







机器学习的相关BP算法理解
一.BP算法
1.什么是BP算法
BP算法由信号的正向传播和误差的反向传播两个过程组成
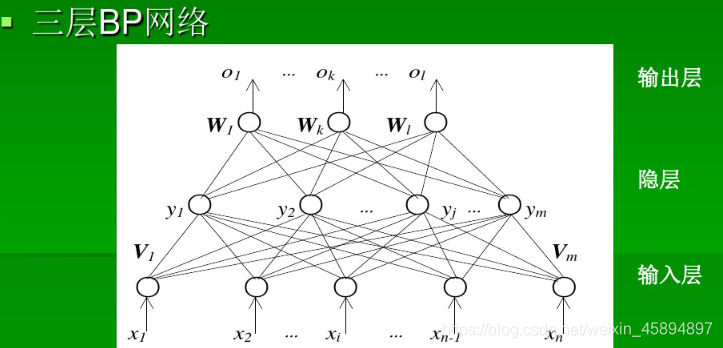
正向传播 时,输入样本从输入层进入网络,经过隐层逐层传递至输出层,如果输出层实际输出与期望输出不同,则误差反向传播;如果相同,则结束算法。
反向传播 时,输出误差按照原路返回计算,先到隐层,再到输入层。反传过程中将误差分给各层各个单元,获得各层各单元的误差信号,并将其作为修正各单元权值的依据。通过梯度下降法不断调整各层神经元的权值,使误差信号减小到最低限度。
2.BP算法的简要步骤
(1)初始化,用小的随机数给各个权值赋初值。
(2)读取参数和训练样本集
(3)归一化处理
(4)对训练集中每一个样本进行计算
(5)满足要求或者条件的结束训练,否则的话,转入步骤4继续。
二.“挑选西瓜”的核心算法
1.preprocess函数:将文字转化为数字,LabelEncoder只适用于转化一列文本数据,转换多列需要factorize方法
2.尝试代码为X=StandardScaler.fit_transform(X),并去掉前面的ss=StandardScaler()报错,因为涉及了两个类,需要先对类实例化,即a=A()
计算基于数学函数方法,如果用文字不能处理,使用LavelEncoder方法转换为数字
#定义Sigmoid
def sigmoid(x):
x=np.array(x,dtype=np.float64)
return 1/(1+np.exp(-x))
#求导
def d_sigmoid(x):
return x*(1-x)
def preprocess(data):
for title in data.columns:
if data[title].dtype=='object':
#print(data[title])
#print("#######")
#每列相同类别转化为同一个数字,不同类别之间不同数字
encoder = LabelEncoder()
data[title] = encoder.fit_transform(data[title])
#print(data[title])
#print("############")
ss = StandardScaler()
#去掉“好瓜”这一列
X = data.drop('好瓜',axis=1)
#print(X)
Y = data['好瓜']
#print(Y)
#StndardScaler.fit_transform计算数据均值和方差,并把数据转换成标准的正态分布
#17行数据17个列表
X = ss.fit_transform(X)
#print(X)
#print(Y)
#将“好瓜”这一列转化为数字的数据reshape为一行
x,y = np.array(X),np. 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









