







绕过请求头方法一、
绕过请求头检查:
import requests
import re
from fake_useragent import UserAgent
url='https://music.163.com/'
headers={
'user-agent':UserAgent().random
}
print(headers)
req=requests.get(url=url,headers=headers)
code=req.status_code
print(code)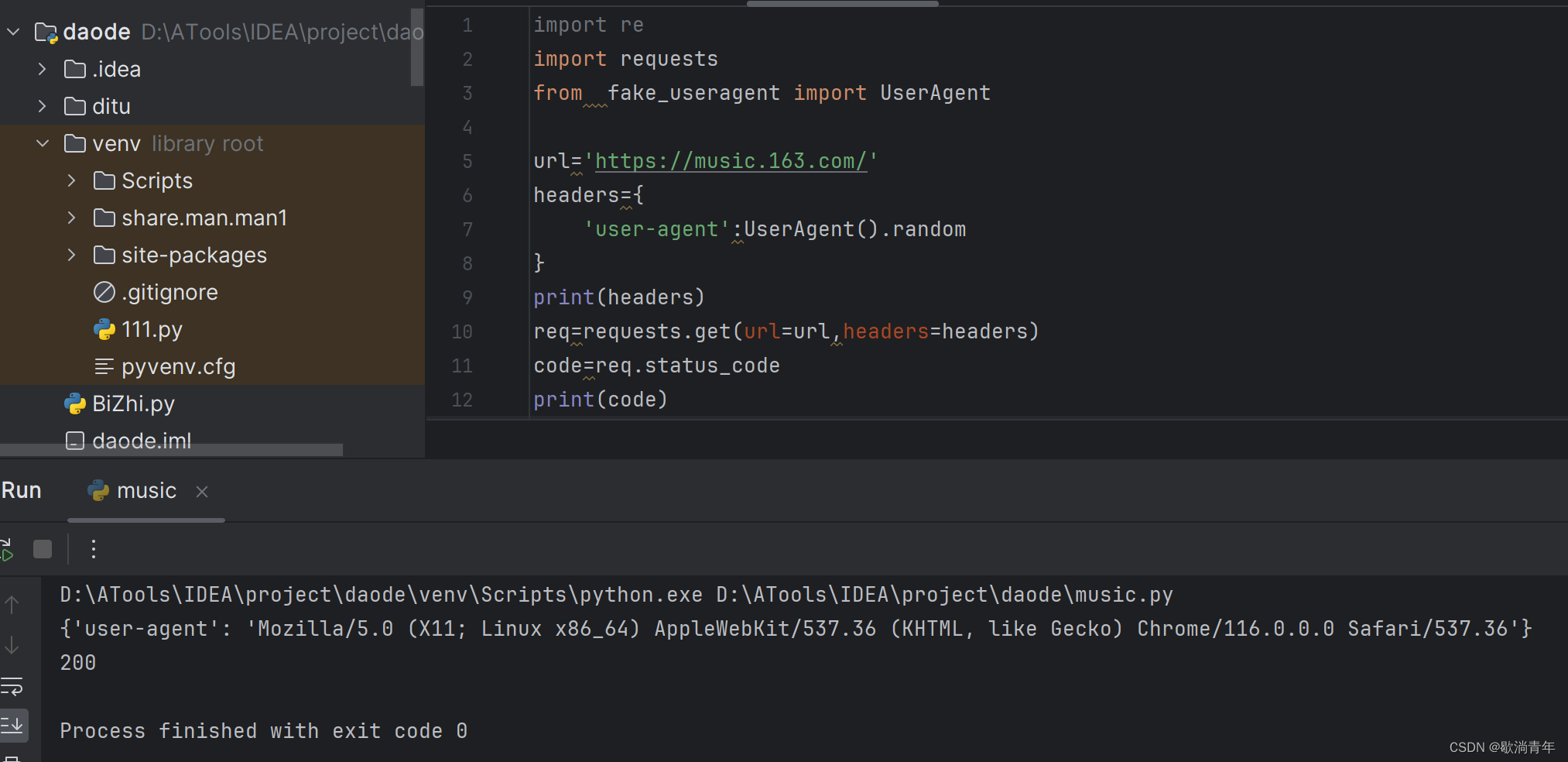
绕过请求头 方法二、
import requests
import re
import fake_useragent
ua=fake_useragent.UserAgent()
url='https://music.163.com/'
headers={
'user-agent':ua.random
}
print(headers)
req=requests.get(url=url,headers=headers)
code=req.status_code
print(code)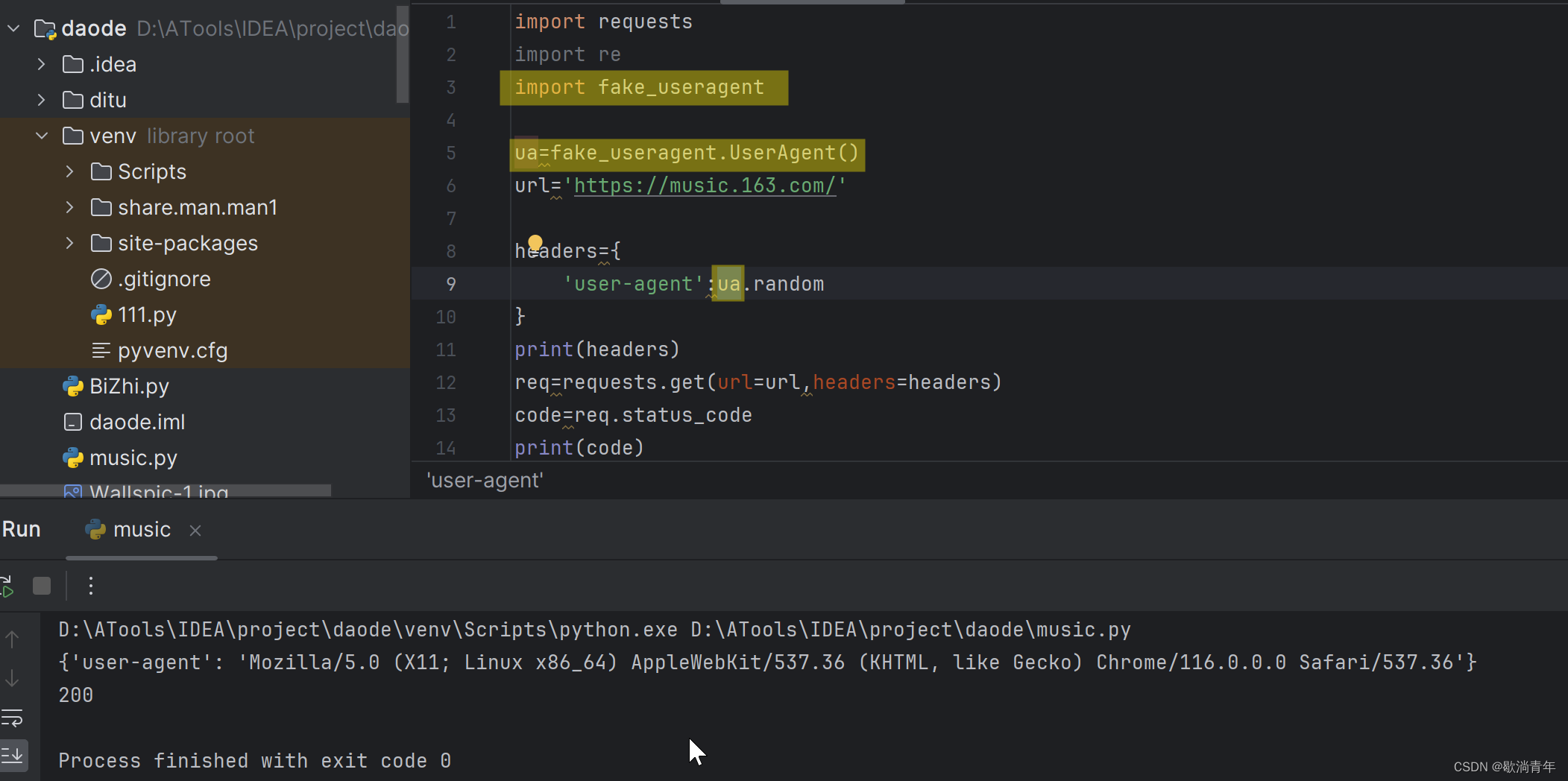
import requests
import fake_useragent
import re
"""
1.确定网址
2.搭建关系 发送请求 接受响应
3.筛选数据
4.保存本地
"""
url = "https://music.163.com/discover/toplist?id=3778678"
ua = fake_useragent.UserAgent()
header = {
'user-agent': ua.random
}
response = requests.get(url=url, headers=header)
r = response.text
# print(r)
response.close()
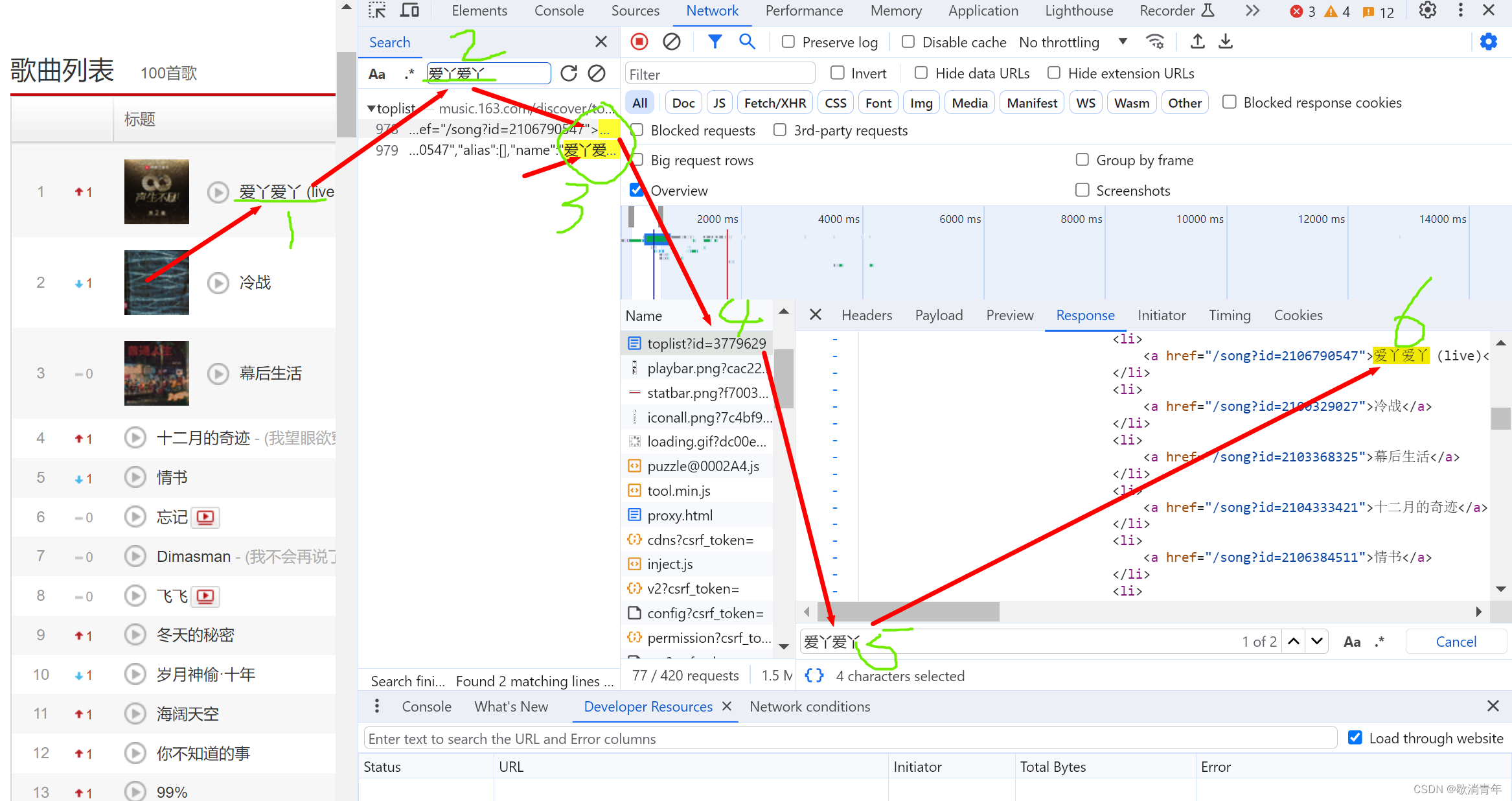
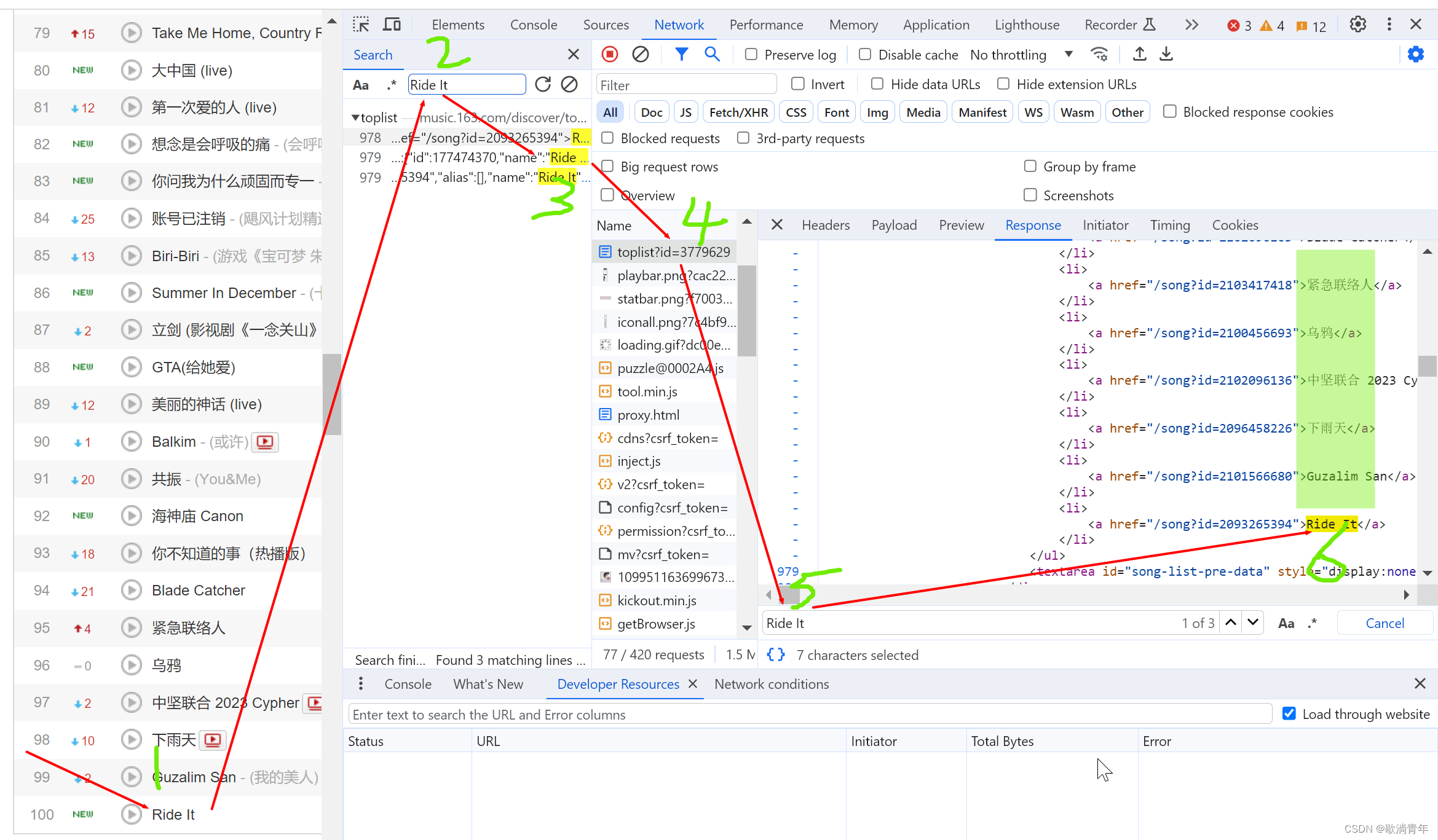
# 包含歌曲和歌曲链接的一段字符串
all = ''.join(re.findall('<ul class="f-hide">(.*?)</ul>', r))
# 从 all 里提取歌名
name = re.findall('<a href=".*?">(.*?)</a>', all)
# 从 all 里提取歌曲地址
song_url = re.findall('<a href="(.*?)">.*?</a>', all)
# 从页面全部源代码中提取歌手的信息
singer = re.findall(r'"artists":\[{"id":.*?,"name":"(.*?)",', r)
# 打印
for i in range(len(name)):
print(name[i], '\t', singer[i], '\t','https://music.163.com/#/'+song_url[i])需要添加放到 excle中,放到docs中打印输出


















 440
440

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











