






本文所属专栏:爬虫方法论 - DaveCui的专栏 - 掘金 (juejin.cn)
专栏记录了我本人在工作室接爬虫单的几个经典的真实案例,干货满满,这可是吃饭的家伙,还不关注一波。
前言
在上篇文章中,我们整个爬虫任务进行了分析,同时也通过一个简单的requests.get()方法获取到了页面源码。
接下来我们要做的就是通过页面源码解析获取到我们想要的数据。(在这里是每个律师的个人界面的链接)
一、beatifulsoup介绍
Beautiful Soup是一个可以从HTML或XML文件中提取数据的Python库,简单来说,它能将HTML的标签文件解析成树形结构,然后方便地获取到指定标签的对应属性。
通过Beautiful Soup库,我们可以将指定的class或id值作为参数,来直接获取到对应标签的相关数据。简单来说,就是把html或者xml源代码进行了格式化,方便我们对其中的节点、标签、属性等进行进一步的操作.
我们都知道HTML是一种标签语言,类似一种树形结构,而beatifulsoup则提供了封装好的方法从这些结构中提取出我们想要的资源。
二、实战讲解
库的安装就不讲了,太基础了。
import requests
from bs4 import BeautifulSoup
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36'}
url = "https://www.hklawsoc.org.hk/zh-HK/Serve-the-Public/The-Law-List/Members-with-Practising-Certificate?name=&jur=&sort=1&pageIndex=1#tips"
response = requests.get(url, headers=headers)
html = response.content.decode('utf-8', 'ignore')
my_page = BeautifulSoup(html, 'lxml')
print(type(my_page))# <class 'bs4.BeautifulSoup'>
my_page = BeautifulSoup(html, 'lxml')
print(type(my_page))# <class 'bs4.BeautifulSoup'>
首先通过BeautifulSoup对我们之前获取到的页面源码进行解析,这样就可以通过BeautifulSoup里面的方法对my_page对象进行解构。
三、寻找元素定位
用我们之前讲过的定位方法(F12弹框左上角的小箭头)。在这里我们发现,包含三个律师的信息表的根元素是<table class="responsive">
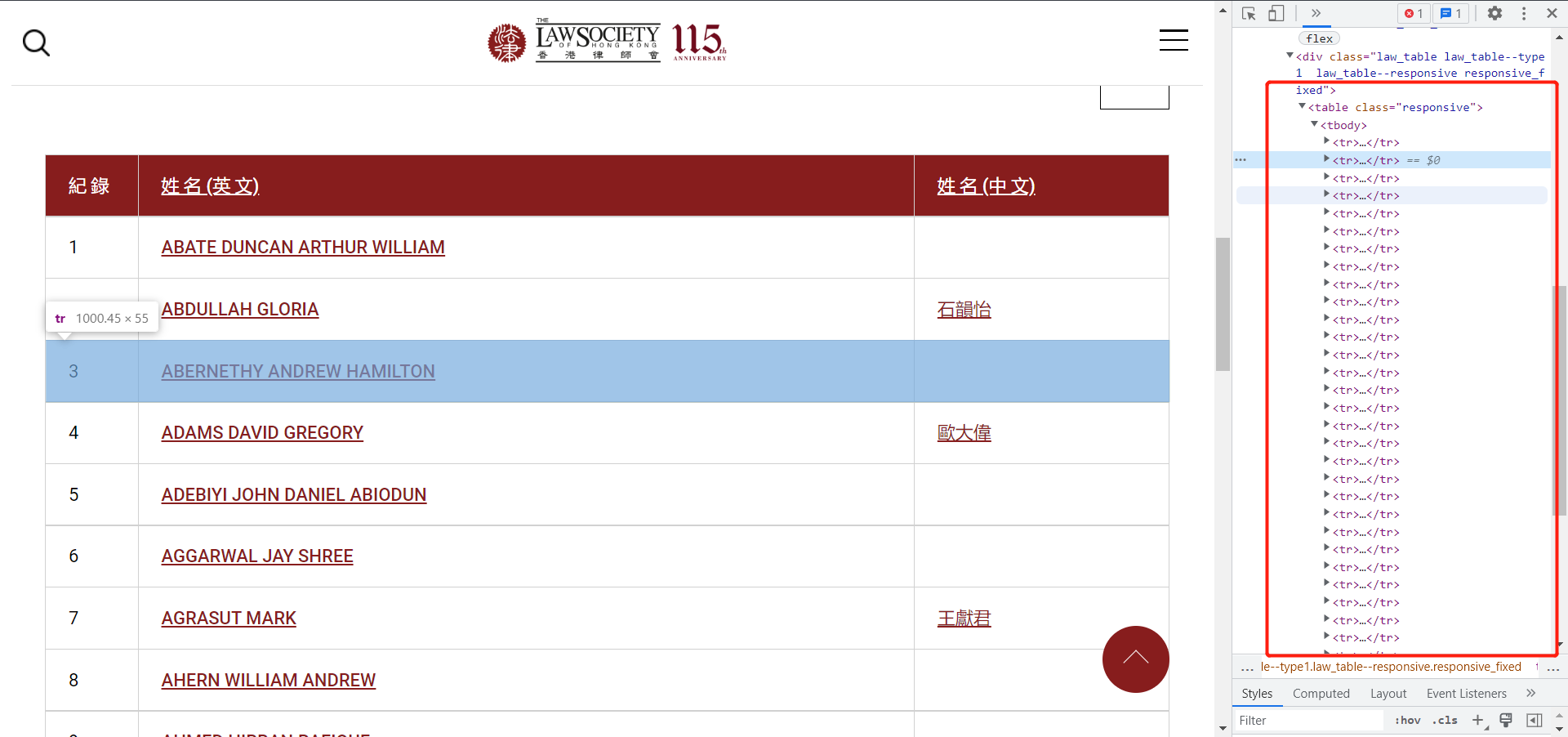
table下的一个<tr> ...</tr>就代表一行,所以思路很清晰了吧。
-
通过 find方法结合标签和class名称定位整个table -
通过 find_all方法,找出所有的tr元素
table=my_page.find('table', class_='responsive')
my_tr = table.find_all('tr') #my_tr是个列表
print(len(my_tr)) # 31
这里是31行,注意第一行是表头,不是我们想要的元素,记得跳过。
四、进一步的元素定位
刚才我们找到的是一行元素(包括序号,姓名等),所以我们还要进一步的定位找出我们想要的超链接出来。
-
超链接是挂在姓名上的,定位姓名
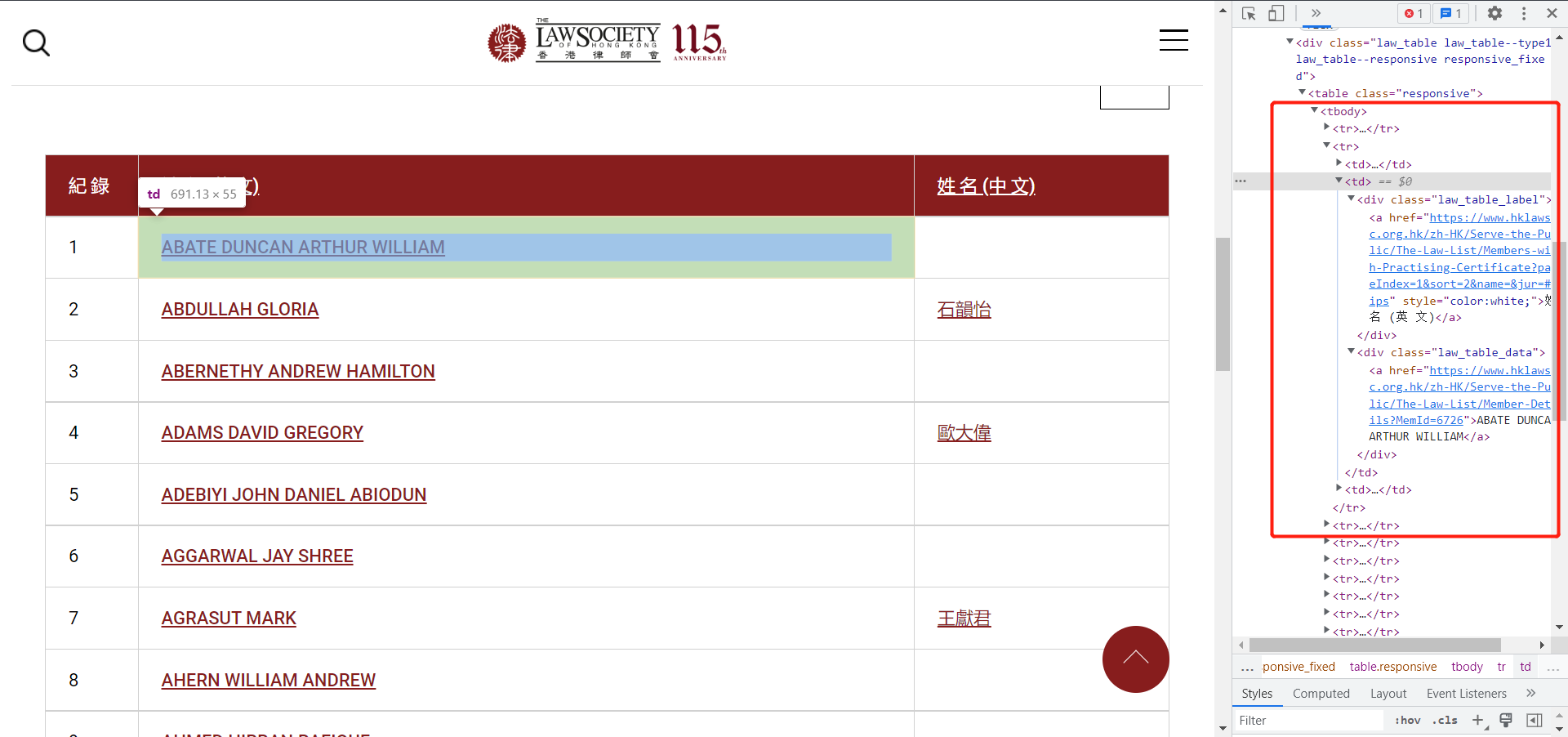
一个tr标签里面有三个td分别代表了,序号,英文名,中文名。
然后那个链接在第二个td的第二个div中,所以思路明确。
target_td=tr.find_all('td')[1]
target_a=target_td.find('a')
href=target_a.attrs['href']
-
这里为什么直接用 td的a元素,a元素不是两个嘛。这个自己输出下,应该就明白了。
target_td=tr.find_all('td')[1]
target_a=target_td.find_all('a')
print(target_a)
输出是这样的,仅有一个元素:
[<a href="https://www.hklawsoc.org.hk/zh-HK/Serve-the-Public/The-Law-List/Member-Details?MemId=6726">ABATE DUNCAN ARTHUR WILLIAM</a>]
这个也是很好理解的因为前端有很多界面元素都是变化的,可能我们打开页面触及到一些
js函数导致界面的变化。所以最好还是有问题自己输出下。
五、结果:
因为我们不可能只保留超链接,所以我这里处理就是把所有的元素都加进去了。
for tr in my_tr[1:]:
row = []
for td in tr.find_all('td'):
row.append(td.text.replace('\n', ''))
target_td=tr.find_all('td')[1]
target_a=target_td.find('a')
row.append(target_a.attrs['href'].replace('\n', ''))
print(row)
-
输出结果如下: 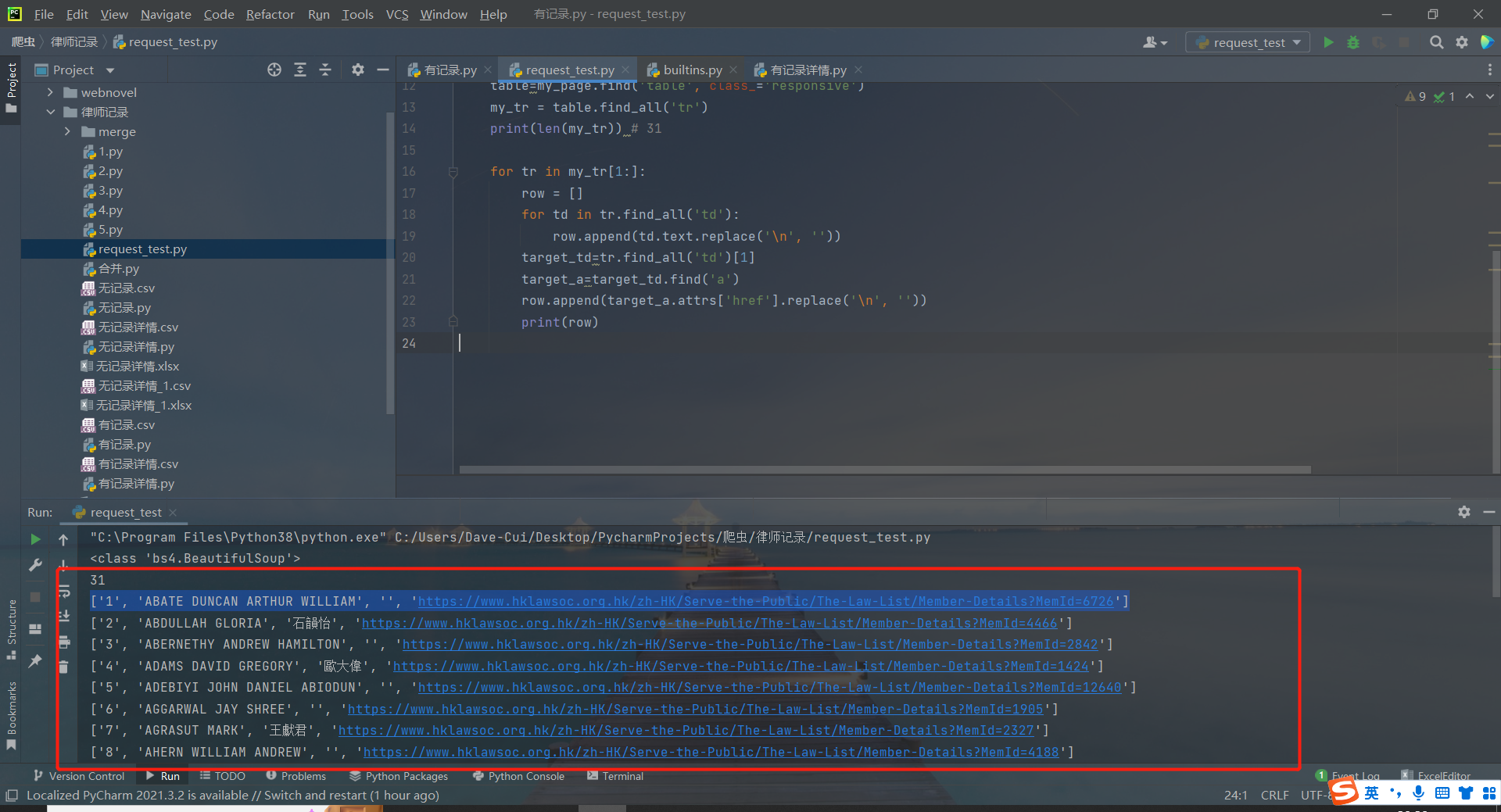
找出个人链接的完整代码
import requests
from bs4 import BeautifulSoup
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36'}
flag=True
for i in range(1, 11339//30):
# print(i/(11339//30),end=' ')
url = "https://www.hklawsoc.org.hk/zh-HK/Serve-the-Public/The-Law-List/Members-with-Practising-Certificate?name=&jur=&sort=1&pageIndex="+str(i)+"#tips"
response = requests.get(url, headers=headers)
html = response.content.decode('utf-8', 'ignore')
my_page = BeautifulSoup(html, 'lxml')
print(type(my_page))# <class 'bs4.BeautifulSoup'>
table=my_page.find('table', class_='responsive')
my_tr = table.find_all('tr')
print(len(my_tr)) # 31
for tr in my_tr[1:]:
row = []
for td in tr.find_all('td'):
row.append(td.text.replace('\n', ''))
target_td=tr.find_all('td')[1]
target_a=target_td.find('a')
row.append(target_a.attrs['href'].replace('\n', ''))
print(row)
个人总结
beatifulsoup这里我只是根据案例讲了应用,相关的知识点,其实网络也有很多,所以没有详细的讲解。这里可能更加侧重爬虫任务的思路。
目前这个简单的任务就告一段落了,至于之后访问这些爬下来的个人界面的链接获取详细信息,其实和这个思路相差不大,都是分析界面然后find、find_all方法逐级定位元素,通过text、attrs方法搞到具体的文本或者属性。
如果有时间的话,会讲一讲个人信息界面爬取的思路的。因为这个任务是一个同行没有搞好,然后我才能接到的任务。
本文由 mdnice 多平台发布














 169
169











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









