






0.前导内容:
一般定义:管理软 \ 硬件资源,为程序提供服务。
其实操作系统是一个很广义的概念,它的边界很模糊,其核心就是让程序跑的更快,协助程序运行。

所以最开始的操作系统是什么样子的呢?
- 第一台计算机 ENIAC 于1946年诞生,这个计算机的实现非常简单,逻辑门是由 真空电子管实现的,存储是由延迟线构成,输入输出是由打孔纸带和指示灯构成,此时的计算机算一个纯粹的图灵机(图灵的基本思想是用机器来模拟人们用纸笔进行数学运算的过程),他的功能就是帮助做些人们需要花费很长时间做的计算,此时是不存在操作系统这一说的,因为能把程序运行起来就算可以的了。
CPU是怎么工作的视频:https://www.bilibili.com/video/BV1nL411x7jH/?spm_id_from=333.788&vd_source=c970f4e8ec3be55e620e45ad71365a05
1.什么是MOSFET?
在初中化学里我们学过一个元素是由原子构成的,一个原子是由带正点的质子和不带电的中子组成原子核,外围围绕带负电的电子构成。在不受外力的影响下电子在原子核周围做无规律运动,此运动范围则为电子云,我们通常是以平面结构来展示层级关系和结构的。
- 导体:而铜是我们常见的导体,因为铜的最外层有一个电子,这个电子是有脱离原子飞出去成为自由电子的趋势的,在不受外力的影响下此电子是自由运动的,但是如果我们把一串铜原子连接起来,并且连接电源,在电压的影响下每个铜元素中的此电子会发生定向的移动,形成电流。
- 半导体:半导体就是介于导体和绝缘体之间,我们常见的半导体是硅元素,因为其最外层是4个电子,当硅元素组合在一起时,其外层的原子会形成稳定的共价键使每个硅原子的外层都达到8电子稳定,所以纯硅的导电性是很弱的,所以可以在硅中分别添加少量的磷和硼形成N型掺杂和P型掺杂,将两者混合在一起,左边是N型右边是P型就形成了PN结即二极管,再组合一下就变成了 MOSFET(这里的组合我实在看不懂),MOSFET就是组成逻辑门的基本单位,而逻辑门是CPU很多功能的基本实现基础(NMOS是高压导通低压不导通,PMOS是低压导通高压不导通,两者合在一起就构成了CMOS,一个CMOS就可以构成一个非门)。
下面是一个非门的案例,VDD表示供电电压,VSS是接地点;当A传入正向电压时,此时电压高于阈值,上面不导通下面导通(即NMOS),此时下面连接的是VSS接地点,相当于B直接接入到了VSS上,输出的就是相对的低压,另一个相反。
CPU的一些计算就是由这些逻辑门构成的


-
1950s
相比于第一台计算机,有了很大的提升:更快更小的逻辑门(晶体管)等等,并可以执行更复杂的任务,并且更多发人希望使用到计算机,希望直接调用API而不是直接操作访问设备,此时 Fortran 诞生,也是最早的高级语言(1957年),他的操作是通过打孔的卡片进行的,如果你需要进行某些代码的编译,则需要自己将卡片打孔好,再放入计算机运行即可(一行代码一张卡片)
那时的计算机稍微的普及开来,但是价格昂贵,一个学校可能只有一台,但是使用者却有很多,需要执行的卡片也有很多,再此环境下,操作系统诞生了(operate job system),此时的操作系统可以理解为卡片管理系统,他管理的是这些需要操作的卡片,并执行换卡的操作,卡片就相当于需要运行的程序,操作系统做的就是在一个卡片运行完后切换下一个卡片。并且操作系统还有其他的功能比如文件(需要把一些卡片的执行结果存储到另一些卡片上)等。 -
1960s
此时的计算机有了很大的发展,出现了很多其他的高级语言,并拥有更大的内存(这样就不用频繁换卡了),可以存储不止一个程序,但是只有一个CPU意味着同一时间只能执行一个程序,但是在cpu和内存运行速度很快的情况下,可能会出现大量的空闲状态(这时程序可能在执行其他如打印机等操作)。
此时人们想到,或许可以让两个程序交替执行,操作系统就在其中发挥着管理切换程序的作用。

此时操作系统已经可以实现切换程序的功能了,为了更加的方便,可以设置定时切换,比如中断机制,某一程序运行指定时间后,操作系统将其中断,并决定是否要切换到另个程序执行:

发展到这里,我们发现了一个问题:当两个以上的程序同时存在于内存中时,在两者不隔离开的情况下一个坏的程序很有可能会对好的程序进行干扰,比如A程序的某个变量发送错误,指向了B程序,针对这个问题,1960s的计算机将内存中的不同程序进行了隔离。 -
1970s,此时的计算机已经呈现出了一个基本的架构,现代的计算机也是使用的此套架构。
总结:
操作系统 = 对象 + api(应用/设计方面)= C语言(实现方面)
1.什么是程序?
状态机:全称是有限状态自动机,最主要是展示转态和转态的转换。(也称时序逻辑电路)
数字逻辑电路就是:由寄存器保存的值就是我们的状态(可用0和1表示),我们为其设置一个初始状态,他则会根据固定的逻辑算出下一个状态,形成一个状态的转化

以下代码就是实现数字电路模拟的代码,核心思想就是实现了一个状态机:
#define REGS_FOREACH(_) _(X) _(Y)
#define RUN_LOGIC X1 = !X && Y; \
Y1 = !X && !Y;
#define DEFINE(X) static int X, X##1;
#define UPDATE(X) X = X##1;
#define PRINT(X) printf(#X " = %d; ", X);
int main() {
REGS_FOREACH(DEFINE);
while (1) { // clock
RUN_LOGIC;
REGS_FOREACH(PRINT);
REGS_FOREACH(UPDATE);
putchar('\n'); sleep(1);
}
}
下面就是执行的结果
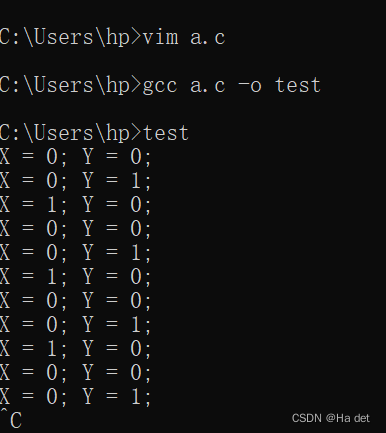
看上去好像没有什么用处,就是一些状态的变化,实则不然,如果我们使用7个“寄存器”来存储状态,那我们通过控制每个字母对应的横线或竖线的颜色,完成一个数字的循环显示。
这个的原理就是将我们写好的改进版的模拟状态机的结果传进另一个程序中,达到显色的效果。

这个就是显示的效果,非常的神奇,通过各个部位状态的变换我们就可以得到一个这个样的数字变换

程序是什么?
c语言程序本质就是一个状态机,由参数,和pc(程序计数器)组成,下面是一段c语言的实例:
#include <stdio.h>
int add(int,int);
int main()
{
int a = 2 ,b = 5;
int s = add(a,b);
return 0;
}
int add(int a,int b)
{
return a + b;
}
此代码的汇编结果,命令:gcc -S test.c -o test.s ,目标文件名是由自己自定义
.file "test.c"
.text
.def ___main; .scl 2; .type 32; .endef
.globl _main
.def _main; .scl 2; .type 32; .endef
_main:
LFB13:
.cfi_startproc
pushl %ebp
.cfi_def_cfa_offset 8
.cfi_offset 5, -8
movl %esp, %ebp
.cfi_def_cfa_register 5
andl $-16, %esp
subl $32, %esp
call ___main
movl $2, 28(%esp)
movl $5, 24(%esp)
movl 24(%esp), %eax
movl %eax, 4(%esp)
movl 28(%esp), %eax
movl %eax, (%esp)
call _add
movl %eax, 20(%esp)
movl $0, %eax
leave
.cfi_restore 5
.cfi_def_cfa 4, 4
ret
.cfi_endproc
LFE13:
.globl _add
.def _add; .scl 2; .type 32; .endef
_add:
LFB14:
.cfi_startproc
pushl %ebp
.cfi_def_cfa_offset 8
.cfi_offset 5, -8
movl %esp, %ebp
.cfi_def_cfa_register 5
movl 8(%ebp), %edx
movl 12(%ebp), %eax
addl %edx, %eax
popl %ebp
.cfi_restore 5
.cfi_def_cfa 4, 4
ret
.cfi_endproc
LFE14:
.ident "GCC: (MinGW.org GCC Build-2) 9.2.0"
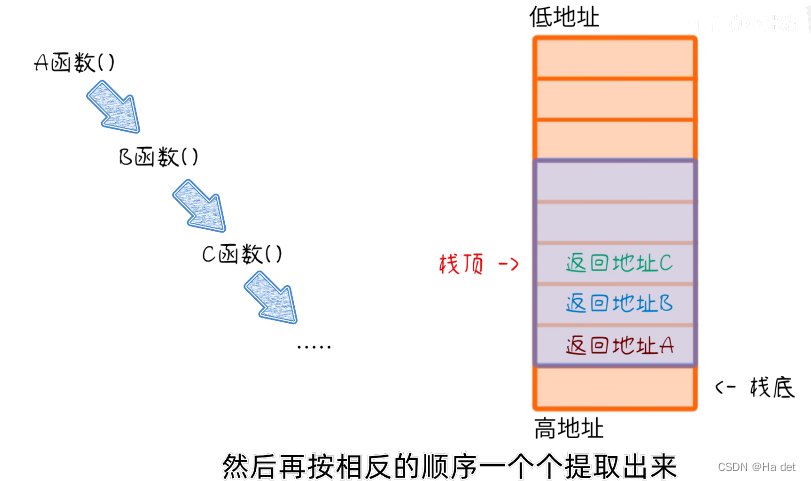
- 函数调用和堆栈是密切相关的:
我们可以看到,c语言最后会被转换为机器能看懂的汇编语言来对计算机进行操作,在操作的过程中我们知道,自定义的方法中的变量和数据都是局部变量,当方法结束时,这些变量就失效了,这些代码的计算都是在cpu中进行的,所以开发者就在cpu中开辟了一块地方:寄存器 专门存储这些临时变量,因为内存读取速度快的特性,就在内存中开辟了一块空间:栈(堆也是内存的另一块区域,堆栈和堆是不同的概念)
系统开始执行main函数时,会为它在内存里面建立一个帧(frame),所有main的内部变量(比如a和b)都保存在这个帧里面。main函数执行结束后,该帧就会被回收,释放所有的内部变量,不再占用空间。- 栈(stack)的特点:
栈的设计有个很特殊的地方,就是它的存储是由高位到低位的,就是当一个数据存进来时,栈帧的地址会减一些数值,变到低位上去,这样我们就先确定了高位,这样栈空间的起始位置就能确定下来,动态的调整栈空间大小也不需要移动栈内的数据;高位处是栈底,低位处是栈顶。
我们使用栈来存储函数调用,就是利用了其先进后出的特性,函数的嵌套调用的执行顺序和栈的特性正好相符。
- 栈溢出(stack overflow):
因为栈是从高地址开始,所以可用的长度是有限,如果此栈全用满了,再添加就会出现栈溢出的问题。- 常见的寄存器:
寄存器是CPU内部用来存放数据的一些小型存储区域,用来暂时存放参与运算的数据和运算结果。寄存器拥有非常高的读写速度,所以在寄存器之间的数据传送非常快。
ebp和esp是32位的SP,BP, esp是堆栈指针, ebp是基址指针。
这里特别说明一下ESP和EBP的作用:
ESP始终指向栈顶,可以sub,push,call(调用函数时需要压栈调用指令下一条的指令地址
即执行call指令时的指令计数器CP内的地址)等指令改变ESP的值;而EBP对于当前活动区,EBP值一般不变,固定指向堆栈列表中的一个地址(一般为进入函数后ESP指向的栈顶地址暂时称为基栈),若当前活动区改变(如调用函数),EBP值也就改变,通过查看汇编程序我们可以看到一般进入子函数后有一下指令:
pushl %ebp
movl %esp, %ebp
压栈上一层的基栈,把这一层的基栈(目前存在ESP中)传给EBP















 185
185











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









