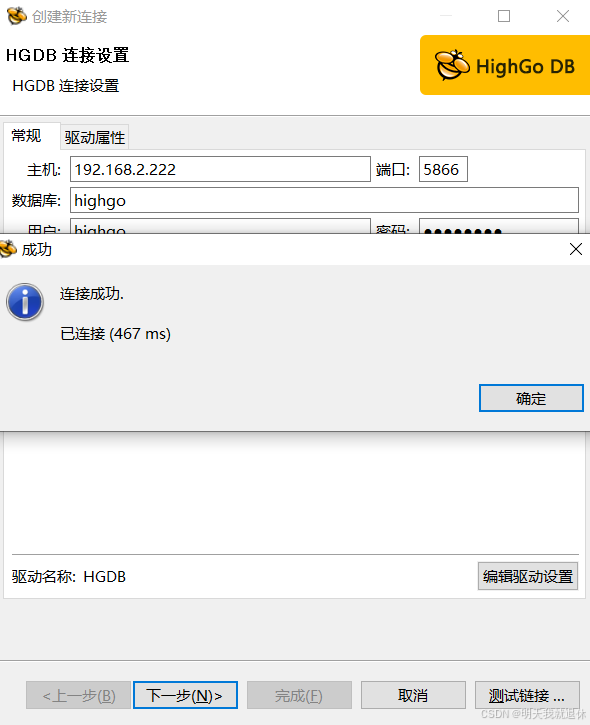
5.2、 Windows
条件有限,这里使用在同一网络下的两个电脑
部署机器:192.168.2.222
连接IP:192.168.2.182
其实自己连接也可以,只要把localhost更换成网络IP就可以了(我这里使用两个电脑更直观一些)


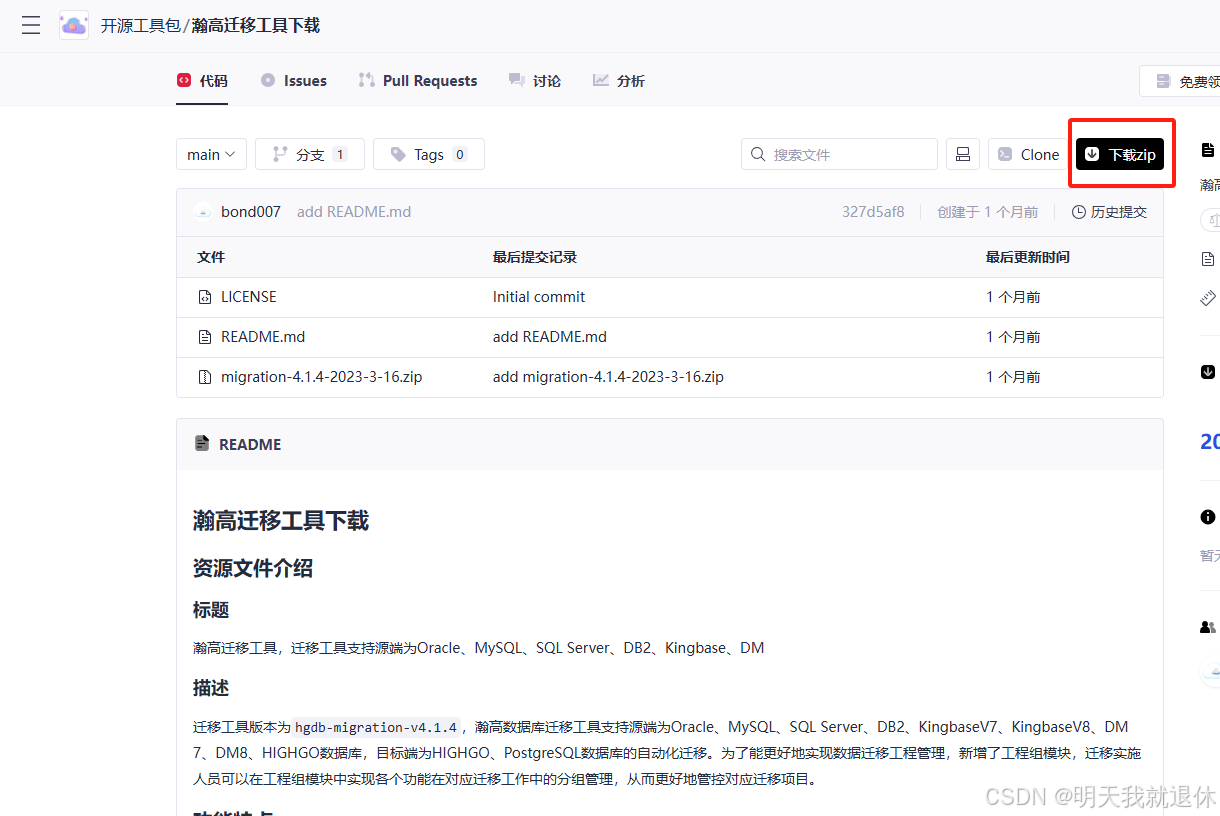
五、数据迁移(瀚高)
1、下载
瀚高迁移工具下载地址:https://gitcode.com/open-source-toolkit/de013/overview
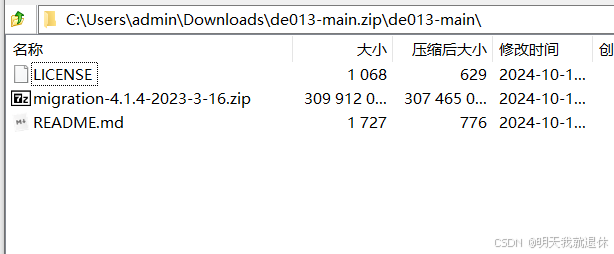
2、解压
下载完成之后包名为
de013-main.zip
双击进行解压
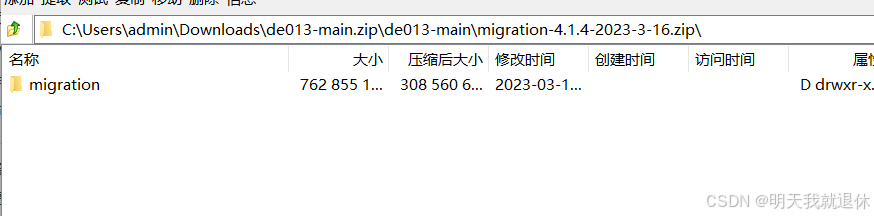
进入de013-main文件内
在进入migration-4.1.4-2023-3-16.zip压缩包内,开始解压
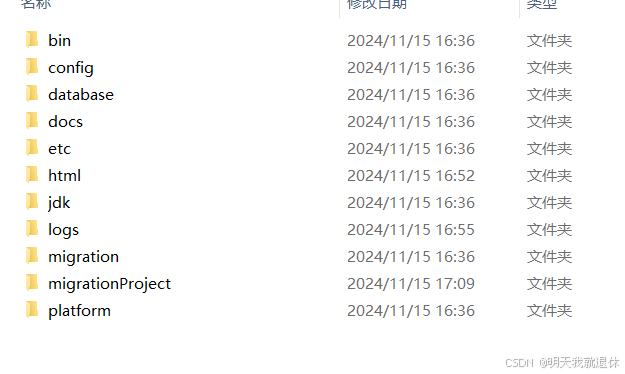
解压后目录文件如下

3、打开软件
进入
bin目录,双击migration.exe和migration64.exe都可以进行打开软件
进入docs目录,可以查看使用手册

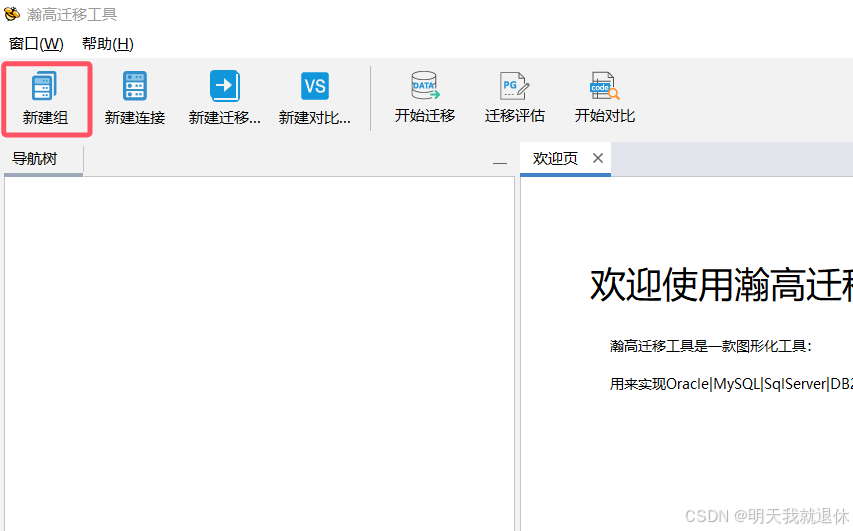
4、新建组
点击新建组
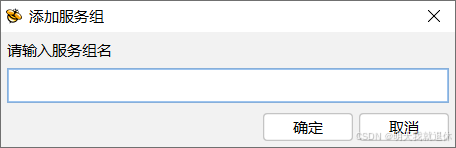
输入组名,点击确定
5、新建连接
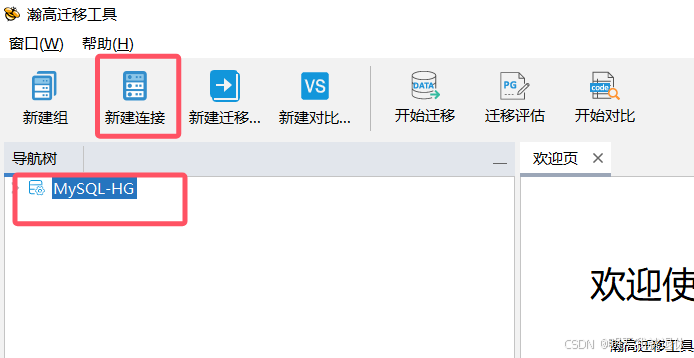
选中刚才新建的组,点击上方的
新建连接,
或者展开,右键数据库连接,选择新建连接
然后就会弹出填写信息的窗口(根据连接的数据库选择相应的类型,还有数据库是需要迁移或者存储的数据库)
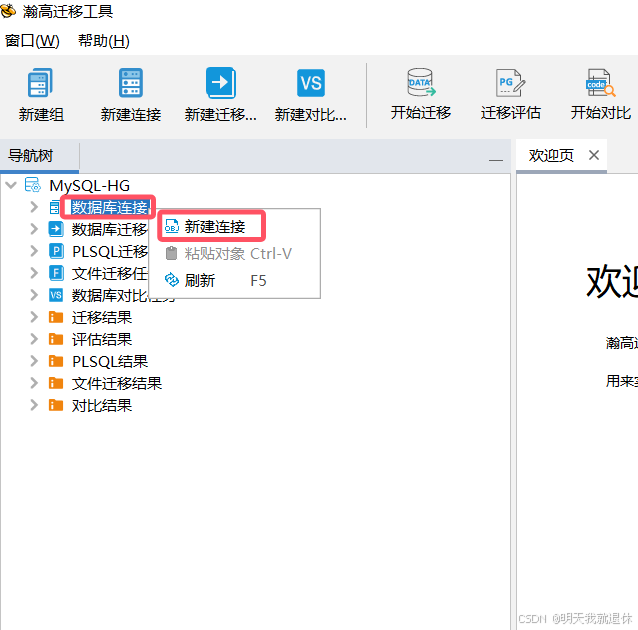
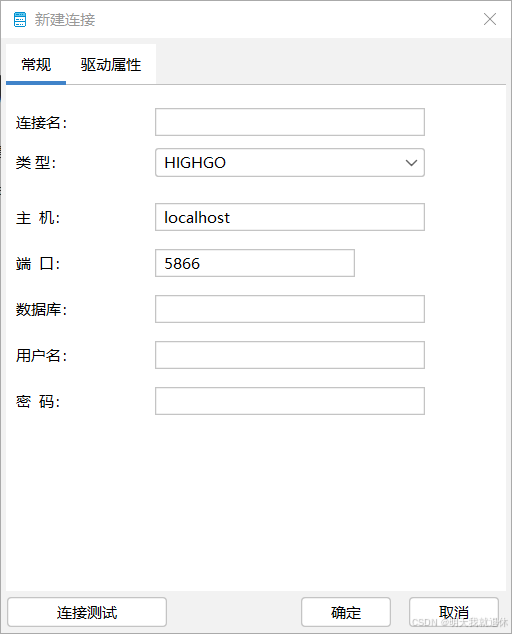
5.1、新建源库数据连接
输入相关信息,点击连接测试,查看是否输入正确,成功之后点击确定(这里我就加入本地的
mysql数据库,这里的类型根据实际进行选择)
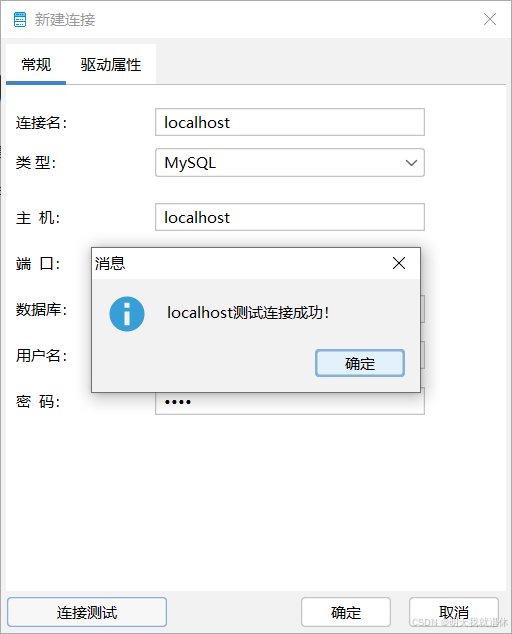
5.2、新建目标库数据连接
重复操作,将另一个数据库加入进去
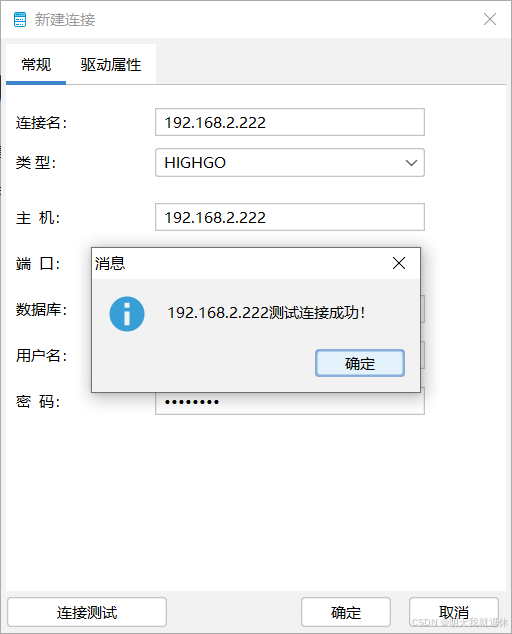
完成之后如下
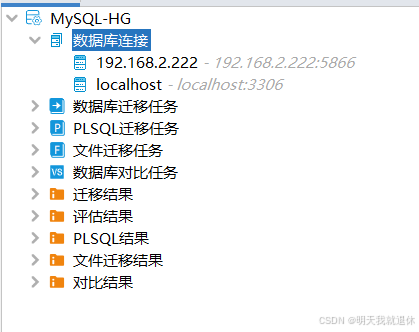
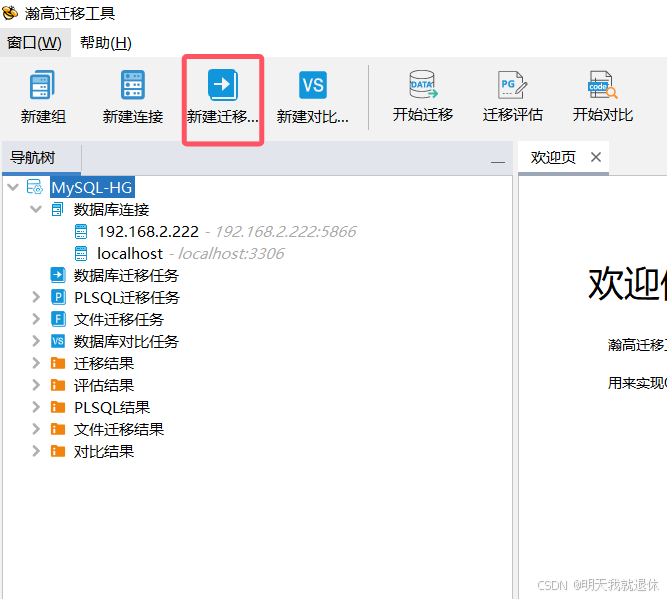
6、新建数据库迁移任务
这个和5新建连接一样子,可以选中点击上方
新建迁移任务也可以右键数据库迁移任务,选择新建迁移任务
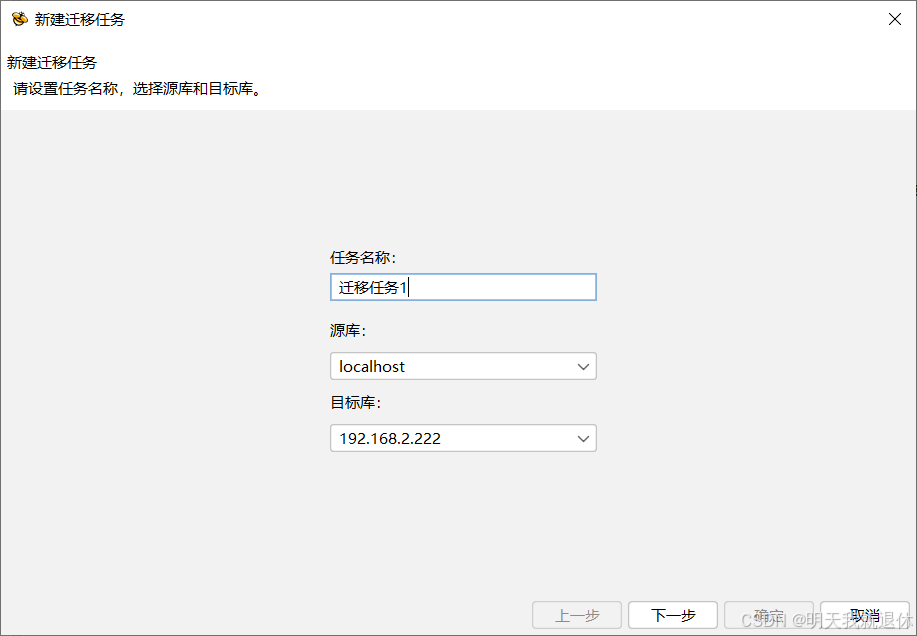
6.1、填写任务信息
根据提示填写相关信息,这里的源库和目标库与
5.1和5.2对应,点击下一步
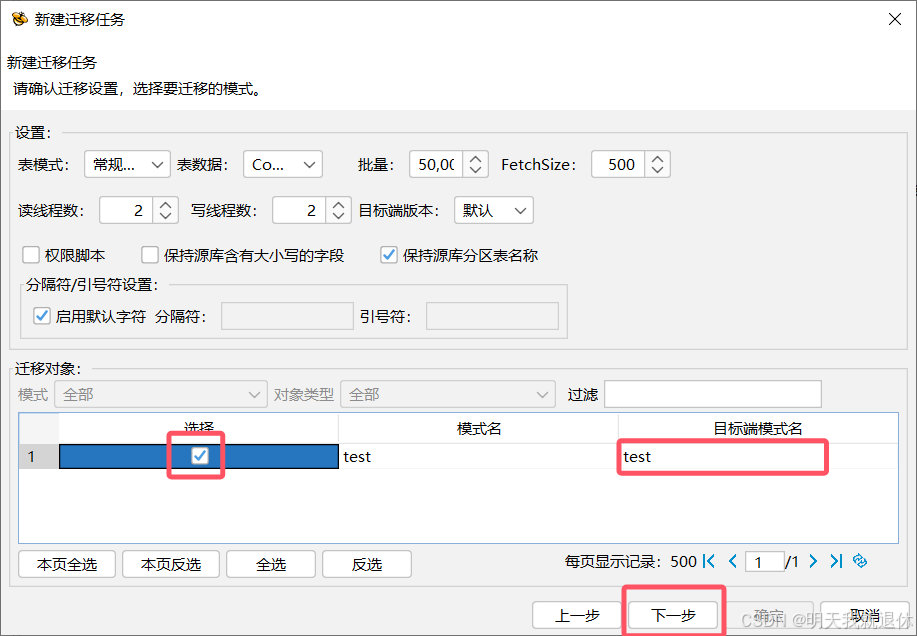
6.2、勾选迁移对象,自定义模式名
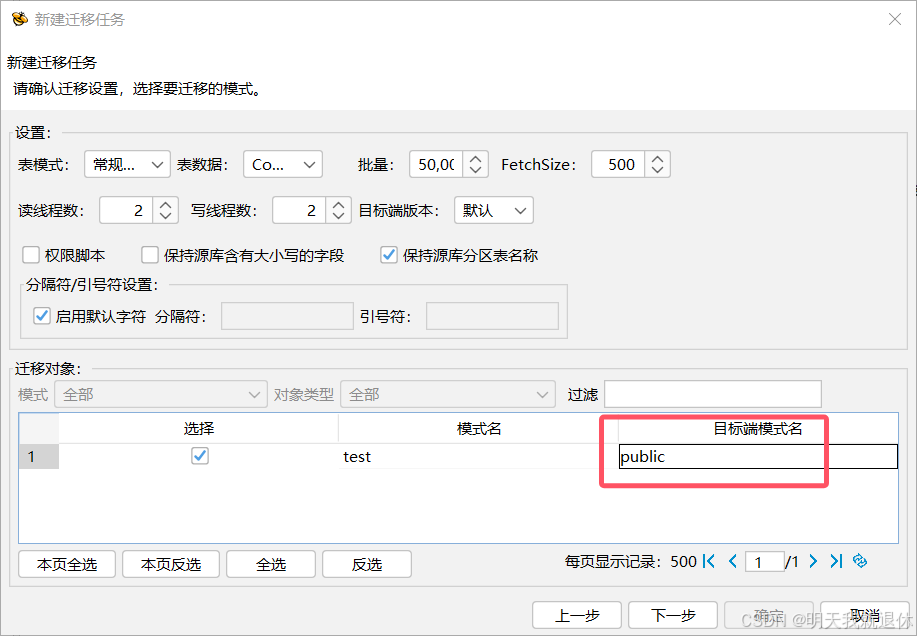
勾选要迁移的对象,注:这里的目标端模式名默认跟源库一样,不过可以进行修改
这里就修改成默认的公共模式public(别输错了,如果没有会自动新建的),然后下一步
6.3、选择迁移表
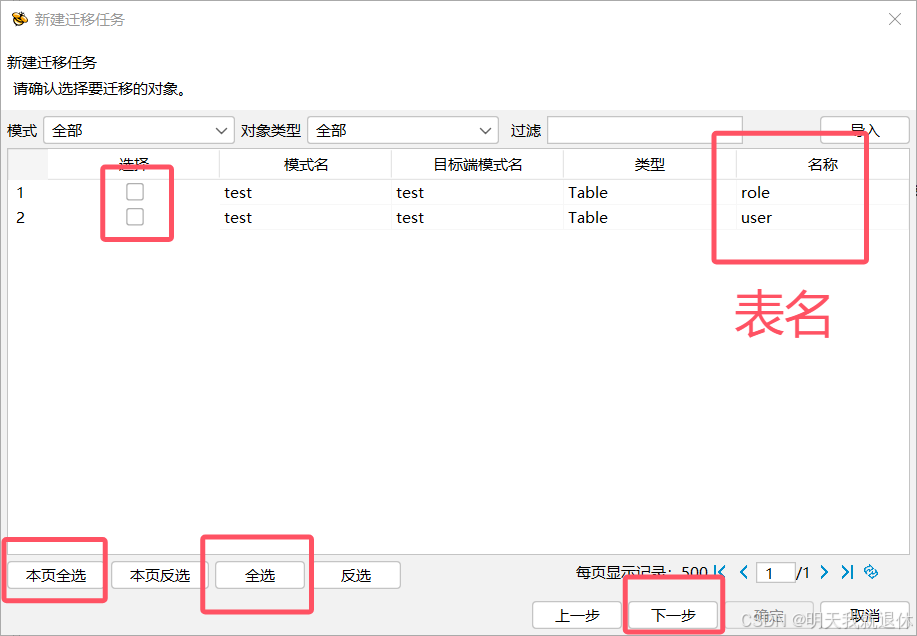
一般都是默认全选,不过有时候只需要迁移部分表,看个人需求
时间关系,和不太聪明,就新建俩表,假设很多,可以点击全选,全部迁移,也可以本页全选,加勾选,部分迁移,然后点击下一步。
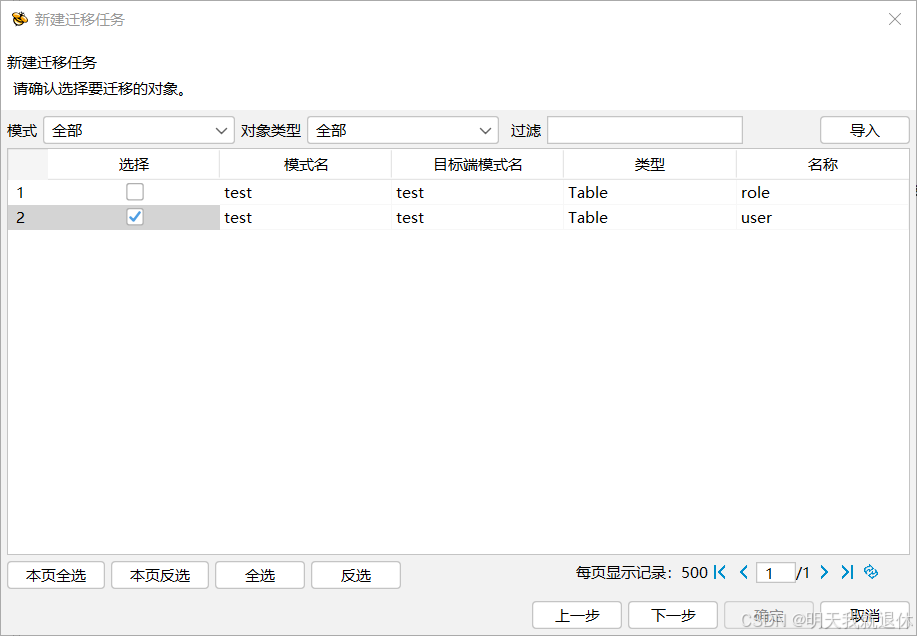
这里我就部分迁移,只迁移user表。
然后点击确定,任务就新建完成了
7、开始迁移
7.1、迁移前信息
迁移之前先查看表
| 源库 | 目标库 |
|---|---|
 |  |
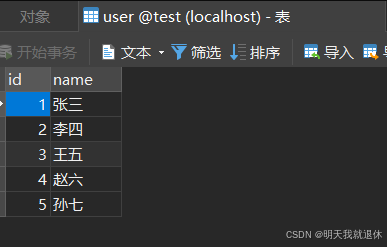 | 无 |
7.2开始迁移
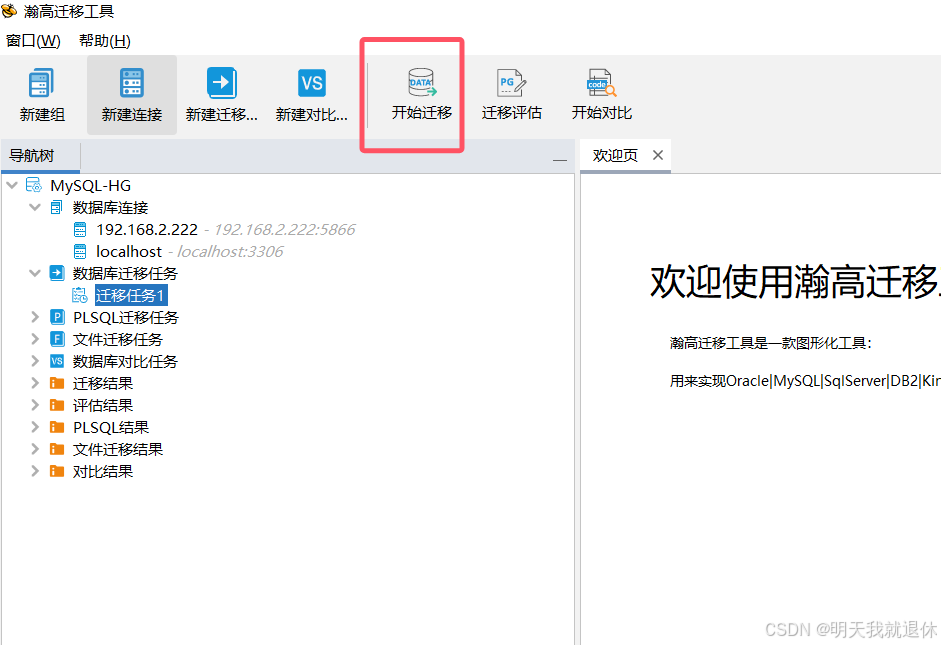
选中新建的
迁移任务1,点击开始迁移
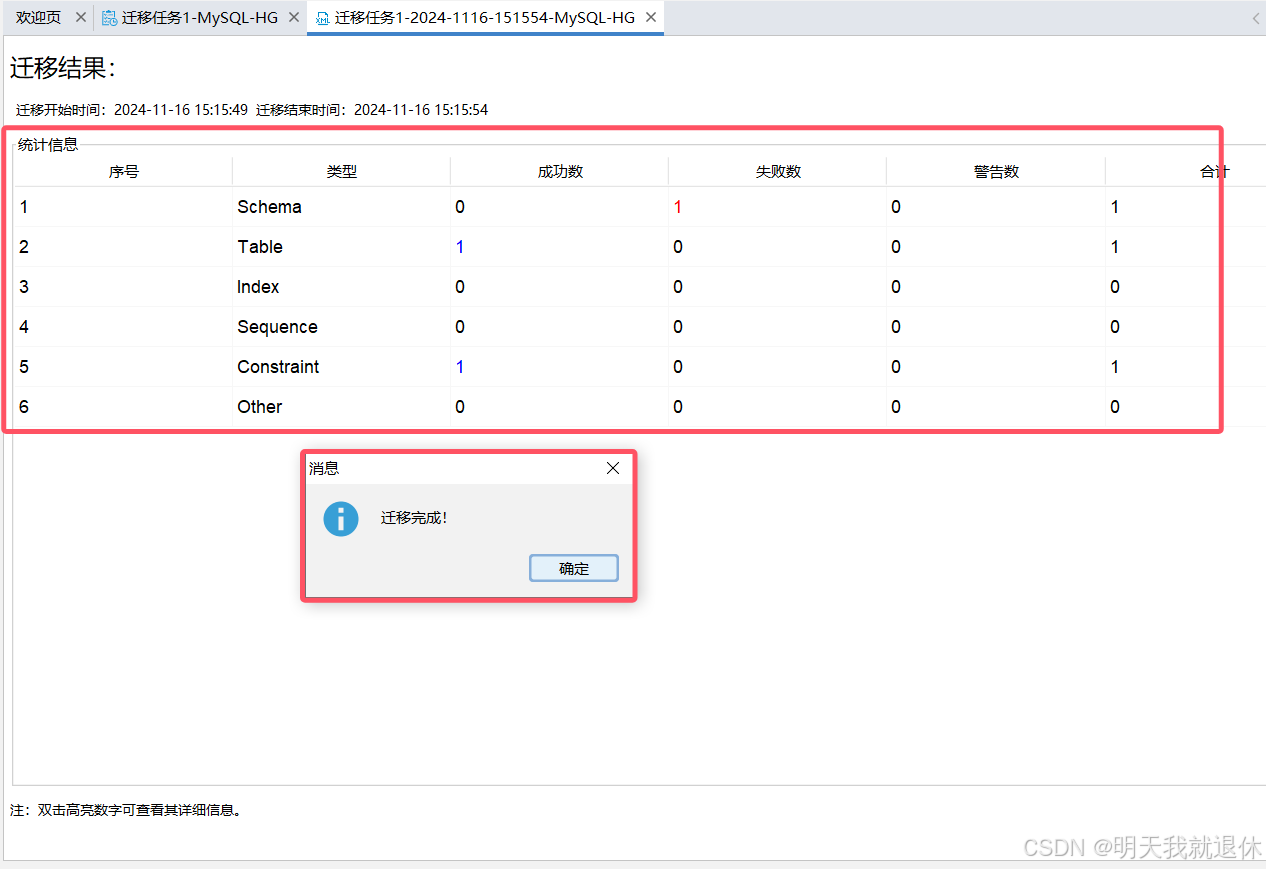
7.3迁移后信息
直接可以看到成功了
| 源库 | 目标库 |
|---|---|
| 不变 |  |
| 不变 | 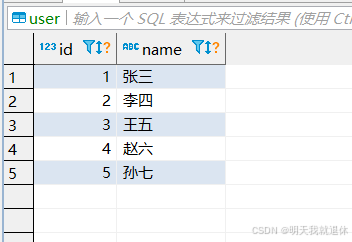 |
六、MySQL和瀚高注意
写的太多,看不过来,进行跳转网址单独显示
MySQL更换瀚高语法更换:https://blog.csdn.net/weixin_45853881/article/details/143885486


















 1179
1179

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









