






其实我们或多或少都是听说过爬虫这个概念,这个东西的技术栈其实也比较成熟了。
其实在我的理解中,爬虫嘛,就是给自己伪装一下,装成是正常的访问请求,然后获取到网站或者APP中的数据资源的一种技术手段。
当然目前大部分爬虫都是python写的,毕竟python丰富的第三方库资源还有语言优势摆在这里。所以,这里也是通过python进行爬虫的编写。
一、项目需求
一个香港的老板应该是,他给个网址
里面大概是这样的
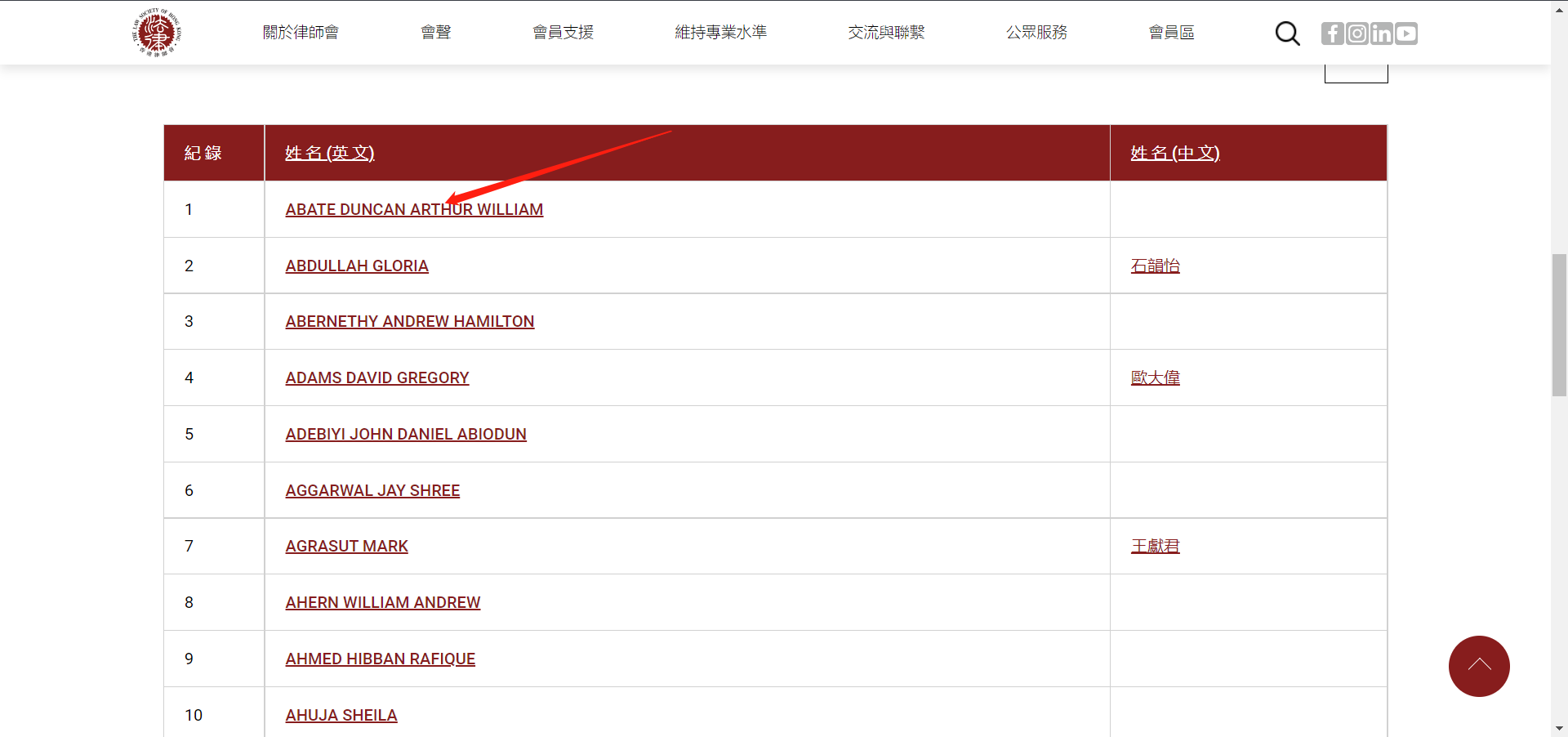
点进去那个箭头的之后是个超链接,然后,要把这个信息爬下来。
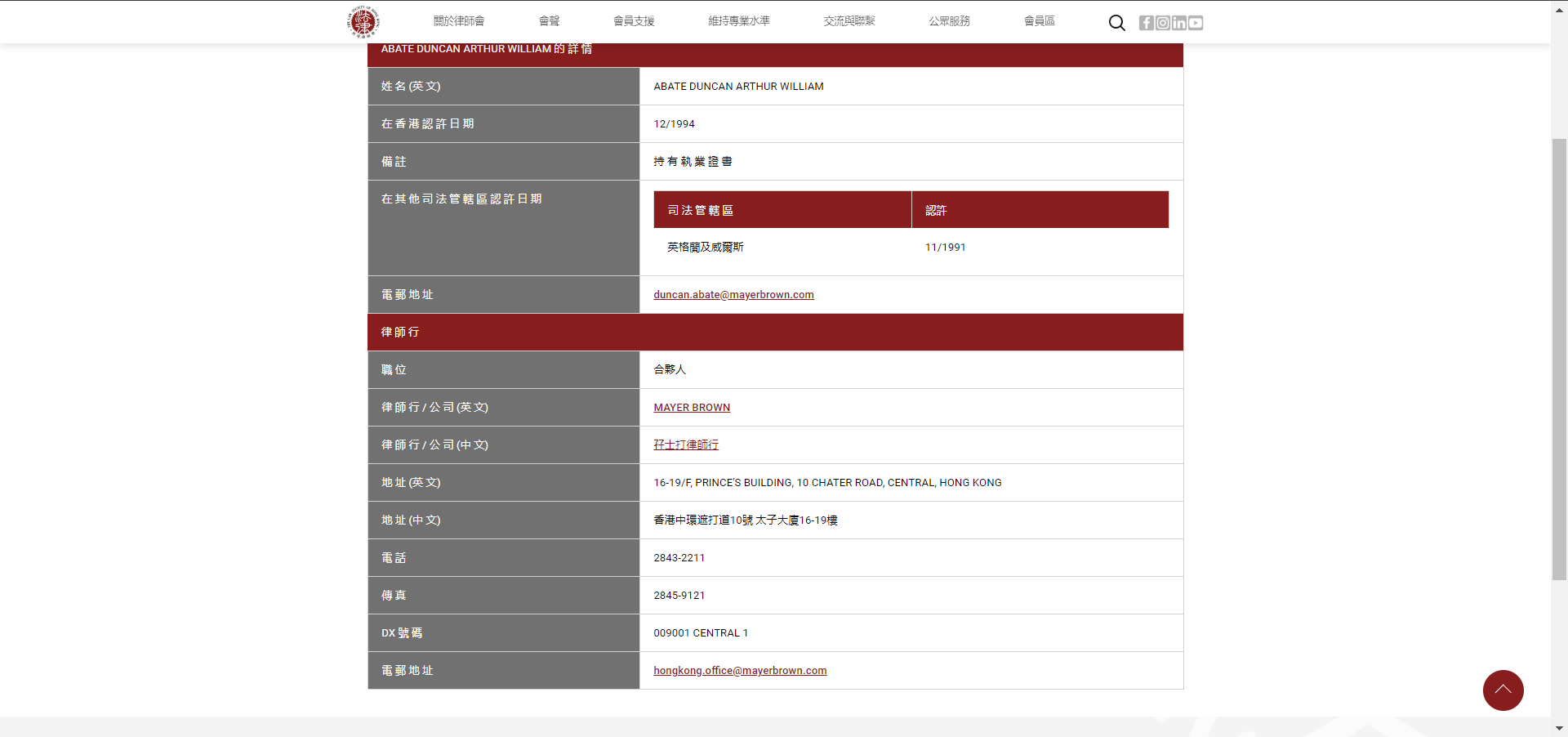
需求挺明确的,而且这个网站,连一些基础的反爬手段都没有。
二、分析网页
搞到所有律师的信息的流程清晰的分为两个步骤:1.搞到所有律师的个人介绍的超链接;2.然后再对所有链接进行访问。
 可以看到哈,这个记录还是有点多的,11339条,30个记录一页。要全部拿下来不是一件简单的事,
可以看到哈,这个记录还是有点多的,11339条,30个记录一页。要全部拿下来不是一件简单的事,
1.找到所有页面的链接:
这个是第一页。 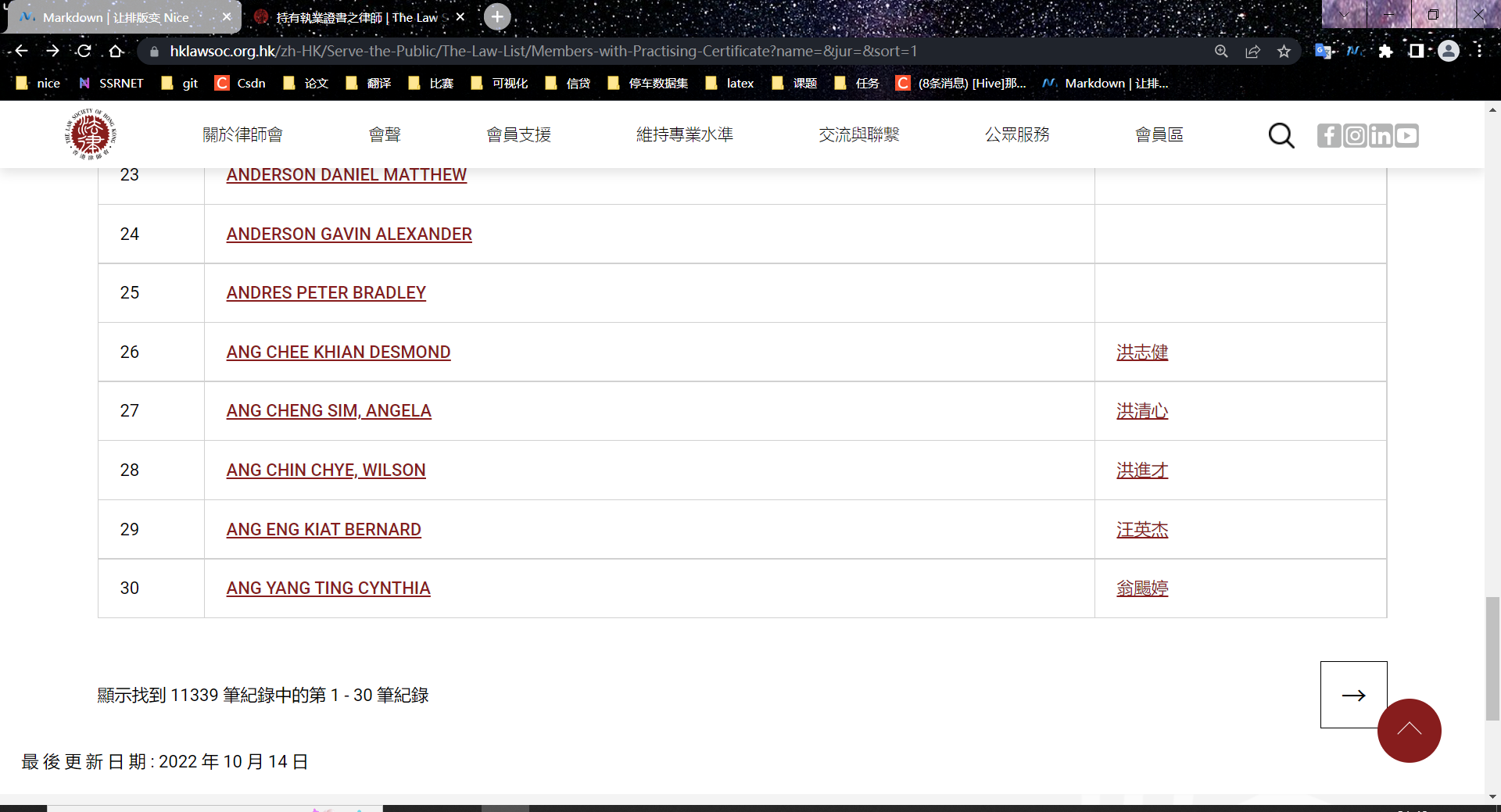
这个是第二页。 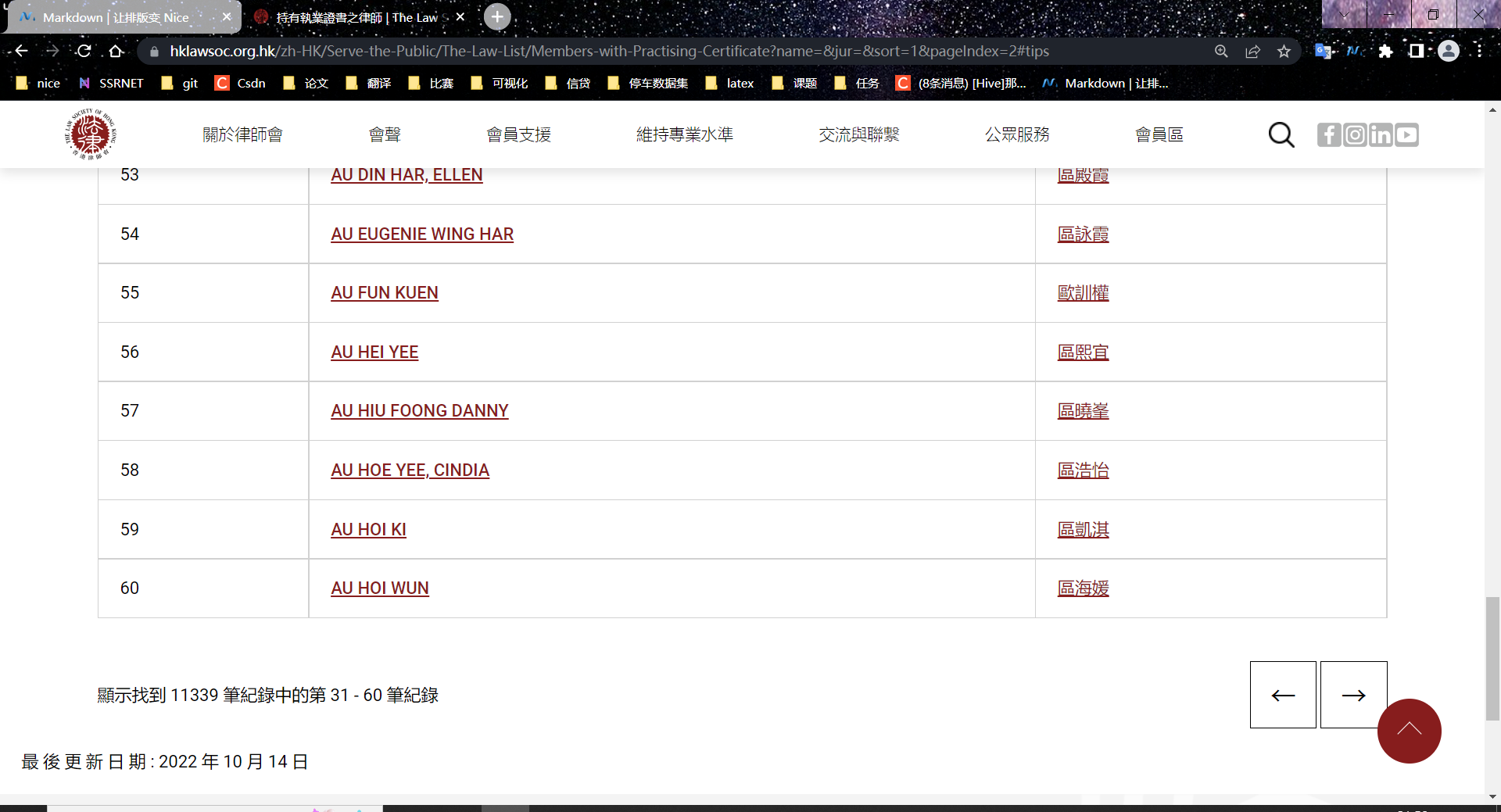
让我们来看看他的链接:
第一页:https://www.hklawsoc.org.hk/zh-HK/Serve-the-Public/The-Law-List/Members-with-Practising-Certificate?name=&jur=&sort=1
第二页:https://www.hklawsoc.org.hk/zh-HK/Serve-the-Public/The-Law-List/Members-with-Practising-Certificate?name=&jur=&sort=1&pageIndex=2#tips
找到不同了嘛.第二页多出了一个字段:&pageIndex=2#tips 可以把这个数字换成1和3,试一下.
&pageIndex=1#tips 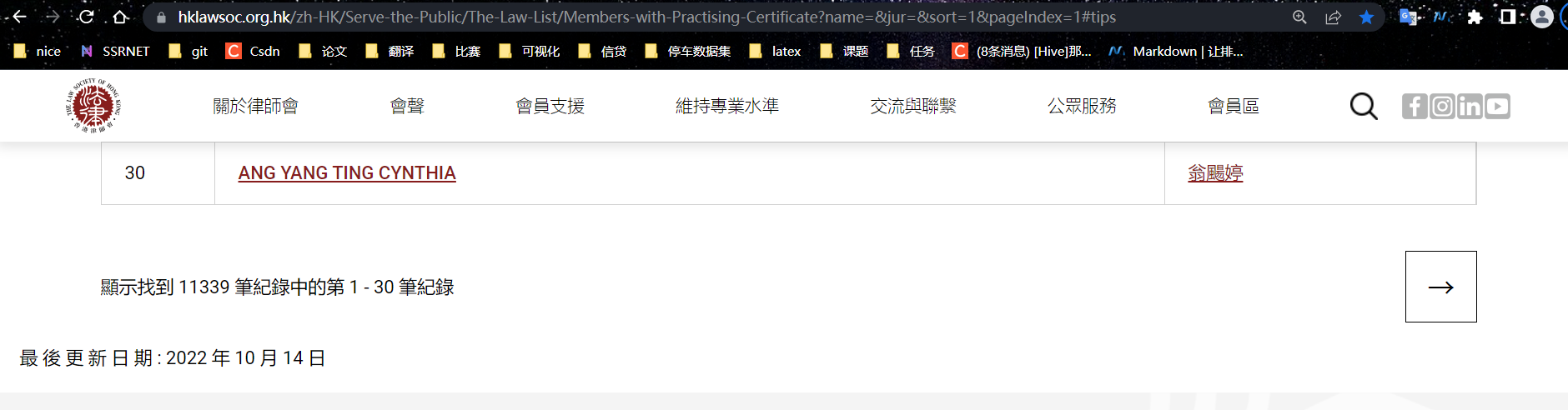
&pageIndex=3#tips 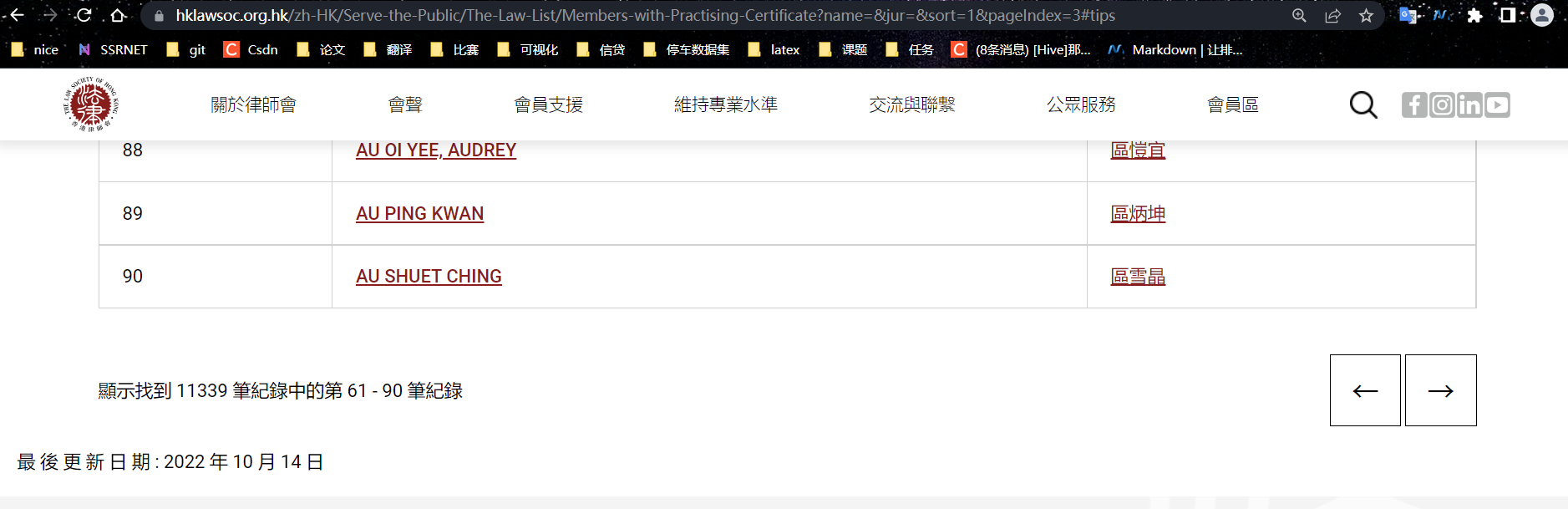
所以所有页面的规律就找到了,用来访问的链接如下:
for i in range(1, 11339//30):
print(i/(11339//30),end=' ')
url = "https://www.hklawsoc.org.hk/zh-HK/Serve-the-Public/The-Law-List/Members-with-Practising-Certificate?name=&jur=&sort=1&pageIndex="+str(i)+"#tips"
这个规律真的很简单,所以就用来爬虫的入门了.
2.找到所有律师的个人页面链接:
这个就是一个页面分析的任务了。
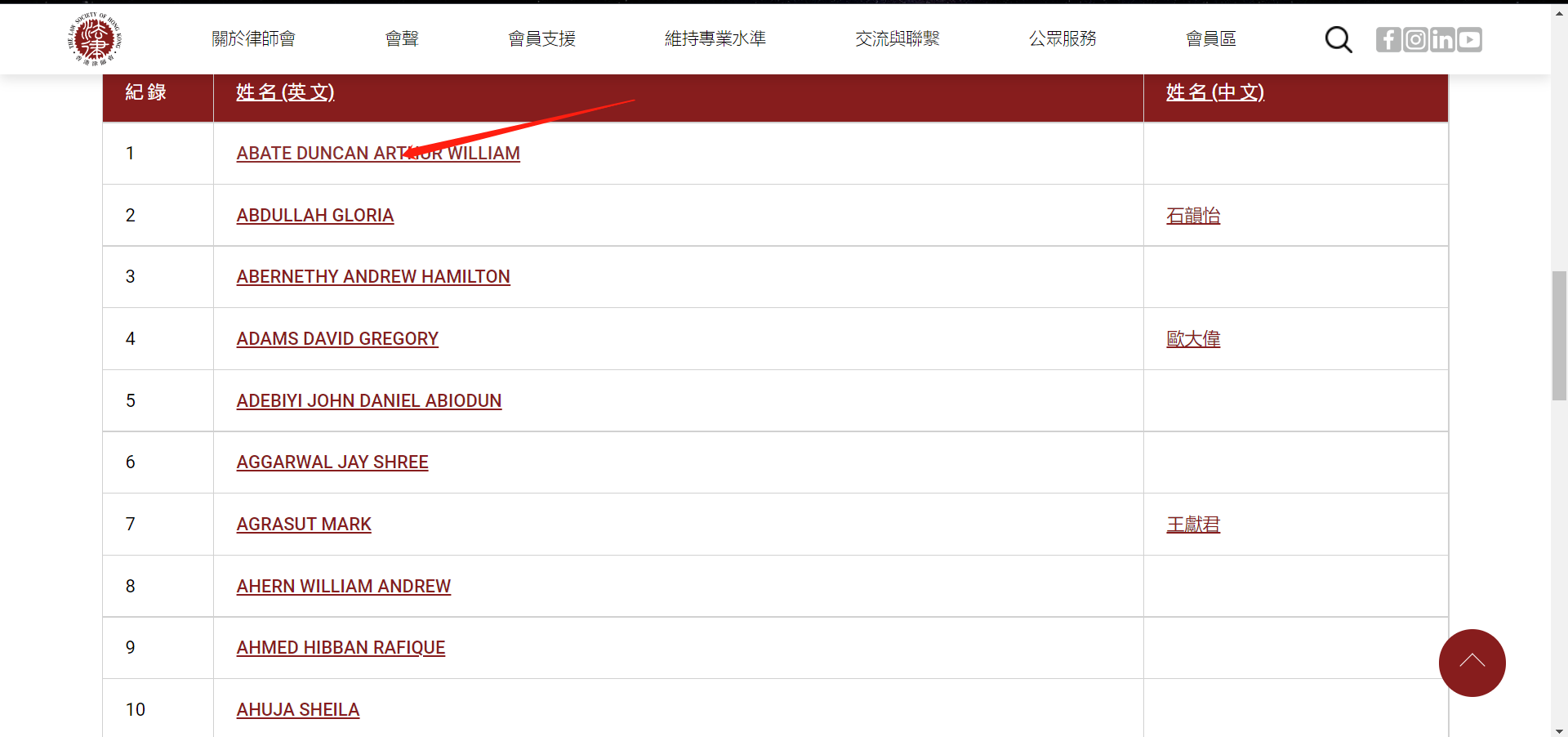
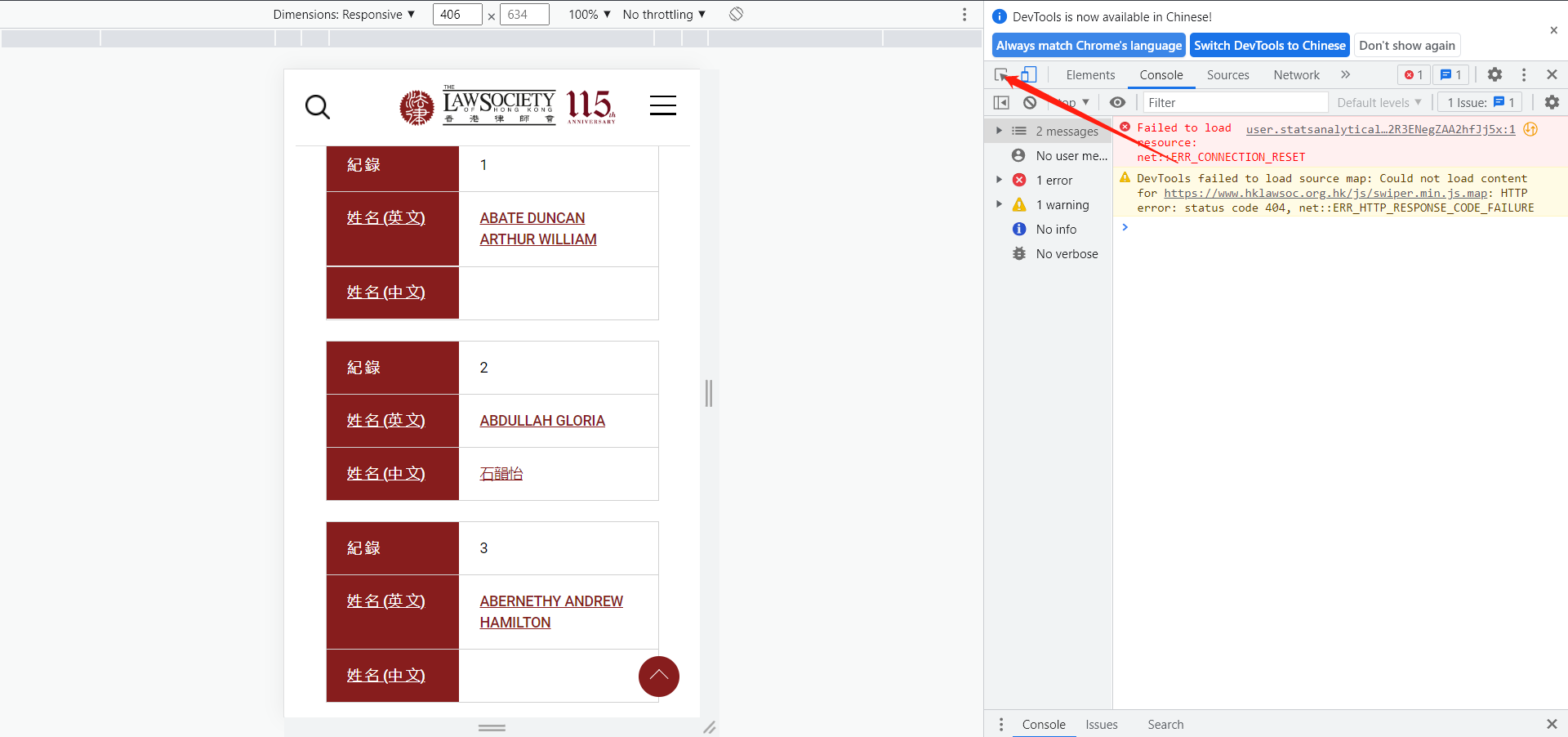
还记得我们刚才是点这个链接访问的这个律师个人信息界面吧,这里面必然有着个人界面的超链接,我们需要的就是把它扒出来出来就可以了。下面我们在这个页面,按F12,查看,操作如下:
-
点击F12,进入下面的界面
 2. 点箭头指向的按钮
2. 点箭头指向的按钮
-
然后点击你想扒出超链接的元素
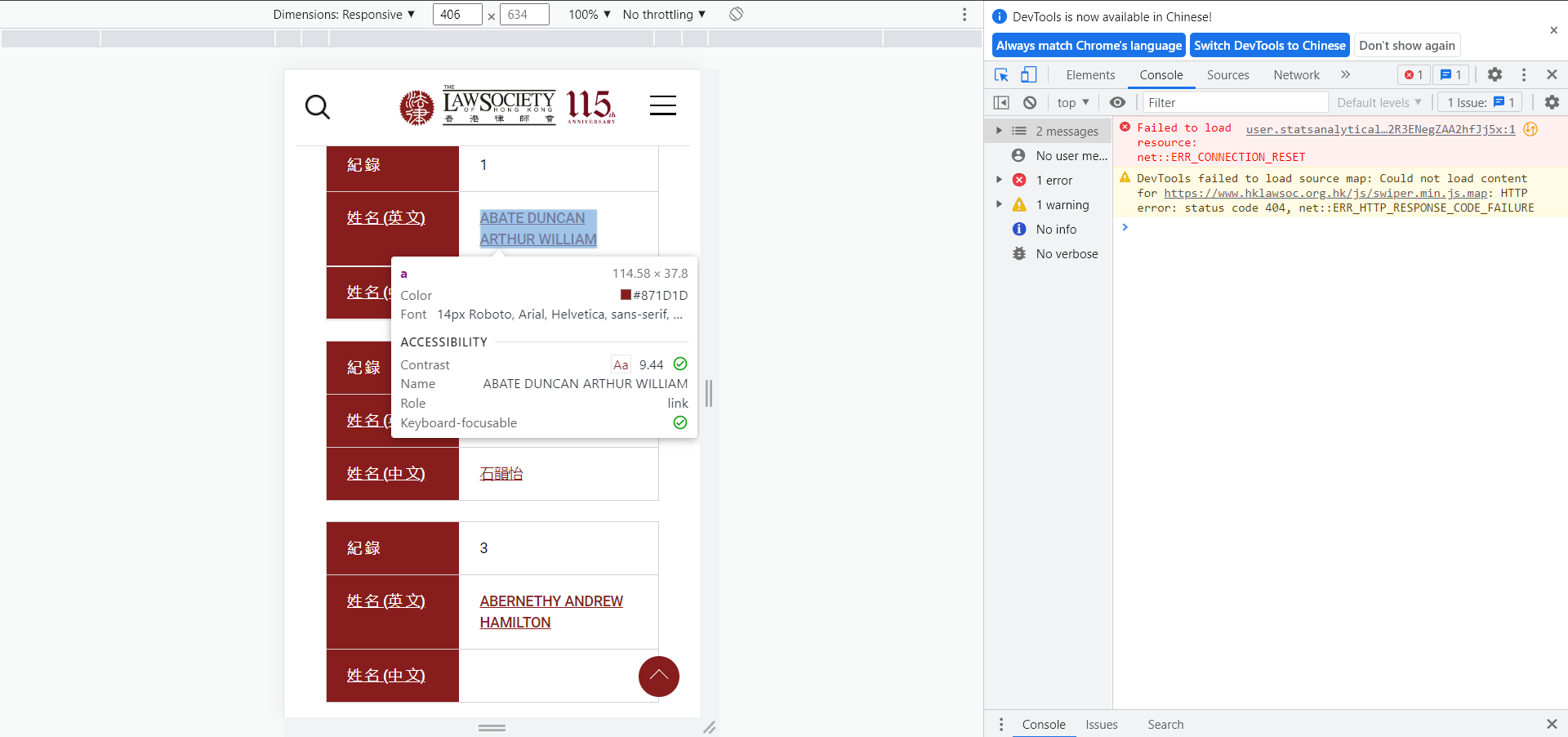
点击后:
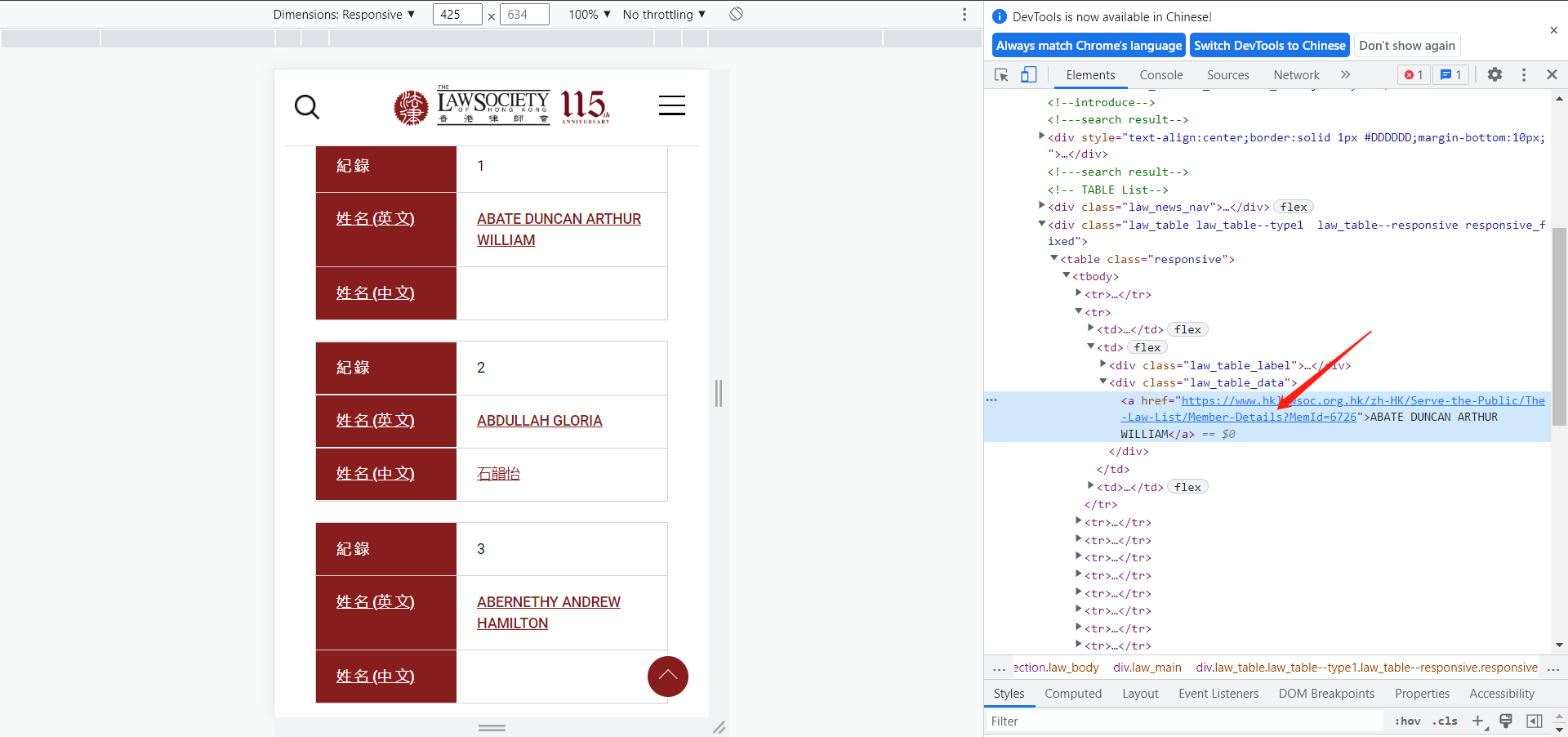
这个超链接很显眼了吧。点进去,正好是我们想要的链接。
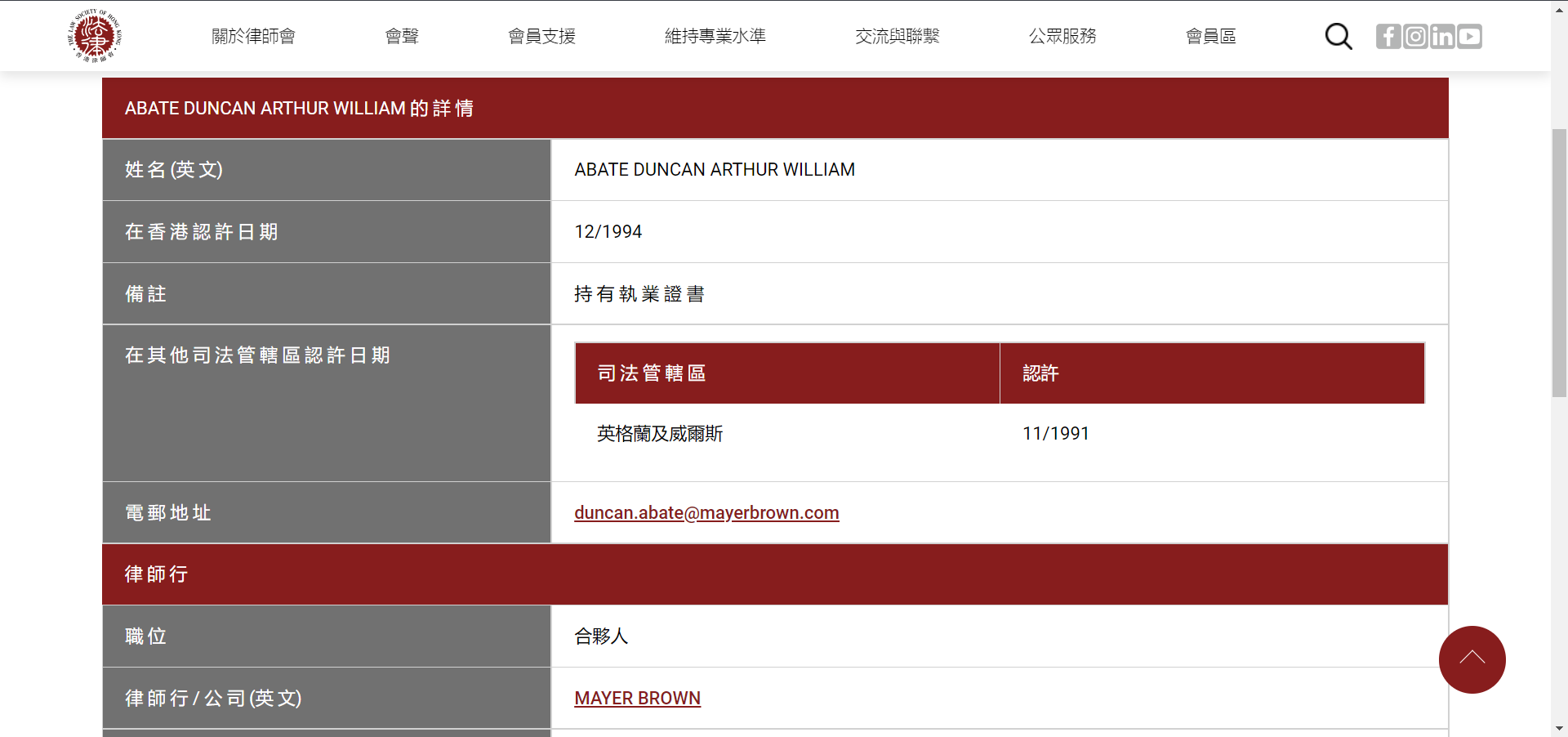
三、开始爬取
还记得我们开始说的嘛,爬虫是封装成正常的请求去访问页面然后下载我们想要的资源,对吧所以,这里细化为两个步骤:
第一步:请求页面资源
爬虫的技术获取网页的手段最基础的就是python的requests方法了。我们这里用的也是这个方法。
代码如下:
import requests
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36'}
for i in range(1, 11339//30):
print(i/(11339//30),end=' ')
url = "https://www.hklawsoc.org.hk/zh-HK/Serve-the-Public/The-Law-List/Members-with-Practising-Certificate?name=&jur=&sort=1&pageIndex="+str(i)+"#tips"
response = requests.get(url, headers=headers)
html = response.content.decode('utf-8', 'ignore')
这里response就是我们请求下来的页面资源了,经过源码解析获取到了html源码。
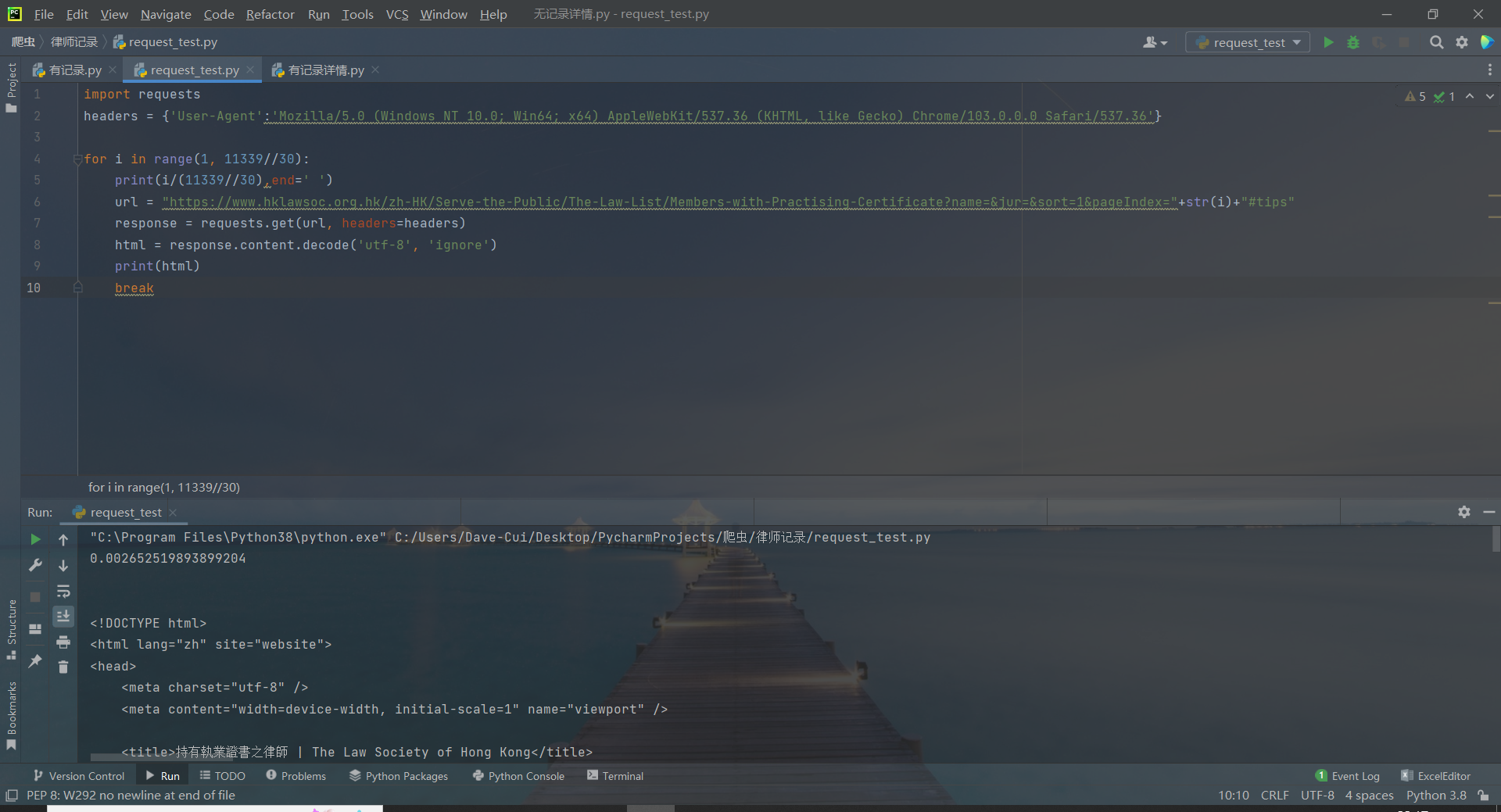
当然,你可能会有疑问这个headers从哪来的,哪里规定的。
每个浏览器都有自己的headers,因为headers要模仿你自己的浏览器向网页发送信息。如果使用Python进行爬取页面时,使用了别人的headers可能会导致爬取不到任何数据(因为代码在你自己的电脑运行,所以无法模拟别人的浏览器)
当然其实用别人也可以,有的网站他可能安全做的没有那么好,就都还可以正常访问。当然,所以如何查找自己headers也很重要,具体步骤如下:
-
随便打开一个网页,例如打开我们这个页面,右键点击‘检查’或者按F12,出现下图页面。

-
点击network
-
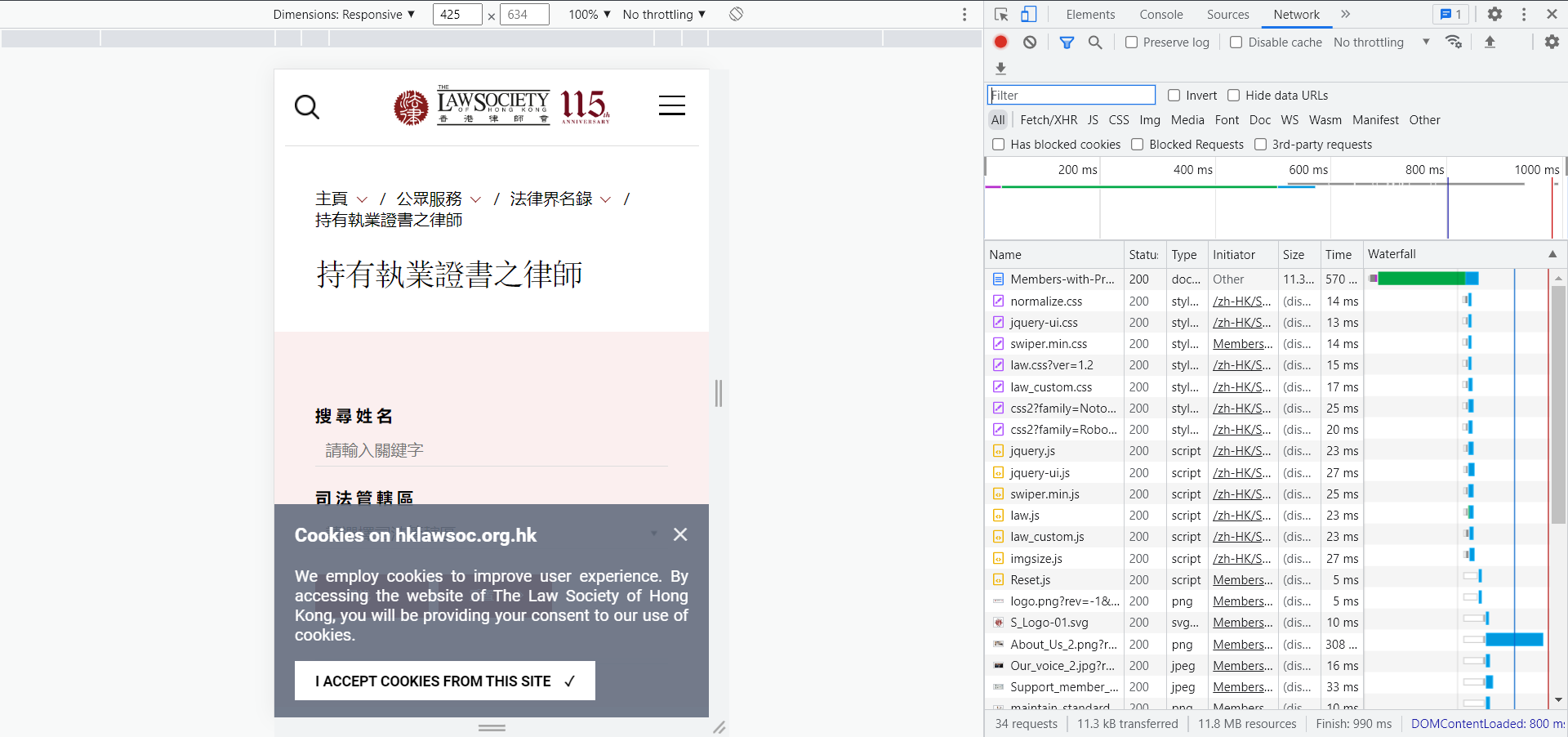
F5刷新
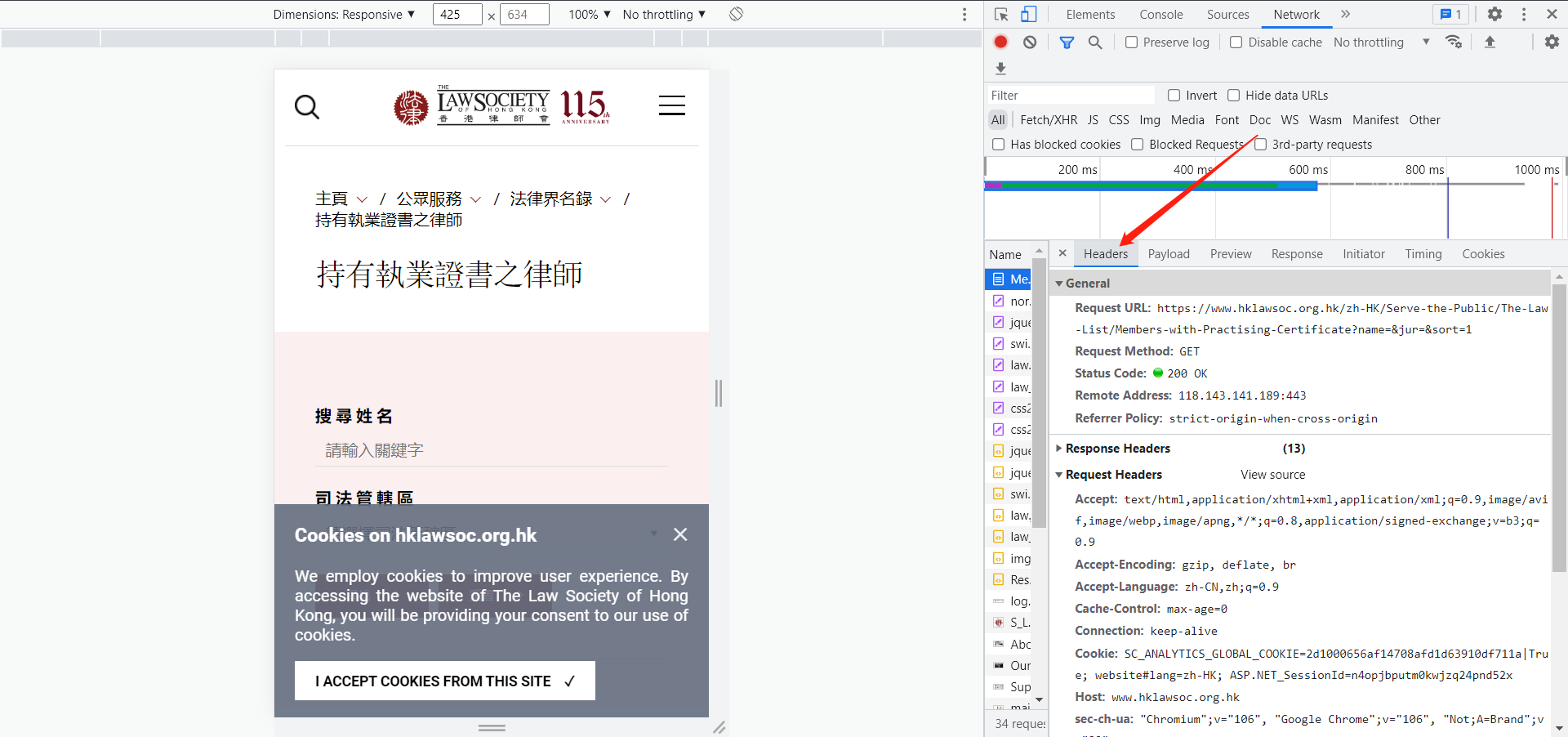
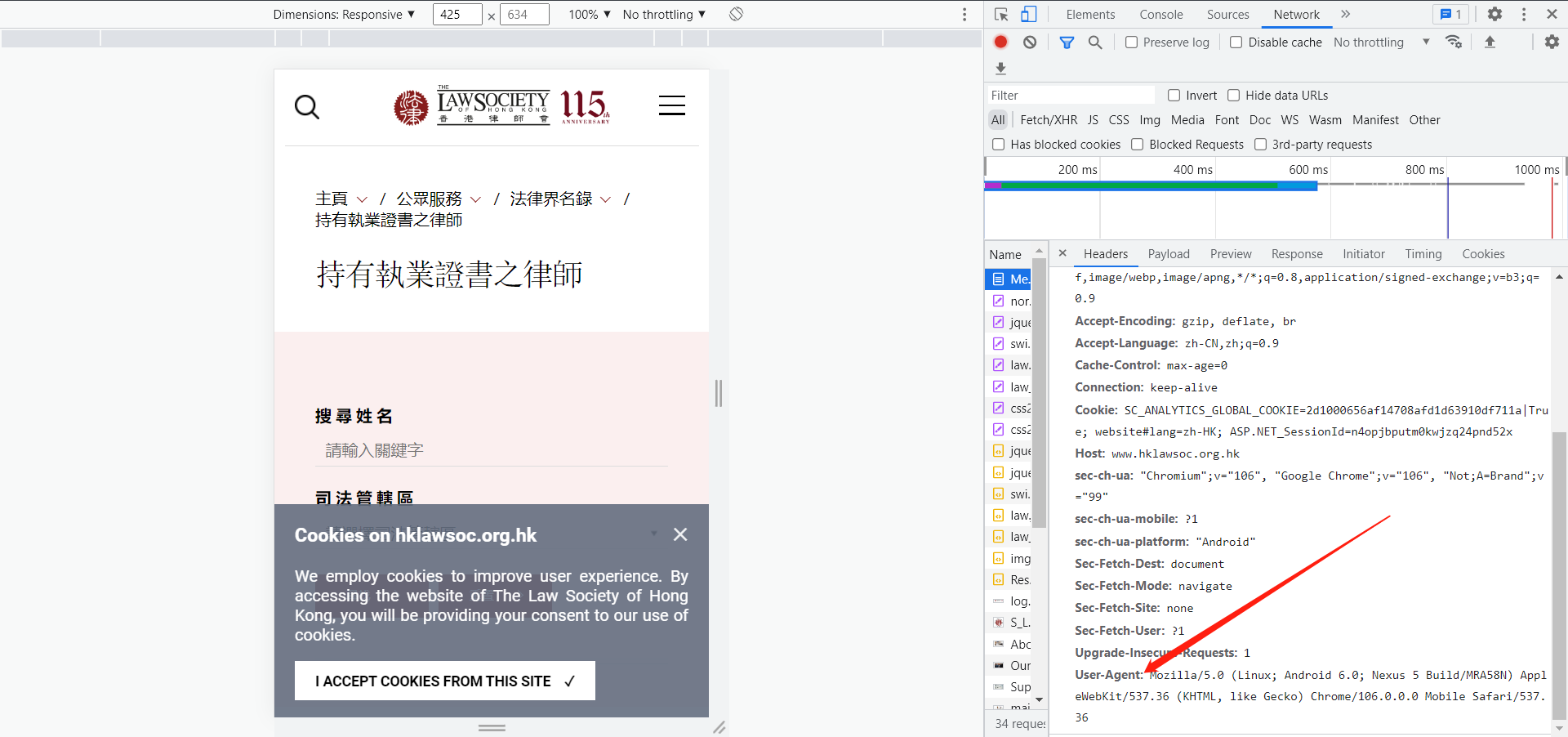
 4. 在name框随便点一个选项,在右侧点击‘headers’选项,在最下方找到‘User-Agent:’,粘贴到自己代码即可。如下图
4. 在name框随便点一个选项,在右侧点击‘headers’选项,在最下方找到‘User-Agent:’,粘贴到自己代码即可。如下图
第二步:解析页面资源
本文由 mdnice 多平台发布















 3050
3050











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









