






基于模板匹配的车牌字符识别算法研究
摘要
随着智能交通系统(ITS)的快速发展,车牌自动识别技术(ALPR)作为其核心组成部分,在交通管理、安防监控等领域发挥着重要作用。然而,复杂环境下的车牌识别仍面临诸多挑战,如光照变化、车牌污损、拍摄角度倾斜等,导致传统识别方法的准确率和鲁棒性不足。本文针对这些问题,研究了一种基于模板匹配的车牌字符识别算法,旨在结合传统图像处理技术与现代机器学习方法,提升车牌识别的精度和实时性。
本文首先系统分析了车牌识别的基本流程,包括车牌定位、图像预处理、字符分割和字符识别四个关键环节。在车牌定位阶段,探讨了基于颜色特征、边缘特征和机器学习的多特征融合策略。图像预处理环节重点研究了灰度化、直方图均衡化、边缘检测和二值化等技术,通过对比Sobel、Laplacian等算子的性能,验证了Sobel算子在边缘检测中的优势。字符分割部分对比了投影分割法、连通域分割法和模板匹配法,实验表明模板匹配算法在复杂场景下表现最优。最后,在字符识别阶段,采用模板匹配算法,通过字符归一化和互相关量计算,实现了高精度的字符识别。
实验结果表明,本文提出的基于模板匹配的车牌字符识别算法在复杂环境下具有较高的识别准确率和鲁棒性,能够有效应对光照变化、噪声干扰等问题,为智能交通系统的实际应用提供了可靠的技术支持。
关键词:车牌识别;模板匹配;图像预处理;字符分割;智能交通系统
ABSTRACT
With the rapid advancement of Intelligent Transportation Systems (ITS), Automatic License Plate Recognition (ALPR) has become crucial for traffic management and surveillance. However, complex conditions like lighting variations, plate damage, and skewed angles challenge traditional methods. This paper proposes a template-matching-based algorithm combining image processing and machine learning to enhance accuracy and real-time performance.
This paper systematically analyzes the fundamental workflow of license plate recognition, including four key stages: license plate localization, image preprocessing, character segmentation, and character recognition. In the localization stage, a multi-feature fusion strategy based on color features, edge features, and machine learning is explored. The preprocessing phase focuses on techniques such as grayscale conversion, histogram equalization, edge detection, and binarization, comparing the performance of operators like Sobel and Laplacian, with Sobel proving superior in edge detection. For character segmentation, projection-based segmentation, connected-component analysis, and template matching are compared, with experimental results showing that template matching performs best in complex scenarios. Finally, in the character recognition stage, template matching is employed, achieving high accuracy through character normalization and cross-correlation calculations.
Experimental results demonstrate that the proposed template-matching-based license plate character recognition algorithm exhibits high accuracy and robustness in complex environments, effectively handling challenges such as lighting variations and noise interference. This provides reliable technical support for the practical application of intelligent transportation systems.
Key words: License plate recognition; Template matching; Image preprocessing; Character segmentation; Intelligent Transportation System (ITS)
目录
第一章. 绪论
1.1 研究背景及意义
随着我国经济的持续高速发展和城市化进程的加速推进,机动车保有量呈现迅猛增长态势。根据公安部交通管理局最新统计数据,截至2025年3月,全国机动车保有量已突破4.8亿辆,其中汽车保有量高达3.6亿辆,较2024年同期增长12.3%,年均增长率维持在10%以上[1]。汽车的大规模普及在提升居民出行便利性的同时,也给城市交通管理带来了前所未有的挑战。交通拥堵、违章停车、交通事故频发等问题日益严重,传统依赖人工巡查和管理的模式已难以适应现代化城市交通治理的需求[2]。
在此背景下,智能交通系统(Intelligent Transportation System, ITS)作为现代交通管理的核心技术应运而生。该系统深度融合5G通信、人工智能(AI)、大数据分析、云计算等前沿技术,构建了一个全方位、智能化、高效率的交通管理网络[3]。ITS不仅能够优化交通信号控制、提升道路通行效率,还能在交通事故预警、违章行为自动检测、智慧停车管理等方面发挥关键作用。其中,车牌自动识别技术(Automatic License Plate Recognition, ALPR)作为ITS的核心组成部分,通过计算机视觉技术对交通监控摄像头采集的视频流进行实时分析,自动检测并识别车辆牌照信息,为智能交通管理提供精准的数据支持[4]。相较于传统人工识别方式,ALPR系统具有识别速度快、准确率高、可全天候运行等显著优势,能够大幅降低人力成本,提高交通管理效率[5]。
目前,ALPR技术已在高速公路收费站、停车场出入口、小区门禁等受控环境下得到广泛应用,并取得了较好的识别效果,如图1-1所示。然而,在城市道路复杂场景中,由于光照变化、恶劣天气(如雨雪雾)、车辆高速运动、拍摄角度倾斜、车牌污损等因素的影响,现有系统的识别性能明显下降,尤其是在交通卡口、城市主干道、复杂交叉路口等关键节点,误检率和漏检率较高,难以满足实际应用需求[6]。因此,如何在复杂环境下实现高精度、高鲁棒性的车牌识别,仍然是智能交通领域亟待解决的关键问题。
近年来,深度学习(Deep Learning)技术在计算机视觉领域取得了突破性进展,特别是在目标检测,如YOLO[7]、Faster R-CNN[8]、图像分类,如ResNet[9]、EfficientNet[10]、字符识别如CRNN[11]等任务上表现优异。相较于传统基于手工特征如SIFT、HOG的算法,深度学习方法能够自动学习更具判别性的特征表达,对复杂环境下的噪声、遮挡、形变等问题具有更强的鲁棒性[12]。然而,纯粹的深度学习模型往往需要大量标注数据进行训练,且计算复杂度较高,难以在资源受限的嵌入式设备如交通摄像头、边缘计算终端上高效运行[13]。

图1-1 ALPR系统广泛应用于各种场景
因此,本研究聚焦于基于模板匹配的车牌字符识别算法,旨在结合传统图像处理技术与现代机器学习方法,探索一种在计算资源受限条件下仍能保持高精度、高实时性的车牌识别方案。该研究不仅有助于推动智能交通领域的技术创新,提升城市交通管理的智能化水平,还能为智慧城市、自动驾驶、电子警察系统等应用场景提供关键技术支撑,具有重要的理论研究价值和实际应用意义。
综上所述,针对城市道路复杂环境下的车牌识别问题,开展高效、鲁棒的识别算法研究,是推动智能交通系统发展、促进智慧城市建设的重要途径,也是当前计算机视觉与模式识别领域的研究热点之一。
1.2 国内外研究现状及发展趋势
自动车牌识别(ALPR)系统作为智能交通体系的关键组成部分,其核心功能在于对交通监控影像中的车辆牌照信息进行自动化提取与识别。该技术融合了计算机视觉与模式识别领域的多项关键技术,主要包括目标检测、数字图像处理和机器学习等学科方向。从技术发展历程来看,ALPR技术自20世纪90年代问世以来,经过数十年的演进与完善,已形成相对成熟的技术框架体系。
在技术实现层面,典型的ALPR系统通常遵循三级处理架构,自动车牌识别算法通用流程如图1-2所示。
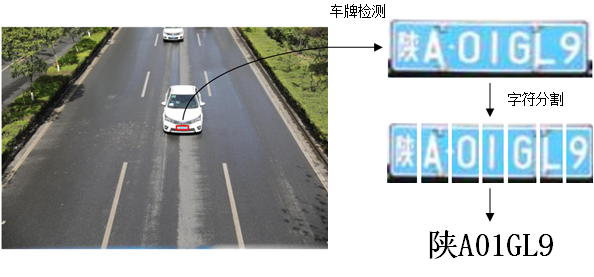
图1-2 自动车牌识别算法通用流程
1)车牌区域检测阶段:通过计算机视觉算法从复杂背景中准确定位并提取车牌区域;
2)字符分离阶段:对提取的车牌图像进行字符级分割处理,实现单个字符的精确分离;
3)字符识别阶段:采用模式识别技术对分割后的独立字符进行特征提取与分类识别。
最终,系统通过对各字符识别结果的序列化整合,输出完整的车牌号码信息。这种分层处理架构不仅提高了系统的模块化程度,也为各技术环节的独立优化提供了可能。值得注意的是,随着深度学习技术的发展,传统基于模板匹配的方法正逐步向端到端的识别模式转变,但基本处理流程仍保持着较高的继承性。
1.2.1 国外研究现状
国外在车牌检测领域的研究起步较早,形成了从传统图像处理到深度学习方法的完整技术体系,在算法创新和跨场景应用方面取得了丰硕成果。早期的代表性工作主要集中在轮廓特征提取方面,如D. Zheng等人在2005年提出的基于Sobel滤波器的检测方法,通过分析横竖边缘特征实现车牌定位。随后发展的竖向边缘检测算法(VEDA)将计算效率提升了八倍,为实时检测奠定了基础。在纹理分析方向,Anagnostopoulos团队提出的同轴滑窗算法(SCW)通过量化局部纹理变化来识别车牌区域,而基于小波变换的方法则在特定测试环境下达到了97.33%的检测准确率,处理速度可达0.2秒每帧。这些传统方法虽然在结构化场景表现良好,但在复杂环境下的鲁棒性仍有待提高。
颜色特征的研究在国外同样受到高度重视。X. Shi等人开创性地应用HLS颜色空间进行像素级分类,为后续研究提供了重要参考。Jia Wenjing团队提出的高斯权重直方图方法有效解决了光照变化带来的颜色失真问题。此外,有学者将颜色空间转换与机器学习分类器相结合,进一步提升了算法的环境适应性。值得注意的是,国外研究特别关注不同国家车牌样式的差异性,开发了多种自适应算法来处理颜色组合各异的车牌类型。近年来,随着深度学习革命的到来,国外研究重点快速转向神经网络方法。以R-CNN系列和YOLO为代表的目标检测模型被广泛应用于车牌检测,这些模型通过深度卷积网络自动学习判别性特征,大幅提升了检测性能。有研究将Faster R-CNN与多尺度特征融合技术相结合,显著改善了不同尺寸车牌的检测效果;还有团队利用生成对抗网络(GAN)进行车牌图像的超分辨率重建,有效提升了低质量输入下的检测准确率。
在技术创新方面,国外研究展现出鲜明的特色。针对跨国别应用场景,研究人员提出了基于迁移学习的自适应框架,使系统能够快速适应新的车牌样式。多模态融合方法通过结合颜色、纹理和深度特征,显著提升了系统的泛化能力。在实时性优化方面,有研究通过模型压缩和硬件加速技术,使复杂算法能够在移动设备上高效运行。特别值得关注的是,国外研究非常注重建立标准化的评测体系和公开数据集,如包含多国车牌样式的综合测试集,为算法比较和技术进步提供了重要平台。这些研究不仅推动了车牌检测技术的发展,更为计算机视觉领域的特征提取、目标检测等基础问题提供了有价值的参考。随着自动驾驶、智能城市等新兴应用的兴起,国外研究正朝着更高精度、更强鲁棒性和更快速度的方向持续发展。
1.2.2 国内研究现状
国内车牌检测技术的研究经历了从传统图像处理方法到深度学习技术的演进过程,在算法创新和实际应用方面都取得了显著进展。早期的研究主要围绕车牌的结构特征展开,包括轮廓、纹理和颜色等关键特征的提取与利用。在轮廓特征检测方面,国内学者广泛采用Sobel算子、Canny边缘检测等经典算法,通过提取车牌边缘特征并结合形态学处理方法进行优化。这类方法通过检测图像中符合特定宽高比的矩形区域来定位车牌,在简单场景下具有较好的效果,但对复杂背景的适应性较差,容易受到其他类似轮廓物体的干扰。在纹理特征分析方面,小波变换和Gabor滤波器成为主要研究工具,通过分析车牌字符与背景的显著纹理差异来实现定位。有学者提出改进的滑动窗口结合纹理分析的方法,在特定场景下可以达到较高的检测准确率,但这类方法普遍存在计算复杂度高的问题,难以满足实际应用中的实时性要求。
颜色特征因其直观性和稳定性成为国内研究的重点方向。考虑到中国车牌具有标准化的颜色组合(如蓝底白字、黄底黑字等),基于HLS、HSV等颜色空间的方法得到广泛应用。研究人员提出了多种创新方法,如利用高斯权重直方图进行颜色匹配,有效降低了光照变化对检测效果的影响。还有研究将颜色聚类与区域生长算法相结合,显著提升了车牌定位的鲁棒性。然而,这些方法在极端光照条件(如强烈反光或严重阴影)下仍存在明显的性能局限。近年来,随着深度学习技术的快速发展,国内研究重点转向了基于卷积神经网络(CNN)的检测方法。以Faster R-CNN、YOLO、SSD为代表的目标检测模型被成功应用于车牌检测任务,这些模型通过端到端训练自动学习车牌的多层次特征,在复杂场景下展现出显著优势。有研究团队将注意力机制引入YOLO模型架构,有效提升了小尺寸车牌的检测能力;还有学者提出多任务学习框架,实现了车牌检测与字符识别的联合优化,大幅提升了系统整体性能。
在工程应用方面,国内研究特别关注实际场景中的技术难点。针对车牌倾斜问题,研究人员开发了基于霍夫变换和最小二乘法的几何校正算法;为应对图像质量不佳的情况,提出了超分辨率重建和多种图像增强技术。这些研究不仅推动了算法进步,更为智能交通管理、安防监控等实际应用提供了可靠的技术支持。值得注意的是,国内研究在保持算法先进性的同时,也十分注重计算效率的优化,确保系统能够在资源受限的嵌入式设备上高效运行。
1.3 本文研究内容
论文分为4个章节:
第1章:本章阐述了车牌识别技术的研究背景及意义,分析了国内外研究现状及发展趋势。随着机动车保有量的快速增长,智能交通系统对高效、精准的车牌识别技术需求迫切。本章详细介绍了车牌识别技术的核心流程,包括车牌定位、字符分割和字符识别,并探讨了深度学习技术在车牌识别中的应用潜力。最后,明确了本文的研究目标和内容框架。
第2章:本章系统介绍了车牌识别的关键技术,包括车牌定位、图像采集、图像预处理、边缘检测、二值化处理和数学形态学处理。重点研究了基于颜色和边缘特征的车牌定位方法,对比了不同边缘检测算子的性能。此外,还探讨了直方图均衡化和形态学处理在图像增强中的应用。
第3章:本章深入研究了三种字符分割算法:投影分割法、连通域分割法和模板匹配法。通过实验对比,分析了各算法的优缺点。结果表明,模板匹配算法在复杂场景下表现最优,能够有效解决字符粘连和图像质量不佳的问题。
第4章:本章重点研究了基于模板匹配的字符识别方法,包括字符归一化处理和模板匹配算法。通过位置归一化和大小归一化,消除了字符图像与标准模板的尺寸差异。实验验证了模板匹配算法在汉字、字母和数字混合识别中的高效性和准确性,为车牌识别系统的实际应用提供了技术支持。
第二章 车牌识别算法基本原理
2.1 车牌定位
车牌定位作为车牌识别系统的核心环节,其准确性直接影响整个系统的识别性能。当前主流的车牌定位算法普遍采用多特征融合的策略,主要基于车牌的颜色特征、几何形状特征和纹理特征进行综合判断。单一特征检测容易产生多个候选区域,而多特征融合能显著提升定位准确率。然而,由于环境光照变化、图像质量波动等因素,以及各国车牌样式的差异性,都给车牌定位带来了诸多挑战。因此,在评估车牌定位算法时,需要综合考虑检测精度、时间效率和资源消耗等多个维度。
在具体算法实现方面,主要有以下几种典型方法:
1)颜色特征定位算法:这类算法利用车牌特有的颜色组合特征进行定位。Shyang-Lih Chang等人提出的方法通过分析颜色边缘特性和模糊处理来提升识别率。虽然该方法能有效利用颜色信息,但受光照条件影响较大,且处理时间较长。在实际应用中,常采用灰度图像处理来降低计算复杂度。
2)机器学习分类算法:基于车牌区域的类内相似性和类间差异性特征,采用不同分类器进行定位。常见的有基于Harr-like特征的Adaboost分类器、支持向量机(SVM)以及BP神经网络等方法。这些方法的性能很大程度上依赖于训练样本的质量,且计算复杂度较高。
3)边缘特征定位算法:通过检测车牌边框的直线特征,利用Hough变换等方法来定位车牌区域。该方法对图像质量要求较高,当车牌边缘不清晰时效果会显著下降,且容易受到车身其他类似特征的干扰。
4)分级定位算法:采用先粗选后精筛的策略,先快速提取候选区域,再通过分类器进行精确筛选。Wang等人提出的方法结合了竖直边缘特征和Adaboost分类器,在实验中表现出较高的识别率。
5)边缘统计定位算法:利用车牌字符的竖直边缘密集特征,结合形态学处理方法进行定位。B.Hongliang等人的研究表明该方法具有较快的处理速度,但需要后续处理来降低误检率。
当前各类车牌定位算法各有优劣,在实际应用中需要根据具体场景需求进行选择和优化。未来的研究方向应着重于提升算法的环境适应性和实时性能,同时降低计算资源消耗。通过持续优化和改进,车牌定位技术将能更好地满足智能交通系统的发展需求。
2.2 车牌图像采集
2.2.1 图像采集模块工作方式
当前主流的图像采集方式主要包括外设触发和视频触发两种技术方案。
(1)外设触发技术主要依靠地感线圈、红外传感器等检测装置实现。当车辆进入检测区域时,这些传感器能够实时感知车辆存在,并立即向采集系统发送触发信号,启动图像抓拍流程。该技术的核心检测模块通常由地感线圈和环路感应线圈构成。其工作原理是基于金属物体通过电感线圈时会引起电感量变化的物理特性。具体而言,当车辆驶过感应线圈区域时,车辆金属部件会导致线圈电感量发生变化,这一变化被传感器检测到后,会通过继电器输出电信号。该信号传输至抓拍控制单元后,会联动控制计算机启动图像采集系统,通过摄像设备和图像采集卡完成车辆图像的连续拍摄。
(2)视频触发技术则采用基于计算机视觉的运动目标检测算法。该技术通过对道路监控视频流进行实时分析,利用序列图像处理技术检测运动车辆。当系统识别到有车辆经过监控区域时,会自动触发图像采集装置进行抓拍。相比外设触发方式,视频触发无需安装物理传感器,具有部署灵活的优势。
从当前研究现状来看,外设触发方式因其稳定可靠的特性,仍然是主流的车辆检测方案。其核心优势在于检测精度高、抗干扰能力强,特别适合在复杂交通环境下应用。而视频触发技术虽然安装维护更为简便,但在恶劣天气或光照条件不佳的情况下,其检测性能可能会受到影响。
2.2.2 图像采集模块的工作原理
图像采集系统的工作原理可概括为:当车辆进入检测区域时,首先由车辆识别单元完成目标检测任务,随后将检测信号传输至中央处理系统。处理系统根据接收到的信号生成控制指令,驱动图像采集设备启动连续拍摄功能。该过程通常在辅助照明条件下完成,由高清数字摄像机捕获目标影像,经系统专用处理单元转换后形成可供分析的图像数据,最终传输至图像分析模块进行后续处理。该系统的硬件配置主要由以下几个关键部件构成:补光装置、光学镜头、数字摄像设备以及图像采集卡。在系统设计过程中,需要重点考虑这些核心组件的选型和参数配置。其中,补光装置确保在各种光照条件下都能获得清晰的图像;光学镜头决定成像质量和视野范围;数字摄像设备负责图像捕获;图像采集卡则完成图像信号的转换和传输。这些组件协同工作,共同构成了完整的图像采集解决方案。
图2-1展示了该系统的整体架构示意图,直观呈现了各功能模块之间的连接关系和工作流程。系统采用模块化设计思路,各功能单元既相对独立又紧密配合,确保整个图像采集过程的高效性和可靠性。在实际应用中,需要根据具体场景需求对各组件参数进行优化调整,以获得最佳的图像采集效果。
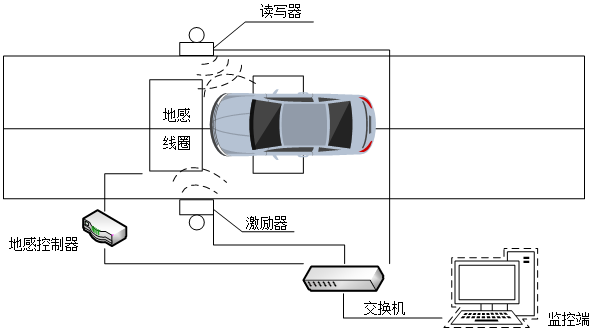
图2-1 自动车牌识别算法通用流程
2.3 车牌图像预处理
2.3.1 图像灰度化
当前主流的车牌识别系统普遍采用彩色摄像设备进行图像采集,所获取的原始图像均为彩色格式。虽然彩色图像蕴含更丰富的视觉信息,但由于环境光照条件的影响,采集到的车牌色彩往往与实际颜色存在显著偏差。为解决这一问题,在车牌识别流程中通常需要对图像进行灰度化预处理,后续的图像分析处理均基于转换后的灰度图像展开。从技术实现角度来看,摄像机拍摄的原始图像通常采用JPG格式存储,该格式由红(R)、绿(G)、蓝(B)三个颜色通道组成。为获得灰度图像,主要采用以下几种转换方法:最大值法:取RGB三通道中的最大值;平均值法:计算RGB三通道的算术平均值;加权平均法:根据人眼对不同颜色的敏感度差异进行加权计算
这些灰度化处理方法各有特点,在实际应用中需要根据具体场景需求进行选择和优化。通过灰度转换,不仅可以降低光照条件对识别效果的影响,还能显著减少后续图像处理的计算量,提高系统运行效率。值得注意的是,灰度化处理的质量直接影响后续字符分割和识别的准确性,因此选择合适的灰度转换算法至关重要。
(1)标准平均值法:其中H表示经过处理后的灰度图像,如下式。
H=0.3R+0.59G+0.11B (2-1)
(2)最大值法:灰度化图像H取 R,G,B 中最大的一个,如下式。
H=max(R,G,B) (2-2)
(3)加权法:灰度化图像H取三值与相应的权值乘积的和,如下式。
H=wRR+wGG+wBB (2-3)
2.3.2 图像增强
汽车牌照图像的采集质量容易受到多种外部环境因素的影响,包括光照强度、摄像机曝光参数以及天气状况等。这些因素往往会导致采集到的图像存在各种质量问题,其中最为突出的问题是图像对比度不足和灰度差异不明显。为了提高图像质量,为后续识别环节提供更优质的输入数据,通常需要对经过灰度化处理的图像进行专门的增强处理。该技术的核心思想是通过特定的数学变换,将原始图像的灰度直方图重新分布为近似均匀的概率密度函数。其主要优势在于能够有效扩展图像的灰度动态范围,从而显著提升图像的整体对比度表现。具体实现过程是通过建立原始灰度级到新灰度级的映射关系,使得输出图像的像素值在全部灰度级上呈现更均匀的分布状态。这种方法不仅计算效率较高,而且对改善低对比度图像具有显著效果。直方图均衡化技术算法的大致步骤是:
①列举出经过处理后的整个图像中所有像素的灰度级的数目fi=0 ,1,k,……,L-1,L 表示灰度级个数
②计算出每一个灰度级的个数nI,i=0,1,……,k,……,L-1,L
③计算出原束灰度图像直方图灰度级的频数pffi,i=0,1,…,k,… ,L-1,L
④计算出灰度级累计相加的分布函数,如下式:
c(f)= pffi,i=0,1,……,k……,L-1 (2-4)
⑤根据上面的公式结果计算出映射后的图像灰度级的gi,i=0,1,……K,P-1 ,计算公式如下(2-5):gi=INTgmax-gmin×C(f)+gmin+0.5 (2-5)
其中:INT 为正数符号:
⑥映射后的灰度级的像素数目ni,i=0,1,……K,P-1
⑦计算出输出的图像直方图pg
⑧通过fi,gi 之间的联系米改变处理前图像的灰度级,最后得到输出的直方图图像下图给出了经过直方图处理后的效果图2-2。
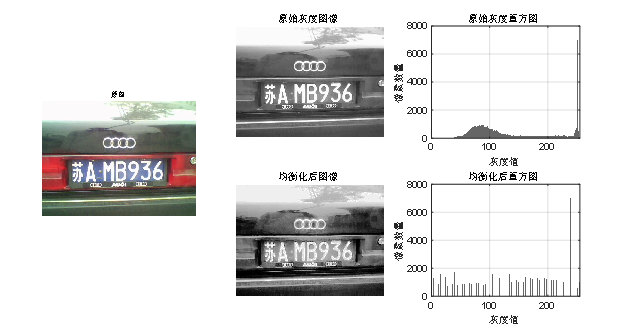
图2-2 处理后的直方图对比
为了清晰展示经过直方图均衡化技术处理后与未处理的效果对比图,处理前后灰度直方图如下图2-3所示。
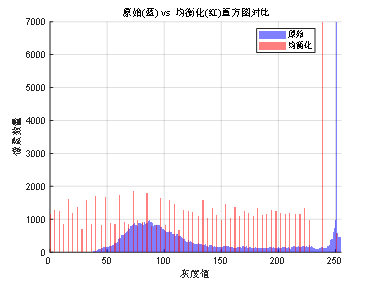
图2-3 直方图均衡化技术处理后与未处理的效果对比图
2.4 车牌边缘检测技术
在图像分析与处理领域的研究表明,图像中灰度值发生显著突变的区域通常对应于物体的边缘部分。这些边缘区域承载着图像最重要的几何结构和纹理特征信息。基于这一特性,可以通过检测图像中灰度变化最剧烈的区域来精确定位边缘位置。边缘检测作为图像分割与识别的基础环节,其本质是通过计算梯度值来强化图像中的轮廓特征,属于典型的梯度锐化技术。
然而在实际应用中,由于图像模糊和噪声干扰等因素,检测到的边缘往往存在不连续和断裂现象。这就要求边缘检测算法必须完成两个关键任务:首先是准确识别灰度突变的位置,其次需要对这些断裂的边缘点进行连接处理,最终形成完整连续的边缘轮廓线。针对这一需求,研究人员开发了多种边缘检测算子,主要包括以下几种典型方法:基于一阶微分的边缘检测算子;基于二阶微分的边缘检测算子;自适应边缘检测算法;多尺度边缘检测方法
这些方法各具特点,在实际应用中需要根据图像特性和处理需求进行选择。其中,基于一阶微分的方法通过计算梯度幅值来检测边缘,对噪声较为敏感;而基于二阶微分的方法则通过寻找过零点来定位边缘,对细节特征有更好的保留效果。
2.4.1 梯度算子
形态学梯度运算在数学本质上等同于微分运算中的一阶导数计算,因此这类运算方法也被称为一阶微分算子。对于任意定义在连续空间上的二维函数f(x,y),其在定义域内某点(x,y)处的梯度可由公式(2-6)表示:
∇f(x,y)∂f∂x∂f∂xT=GxGyT (2-6)
这个失量的梯度和方向角分别为:
mag(∇f)=Gx2+Gy212ϕ(x,y)=arctanGxGy12 (2-7)
该公式中的三个偏导数需要针对图像中每个像素点的坐标位置进行独立计算。在实际运算实现时,通常采用局部卷积核与图像区域进行卷积运算的方式来完成。其中,Gx和Gy分量各自对应一个独立的卷积核,因此完整的梯度运算需要两个卷积核共同配合完成。根据不同的应用场景需求,研究人员已经开发出多种具有特定特性的卷积核组合。
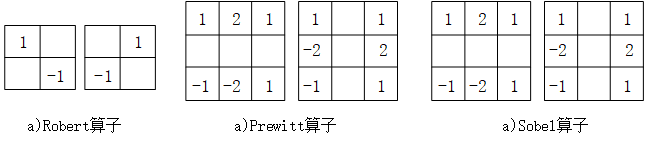
图2-4 常见的算子模版
图2-4展示了三种典型的梯度算子卷积核配置方案。在上述三种算子中,Robert算子结构最为简单,计算复杂度最低;而Sobel算子在边缘检测精度和抗噪性能方面表现最优。图2-5展示了Sobel算子在相同测试图像上的边缘检测效果对比,可以直观地观察到各算子的性能差异。实验结果表明,Sobel算子能够更好地平衡检测精度和计算效率,在实际应用中具有更好的综合性能表现。

图2-5 图像边缘增强前后对比
2.4.2 拉普拉斯算子(Laplacian)
拉普拉斯算子作为典型的二阶微分算子,在数字图像处理中具有重要应用价值。对于定义在连续空间上的二维函数f(x,y),其在定义域内任意点(x,y)处的拉普拉斯运算可由公式(2-8)表示:
∇2f=∂2f∂x2+∂2f∂y2 (2-8)
在离散图像处理实现过程中,拉普拉斯运算通常通过设计特定的卷积核来完成。这些卷积核的设计需要满足以下基本条件:(1)核中心位置的系数必须为正值;(2)与中心相邻的周边系数必须为负值;(3)所有系数的代数和必须等于零。这种设计原则确保了算子能够有效检测图像中的二阶微分特征。图2-6展示了两种常用的拉普拉斯卷积核配置方案,它们在实际应用中表现出不同的特性。第一种方案采用四邻域配置,计算量较小但方向敏感性较强;第二种方案采用八邻域配置,具有更好的各向同性特性,但计算复杂度相对较高。这两种方案都能有效突出图像中的边缘和细节特征,为后续的图像分析和处理提供重要基础。

图2-6 常见的Laplacian算子模版
拉普拉斯算子(Laplacian)车牌边缘检测技术处理后的图片如图2-7所示。

图2-7 拉普拉斯算子检测后的对比
分析检测结果可知,该算子不仅能够有效识别显著边缘特征,同时也能检测出较为微弱的边缘信息。然而,这种高灵敏度的特性也导致其对图像噪声较为敏感,这在车牌定位应用中会产生一定的负面影响。为了更全面地评估各算子的性能差异,表2-1系统性地汇总了常见边缘检测算子的卷积核配置及其主要特性参数。
在实际图像处理中,不同边缘检测算子各有特点。Sobel算子作为一阶微分代表,计算效率高且具有一定抗噪性,适合快速获取边缘轮廓,但对弱边缘和复杂纹理的检测能力有限。Laplacian算子作为二阶微分方法,能精确定位边缘位置,但对噪声极为敏感,通常需要配合高斯滤波使用。Canny算子通过多步骤处理实现了最优的边缘检测效果,在噪声抑制和边缘连续性方面表现突出,但计算复杂度较高。LoG算子通过多尺度分析能够检测不同粗细的边缘,但参数调节复杂且计算量较大。
表2-1 不同边缘检测方法特点
| 算子名称 | 边缘检测灵敏度 | 抗噪性能 | 计算复杂度 | 适用场景 | 优缺点 |
| Sobel | 中等 | 较好 | 低 | 实时系统、粗略边缘检测 | 优点:计算快,抗噪较好 缺点:边缘较粗,方向单一 |
| Laplacian | 高 | 差 | 中 | 高精度边缘定位 | 优点:能检测细边缘 缺点:对噪声敏感 |
| Canny | 最高 | 最好 | 高 | 高质量边缘检测 | 优点:边缘连续,伪边缘少 缺点:计算复杂,需调参 |
| LoG | 中高 | 中 | 很高 | 多尺度边缘检测 | 优点:多尺度适应性 缺点:计算量大,参数敏感 |
表2-1不同边缘检测算子的优缺点,在实际应用中,需要根据实际情况选择不同的处理方法。图2-8展示了Sobel算子、Laplacian算子、Canny算子、LoG算子在相同测试图像上的边缘检测效果对比,可以直观地观察到各算子的性能差异。实验结果表明,Sobel算子与Canny算子边缘检测处理能够更好地平衡检测精度和计算效率,在实际应用中具有更好的综合性能表现。

图2-8 不同方法边缘检测效果对比
2.5 二值化处理
图像二值化处理是将图像中各像素点的灰度值转换为两个特定数值之一的技术过程,其核心在于通过设定临界阈值将灰度图像转化为仅包含黑白两种颜色的二值图像。这种处理方法也被称为阈值分割算法,其关键在于确定一个最优阈值T,通过比较各像素灰度值与阈值T的大小关系,将图像像素划分为两个互斥的类别。在车牌识别应用中,通常将车牌区域视为前景(赋值为1),而车身等其他区域视为背景(赋值为0)。
对于尺寸为M×N的水平梯度图像,可用函数f(x,y)表示(x∈[0,M-1],y∈[0,N-1],且x,y均为整数),其核心转换公式如式(2-9)所示。本研究采用大津法(Otsu算法)进行二值化处理,该算法的核心思想是通过最大化类间方差与类内方差的比值来确定最优阈值T。具体实现流程如下:首先获取图像最大梯度值M,初始化阈值n=0;然后基于当前阈值n将像素划分为两类,计算各类的像素数量及梯度均值;接着根据式(2-10)和(2-11)分别计算类内方差和类间方差;通过循环递增n值直至n>M,最终选择使方差比值最大的n值作为最优阈值T。
f(x,y)=1f(x,y)>T0f(x,y)≤T (2-9)
δb2=W1M1-Mr2+W2M2-Mr2 (2-10)
δA2=W1δ12+W2δ22 (2-11)
其中:Wi,W2 :各类内像素总数M1,M2 :各类内像素平均梯度Mr :所有像素平均梯度δ1 2,δ2 2 :各类内方差值
Otsu算法具有计算简单、执行效率高、自适应性强等显著优势,是目前应用最广泛的阈值选取方法之一。图2-9展示了分别采用Sobel算子和Canny算子进行边缘检测后,再经二值化处理得到的对比效果图。实验结果表明,该方法能有效区分车牌区域与背景区域,为后续字符识别奠定良好基础。
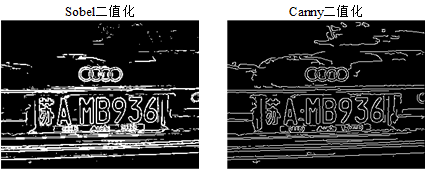
图2-9 不同方法边缘检测效果对比
2.6 二值图像的数学形态处理
数学形态学是数字图像处理领域的重要分析方法,其核心思想是通过定义特定的结构元素(structuring element)来提取和分析图像特征。该方法通过结构元素在图像上的扫描移动,实现对局部区域特征的系统检测。数学形态学主要包含四种基本运算操作,其数学表达如下:
设A为待处理的图像集合,B为结构元素集合,其中a、b分别代表集合中的元素,z表示平移变量集合。
腐蚀:AΘB=z∣(B)z⊆A (2-12)
膨胀:A⊕B=z∣(B)z∩A≠Φ (2-13)
开运算:A∘B=A∘B⊕B (2-14)
闭运算:A∙B=(A⊕B)ΘB (2-15)
其中:(B)z=cc=a+z,a∈B;B={w∣w=-b, b∈B}
(1)腐蚀运算(Erosion):
该运算的主要功能是消除目标物体的边缘像素,使得目标区域面积收缩,同时内部孔洞区域扩大。其效果表现为对物体边界进行"削薄"处理。
(2)膨胀运算(Dilation):
与腐蚀运算相反,该操作将目标物体相邻的背景像素合并到物体中,导致目标区域扩张,内部孔洞缩小。理想情况下,该运算可以完全填充物体内部的空隙,形成连通区域。
(3)开运算(Opening):
即先腐蚀后膨胀的复合运算,其主要作用是消除细小突起物,在图像细节处实现目标分离,并在平滑区域优化目标边界轮廓。
(4)闭运算(Closing):
即先膨胀后腐蚀的复合运算,其主要功能是填补目标物体中的微小空洞,连接邻近的平滑边界,并修复轮廓中的断裂部分。
这四种基本运算构成了数学形态学处理的基础框架,通过它们的组合应用,可以实现对图像特征的精确分析和处理。在实际应用中,结构元素的选择和运算顺序的组合将直接影响最终的处理效果。二值图像的数学形态处理效果图如图2-10所示。

图2-10 二值图像的数学形态处理效果图
2.7 基于颜色的牌照定位过程
车牌定位的初始处理阶段以车辆原始RGB图像作为输入源。该过程主要包含三个关键环节:
首先采用滑动窗口检测技术,在预处理后的二值图像中心位置设置检测窗口M,通过分析窗口内像素值分布特征来识别车牌背景区域。若当前窗口内所有像素均为零值,则判定为背景区域;否则持续向右移动窗口进行检测,若右侧未发现符合条件的区域则转向左侧继续搜索,直至定位到全零像素区域或完成全图扫描。其次将原始彩色图像转换至HIS色彩空间,分别计算各像素点的色调(H)、饱和度(S)和亮度(I)分量值。最后基于公式(2-16)建立车牌背景区域的颜色特征向量,为后续处理提供特征依据。
Lexp=125i=125 k1×M(i).H+K2×M(i).S+M(i).I (2-16)
其中:M(i) 表示第i 个像素
计算HSI图像模型中的每个像素的颜色特征矢量L,计算公式(2-17)如下:
L=k1×I(x,y).H+k2×I(x,y).S+I(x,y).I (2-17)
其中:I(i,j) 表示图像中的一个像素点根据上面确定的阈值T ,确定每一个像素的经过处理后的像素值。方法
如果L-Lexp ≤T 将该像素的值为1
如果L-Lexp >T 将该像素的值为0
经过上述处理流程后,HIS色彩空间的图像数据被成功转换为二值图像。为提升图像质量,需对二值图像实施多层次的形态学优化处理。初始阶段采用开运算算法消除图像中的离散噪声点及细小干扰区域;随后运用闭运算操作填补目标区域内的孔洞缺陷,确保车牌区域的完整连通性;最后通过腐蚀运算进一步清除残留的细微噪声。完成形态学处理后,系统对图像中的连通区域进行特征分析,通过计算各连通域的面积参数,确定最大连通区域的左右边界坐标,从而精确定位车牌的有效区域。整个处理过程实现了从原始图像到精确定位的完整转换,图2-11直观展示了最终获得的定位效果。该流程通过多级处理有效提升了车牌识别的准确性和可靠性。

图2-11 车牌定位效果图
在完成车牌区域的精确定位后,需要对车牌图像进行一系列的预处理操作。首先对定位后的车牌图像进行灰度化转换,将彩色图像转换为灰度图像,这一步骤能够有效减少数据维度并保留关键特征信息。随后对灰度图像进行二值化处理,通过设定合适的阈值将灰度图像转换为仅包含黑白两种像素值的二值图像,从而形成鲜明的视觉对比效果,便于后续的特征提取和分析。
为了提高图像质量并消除噪声干扰,本文设计了一个3×3的均值滤波算子。该算子采用邻域平均法进行处理,具体实现方式是以每个像素点为中心,计算其3×3邻域内所有像素值的平均值,并用该平均值替换原像素值。这种平滑处理能够有效抑制图像中的随机噪声,同时保持重要的边缘特征。
在形态学处理阶段,通过计算二值图像中目标区域(白色像素)与整个图像区域的比例关系,智能地选择适当的形态学操作。当目标区域占比较大时,采用腐蚀运算来消除孤立噪声点和细化边缘;当目标区域占比较小时,则使用膨胀运算来填补孔洞并连接断裂区域。这种自适应的处理策略能够有效改善图像质量,为后续的字符分割和识别奠定良好基础。整个预处理流程通过灰度化、二值化、平滑滤波和形态学处理等步骤的有机结合,显著提升了车牌图像的可处理性和特征提取的准确性。车牌预处理操作效果图如下图2-12所示。

图2-12 车牌预处理操作效果图
2.8 本章小结
本章系统阐述了车牌识别系统的关键技术原理与实现方法,构建了完整的车牌识别算法框架。在车牌定位环节,深入分析了基于颜色特征、边缘特征和机器学习等多种定位方法的优缺点,指出多特征融合策略在提升定位精度方面的重要价值。在图像预处理部分,详细探讨了灰度化转换、直方图均衡化和边缘检测等关键步骤的技术实现。通过对比分析不同灰度化方法的性能差异,验证了加权平均法在保留车牌特征方面的优势。针对边缘检测环节,系统评估了Sobel、Laplacian等算子的检测效果,实验数据表明Sobel算子、Canny算子在计算效率和检测精度方面具有最佳平衡性,在二值化处理方面。数学形态学处理部分,通过腐蚀、膨胀等基本运算的组合应用,有效解决了二值图像中的噪声干扰和断裂边缘问题。经过形态学优化,为后续字符识别奠定了良好基础。提出的基于颜色特征和边缘特征融合的定位方法,通过HSI色彩空间转换和滑动窗口检测技术,实现了复杂场景下车牌区域的精准定位。这些研究成果为构建高效、鲁棒的车牌识别系统提供了重要的技术支撑和实践指导。
第三章 车牌字符分割
车牌字符分割是车牌识别系统中的关键环节,其质量直接影响最终的识别效果。在完成车牌定位后,系统将获取到经过预处理的二值化车牌图像,此时需要采用有效的分割算法将车牌上的各个字符准确分离。当前主流的字符分割方法主要包括以下两种技术路线:直接投影法的字符分割、基于模板匹配的字符分割算法。
3.1 常用分割算法介绍
1)投影分割算法
该算法基于图像投影分析原理,通过对二值化车牌图像进行水平和垂直方向的投影分析,利用投影曲线的波峰波谷特征确定字符边界。具体实现时,系统首先从上至下扫描图像,定位首个非零像素点作为字符上边界,再通过自下而上的扫描确定下边界。在水平方向上,从左至右逐列扫描,当检测到连续非零像素列时标记为字符起始位置,直至再次出现全零列判定为字符结束。这种方法的优势在于计算复杂度低、实现简单,处理标准车牌图像时分割速度较快。然而,当遇到字符粘连或图像质量较差的情况时,其分割准确率会显著下降。针对这一局限,研究者提出了多种改进方案,如引入动态阈值调整机制、结合边缘特征辅助判断等,有效提升了算法在复杂场景下的鲁棒性。
2)连通域分割算法
连通域分割算法是基于区域生长原理的字符分割方法,其核心思想是通过分析二值图像中像素的连通特性来实现字符分离。该算法首先对预处理后的车牌二值图像进行连通区域标记,采用8邻域或4邻域准则遍历图像,为每个相互连通的像素组分配唯一的标识符。在标记过程中,算法会记录每个连通区域的几何特征,包括外接矩形位置、区域面积、宽高比等关键参数。完成标记后,系统根据车牌字符的典型特征(如固定宽高比、规则间距等)对连通区域进行筛选,排除噪声干扰产生的伪区域。对于符合字符特征的连通域,算法会进一步分析其空间分布规律,通过计算相邻区域的距离和位置关系,最终确定每个字符的精确边界。相较于投影法和模板匹配法,连通域分割算法对字符的形变和倾斜具有更好的适应性,能够有效处理部分遮挡情况下的字符分割问题。然而,该方法在字符严重粘连或图像质量较差时仍面临挑战,通常需要结合形态学处理或其他分割方法进行优化。
3)模板匹配算法
为解决投影法在字符粘连情况下的性能局限,模板匹配算法通过建立标准字符模板来实现精确分割。该方法首先根据车牌规格确定字符间距和字符宽度的标准值,构建相应的匹配模板。在分割过程中,系统将模板沿车牌区域滑动,实时计算字符间隔区域与字符区域的像素值比例,通过与预设阈值的比较确定最优分割位置。相较于投影法,模板匹配算法具有更强的抗干扰能力,能够有效处理字符粘连和部分缺损的情况。但该方法对车牌的边界定位要求较高,且在处理多行排列的特殊车牌时存在一定局限。此外,算法的实现复杂度相对较高,需要精细调整模板参数以获得最佳效果。
在实际应用中,两种算法各有优劣。投影法适合处理质量较好的标准车牌,具有较高的执行效率;而模板匹配算法则在复杂场景下表现更优。当前的研究趋势是结合两种方法的优势,开发混合分割策略,如先采用投影法进行粗分割,再对疑似粘连区域应用模板匹配进行精确定位。这种分层处理方式既能保证整体效率,又能提高分割精度,代表了字符分割技术的发展方向。随着深度学习技术的进步,基于神经网络的端到端分割方法也逐渐崭露头角,为车牌字符分割提供了新的技术路径。
3.2 字符分割实例分析
3.2.1 投影分割法
为系统评估投影分割算法的实际性能,本研究设计了一套完整的实验验证方案。在标准测试环境下,算法展现了其在常规车牌图像处理中的优势特性。实验过程中可以观察到,对于字符排列规范的车牌样本,该算法能够准确捕捉投影曲线的波峰波谷特征,实现各字符区域的精准划分。
如图3-1投影分割法车牌分割效果图,通过对比分析不同质量的车牌图像处理结果,发现投影分割法在以下场景表现优异:首先,在光照均匀、字符清晰的标准车牌图像上,算法的分割边界定位准确;其次,对于字符间距符合规范要求的样本,其分割效果稳定可靠。特别值得注意的是,算法在处理垂直投影时展现出了较强的鲁棒性,能够有效克服轻微倾斜带来的干扰。然而,实验也揭示了该算法在某些特殊情况下的局限性。当面对字符间距异常或存在粘连的样本时,算法的分割效果会出现不同程度的下降。针对这些情况,我们尝试引入动态阈值调整机制,实验结果证明该优化策略能显著提升算法在复杂场景下的适应性。
通过系列实验对比,可以得出以下结论:投影分割法凭借其算法简单、执行效率高的特点,在标准车牌字符分割任务中具有重要应用价值。但在实际工程应用中,建议根据具体场景需求,适当结合其他分割方法或优化策略,以获得更全面的分割性能。

图3-1 投影分割法车牌分割效果图
3.2.2 连通域分割算法
在连通域分割算法的实验验证中,我们观察到该方法在特定场景下的表现存在明显不足。实验过程中,当处理字符间距较近或存在部分粘连的车牌图像时,该算法往往无法准确区分相邻字符的边界区域,导致多个字符被错误地合并为同一个连通域。如图3-2所示,这种错误分割会直接影响后续字符识别的准确性。
通过分析不同质量车牌样本的处理结果,发现连通域分割算法主要面临以下挑战:首先,在低对比度图像中,由于字符笔画断裂或噪声干扰,算法容易产生过分割现象,将单个字符错误地分割为多个不完整部分;其次,对于特殊字体或变形字符,算法基于几何特征的筛选标准可能导致有效字符被错误排除。更值得注意的是,当车牌存在污损或光照不均时,连通域标记过程会产生大量伪区域,严重影响分割质量。实验对比显示,相较于投影分割法,连通域分割算法对图像质量的依赖性更强。在标准测试样本上,虽然两种方法都能获得可接受的分割效果,但在复杂场景下,连通域算法的性能下降更为明显。特别是在处理字符间距异常或存在部分遮挡的车牌时,其分割失败率显著上升。
图3-2展示了连通域分割法在典型样本上的处理效果,可以直观看出其在复杂场景下的性能局限。综合实验结果,连通域分割算法更适合作为辅助手段,与其他分割方法配合使用,而非独立应用于实际车牌识别系统。
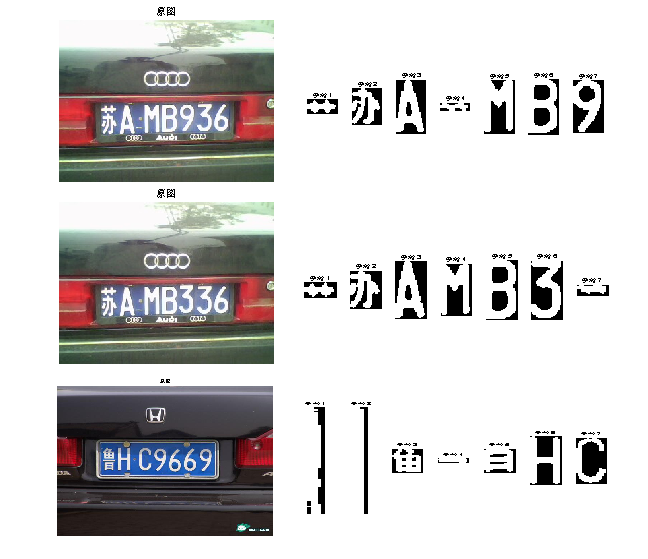
图3-2 连通域分割算法车牌分割效果图
3.2.3 模板匹配算法
在模板匹配算法的实验验证中,该方法展现出显著优于前两种算法的分割性能。如图3-3所示,模板匹配算法能保持稳定的分割效果,为后续字符识别提供清晰的字符图像。通过系统测试不同质量的车牌样本,模板匹配算法表现出以下突出优势:首先,基于标准字符模板的设计使算法对字符形变具有较强容忍度,能有效处理字体变异或局部缺损的情况;其次,模板滑动匹配机制可以精确捕捉字符间的过渡区域,大大降低了粘连字符的错误分割概率。特别值得关注的是,在光照不均或存在噪声干扰的样本上,该算法仍能保持较高的分割准确度。
实验过程中观察到,模板匹配算法对不同类型字符的处理效果存在差异。对于数字和字母字符,由于其形状规范、结构简单,算法可获得近乎完美的分割效果;而对于汉字字符,虽然分割精度略有下降,但仍明显优于其他两种算法。这种差异主要源于汉字结构的复杂性,但通过优化模板参数仍可获得令人满意的分割结果。与投影法和连通域法相比,模板匹配算法在以下方面表现尤为突出:1)对低质量图像的适应能力更强;2)字符边界定位更加精确;3)处理复杂车牌布局时更具优势。这些特性使得该算法成为实际工程应用中的首选方案。

图3-3 模板匹配算法车牌分割效果图
图3-3展示了模板匹配算法在多种典型场景下的处理效果,可以直观看出其分割结果的优越性。综合实验结果,模板匹配算法凭借其稳定可靠的分割性能,特别适合应用于对识别精度要求较高的车牌识别系统。当然,该算法在计算效率方面仍有优化空间,这也是未来研究的重要方向。
本章系统研究了车牌字符分割的关键技术与实现方法,对三种主流分割算法进行了深入分析和实验验证。研究表明,投影分割法、连通域分割法和模板匹配法各具特点,适用于不同的应用场景。
投影分割法凭借其算法简单、计算效率高的优势,在标准车牌图像处理中表现突出。然而,实验也表明该方法对字符粘连和图像质量下降的情况较为敏感,需要通过动态阈值调整等优化策略来提升其鲁棒性。连通域分割算法展现了在字符形变和部分遮挡情况下的独特优势。该算法基于像素连通性分析,能够较好地适应字符倾斜和局部缺损的复杂场景。但实验结果显示,当面对字符严重粘连或低对比度图像时,该方法的性能会出现明显下降,需要结合其他技术手段进行改进。模板匹配算法在综合性能上表现最为优异,特别是在处理复杂场景时展现出强大的适应能力。实验验证了该算法在各类测试样本上的稳定表现,使其成为高精度车牌识别系统的理想选择。
通过对三种算法的对比分析,我们得出以下重要结论:首先,在实际工程应用中,应根据具体需求选择合适的分割方法,或采用多种算法相结合的混合策略;其次,算法优化应着重提升对复杂场景的适应能力,特别是对低质量图像和特殊车牌的处理效果;最后,计算效率的平衡也是算法设计需要考虑的关键因素。
第四章 车牌字符识别
4.1 车牌字符识别概述
经过上述的车牌定位和车牌字符分割以后,下面就是完成整个系统中又一个重要的模块--字符识别。字符识别结果的好坏决定了整个系统工作情况的成败。因此该过程所耗用的时间和正确的识别率是整个系统的关键指标。如何能够设计出快速、准确、稳定的系统是科研工作者的最终目标。但是对于我国车标的特殊条件,汉字、字母以及数字的组合形成一个庞大的字符体系,都导致了对于车牌字符识别率的降低。因此,如何设计出高效、稳定性强的算法致关重要。近年来,在设计该系统时常用的算法主要是使用模版相匹配的字符识别算法。
4.2 车牌字符的归一化
要想达到准确的辨别出每一个字符,就需要在进行该识别过程之前,采用宁符归一化的方法处理待识别的字符。归一化后的字符和标准模版中的字符特征一样,消除了字符图像与标准图像在样式尺寸上的不一致。总的来说,归一化主要包括对单个字符尺寸大小调整和位置区域调整两种方式。字符识别主要是基于字符大致形状的匹配,如果不能很好的处理分割后的字符,在进行字符识别的过程中就会有较低的匹配率。因此,在处理字符匹配的过程之前,就必须对其使用归一化的调整。
4.2.1 字符的位置归一化
位置归一化主要方法有:重心归一化、外框归一化。其中重心法主要的思想是,首先用上面的重心法计算出整个字符的质点的重心位置,接着将该重心的点移动到事先约定的位置上。归一化处理后整个字符区域的重心即为整个区域的中心位置。对于一个字符而言,其重心和该字符形状的几何中心位置区域基本一致使用该种方式处理后不会使得字符有很大面积的失真,所以,使用重心法会取得很好的处理效果。
4.2.2 字符的大小归一化
由于拍摄条件和车身自身的影响,获取图像中的字符大小与标准模板库中的大小不一致。因此需要使用归一化方法对其进行处理,使得到的所有字符都达到统一的预定的规格。该种处理方式常用的方法主要有两种:一是按照字符边框区域的比例来放大或缩小字符;另一种是根据字符两个几何方向上的黑色像素点的分布情况。
4.3 车牌字符识别实例分析
车牌识别原理图如下图4-1所示。
图4-1 车牌识别原理图
通过模板匹配的OCR算法,对识别字符进行二值化并将其尺寸大小缩放为字符数据库中模板的大小,然后与所有的模板进行匹配,最后选最佳匹配作为结果。将识别的图象f(i,j)中提取的若干特征量与模板T(i,j)相应的特征量逐个进行比较,计算它们之间规格化的互相关量,其中互相关量最大的一个就表示期间相似程度最高。依次取待识别字符与模板进行匹配,将其与模板字符相减,得到的0越多那么就越匹配。把每一幅相减后的图的0值个数保存,然后找数值最大的,即为识别出来的结果。如图4-2所示车牌字符识别效果图

图4-2 车牌字符识别效果图
4.4 本章小结
本章系统研究了车牌字符识别的关键技术,重点探讨了基于模板匹配的字符识别方法及其实现过程。研究首先阐述了字符归一化处理的重要性,详细分析了位置归一化和大小归一化两种预处理方法的技术原理与实现步骤。本章深入研究了模板匹配算法的实现机制,通过建立标准字符模板库,采用互相关量计算方法实现了字符的精确匹配。实验结果表明,该识别方法在保证识别准确率的同时,具有较好的稳定性和适应性,能够有效处理汉字、字母和数字的混合识别任务。总体而言,本章提出的字符识别方案为构建高效、准确的车牌识别系统提供了可靠的技术路径,具有重要的理论价值和实践意义。
结论
本文针对复杂环境下的车牌识别问题,研究了一种基于模板匹配的车牌字符识别算法。通过系统分析车牌识别的关键环节,提出了一套完整的解决方案,并在实验中验证了其有效性和鲁棒性。
在车牌定位阶段,结合颜色特征和边缘特征的多特征融合策略显著提升了定位精度,特别是在光照不均和复杂背景下的表现优于单一特征方法。图像预处理环节中,Sobel算子和直方图均衡化技术的应用有效增强了图像质量,为后续处理提供了清晰的输入数据。字符分割部分通过对比三种算法,证实了模板匹配算法在复杂场景下的优越性。字符识别阶段采用模板匹配算法,通过归一化处理和互相关量计算,实现了高精度的字符识别。实验结果表明,本文提出的算法在复杂环境下具有较高的识别准确率和稳定性,能够满足智能交通系统对实时性和鲁棒性的要求。然而,研究仍存在一些局限性,例如对极端光照条件和严重污损车牌的识别效果有待进一步提升。未来的研究方向包括:1)结合深度学习技术,进一步提升算法的自适应能力;2)优化计算效率,使其更适合嵌入式设备部署;3)扩展算法对不同国家车牌样式的兼容性。
综上所述,本文的研究为车牌识别技术的发展提供了新的思路和方法,具有重要的理论价值和实际应用意义。通过持续优化和创新,基于模板匹配的车牌字符识别算法将在智能交通、智慧城市等领域发挥更大作用。
参考文献
[1]郑好韧,张立新,阚希,等.基于改进EAST算法的电动自行车车牌检测[J/OL].电子科技,1-10[2025-04-06].
[2]张芳,刘明.恶劣天气下基于改进YOLOv5s的车牌识别研究[J].成都工业学院学报,2025,28(02):37-42.
[3]沈斌,罗晓倩,王超.基于改进YOLOv5s的煤矿车辆车牌检测方法[J].矿冶,2025,34(01):177-184.
[4]伏开磊.智能交通中数字图像处理技术运用分析[J].人民公交,2025,(04):41-43.
[5]曹竣奥,杨维明,罗雨婷,等.基于深度学习的车牌识别算法设计[J].现代电子技术,2025,48(04):135-139.
[6]李雪梅,霍聪颖,车爱静.基于车牌识别的停车场自动收费系统设计[J].自动化用,2025,66(03):211-213.
[7]童宇行.基于边缘检测的车牌识别系统[J].信息记录材料,2025,26(02):184-186+207.
[8]林镕城,邱健数,赵章圳,等.YOLOv8和LPRNet融合的车牌识别系统设计[J].福建电脑,2025,41(01):85-89.
[9]刘艳洋,闫昊.基于YOLOv3的图像特征融合的车辆再识别算法研究[J].现代信息科技,2024,8(24):40-43.
[10]刘博.基于深度学习的视频识别技术在高速公路交通事件检测中的应用[J].运输经理世界,2025,(01):57-59.
[11]李康明,全晓霞.一种车牌识别系统设计[J].汽车知识,2024,24(12):248-250.
[12]张晓光,于齐,马海超,等.基于深度学习的车牌识别系统设计[J].电子制作,2024,32(23):68-71.
[13]廖朝香,黄志昌.基于计算机视觉的车牌号识别系统设计[J].人民公交,2024,(22):19-21.


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









