







 Gluten项目通过整合ApacheSpark与多种Native后端(如Velox、Clickhouse等),加速计算并支持数据格式转换,提供数据传输和内存管理优化。其FallbackProcessing机制确保兼容性,而glutenshuffle专注于列式数据shuffle。对于调试,支持跨Spark和Native库的排查。
Gluten项目通过整合ApacheSpark与多种Native后端(如Velox、Clickhouse等),加速计算并支持数据格式转换,提供数据传输和内存管理优化。其FallbackProcessing机制确保兼容性,而glutenshuffle专注于列式数据shuffle。对于调试,支持跨Spark和Native库的排查。
Gluten 项目主要用于“粘合” Apache Spark 和作为 Backend 的 Native Vectorized Engine。Backend 的选项有很多,目前在 Gluten 项目中已经明确开始支持的有 Velox、Clickhouse 和 Apache Arrow。通过使用Native backend 执行计算,加速 Spark 执行速度,目前在TPCH 测试中使用 velox backend 得到了最多3.6倍加速。下图为 Gluten 整体架构

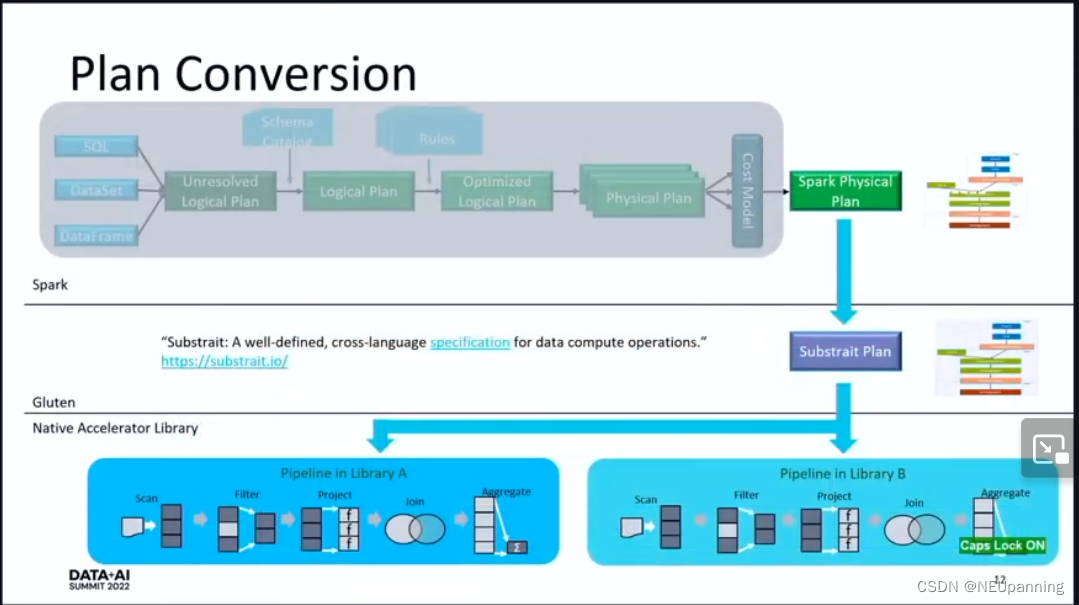
plan conversion
spark physical plan 作为输入,使用 substrait 将其转换为 substrait plan,substrait plan作为一个统一的执行计划传递给不同的 native library,在不同的 library 中执行相同的的 pipeline,使用 library自己的算子执行 pipeline
buffer passing & sharing
gluten 提供两种方法来进行 spark JVM 和 native engine 之间的数据传输,如下图所示
- 下图中的绿线。使用 apache arrow 作为内存数据格式,将 velox 中的 velox 格式数据转换为 arrow 格式,使用 arrowColumnarVec
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 6462
6462

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









