







我们编写的一个c代码是如何运行的呢?换句话说一个c代码是怎么一步一步变为一个可以在电脑上运行的一个程序的呢?这就借助到了编译器,本章会通过具体实践来分析预处理、编译、汇编、链接和装入的整个过程。
在Linux系统下,先来说GCC编译器的一个整体的流程:
 接下来我们一步一步分析过程:
接下来我们一步一步分析过程:
我们先来编写一个hello.c源文件:
#include<stdio.h>
int main(){
printf("Hello World!");
}这个代码就是一个很简单的helloworld程序。
1.预处理
通过以下指令进行预处理并查看预处理后的hello.i文件:
gcc hello.c -o hello.i -E
cat hello.i//代码很长,这里只截取部分代码
28 "/usr/include/x86_64-linux-gnu/bits/types.h" 2 3 4
# 1 "/usr/include/x86_64-linux-gnu/bits/timesize.h" 1 3 4
# 29 "/usr/include/x86_64-linux-gnu/bits/types.h" 2 3 4
typedef long int __fsword_t;
typedef long int __ssize_t;
typedef long int __syscall_slong_t;
typedef unsigned long int __syscall_ulong_t;
extern int snprintf (char *__restrict __s, size_t __maxlen,
const char *__restrict __format, ...)
__attribute__ ((__nothrow__)) __attribute__ ((__format__ (__printf__, 3, 4)));
extern int vsnprintf (char *__restrict __s, size_t __maxlen,
const char *__restrict __format, __gnuc_va_list __arg)
__attribute__ ((__nothrow__)) __attribute__ ((__format__ (__printf__, 3, 0)));
# 379 "/usr/include/stdio.h" 3 4
extern int vdprintf (int __fd, const char *__restrict __fmt,
__gnuc_va_list __arg)
__attribute__ ((__format__ (__printf__, 2, 0)));
extern int dprintf (int __fd, const char *__restrict __fmt, ...)
__attribute__ ((__format__ (__printf__, 2, 3)));
# 2 "hello.c" 2
# 2 "hello.c"
int main(){
printf("Hello World!");
}预处理删除源文件中的注释,在源文件中插入包含文件的内容(#include),定义符号并替换源文件中的符号等(#define),通过这些处理,将会得到编译器实际进行分析的文本。
2.编译
通过以下指令对hello.i文件进行编译,并使用cat指令进行查看:
gcc hello.i -o hello.s -S
cat hello.s .file "hello.c"
.text
.section .rodata
.LC0:
.string "Hello World!"
.text
.globl main
.type main, @function
main:
.LFB0:
.cfi_startproc
endbr64
pushq %rbp
.cfi_def_cfa_offset 16
.cfi_offset 6, -16
movq %rsp, %rbp
.cfi_def_cfa_register 6
leaq .LC0(%rip), %rdi
movl $0, %eax
call printf@PLT
movl $0, %eax
popq %rbp
.cfi_def_cfa 7, 8
ret
.cfi_endproc
.LFE0:
.size main, .-main
.ident "GCC: (Ubuntu 9.4.0-1ubuntu1~20.04.2) 9.4.0"
.section .note.GNU-stack,"",@progbits
.section .note.gnu.property,"a"
.align 8
.long 1f - 0f
.long 4f - 1f
.long 5
0:
.string "GNU"
1:
.align 8
.long 0xc0000002
.long 3f - 2f
2:
.long 0x3
3:
.align 8
4:gcc编译器会对hello.i文件汇编成hello.s汇编语言源代码文件。
3.汇编
gcc hello.s -o hello.o -c汇编这个步骤会将hello.s汇编语言源代码文件生成为hello.o目标文件(二进制文件)。
4.链接
链接指令:
gcc hello.o -o hello汇编程序生成的目标文件并不能立即就被执行,其中可能还有许多没有解决的问题。 例如,某个源文件中的函数可能引用了另一个源文件中定义的某个符号(如变量或者函数调用等);在程序中可能调用了某个库文件中的函数,等等。链接程序的主要工作就是将有关的目标文件彼此相连接,也即将在一个文件中引用的符号同该符号在另外一个文件中的定义连接起来,使得所有的这些目标文件成为一个能够按操作系统装入执行的统一整体。
通过链接以后,就形成了真正可以运行的ELF可执行文件。
5.ELF可执行文件
通过以上的步骤,现在我们生成了真正可以执行的文件了,这个文件的格式是ELF格式,那么我们继续,来查看一下这个文件的内容:
//1.打印所有信息
readelf hello -a
//2.读取section(节)
readelf hello -S
//3.读取segment (load类型表示需要装载的段)
readelf hello -l


这里只截取了部分内容,ELF文件格式较为复杂,后面我会专门写一篇文章来介绍它,这里我们先大致了解一下ELF文件格式:

6.装入内存
hello.c文件通过以上步骤的操作,生成elf文件之后,当我们运行该elf文件时,操作系统就会通过装入器loader,来将以上elf文件中的代码段、数据段等内容装入到内存中,并且程序的虚拟地址空间是在程序加载到内存时由loader动态分配的。总之,装入内存这个工作是由加载器loader来实现的,加载器负责将程序的各个段分配到虚拟地址空间中,并处理重定位等任务。我们来看一下64位虚拟内存地址空间的分布情况:

操作系统在装载可执行文件时,并不关心哪个段中存放什么内容,操作系统关系的是段的权限。等会我们做另外一个实验的时候,就可以明白这个问题了。
链接器在链接的时候,会将同一权限、属性的相似section会链接在统一空间,然后这些相似的section会合并为统一segment。
这里关注一下.text、.rodata、.data、.bss四个节:(因为这四个和程序是相关的,其他只是给程序的辅助作用):
.text存放的是可执行的二进制代码。
.rodata存放的是被const修饰的全局变量。
.data(存放初始化的数据)和.bss(存放未初始化的数据)存放的是全局变量和局部变量。(目前bss段也映射到了数据段 .data中)
7.总结:
通过以上分析,我们应该清楚了我们编写的一个C源代码是如何一步一步变换,最终可以在计算机上运行。那么接下来,我们就通过一个实验来具体看一下程序在装入内存后,它的各个段在内存中的地址分配具体是怎样的,和我们第6点分析的结果是否一样。
8.实验:打印虚拟地址空间的分布情况
简介:本次实验会涉及到三个代码文件,一个是用户态代码文件ucode.c,一个是内核态代码kcode.c,以及一个makefile编译文件用来编译kcode.c。我的Linux内核版本是5.15,版本不同,可能需要修改一下函数名。
1.编写用户态代码,在用户态查看程序中的各种类型变量的地址信息:
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
//全局变量
int A;
int B=0;
int C=2;
//静态变量
static int D;
static int E=0;
static int F=4;
const int G=5;
static char H=6;
int main(void)
{
//局部变量
int a;
int b=0;
int c=2;
static int d;
static int e=0;
static int f=4;
static int g=5;
char char1[]="abcde";
char *cptr="123456";
int *heap=malloc(sizeof(int)*4);//堆
//打印进程的PID
printf("PID is: %d \n\n",getpid());
//打印变量的虚拟地址
printf("int A A_addr=%p\n",&A);
printf("int B=0 B_addr=%p\n",&B);
printf("int C=2 C_addr=%p\n",&C);
printf("static int D; D_addr=%p\n",&D);
printf("static int E=0 E_addr=%p\n",&E);
printf("static int F=4 F_addr=%p\n",&F);
printf("const int G=5 G_addr=%p\n",&G);
printf("static char H=6 H_addr=%p\n",&H);
printf("\n");
printf("int a A_addr=%p\n",&a);
printf("int b=0 B_addr=%p\n",&b);
printf("int c=2 C_addr=%p\n",&c);
printf("static int d; D_addr=%p\n",&d);
printf("static int e=0 E_addr=%p\n",&e);
printf("static int f=4 F_addr=%p\n",&f);
printf("const int g=5 G_addr=%p\n",&g);
printf("\n");
printf("char char1[] = 'abcde'\t\t\tchar1_addr = %p\n",char1);
printf("char char1[] = 'abcde'\t\t\t&char1_addr = %p\n",&char1);
printf("char **cptr = '1'\t\t\tcptr_addr = %p\n",&cptr);
printf("value of the cptr\t\t\tcptr_value = 0x%p\n",cptr);
printf("value of %p\t\t\tvalue_0x%p = %d\n",cptr,cptr,*cptr);
printf("int *heap=malloc(sizeof(int)*4)\theap_addr = %p\n",heap);
printf("int *heap=malloc(sizeof(int)*4)\t&heap_addr = %p\n",&heap);
//pause()的作用是让进程暂停
pause();
free(heap);
return 0;
}
2.编写内核模块,通过进程控制块task_struct中的mm_struct成员来访问虚拟地址空间中的段信息,并且该模块可以通过接收PID来查看我们指定的进程虚拟地址信息,这里我们来查看ucode这个进程的内容:
#include <linux/init.h>
#include <linux/module.h>
#include <linux/kernel.h>
#include <linux/mm.h>
#include <linux/sched.h>
static pid_t pid;
//向模块传递参数,文件的权限为0644
module_param(pid,int,0644);
int print_vma(void)
{
struct task_struct *task;
struct mm_struct *mm;
struct vm_area_struct *vma;
printk("\n\n\n\n\n\n\n\n");
printk("begin to print virtual address space... \n");
printk("\n");
task=pid_task(find_vpid(pid),PIDTYPE_PID);
mm=task->mm;
//打印进程的名字(comm)与进程号(pid)
printk("executable name:%s pid:%d\n",task->comm,task->pid);
printk("\n");
//打印mm_struct结构体中的一些内容
//代码段的开始地址、结束地址
printk("start_code:0x%lx end_code:0x%lx\n",mm->start_code, mm->end_code);
//数据段的开始地址、结束地址
printk("start_data:0x%lx end_data:0x%lx\n",mm->start_data,mm->end_data);
printk("\n");
//堆的开始地址、结束地址
printk("start_brk:0x%lx end_code:0x%lx\n",mm->start_brk,mm->brk);
printk("\n");
//栈的开始地址、结束地址
printk("start_stack:0x%lx\n",mm->start_stack);
printk("\n");
//给mm加锁,确保数据正确
mmap_read_lock(mm);
//打印每个vma的权限
for(vma=task->mm->mmap;vma;vma=vma->vm_next){
printk(KERN_CONT"0x%lx - 0x%lx",vma->vm_start,vma->vm_end);
printk(KERN_CONT" ");
if(vma->vm_flags & VM_READ)
printk(KERN_CONT"r");
else
printk(KERN_CONT"-");
if(vma->vm_flags & VM_WRITE)
printk(KERN_CONT"w");
else
printk(KERN_CONT"-");
if(vma->vm_flags & VM_EXEC)
printk(KERN_CONT"x");
else
printk(KERN_CONT"-");
if(vma->vm_flags & VM_SHARED)
printk(KERN_CONT"s");
else
printk(KERN_CONT"p");
printk("\n");
}
//解锁
mmap_read_unlock(mm);
return 0;
}
static int __init print_vma_init(void){
print_vma();
return 0;
}
static void __exit print_vma_exit(void){
printk("good bey,kernel!\n");
}
module_init(print_vma_init);
module_exit(print_vma_exit);
MODULE_LICENSE("GPL");3.编写makefile文件:
obj-m := kcode.o
CURRENT_PATH:=$(shell pwd)
LINUX_KERNEL:=$(shell uname -r)
LINUX_KERNEL_PATH:=/usr/src/linux-headers-$(LINUX_KERNEL)
all:
make -C $(LINUX_KERNEL_PATH) M=$(CURRENT_PATH) modules
clean:
make -C $(LINUX_KERNEL_PATH) M=$(CURRENT_PATH) clean
4.实验结果:
1.先运行用户态下的ucode进程:
//编译链接,形成elf文件(一步实现)
gcc ucode.c -o ucode
//运行程序
sudo ./ucode
通过运行结果,可以发现该程序的PID为8540,且每个变量的虚拟地址也打印了出来。
2.插入内核模块,并通过查看内核打印信息来观察进程的虚拟地址分配情况:
新开一个终端,先使用make指令编译内核模块,接下来插入该模块:
//编译
make
//插入模块
sudo insmod kcode.ko pid=8540
//查看内核打印信息
sudo dmesg -w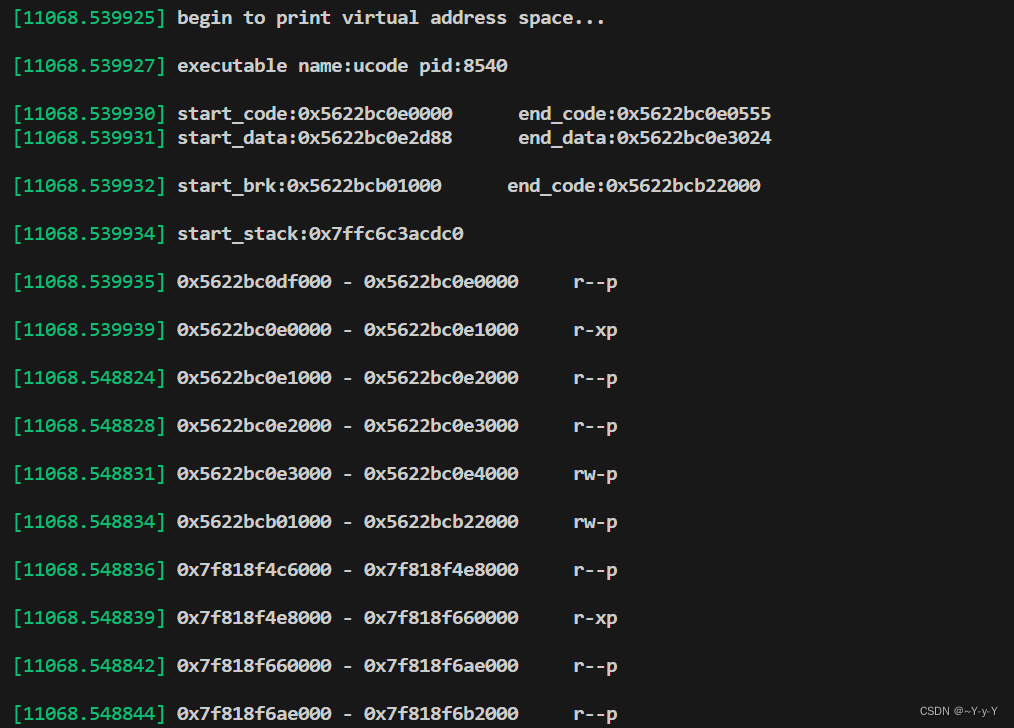
5.结果分析:
通过ucode的结果,A变量的地址为:0x5622bc0e303c,且它是未初始化的全局变量,应该在数据段data中,对比kcode的结果,data段的范围是:0x5622bc0e2d88------0x5622bc0e3024,A的地址刚好在data段中。
同理,由于局部变量存放在栈中,所以a、b、c三个变量的地址就是从栈的起始地址向后增加的。
通过对比ucode执行结果中变量的地址和kcode中给出的数据段的范围和栈段的范围,可以发现,我们分析的程序段在内存中的分配情况时正确的。
本章介绍了程序从编写到执行的整个流程,并且通过打印进程的虚拟地址空间的分布情况这一实验,说明了可执行文件到内存中虚拟地的具体分配情况,本文简化了很多知识点,后期我会对其中简化的知识点做一次补充。希望本文能对您有所帮助,感谢您的阅读。















 1444
1444











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









