







前言
编码不易,请支持原创!
一、爬取目标
网易云热歌榜飙升榜原创榜新歌榜
飙升榜 - 排行榜 - 网易云音乐 (163.com)
新歌榜 - 排行榜 - 网易云音乐 (163.com)
原创榜 - 排行榜 - 网易云音乐 (163.com)
热歌榜 - 排行榜 - 网易云音乐 (163.com)
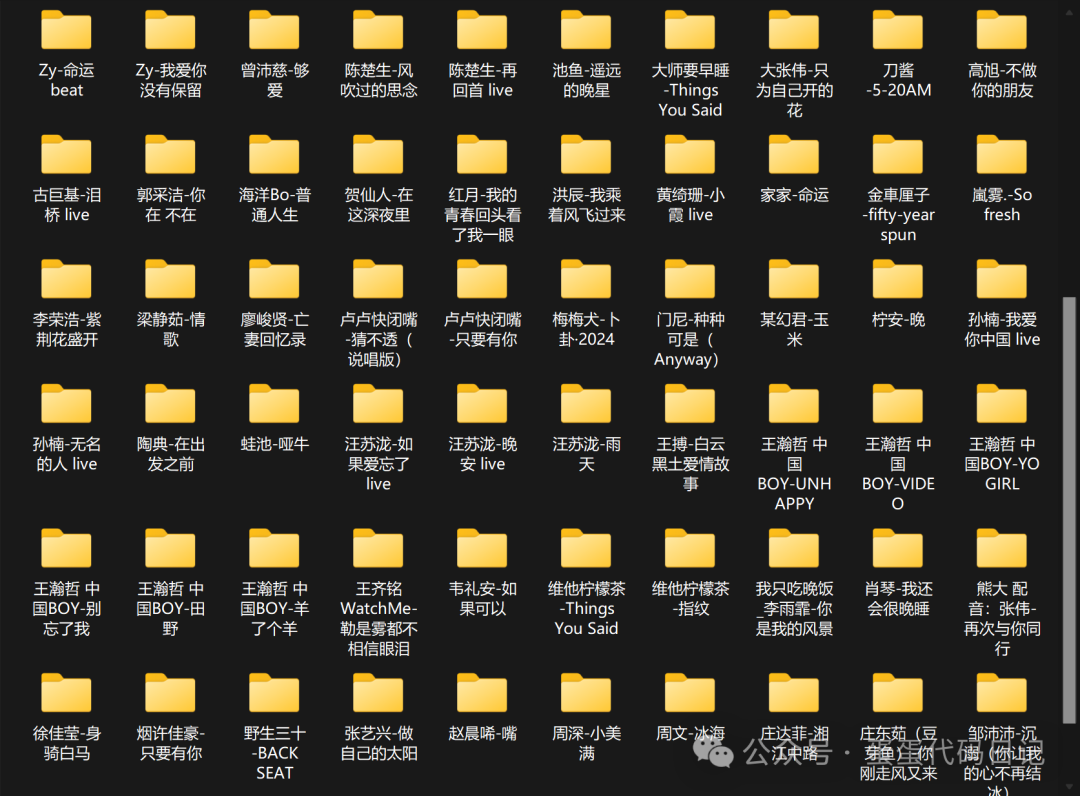
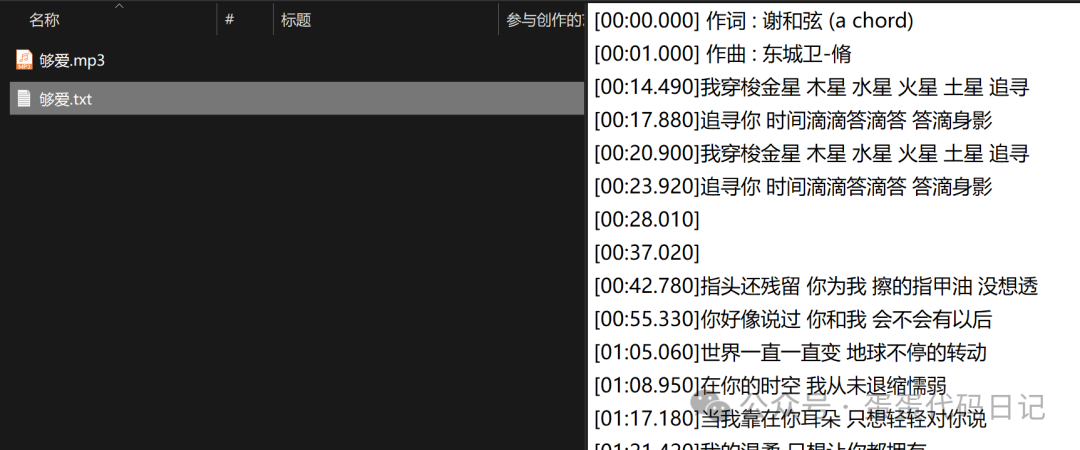
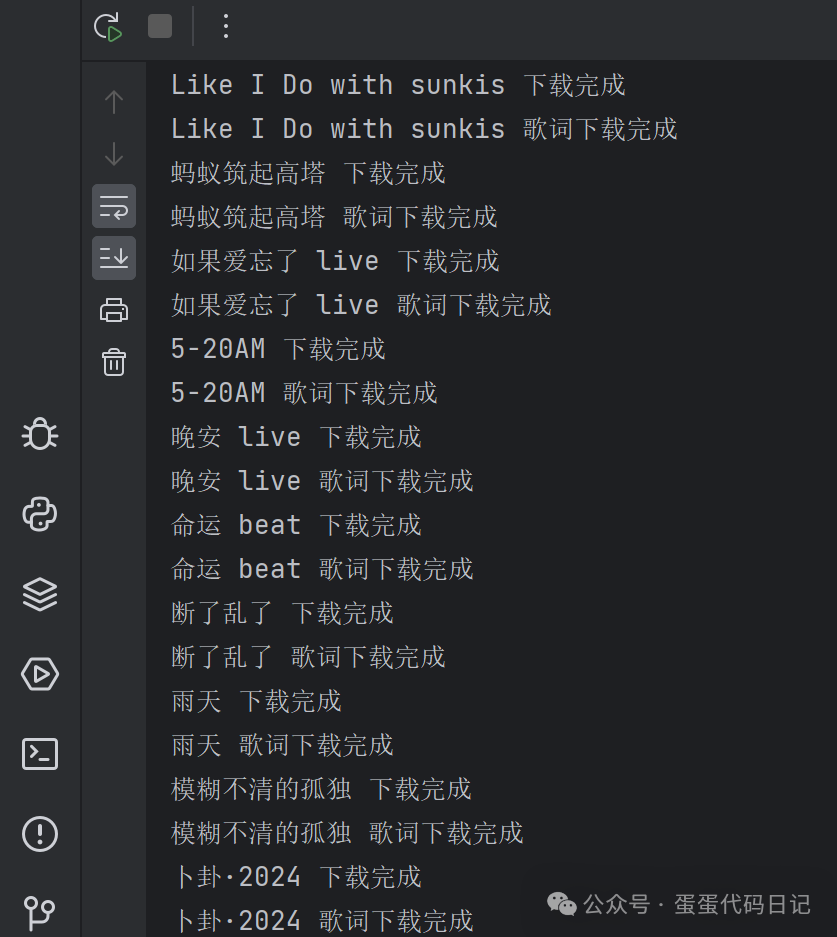
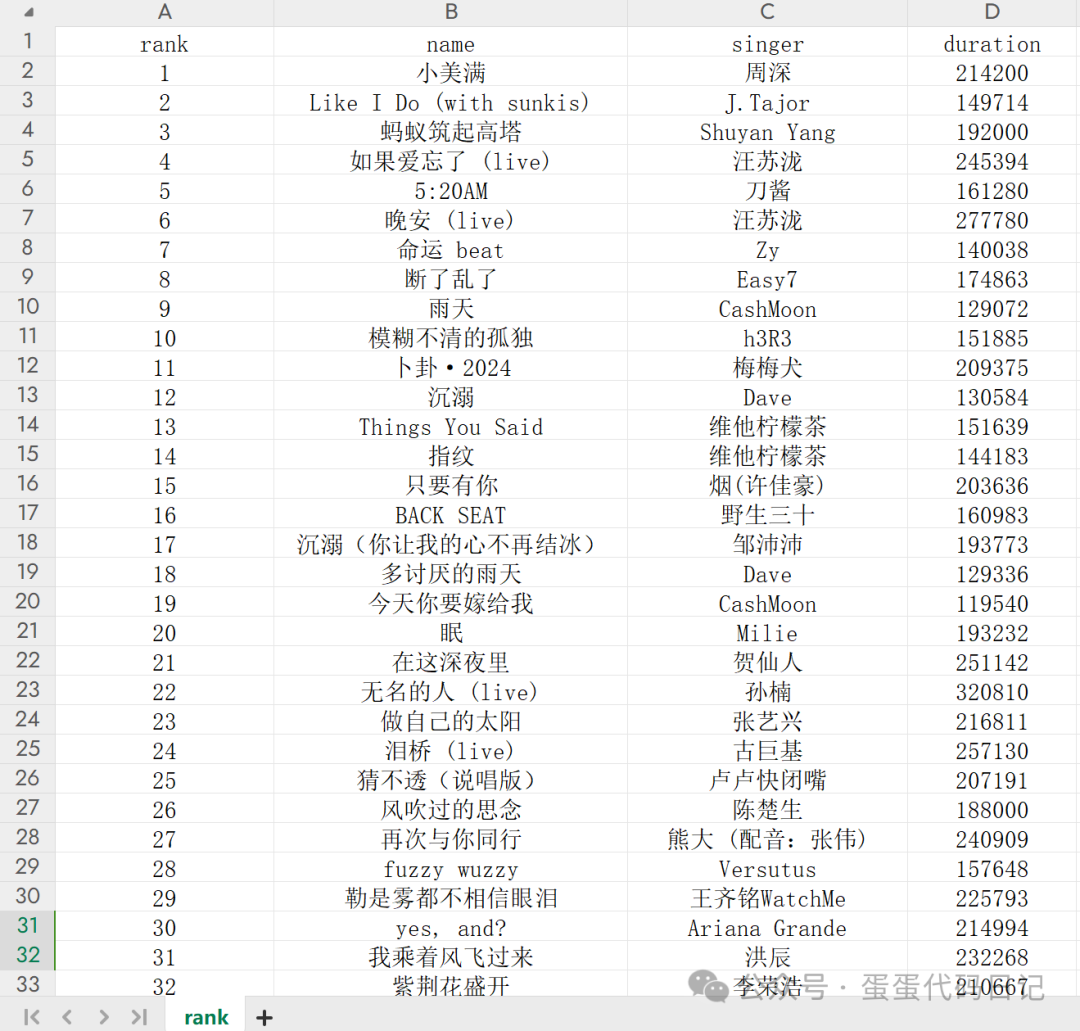
获取榜单里面所有歌曲的歌名、歌手名字、时长、歌词、音频文件
并形成csv、txt、mp3等结果输出
二、爬取结果展示
三、代码过程解析
1. 导入模块:
-
os:用于与操作系统交互,如创建文件夹。
-
time:用于时间相关的功能,但在这段代码中没有使用。
-
pandas:用于数据处理和CSV文件操作。
-
PyQuery:用于解析HTML文档。
-
requests:用于发送HTTP请求。
-
json:用于处理JSON数据。
-
csv:用于CSV文件的读写操作。
-
re:正则表达式模块,用于字符串匹配和替换。
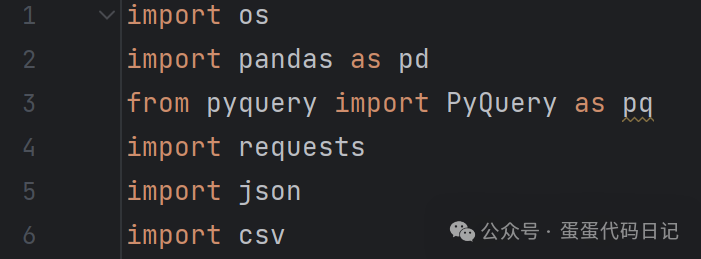
2. Wangyi_yun类:
-
这个类用于处理网易云音乐的数据。
-
__init__方法初始化类的实例,设置请求头和URL。
-
get_page方法发送HTTP请求,获取网页源代码。
-
get_data方法使用PyQuery解析HTML,提取歌曲信息。
-
get_download方法下载歌曲并保存到本地。
-
write_csv方法将歌曲信息写入CSV文件。
-
main方法是生成器,用于迭代歌曲信息。
-
fetchData方法用于获取所有歌曲数据。
-
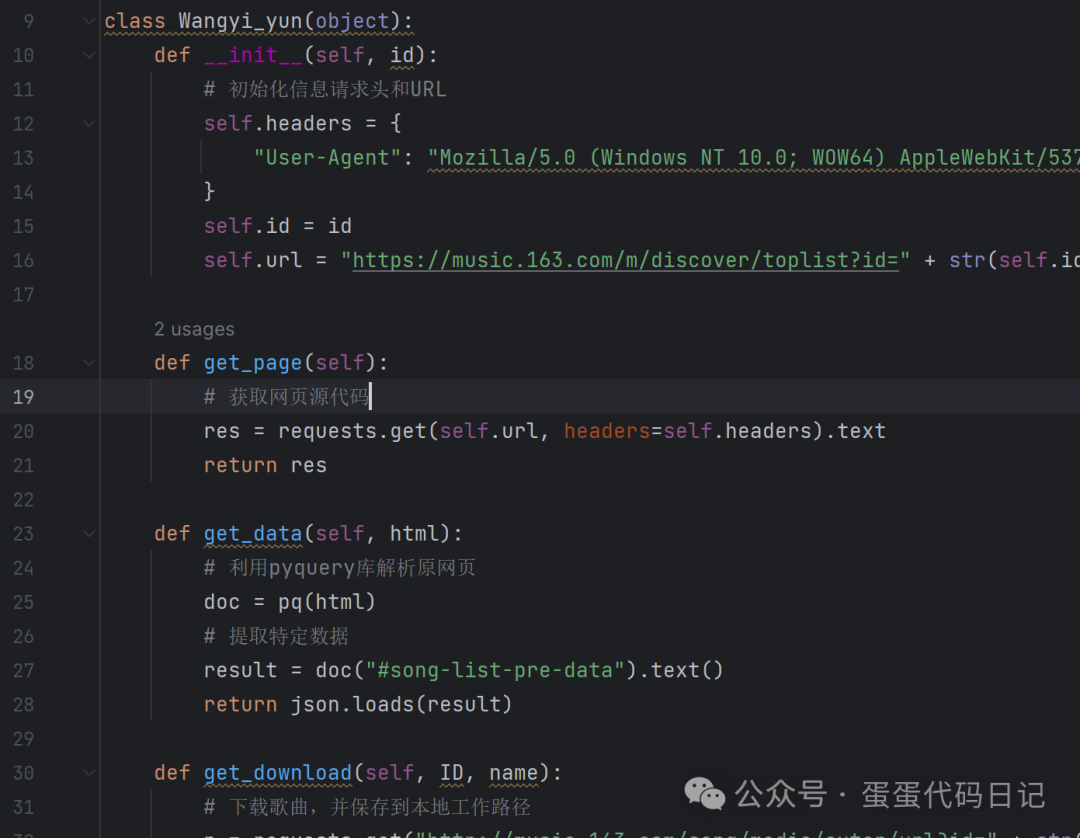
3. sanitize_filename函数:
-
用于清理文件名,移除非法字符。
-
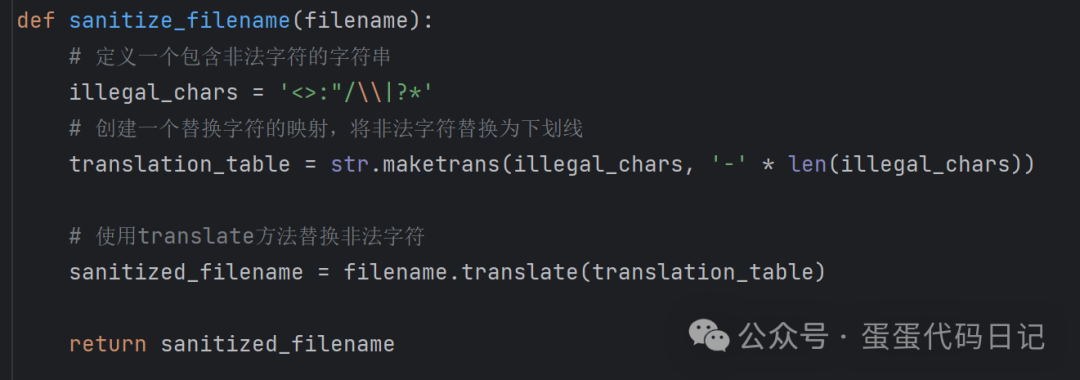
4. get_lyric函数:
-
根据歌曲ID获取歌词。
-
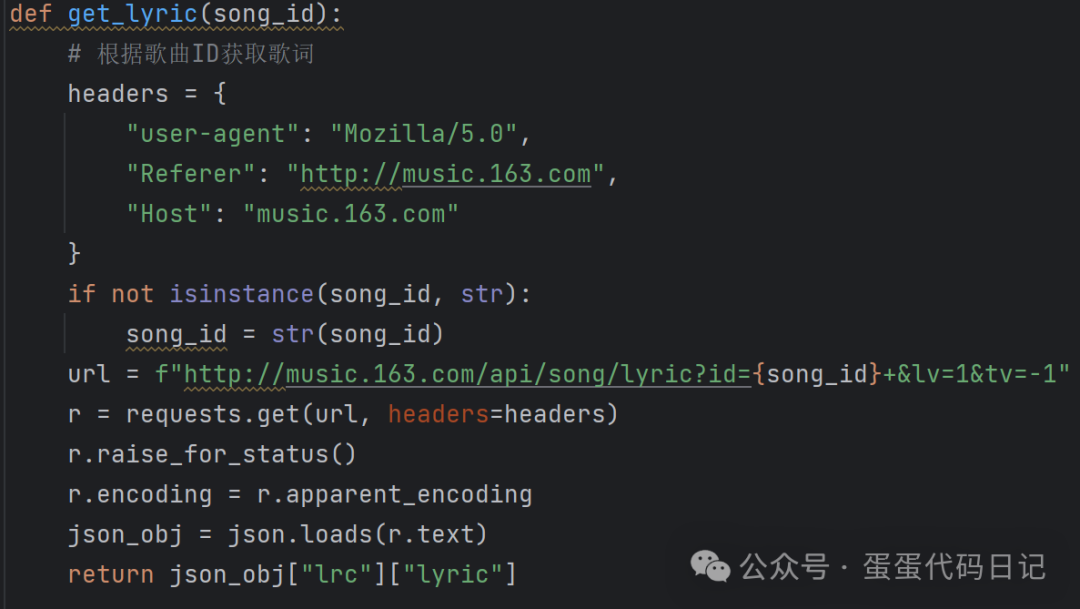
5. 主程序:
-
设置请求头。
-
初始化Wangyi_yun对象,传入音乐榜单ID。
-
使用main方法获取歌曲信息,并写入CSV文件。
-
使用pandas读取CSV文件,添加序号列,然后保存回CSV文件。
-
使用fetchData方法获取歌曲数据,然后尝试下载歌曲和歌词。
四、获取完整源码
编码不易,请支持原创!
本案例完整爬虫源码及csv、txt、mp3等结果文件,关注后回复网易云可获取↓
获取后,有任何代码问题请留言!
任何疑问可以直接后台留言,蛋蛋会及时回复

















 2048
2048

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









