






 本文介绍了XML作为数据传输和存储的工具,RDF的资源描述框架以及OWL的Web本体语言,强调它们在描述Web信息和增强计算机理解方面的作用。同时,展示了如何使用Python的rdflib库处理RDF和OWL数据,将查询结果转化为CSV文件。
本文介绍了XML作为数据传输和存储的工具,RDF的资源描述框架以及OWL的Web本体语言,强调它们在描述Web信息和增强计算机理解方面的作用。同时,展示了如何使用Python的rdflib库处理RDF和OWL数据,将查询结果转化为CSV文件。
1、知识预热(这些内容参考了菜鸟教程,可以直接去菜鸟官网阅读,更清晰明了):
- XML:是独立于软件和硬件的信息传输工具,被设计用来传输和存储数据,其焦点是数据内容,但XML语言没有预定义的标签,允许创作者定义自己的标签和自己的文档结构;
- HTML:被设计用来显示数据,其焦点是数据的外观;
- XHTML:指的是可扩展超文本标记语言,是以XML格式编写的HTML,是更加严格更加纯净的HTML版本;
- XML命名空间:提供避免元素命名冲突的方法。在XML中,元素名称是自定义的,当两个不同文档使用相同的元素名时,就会发生命名冲突。可以使用前缀来避免命名冲突,命名空间是在元素的开始标签的 xmlns 属性中定义的,所有带有相同前缀的子元素都会与同一个命名空间相关联。
2、RDF:用于web上的资源描述框架,使用XML编写,是为了被计算机阅读和理解
(1)RDF规则:使用web标识符来标识资源,使用属性和属性值来描述资源。其中,资源是可拥有URI的任何事物,如 “https://www.runoob.com//rdf”;属性是拥有名称的资源,如 “author” 或 “homepage”;属性值是某属性的值,如"David" 或 “https://www.runoob.com/” (属性值可以是另外一个资源)
(2)RDF主要元素:以及可表示某个资源的元素:
- rdf:RDF:是RDF文档的根元素,他把XML文档定义为一个RDF文档,包含对RDF命名空间的引用;
- rdf:Description:通过about属性标识一个资源,可包含标记资源的那些元素
(3)RDF容器元素:用于描述一组事物,包括:、、 - rdf:Bag:用于描述一个规定为无序的值的列表
- rdf:Seq:用于描述一个规定为有序的值的列表(如字母顺序排序)
- rdf:Alt用于一个可替换的值的列表(用户仅可选择这些值的其中之一)
(4)RDF集合:用于描述仅包含指定成员的组
(5)RDF Schema:是对RDF的一种扩展,不提供实际的应用程序专用的类和属性,而提供一个描述应用程序专用的类和属性框架
(6)RDF都柏林核心:一套供描述文档的预定义属性
3、OWL:一门供处理web信息的语言,是构建在RDF之上的web本体语言,但较RDF相比,OWL是一门具有更强解释能力的更强大的语言
(1)为什么使用owl?
- Web信息拥有确切的含义
- Web信息可被计算机理解并处理
- 计算机可从Web上整合信息
import csv
from rdflib import Graph, Namespace
# 创建一个RDF图
graph = Graph()
# 导入PKU PIE本体文件
graph.parse(r"../../Datas/PKU_PIE/firstreleaseowl.owl", format="xml")
# 定义命名空间
rdfs = Namespace("http://www.w3.org/2000/01/rdf-schema#")
# 查询主实体和客实体
query = """
SELECT ?subject ?object
WHERE {
?subject rdfs:subClassOf ?object .
}
"""
# 执行查询
results = graph.query(query)
# 输出结果
for row in results:
subject = row.subject
pred = 'http://www.w3.org/2000/01/rdf-schema#subClassOf'
object = row.object
#写入文件
with open("../../Datas/PKU_PIE/firstreleaseowl.csv","w",newline='',encoding='utf-8') as f1:
writer=csv.writer(f1)
header=['Subject','Predicate','Object']
writer.writerow(header)
for row in results:
list_triple=[]
subject = row.subject
pred = 'http://www.w3.org/2000/01/rdf-schema#subClassOf'
object = row.object
st = str(subject)
list_triple.append(st)
list_triple.append(pred)
st = str(object)
list_triple.append(st)
writer.writerow(list_triple)
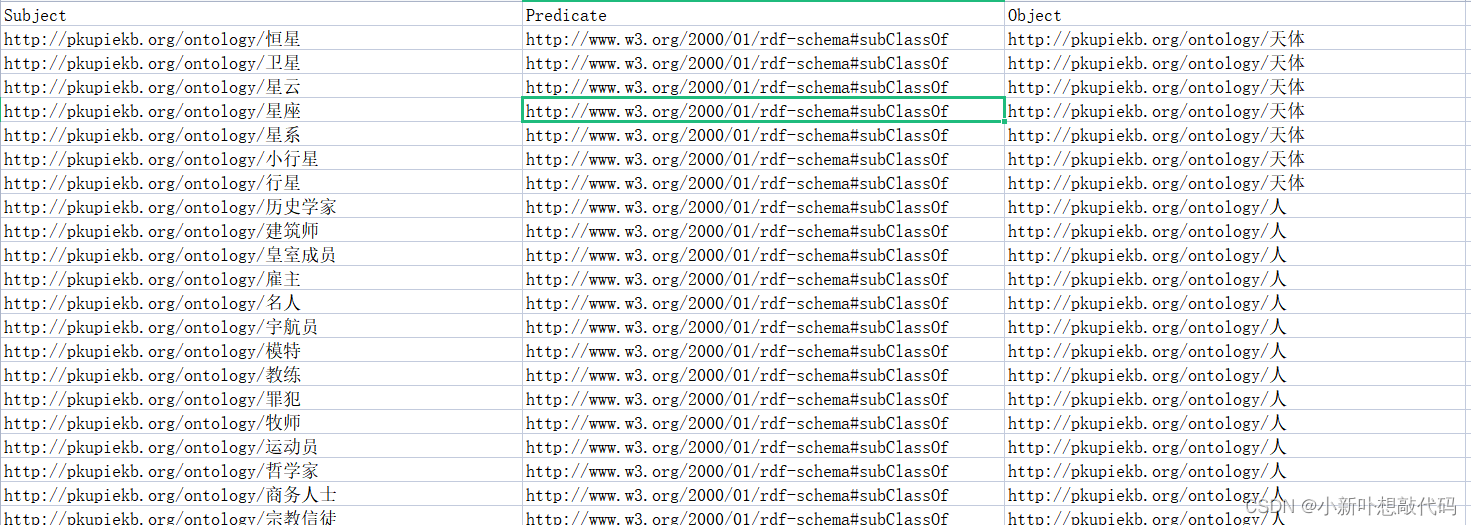
结果展示:
-
原文件内容:

-
解析之后:
(3)当读取了本体层数据信息,还需要获取一个实体类别三元组,即将实体及其所属类别对应,是RDF格式的.ttl文件
from rdflib import Graph
import csv
from tqdm import tqdm
import zhconv
# 创建一个空的 RDF 图
graph = Graph()
# 从 .ttl 文件加载数据到图中
graph.parse(r"../../Datas/PKU_PIE/firstreleasetriple.ttl", format="turtle")
# 进行数据操作,例如查询
query = """
SELECT ?subject ?predicate ?object
WHERE {
?subject ?predicate ?object .
}
"""
results = graph.query(query)
# 将结果写入 .csv 文件
with open("../../Datas/PKU_PIE/firstreleasetriple0.csv", "w", newline="",encoding='utf-8') as csvfile:
writer = csv.writer(csvfile)
# 写入表头
writer.writerow(["Subject", "Predicate", "Object"])
# 写入每一行数据
for row in tqdm(results):
simplified_row = [zhconv.convert(cell,'zh-cn') for cell in row] #源文件有的是繁体
# print(simplified_row)
writer.writerow(simplified_row)
print("数据已成功写入 output.csv 文件。")
解析结果:
-
源文件:
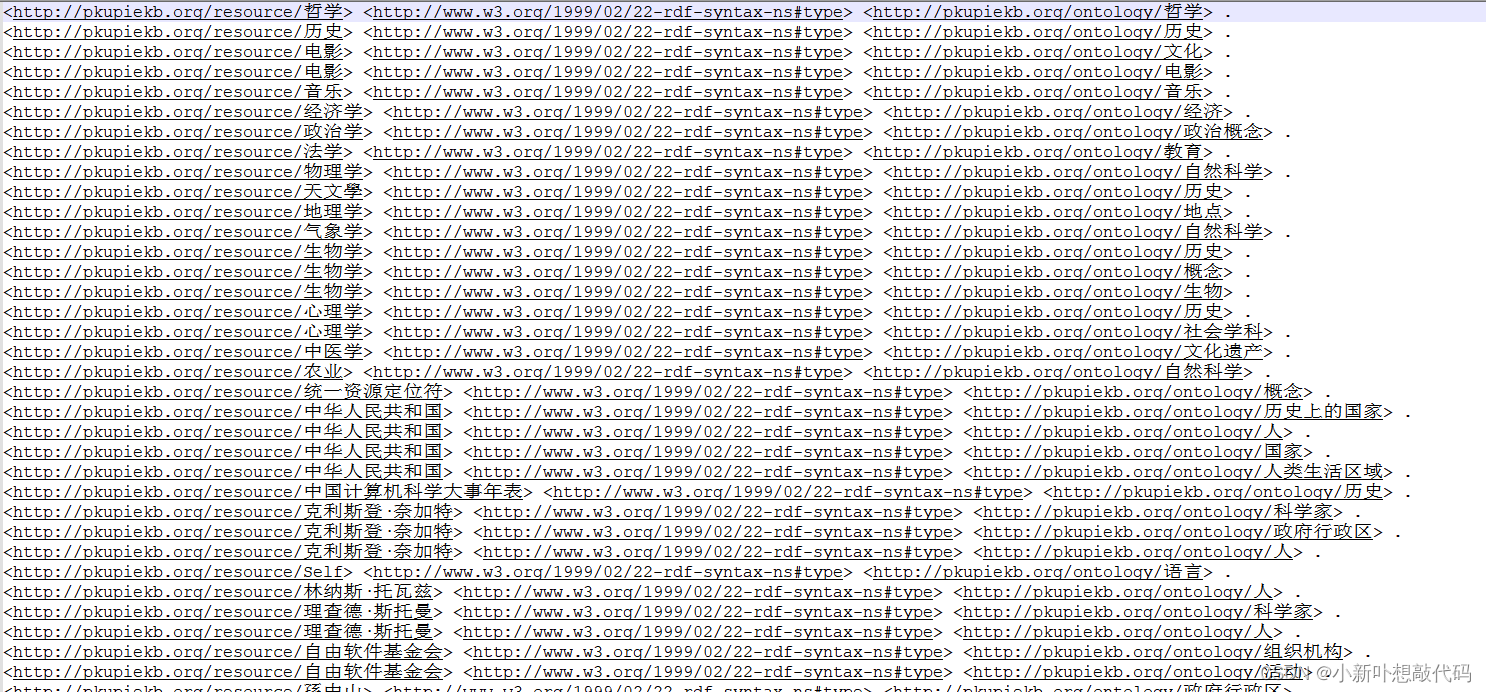
-
目标文件:
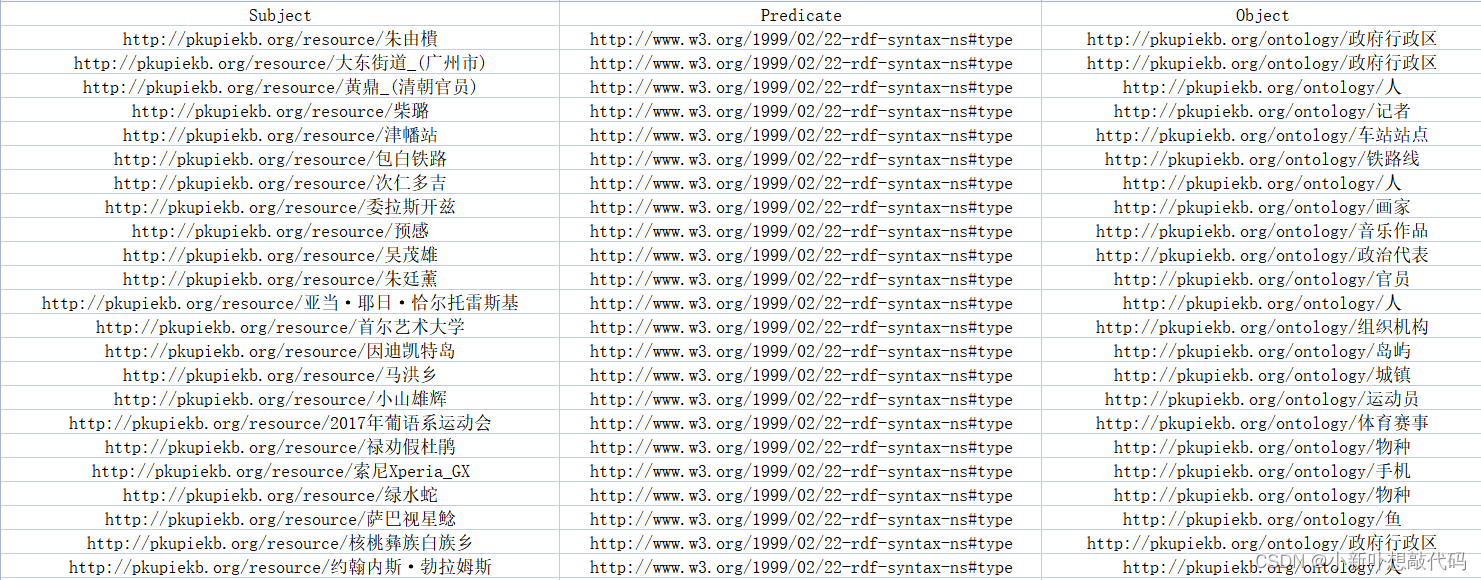
注:上述数据来源于北京大学中文百科知识图谱


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









