







摘要
鉴于深度学习和预训练语言模型(LM)的成功,提出了一些基于 LM 的 KGC 方法。然而,大多数专注于对事实三元组的文本进行建模,而忽略了更深层次的语义信息(例如,拓扑上下文和逻辑规则)。为此,我们提出了一个统一的框架 FTL-LM 来融合(Fuse) KGC 语言模型(LM)中的拓扑(Topology)上下文和逻辑(Logical)规则,主要包括一种新的基于路径的拓扑上下文学习方法和一种用于软逻辑规则提取的变分期望-最大化(EM)算法。前者利用异构随机行走生成拓扑路径和进一步的推理路径,可以隐式地表示拓扑上下文,并可以由 LM 显式地建模。引入掩码语言建模和对比路径学习策略对这些拓扑上下文进行建模。后者通过具有两个 LM 的变分 EM 算法隐式地融合逻辑规则。具体地,在 E 步骤中,在由固定规则 LM 验证的观察到的三元组和有效隐藏三元组的监督下更新三元组 LM 。在 M 步骤中,我们修复了三重 LM 并微调了规则 LM 以更新逻辑规则。在三个常见的 KGC 数据集上的实验证明了所提出的 FTL-LM 的优越性,例如,在 WN18RR和FB15 k-237中,改进了最先进的基于 LM 的模型 LP-BERT ,分别达到了2.1%和3.1%Hits@10。
1. 介绍
一些 KG 嵌入方法,如 TransE 和 DistMult ,将实体和关系嵌入到连续向量空间中。然后,通过计算他们三元组的分数来完成推理。同时,为了对 KGs 的拓扑进行建模,提出了一些图卷积网络(GCN)来融合实体的邻居信息,例如 R-GCN 和 CompGCN 。尽管这两种方法取得了巨大的成功,但它们只利用了单独的三元组或邻居信息,而其算法忽略了实体和关系的内在语义。(Yao Ming, marriedTo, Ye Li)。例如,这些方法都没有考虑到图1中的实体姚明的实际语义,即他是一个出生在中国的 NBA 球员,这导致信息建模和推理性能不足。鉴于此,提出了一些基于语言模型(LM)的 KGC 方法,其中 KG-BERT 和 StAR 是代表性的研究。

他们将实体的文本描述和三元组的关系输入 LM 中,以计算分数,从而对该三元组的合理性进行建模。它们只对三元组的局部信息进行建模,而忽略了 KG 中的远距离信息关联,例如,拓扑上下文和逻辑规则(见图1中的示例)。拓扑上下文和逻辑规则对 KGC 都有重要作用,因为前者关注图的实体拓扑特征;后者强调关系之间的因果关联。
KG-BERT 预测三重可能性的示例:
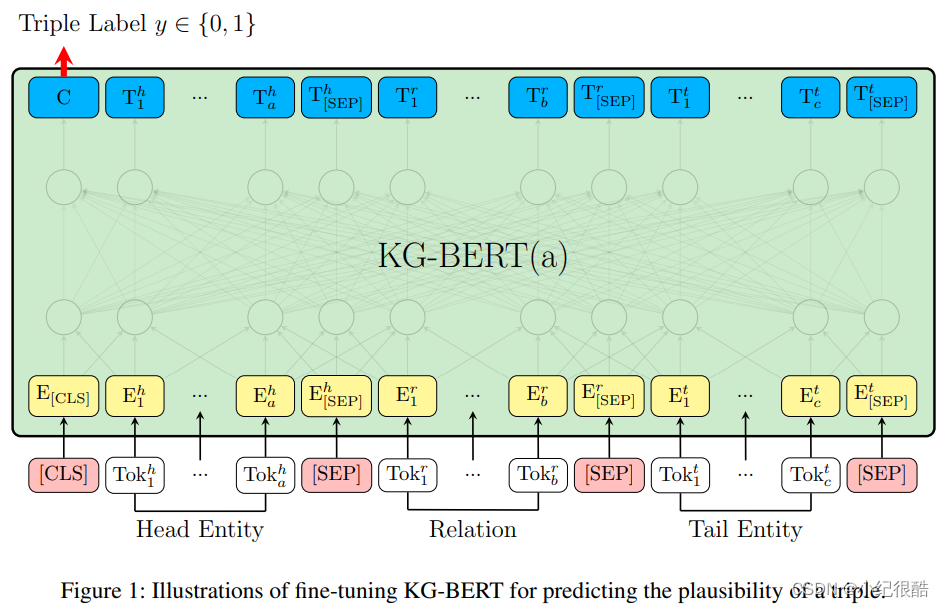
然而,在 LM 中融合拓扑上下文和逻辑规则是具有挑战性的。首先,KGs 中的拓扑上下文以图结构的形式表示,这明显不同于 LMs 所能处理的普通词序列。因此,不能使用 LM 直接对拓扑上下文进行建模。其次,KGs 的逻辑规则由规则置信度和原子公式组成,包含关系和变量,并表示抽象含义,例如,图1中的规则 。将逻辑规则融合到 LM 中是很困难的。一方面,KGs 中逻辑规则的谓词数量非常有限,规则的语义是通过它们的排列来表达的。因此,LM 也不能直接对逻辑规则进行建模。另一方面,没有带有语义置信度的标记逻辑规则可以作为 LM 的监督信息。
为了解决上述问题,我们提出了一种新的两阶段框架,用于隐式融合 KGC 语言模型中的拓扑上下文和逻辑规则,称为 FTL-LM。具体来说,对于拓扑上下文的学习,我们首先提出了一种异构随机行走算法来生成多样化的拓扑路径,该算法综合考虑了 KGs 中的各种因素,包括广度优先采样、深度优先采样和不同的关系。通过省略中间实体,这些拓扑路径被转化为推理路径,然后对它们的正实例和负实例进行采样。然后,采用掩码语言建模和对比路径学习策略对拓扑路径和推理路径的语义信息进行建模。此外,还引入了软逻辑规则提取技术来融合 LM 中的逻辑规则,利用两个结构相同但参数不同的 LM 分别进行三元组建模和规则建模。本文提出了一种变分期望最大化(EM)算法来迭代优化这两个 LM 。在 E 步骤中,三元组 LM 在观察到的三元组和有效的隐藏三元组的监督下更新,由固定规则 LM 验证。在 M 步骤中,我们修复了三重 LM 并微调规则 LM 以更新逻辑规则。通过上述策略,在 LMs 中隐式地融合了 KGs 的拓扑上下文和逻辑规则。主要贡献总结如下:
-提出了一个统一的框架 FTL-LM,该框架融合了 LM 中 KG 的拓扑上下文和逻辑规则。
-提出了一种新的基于路径的拓扑上下文学习方法,首先用异构随机行走算法生成拓扑路径,然后构造推理路径及其正负样本。然后,利用掩码语言建模和对比路径学习对这些拓扑上下文的语义进行建模。
-由于直接融合逻辑规则的困难,引入了一种变分 EM 算法,来交替优化分别用于三元组建模和规则建模的两个 LM 。通过使用这种软蒸馏,KGs 的逻辑规则首次被纳入 LM 。
-在两个常见的 KGC 数据集上的实验证明了我们的方法的优越性,这表明我们的 FTL LM 优于目前所有基于 LM 的方法。此外,消融研究证明了 FTL-LM 框架中每个模块的有效性。
2 相关工作
2.1 事实嵌入方法
2.2 拓扑嵌入方法
2.3 规则融合方法
2.4 基于 LM 的方法
3 初步结果
3.1 知识图谱和拓扑上下文
在 KG 中有两种主要类型的拓扑上下文:局部拓扑上下文和远距离拓扑上下文。局部拓扑上下文表示实体的最基本的图特征,如果两个实体在同一句子或段落中同时出现,那么它们之间就具有局部拓扑关系。尽管一些事实嵌入方法使用这种拓扑实现了很好的性能,但它们不足以对 KG 的综合语义进行建模。远距离拓扑上下文模型用于 KG 中的较长拓扑,例如图1中的路径:(Yao Ming,marriedTo,Ye Li,bornIn,Shanghai,placeIn,China)。它具有更复杂、更丰富的语义。为了更准确的 KG 嵌入,需要这两种类型的拓扑上下文。
3.2 知识图谱的逻辑规则
一般逻辑规则通过蕴涵符号将前提和假设之间的因果关系联系起来,即,前提假设。前提和假设都是由原子组成的,原子是通过谓词连接变量或常数的事实。由于 KG 结构的特殊性,我们引入了 Horn 规则。Horn 规则中的每个原子都表示为连接两个变量的谓词(即 KG 中的关系),例如,bornIn(X, Y)。同时,它将前提限定为一组原子,将假设限定为一个原子,分别称为规则体和规则头。此外,为了方便而不失一般性,封闭 Horn 规则要求其规则体通过共享变量传递连接,其中第一个和最后一个变量与规则头的对应变量相同。为了对不确定性进行建模,通常为每个 Horn 规则引入置信度 ε ∈ [0,1]。Horn 规则的长度是规则体中原子的数量。长度为2的封闭 Horn 规则示例如下所示:
(1)
其中, 是规则主体,
是规则头。通过将这些变量替换为 KG 中的具体实体,我们可以得到与原始 Horn 规则相对应的基本 Horn 子句。例如,规则(1)的基本 Horn 子句可以是:















 1747
1747











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









