






MySQL基本命令 详见:https://blog.csdn.net/qq_44647926/article/details/90069631
MySQL优化:https://editor.csdn.net/md/?articleId=104267264
MySQL面试:https://www.zhihu.com/search?type=content&q=mysql
扩展:https://blog.csdn.net/qq_44647926/article/details/93654722
思维导图:待办
1、什么是sql?---->结构化查询语言。它只是一个标准,制定了数据库的一些规则
sql语言中分为四大类:
DDL:数据库定义语言
DML:数据库操作语言
DQL:数据库查询语言【重点】
DCL:数据库控制语言
DDL:数据库定义语言
包含了:操作数据库和数据表的,对结构的操作。
DML:操作数据,对数据的增、删、改
增:
情况1,增加所有数据:insert into 表名 values(字段1值,字段2值,字段3值...);
情况2,增加部分数据:insert into 表名(字段名1,字段名2) values(值1,值2);
删:delete from 表名 where 字段 = 值?
改:update 表名 set 字段 = 值 where 条件?
DQL:数据库查询语句:
条件查询、模糊查询、联合查询、子查询、连接查询
DCL:数据库控制语言
操作权限:revoke
2、数据库设计层面
1)数据库的三大范式
第一范式:保证每一列原子性,不可拆分(只要是关系型数据库,一定满足第一范式)
第二范式:保证实体的唯一性(保证能够唯一区分出一行数据)。
第三范式:确保表中的字段和主键直接相关,而不是间接相关(不能出现传递依赖)。
2)实体之间的关系
1)一对一的关系:一张表中只能唯一对应另外一张表中的数据
2)一对多的关系:一张表中一行数据可以对应另外一张表中的多行数据
3)多对多的关系:一张表中的一行数据可以对应另外一张表中的多行数据,反过来,
另外一张表中的一行数据也可以对应一张表中的多行数据。
如果在实际工作中遇到了多对多的关系,一般都是会生成第三张关系表。
二、操作数据库的知识
1、数据类型
数值型:
int:整形
double:小数类型
decimal:定点小数
字符串:
char:定长字符串,效率高,但是会造成一定的空间浪费
varchar:变长字符串,效率低,但是会节约一定的空间
时间类:
timestamp
datatime
2、运算符:基本不用复习
不等于:!=,在数据库里面建议使用<>
在数据库比较和赋值:=
建议:比较运算符 =
赋值运算符 :=
3、约束:
1)非空约束,该字段必须有值
2)默认值:如果在插入数据的时候,没有给值,则直接使用默认值
3)主键约束:用来唯一区分一行数据
4)外键约束:用来约束表与表之间的关系。
5)自增长:可以设置数据库种的行数自动增长
6)自定义约束:存储过程,触发器,触发器体现的是最明显的。(比如联级操作)
比如:如果是论坛式的网站,我们删除一条消息的时候,会使用触发器将该消息
下面的所有评论也随之删除。
重点查询:DQL
1、简单查询SELECT
一条简单的查询语句:SELECT * FROM 表名;
2、条件查询:WHERE
SELECT * FROM 表名 WHERE 字段 = 值;
3、模糊查询:为了优化数据库,所以一般不会使用模糊查询【根据书名查询时,可模糊查】
1)占位符:_
SELECT * FROM 表名 WHERE 字段 LIKE "张_";
2)占位符:%
SELECT * FROM 表名 WHERE 字段 LIKE "张%";
4、子查询:
1)可以将查询出来的结果作为新的表,然后再到这里面查询
SELECT * FROM (SELECT * FROM 表名 WHERE 字段 = 值) WHERE 字段 = 值;
2)IN子查询
SELECT * FROM 表名 WHERE 字段 in(值1,值2,值3.....);
3)NOT IN
SELECT * FROM 表名 WHERE 字段 NOT IN(值1,值2,值3.....);
4)EXISTS子查询
SELECT * FROM 表名 WHERE 字段 EXISTS(值1,值2,值3.....);
5)ALL子查询
SELECT * FROM 表名 WHERE 字段 > ALL(值1,值2,值3.....);
筛选出大于括号里面所有的值。通俗讲:大于最大值。
6)ANY子查询
SELECT * FROM 表名 WHERE 字段 > ANY(值1,值2,值3.....);
筛选出大于括号里面的任意一个值,通俗了讲:大于最小值
5、分组查询GROUP BY:根据什么字段进行分组
SELECT * FROM 表名 WHERE 字段 = 值 GROUP BY 字段;
注意:在mysql中,如果没有使用GROUP BY,则数据库默认分一个组。
6、排序查询ORDER BY
SELECT * FROM 表名 ORDER BY DESC(ASC);
7、筛选记录条数LIMIT
SELECT * FROM 表名 LIMIT 起始位,记录条数;
8、聚合函数查询:COUNT(字段),SUM(字段),AVG(字段),MIN(字段),MAX(字段);
SELECT 聚合函数() FROM 表名 ;
9、HAVING关键字:以聚合函数为条件进行筛选
SELECT * FROM 表名 GROUP BY 字段 HAVING 聚合函数() > 值;
10、DISTINCT:去掉字段中重复的数据
SELECT DISTINCT 字段 FROM 表名;
11、连接查询
2)内连接:[INNER] JOIN
SELECT * FROM 表1 INNER JOIN 表2 ON 表1.字段 = 表2.字段;
3)外连接:[OUTER] RIGHT JOIN或者[OUTER] LEFT JOIN
右外连接:SELECT * FROM 表1 RIGHT JOIN 表2 ON 表1.字段 = 表2.字段;
左外连接:SELECT * FROM 表1 LEFT JOIN 表2 ON 表1.字段 = 表2.字段;
12、联合查询:UNION和UNION ALL
去掉重复的数据:SELECT * FROM 表1 UNION SELECT * FROM 表2;
不去掉重复的数据:SELECT * FROM 表1 UNION ALL SELECT * FROM 表2;
三、数据库高级部分
1、视图
概念:视图是一张虚拟表,实际上,视图就是用的内连接,对于一些表本身需要多次
连接查询的时候,将其创建为视图,可以把视图当成一张单表查询,提高开发效率
优点:在实际开发中,可以将复杂的多表查询转换为单表查询,提高开发效率
缺点:1、只能做查询,不能做增、删、修改。
2、如果创建了视图,那么和视图相关的字段名不能做任何修改。
2、数据库 编程基础
注释:数据库中一般1-->on,0--->off;
数据库中变量分为几个?
1)系统变量
由数据库中提供的变量,称为系统变量,自添加系统变量,以2个@开始的为系统
一般不建议添加和修改系统变量。
-|查询所有的系统变量:SHOW VARIABLES
-|查询指定的系统变量:SELECT @@系统变量名
2)会话变量(用户变量)全局变量
只针对于本次会话使用,以@开始的变量。
-->添加一个会话变量:SET @变量名 =值;
-->查询会话变量:SELECT @变量名;
3)局部变量
在数据库代码块中(BEGIN和END)之间使用DECLARE定义的变量称为局部变量
4)数据库中的分支语句:
IF 判断条件 THEN
语句
END IF;
IF 判断条件 THEN
语句
ELSEIF 判断条件 THEN
语句
ELSE
语句
END IF;
5)数据库中的循环语句:
WHILE 判断语句 DO
循环的代码;
END WHILE;
跳出循环:
leave:跳出整个循环,离开的意思。
iterate:继续迭代,跳过本次循环,继续下一次循环。
注:当由多重循环的时候,跳出指定层次的循环,需要用到标记。
1.为什么学MySQL编程基础:
写代码阶段,用navcat工具。
维护数据库,用linux命令行。
(linux没有图形化界面,
服务器 和 数据库 都是在linux上面部署)
1.1 自定义函数:
a、先创建一个无参的自定义函数:
-- 如果有这个函数,就删除
drop function if exists hello;
-- 创建一个无参的函数
create function hello ()
-- 设置函数的返回类型
returns varchar (255)
begin-- 函数头
-- 中间的是函数体
return '一个简单的mysql函数'; -- 函数的返回值
end; -- 函数结尾
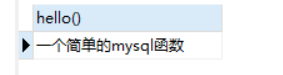
调用函数的方法:
select hello();
调用结果:
b、再创建1个带参数的自定义函数,
函数是把 传入的参数拼接成一个字符串返回出来
drop function if exists hello;
-- a、b 都是函数的参数
create function hello(a varchar(20),b varchar(20)) returns varchar (255)
begin
begin
-- declare 声明参数,default:设置声明参数的默认值
declare x varchar(255) default ' x ';
declare y varchar(255) default b;
declare c varchar(255) default ' 2017-01-02 ';
declare d varchar(255);
-- set 给声明的参数赋值
SET d = concat(x,a,b,y,c);
return d;
end;
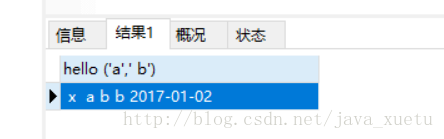
调用函数:
select hello ('a',' b');
结果是:
c、删除自定义函数:
DROP FUNCTION hello; -- hello是函数名。
2.事务
一.什么是事务
事务是应用程序中一系列严密的操作,所有操作必须成功完成,否则在每个操作中所作的所有更改都会被撤消。也就是事务具有原子性,一个事务中的一系列的操作要么全部成功,要么一个都不做。
事务的结束有两种,当事务中的所以步骤全部成功执行时,事务提交。如果其中一个步骤失败,将发生回滚操作,撤消撤消之前到事务开始时的所以操作。
二.事务的 四大特性=ACID
1 、原子性
事务是数据库的逻辑工作单位,事务中包含的各操作 要么都做,要么都不做。
2 、一致性
事务执行的结果必须是使 数据库从一个一致性状态变到另一个一致性状态。
因此当数据库只包含成功事务提交的结果时,就说数据库处于一致性状态。
如果数据库系统 运行中发生故障,有些事务尚未完成就被迫中断,这些未完成事务对数据库所做的修改有一部分已写入物理数据库,这时数据库就处于一种不正确的状态,或者说是 不一致的状态。
3 、隔离性
一个事务的执行不能其它事务干扰。即一个事务内部的操作及使用的数据对其它并发事务是隔离的,并发执行的各个事务之间不能互相干扰。
4 、持续性
也称永久性,指一个事务一旦提交,它对数据库中的数据的改变就应该是永久性的。接下来的其它操作或故障不应该对其执行结果有任何影响。
数据库系统必须维护事务的以下特性 ( 简称 ACID) :
原子性 (Atomicity)
一致性 (Consistency)
隔离性 (Isolation)
持久性 (Durability)
原子性 (Atomicity)
事务中的所有操作要么全部执行,要么都不执行;
如果事务没有原子性的保证,那么在发生系统
故障的情况下,数据库就有可能处于不一致状
态。
3.触发器:
1)创建触发器
触发时机:before,after
触发事件:insert,update,delete
CREATE TRIGGER 触发器名称 触发时机 触发事件 on 表名 for each row
BEGIN
触发器的代码;
END;
2)查询触发器
SHOW TRIGGERS;
3)删除触发器
DROP TRIGGER tri_1;
4.存储过程
1)创建过程:
CREATE PROCEDURE 存储过程名([参数列表])
BEGIN
存储过程的代码;
END;
特别说明:参数列表—>参数类型 参数名 数据类型
参数类型:IN OUT INOUT
IN:是讲存储过程外面的数据,传入到存储过程的里面调用。
OUT:是从存储过程的里面的数据传出到存储过程的外面使用,并且在存储过程里面
可以对用户变量修改,并且修改后的值可以传递到存储过程外面生效。
INOUT:结合IN和OUT的特点,
特别注意:
在存储过程执行到end结束的时候,
会倒回去检测参数的类型,
如果参数的类型是out或者inout,
那么会将判断该参数(形参)是否修改了传入的实际参数的值,
如果做了修改那么将修改后的值,覆盖实际参数的值。
例子:详见*1
【在这个例子中,就是将b,c修改后的值,存储过程执行结束之后,
将@num2和@num3覆盖。用b的值和c的值覆盖。】
2)查询过程:
SHOW PROCEDURE STATUS;
3)调用过程:
CALL 存储过程名称(参数列表);
4)删除过程:
DROP PROCEDURE 存储过程名;
详细:
*1
out数据类型 只要使用了存储过程 意味着 他的原有值 不存在了 一定会覆盖为 null
如果里面没有 修改变量值 就默认修改为 null
此处如果对传入的值num2不修改的话,执行完过程,再查询到的全局变量num2是null
 左边的全部代码:
左边的全部代码:
















 725
725











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









