







最小生成树
什么是最小生成树:
1.生成树:
在一张无向连通有权图中,我们要从一个节点出发,找到一组有权边,将所有节点都连接起来,这样的一组节点和边将构成一颗树,也就是生成树,这颗树是根据图而生成的。
2.最小生成树:
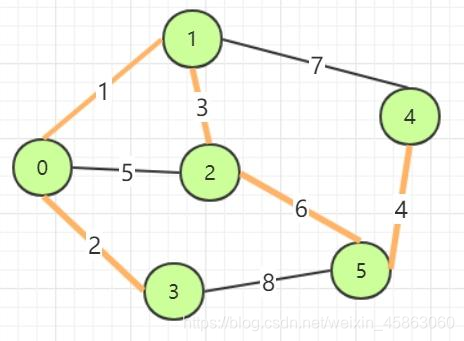
在所有生成树中,如果其中一棵树的所有边的权值和最小,那么就成为最小生成树,不过最小生成树可能不是唯一的。下图中加粗的边就构成了一颗最小生成树。
获得最小生成树的两种算法
1.Kruskal算法
Kruskal算法使用的是一种贪婪策略,首先对于V个节点,我们初始生成包含V棵树的森林,森林中的每一棵树初始本身就是其单个节点。接下来我们将所有边E从小到大排序,并由小到大对其进行遍历,如若找到的一条边(u,v)中u,v不属于同一棵树,那么我们将这个边(u,v)加入到最小生成树的边当中,并将u,v分别所在的两棵树a,b进行合并,合并成同一颗树c,如果u,v在同一棵树上,那么我们就不对(u,v)进行上述操作,而将其舍弃。重复上述过程,可以不断将森林中的树合并,并不断将遍历到的一些边加入到最小生成树的边当中,当森林中的所有树被合并成一棵树时,这棵树就是最小生成树,算法结束。
用上面的图来描述Kruskal算法的过程:
遍历边的顺序大致如下:
(u,v) weight decision
0,1 1 加入
0,3 2 加入
1,2 3 加入
4,5 4 加入
0,2 5 舍弃
2,5 6 加入
1,4 7 舍弃
3,5 8 舍弃
下面给出完整的用c实现的Kruskal算法(基于上面给出的图获得最小生成树):
#include <stdio.h>
#include <stdlib.h>
//Kruskal算法获得最小生成树
# define N 6
//定义邻接表
int map[N][N]={
0,1,5,2,0,0,
1,0,3,0,7,0,
5,3,0,0,0,6,
2,0,0,0,0,8,
0,7,0,0,0,4,
0,0,6,8,4,0
};
//设置邻接表
set_map()
{
int i,j,k;
for(i=0;i<N;i++)
{
printf("请输入第%d个节点的邻接关系:\n",i);
for(j=0;j<N;j++)
{
printf("通向节点%d的边的权值: ",j) ;
scanf("%d",&map[i][j]);
}
}
printf("\n邻接表设置完毕\n");
for(i=0;i<N;i++)
{
for(j=0;j<N;j++)
{
printf("%d ",map[i][j]);
}
printf("\n");
}
}
//定义边
typedef struct edge
{
int u;
int v;
int weight;
} edge;
//定义存放边的集合
typedef struct edgeList
{
int size;
edge edges[N*N];
} edgeList;
//初始化边的集合
Init_edgeList(edgeList ** eL)
{
(*eL)=(edgeList *)malloc(sizeof(edgeList));
(*eL)->size=0;
int i,j,k;
//获得所有边的信息并加入到表中
for(i=0;i<N;i++)
{
for(j=i+1;j<N;j++)
{
if(map[i][j]!=0)
{
(*eL)->edges[(*eL)->size].weight=map[i][j];
(*eL)->edges[(*eL)->size].u=i;
(*eL)->edges[(*eL)->size].v=j;
(*eL)->size++;
}
}
}
//对所有边按权值从小到大进行排序,即对结构体数组进行排序
edge t;
for(i=1;i<=(*eL)->size;i++)
{
for(j=0;j<(*eL)->size-i;j++)
{
if((*eL)->edges[j].weight>(*eL)->edges[j+1].weight)
{
t=(*eL)->edges[j];
(*eL)->edges[j]=(*eL)->edges[j+1];
(*eL)->edges[j+1]=t;
}
}
}
}
//定义树
typedef struct tree
{
edge edges[N-1];
int vertexs[N];
int edge_num;
int flag;
} tree;
//定义森林
typedef struct forest
{
tree trees[N];
int tree_num;
} forest;
//初始化森林和树
forest* Init_forest()
{
int i,j,k;
forest *f=(forest*)malloc(sizeof(forest));
f->tree_num=N;
for(i=0;i<N;i++)
{
for(j=0;j<N;j++) f->trees[i].vertexs[j]=0;
f->trees[i].vertexs[i]=1;
f->trees[i].edge_num=0;
f->trees[i].flag=1;
}
return f;
}
Union(tree *t1,tree *t2)//合并两棵树
{
int i,j;
//将t2中的边加入到t1当中
for(i=0;i<t2->edge_num;i++)
{
t1->edges[t1->edge_num]=t2->edges[i];
t1->edge_num++;
}
//将t2中的节点加入到t1当中
for(i=0;i<N;i++)
{
if(t2->vertexs[i]==1)
{
t1->vertexs[i]=1;
}
}
//将t2标记为舍弃
t2->flag=0;
}
Kruskal(edgeList *eL,forest *f)
{
int i,j,k,n=1;//n表示最小生成树中已经存在的节点数
int u,v,t1=-1,t2=-1;
edge e;
while(n!=N)
{
for(i=0;i<N;i++)
{
e=eL->edges[i];
u=e.u;
v=e.v;
//找到u和v分别在哪一棵树当中
for(j=0;j<N;j++)
{
if(f->trees[j].vertexs[u]==1&&f->trees[j].flag)
{
t1=j;
}
if(f->trees[j].vertexs[v]==1&&f->trees[j].flag)
{
t2=j;
}
}
if(t1!=t2)//如果两节点不在同一棵树当中,则将这条边加入最小生成树,并将两棵树进行合并
{
//将这条边加入到树t1中
f->trees[t1].edges[f->trees[t1].edge_num]=e;
f->trees[t1].edge_num++;
f->trees[t1].vertexs[v]=1;
//将t1和t2进行合并
Union(&f->trees[t1],&f->trees[t2]);
f->trees[t2].flag=0;
n++;
}
}
}
}
int main()
{
//set_map();
tree MinTree;
int i,j,k,min_p=0;
edgeList *eL;
Init_edgeList(&eL);
printf("图的邻接关系及边的权重表示如下:\n") ;
for(i=0;i<eL->size;i++)
{
printf("u=%d v=%d weight=%d\n",eL->edges[i].u,eL->edges[i].v,eL->edges[i].weight);
}
forest * f=Init_forest();
Kruskal(eL,f);
//找到最小生成树的所在
for(i=0;i<N;i++)
{
if(f->trees[i].flag!=0)
{
MinTree=f->trees[i];
}
}
//打印最小生成树中的每一条边
printf("\n最小生成树中的所有边:\n");
for(i=0;i<MinTree.edge_num;i++)
{
printf("(%d,%d) weight=%d\n",MinTree.edges[i].u,MinTree.edges[i].v,MinTree.edges[i].weight);
min_p+=MinTree.edges[i].weight;
}
printf("\n最小生成树所有边的权值之和为:%d\n",min_p);
}
程序运行后结果显示如下:

上面这段用c语言实现的Kruskal算法只是我初学Kruskal算法时按照书上给出的算法逻辑写出的,并不是很高效很正统的算法,但我认为是对于初学者来说是好理解并且形象的。
2.Prim算法
Prim算法也属于一类贪心算法,其主体思路是,从图中任意一个节点开始,将其当作最小生成树的一个根节点,然后不断使用贪心策略找到一条当前看来最短的边使最小生成树保持最小权值和的情况下不断增长:从当前根节点开始,搜索所有对于根节点u,可以到达的另一个节点v,并且v不在树上,找到一个使(u,v)权值最小的v,将v和这条边加入到树中,并且将v标记为已知,再通过v更新已知信息,即更新所有节点到v的边的权是否更小,如果更小则更新为该值,并从中获得下一个新的,与树上节点间拥有最小权边的节点,让最小生成树继续增长,直到所有节点都长到树上为止。
与Kruskal算法相比较,Kruskal算法的操作对象重点在边上,主要对边进行遍历,而Prim算法的关注对象在点上,主要对点进行遍历。
为了方便阅读,我们再将最上面的图复制下来说明以上算法的过程:
还是这张熟悉的图,假设从0开始进行Prim算法的过程,首先对于0来讲,1无疑是符合要求的拥有最小权边的节点,所以让1长到书上并以1为当前节点更新已知信息:此时3为到树节点最近的节点,于是再让3长到树上,立足于3更新路径信息,然后以此类推我们依次获得的节点与边为:(1,2) (2,5) (5,4)。
下面我们再给出简单易于理解版的c语言实现:
#include <stdio.h>
#include <stdlib.h>
//基于Prim算法获得最小生成树
# define N 6
//定义邻接表
int map[N][N]={
0,1,5,2,0,0,
1,0,3,0,7,0,
5,3,0,0,0,6,
2,0,0,0,0,8,
0,7,0,0,0,4,
0,0,6,8,4,0
};
typedef struct
{
int u;
int v;
int weight;
}edge;
typedef struct
{
edge edges[N*N];
int vertexs[N];
int edge_num;
int vertex_num;
}tree;
tree t;
d[N];//每一个节点到树的最短边的权值,之后在选择初始节点时会将其它节点的该值初始化为很大的数,意义是初始情况下不可到达
p[N];//存放对于第i个节点来说,到树上最近的节点
int current_Vertex;//当前节点
//通过初始节点初始化信息
Init_Info(int Init_Vertex)
{
int i,j,k;
for(i=0;i<N;i++)
{
if(i!=Init_Vertex) d[i]=999999;
}
d[Init_Vertex]=0;
//接下来初始化树
t.edge_num=0;
t.vertex_num=0;
t.vertexs[Init_Vertex]=1;
//初始化距离信息
update_distance(Init_Vertex);
}
//更新所有节点到v的距离
update_distance(int v)
{
int i,j,k;
for(i=0;i<N;i++)
{
if(map[v][i]<d[i]&&map[v][i]!=0)
{
d[i]=map[v][i];
p[i]=v;
}
}
}
//将节点v及边(u,v)纳入到最小生成树中
Union(int u,int v)
{
//获得这条边(u,v)的信息
edge e;
e.u=u;
e.v=v;
e.weight=map[u][v];
t.vertexs[v]=1;
t.vertex_num++;
//将这条边e加入到树中
t.edges[t.edge_num++]=e;
}
//获得当前距离树拥有最小权值边的节点v
int get_v()
{
int i,j,min_d=999999;
int v;
for(i=0;i<N;i++)
{
if(min_d>d[i]&&t.vertexs[i]==0)
{
min_d=d[i];
v=i;
}
}
return v;
}
//Prim算法主体
Prim(int Init_Vertex)
{
int i,j,k;
int u,v;
Init_Info(Init_Vertex);
while(t.vertex_num!=N)
{
v=get_v();//获取节点v
u=p[v];//获得u
Union(u,v);//将节点v连带这条边合并到树上
update_distance(v);//更新边的权值信息
}
}
main()
{
int i,j,k,weight_sum=0;
int Init_Vertex=0;
Prim(Init_Vertex);
for(i=0;i<N-1;i++)
{
weight_sum+=t.edges[i].weight;
printf("(%d,%d) weight=%d\n",t.edges[i].u,t.edges[i].v,t.edges[i].weight);
}
printf("最小生成树的权值之和为%d\n",weight_sum);
}

可以看到Prim算法一样能得出和Kruskal算法一样的结果














 4708
4708











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









