







 本文详细描述了replicashard重启时的恢复流程,包括重播translog、判断使用retentionlease还是translog回放数据,以及处理一致性问题的方法。涉及到了primaryshardnode、softdelete、版本校验等关键概念。
本文详细描述了replicashard重启时的恢复流程,包括重播translog、判断使用retentionlease还是translog回放数据,以及处理一致性问题的方法。涉及到了primaryshardnode、softdelete、版本校验等关键概念。
replica shard重启具体流程
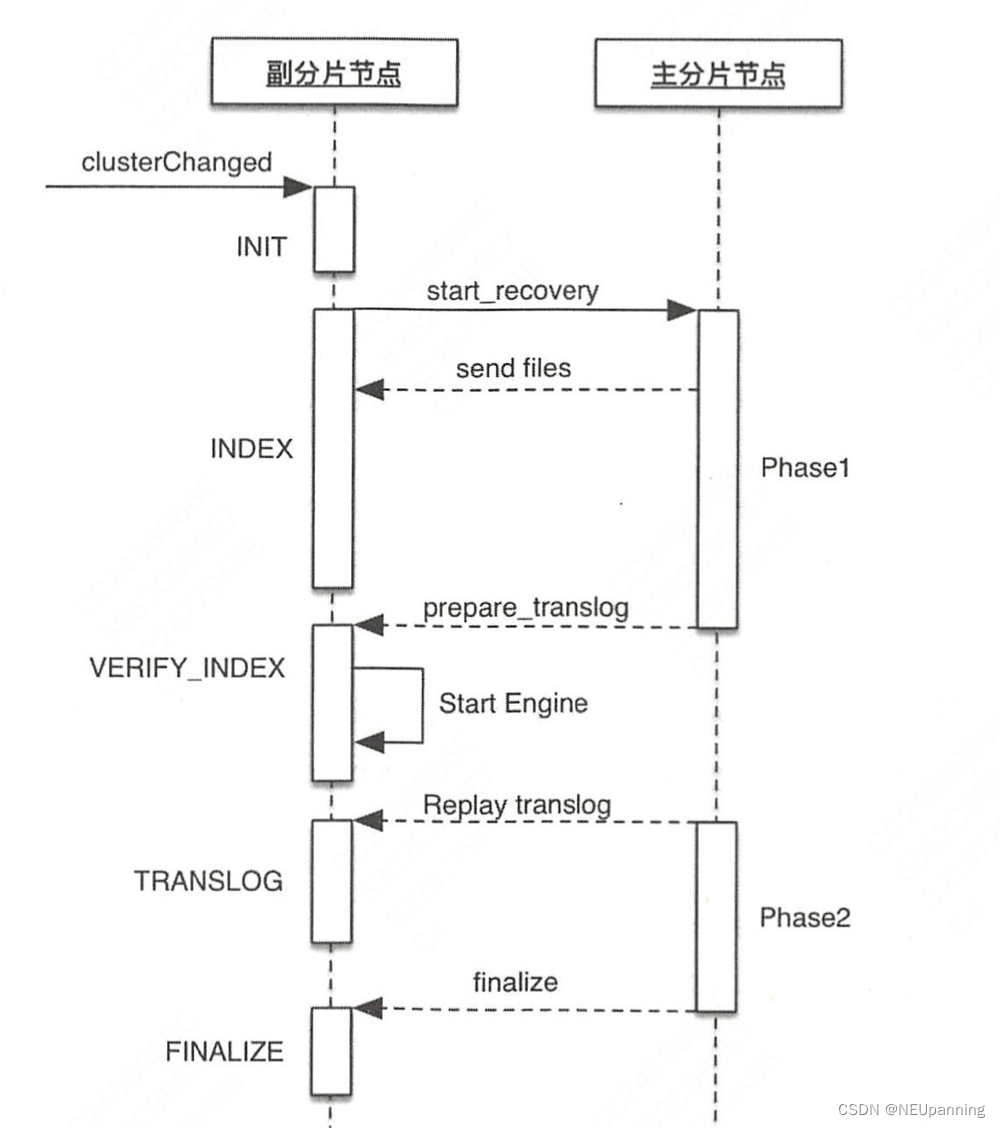
replica shard node (generic threadpool)
- 也是因为应用新的集群状态触发recovery,进入index阶段
- 进入translog 阶段。先尝试重放本地的translog到global checkpoint
- 向primary shard发起start recovery的请求,请求包含replica的localCheckpoint+1。(如果第二步重放translog了,localCheckpoint自然也会增加)
primary shard node
- 如果开启了soft delete并且索引是7.4版本之后创建的(retention lease功能),则使用lucene index作为HistorySource,否则使用translog
- 判断是否可以根据seq no按条恢复数据而不是发送segment file,即跳过phase 1,判断需要满足以下条件(其实就是看能不能使用retention lease/translog回放)
- replica不是没有数据
- primary shard的retention lease或者translog(取决于history source)包含所有要recovery的数据&#
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1196
1196

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









