







atlas数据治理工具
性质
面对海量且持续增长的数据atlas能够清晰的知道,那些数据表格以前是什么样,
以后要变化成什么样?可以知道数据的前世今生!
作用
管理共享元数据,数据分类,集中策略引擎,数据血缘,安全和生命周期的管理,用于数据权限控制策略
角色
Core
Type System:atlas允许用户他们想要管理的元数据对象定义一个模型,在atlas中储存新类型的元数据
Ingest:将原数据添加到atlas,
Export:消费者可以使用这些更改元数据.
Graph Engine:以图形的形式显示各种关系
Titan:图数据库,默认情况下元数据储存配置为Hbase,索引储存配置为Solr,允许高效搜索.
API:atlas的所有功能由api提供给所有的客户
Messaging:出了API以外,用户还可以选择使用基于kafka的消息接口,与atlas集成.
安装
官网的地址:http://atlas.apache.org/
国内镜像的地址:https://mirrors.tuna.tsinghua.edu.cn/apache/atlas/2.0.0/
下载,解压,linux中编译打包,安装maven,配置maven环境,执行maven编译打包,
atlas,内嵌zookeeper,kafka,hbase,solr组件无需安装.
配置atlas
上传atlas编译好的安装包,
修改 vi atlas-env.sh
export JAVA_HOME=/usr/apps/jdk1.8.0_141
export MANAGE_LOCAL_HBASE=true
export MANAGE_LOCAL_SOLR=true
修改atlad-application.properties
atlas.graph.storage.hostname=localhost:2181
atlas.graph.index.search.solr.http-urls=http://localhost:8984/solr
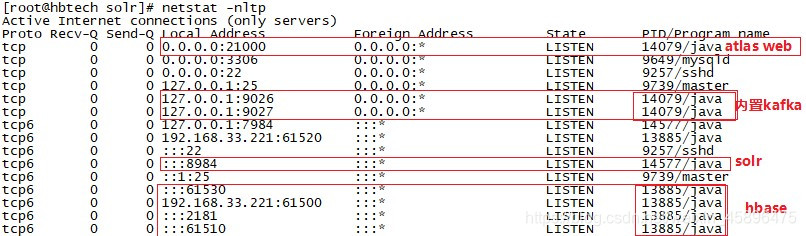
启动atlas
/usr/apps/atlas-2.0.0/bin/atlas_start.py
/usr/apps/atlas-2.0.0/bin/atlas_stop.py
监听端口:
netstat -nltp | grep X
手动启动solr -c:创建一个表 -z:开启zookeeper,hbase代替开启, -p:solr的端口 -force:强制开启!
/usr/apps/atlas-2.0.0/solr/bin/solr start -c -z localhost:2181 -p 8984 -force
以下端口正常开启为atlas启动成功!

solr Web端口为8984 打开solr: http://doit04:8984
solr 可以进去之后首先创建三个表
[root@doit04 atlas-2.0.0]# solr/bin/solr create -c vertex_index -shards 1 -replicationFactor 1 -force
[root@doit04 atlas-2.0.0]# solr/bin/solr create -c edge_index -shards 1 -replicationFactor 1 -force
[root@doit04 atlas-2.0.0]# solr/bin/solr create -c fulltext_index -shards 1 -replicationFactor 1 -force
hive-hook(钩子)的配置
配置了hive的钩子后,在hive中做任何操作,都会被钩子感应到,并以事件的形式发布到kafka,然后atlas的Ingest(摄取)模块消费到kafka中的消息,并被解析成atlas被写入janus的图形数据库来做储存管理.
修改hive-env.sh
export HIVE_AUX_JARS_PATH=/opt/app/apache-atlas-2.0.0/hook/hive
修改 hive-site.xml
<property>
<name>hive.exec.post.hooks</name>
<value>org.apache.atlas.hive.hook.HiveHook</value>
</property>
同步配置
拷贝atlas配置文件,atlas-application.properties到hive配置目录
并添加两行配置
atlas.hook.hive.synchronous=true
atlas.rest.address=http://localhost:21000
执行静态批量导入hive中的表
[root@doit04 atlas-2.0.0]# bin/import-hive.sh
注意
在atlas中静态导入的表是没有血统关系的,只有实时更新的表他会去解析你的insert table 和from才能有你的血统关系,我们我们静态导入的大批量的表,我们如何将表和表之间的关系建立起来呢?
办法
将所有的表在atlas开启的基础上在把所有的表在运行一遍
测试
在hive中创建个数据库再创几个相互依赖的表,
在web界面中点击Search by Type选择hive_db(1)
然后再Relationships中Graph就能看到血统关系了














 2106
2106











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









