







1.简单模式匹配算法(暴力匹配)
在简单的模式匹配算法中,我们使用的是一种暴力求解的匹配思路。
假设有主串S1和模式串S2,在S2向S1匹配的过程中,一但一次匹配失败,我们需要回溯主串的位置进行重新匹配:
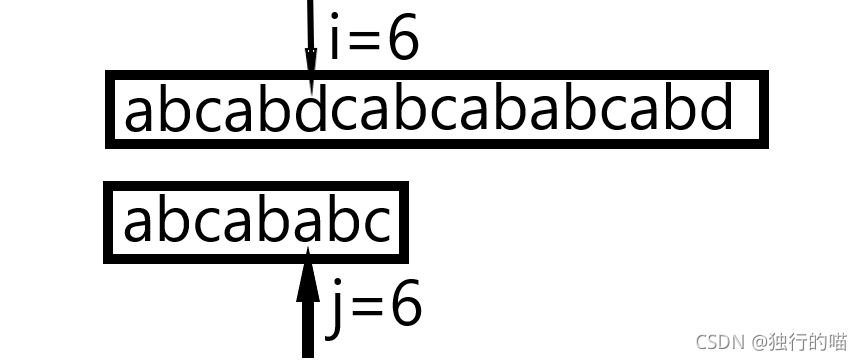
假设在这样的位置比较失败了,这次主串比较的起始位置为1,那么在下次重新比较的时候需要从下一个起始位置2开始对模式串重新比较匹配。
这样的算法简单但是暴力,其算法的时间复杂度为O(nm)其中n为主串长度,m为模式串的长度。为了节省时间优化时间复杂度,引入下面的KMP算法。
2.KMP算法
首先分析暴力匹配模式的缺点,即时间复杂度不理想的原因是每一次模式串匹配失败后,主串和模式串都需要进行回溯,而这样的回溯是极其浪费时间的。为了进行改进,我们可以思考如何尽量减少不必要的回溯,这就是KMP算法的核心。
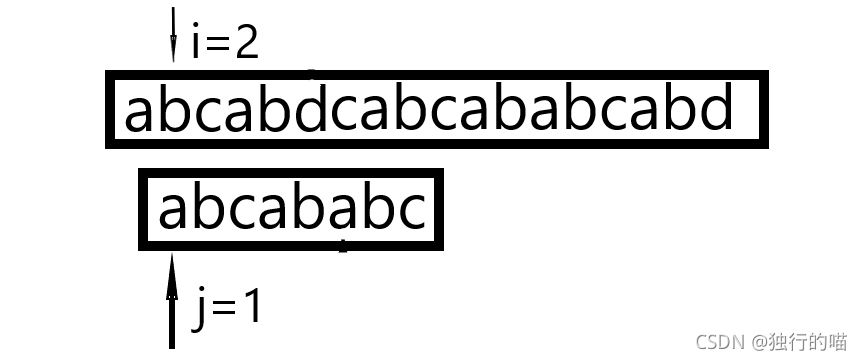
KMP算法是对字符串的简单模式匹配算法的一种改进,其思想是只让模式串的比较位置发生改变移动,而不使主串的比较位置进行回溯。如果采用kmp算法,上图在第一次比较失败后应当使模式串右移至下图的位置进行比较:

如何做到在主串匹配位置不变的情况下,让模式串移动到合适的位置上?
KMP算法给出了模式串移动距离的公式,KMP算法的移动公式:
模
式
串
右
移
量
=
已
匹
配
字
符
数
−
前
缀
与
后
缀
的
最
大
公
共
串
长
度
模式串右移量=已匹配字符数-前缀与后缀的最大公共串长度
模式串右移量=已匹配字符数−前缀与后缀的最大公共串长度
下面对公式进行一定的解释:
前缀:除最后一个字符外,字符串的所有头部子串
后缀:除第一个字符外,字符串的所有尾部子串
我们要计算的最大公共串长度是指匹配失败的字符前的字符串(不包括匹配失败的字符)的公共前后缀最大长度。
例如:上图第一次匹配失败的字符为模式串中的a,a前的字符串为abcab,最长的公共前后缀为ab,长度为2,而已匹配的字符串长度为j-1=5;
所以我们可以计算出右移数量为:move=5-2=3;
而新的j为值应为j=j-move=6-3=3
为了更快地在匹配失败时确定模式串应该回溯到的正确位置,我们采用一种很常见的,时间换空间的思想。即用一个next数组来记录在模式串在第j个位置匹配失败后因该回溯到的正确的位置。这样一来当我们匹配失败时,可以让主串不动,直接通过next数组让模式串移动,然后继续匹配。
求next数组
next数组的意义:next数组用来记录j位置的字符串匹配失败后应该移动到的新的位置j,即j=next[j]
这里简单推导一下为什么j=next[j]:
m
o
v
e
=
已
匹
配
字
符
数
−
最
长
公
共
前
后
缀
move = 已匹配字符数-最长公共前后缀
move=已匹配字符数−最长公共前后缀
最
长
公
共
前
后
缀
=
n
e
x
t
[
j
]
最长公共前后缀 = next[j]
最长公共前后缀=next[j]
已
匹
配
字
符
串
=
j
(
j
从
0
开
始
)
已匹配字符串=j\space (j从0开始)
已匹配字符串=j (j从0开始)
j应该移动到的位置:
j
=
j
−
m
o
v
e
=
j
−
(
j
−
n
e
x
t
[
j
]
)
=
n
e
x
t
[
j
]
j=j-move=j-(j-next[j])=next[j]
j=j−move=j−(j−next[j])=next[j]
如何求解next数组是KMP的一个难点和核心
假设字符串是从索引位置0开始存储的
一般经典的求解算法代码如下:
void get_next(char *s,int *next)
{
next[0]=-1;
int i=0,j=-1;
//关于j=-1 赋值为-1的意义: 要始终保证j=next[j] 而next[0]=-1 i=j+1
//j表示已匹配的字符串
//如果j=-1说明没有可以匹配的字符串,则让后缀向后扩展,寻找新的可以和前缀匹配的后缀
int length=sizeof(s)/sizeof(char);
while(i<length)
{
if(j==-1||s[i]==s[j])//当是s[i]==s[j]时 next[j+1]=next[j]+1 成立,next[-1+1]=next[-1]+1是特殊条件
{
i++;
j++;
next[i]=j;//如果s[i]==s[j],则next[j+1]=next[j]+1;
//i=j+1 j=next[j] j++==next[j]+1
}
else
{
j=next[j];
}
}
}
再解释以下代码中i和j再算法中的实际意义:
j表示所配匹配的前缀的下一个字符的位置,j表示被匹配的字符数量,也就是当前公共缀的长度
而i表示后缀正在被匹配的位置
j的初始值被赋值为-1,表示初始当前的next[0]匹配的公共串的长度为0,随着j的增加,被匹配的公共串的长度也在增加
如果s[j]和s[i]的字符不匹配了,这时要让j回到它应该回到的位置重新进行匹配,而j应该回到的位置正好是next[j]所存储的值,如果当特殊情况j刚好在0也就是字符串首的位置,那么j就没有办法再左移了,只能想办法让i右移,比较新的位置的next值,获得新的后缀位置,所以我们把next[0]的位置赋值为-1,让j=next[0]即让j相对于i左移了一位,再让i和j同时加1则可以实现i的右移,来计算新位置的next值。
由上述算法求出图中模式串的next数组内容为:
next 0 1 2 3 4 5 6 7
value -1 0 0 0 1 2 1 2
有了模式串的next数组后,再利用next数组来匹配模式串在主串中的位置的算法就会比较简单:
int Kmp(char s1[],char s2[],int length1,int length2)
{
int next[length2];
int i=0,j=0;
get_next(s2,length2,next);
printf(" next 数组的内容为:\n");
int k=0;
for(k=0;k<length2;k++)
{
printf("%d ",next[k]);
}
while(i<length1)
{
if(j==-1||s1[i]==s2[j])
{
i++;j++;
}
else
{
j=next[j];
}
if(j==length2-1)
{
return j;
}
}
return -1;
}
这里需要注意的一点是,当模式串与主串匹配成功时,我们自然可以得到最终的j的位置为length2-1.
但是如果匹配失败时的情形时怎样的:
这里需要注意到算法中主串i的值始终只有++的可能,而当匹配一直失败时,模式串j的位置总是最终会回滚到-1(意味着可以使i进行一次增长),这样一来就保证了i的值最终一定可以突破主串的长度来跳出循环。














 1615
1615











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









