







数仓面试题
介绍下数据仓库
主要功能是将OLTP经年积累的大量数据,通过数据仓库的数据存储结构进行OLAP,解决企业中的数据集成与分析问题。
意义:数据仓库的意义就是对企业所有的数据进行汇总,为各个部门提供统一的、规范数据出口
特点:
1、面向主题的:按照主题域进行组织的
2、集成的:数据仓库从企业内不同业务部门数据进行集合的
3、数据稳定的:数仓主要是查询,没有数据更新和删除,趋于稳定
4、数据随时间变化的:数仓会记录某个对象一段时期内的变化情况
5、用于支持管理决策
OLAP、OLTP
| 数据仓库 | 数据库 | |
|---|---|---|
| 应用场景 | OLAP(数据仓库系统) | OLTP(数据库系统) |
| 应用 | 面向主题、分析、决策 | 面向应用、事物驱动,日常操作处理 |
| 数据来源 | 多数据源,强调数据分析 | 单数据源 ,强调内存效率、实时性高 |
| 数据模型 | 以业务主题为参考 | 以业务流程为参考 |
| 特点 | 面向主题的、集成的、相对稳定的、反映历史变化的数据集合 | 二维表的结构存储数据,独立性强,冗余度低 |
| 联机分析处理 | 联机事务处理 |
数仓架构

数仓分层
| 层数 | 作用 | |
|---|---|---|
| ODS 原始数据层 | 建设数据快照,隔离后端表 | 存放原始数据,例如埋点数据(日志数据)、业务操作数据(bin-log) |
| DWD 数据明细层 | 1、对ODS层数据进行清洗、维度退化、脱敏 2、一般与ODS保持粒度一致,组合相似的数据,复用关联计算 | 事实表,以业务驱动为建模驱动,基于每个业务的具体过程特点,构建细粒度的明细事实表 |
| DWS 数据汇总层 | 按照主题域、粒度划分(商家、买家),按照周期粒度,维度聚合形成指标较多的宽表,完成指标口径的统一和沉淀 | 按照业务域进行轻度汇总成一个主题域的服务数据,一般是宽表 |
| ADS 数据应用层 | 按照应用域、颗粒度进行划分;按照应用主题补充数据标签,形成用户画像和专项应用 | BI运营报表、内部数据表 |
| DIM 维表层 | 维度建模思想、建设企业一致性维度。主要包含:高基数维度(用户资料表,千万亿级别),低基数维度(配置表,万级别数据) | 维度表,建立整个业务过程的一致性维度 |
分层的好处:
1、数据解耦,增加可扩展性:减少重复逻辑,便于扩展。
2、清晰数据结构:每一层都有对应的作用
3、数据血缘追踪:清晰表的上下游,方便排查问题
4、复杂问题简单化:复杂问题拆分多个步骤完成,数据出现问题时,方便修复
维度建模&三范式建模
| 维度建模 | 三范式建模 | |
|---|---|---|
| 理论 | Kimball建模 | Inno范式建模 |
| 概念 | 把数据抽取为维度+事实表 | 3NF设计规范,符合实体-关系(E-R)模型 |
| 特点 | 数据抽取为事实-维度模型,数据冗余且不能保证数据口径一致 | 结合业务系统的数据模型,构建实体数据-实体关系的数据表,一份数据只存储在一个地方,没有数据冗余 |
维度建模模型
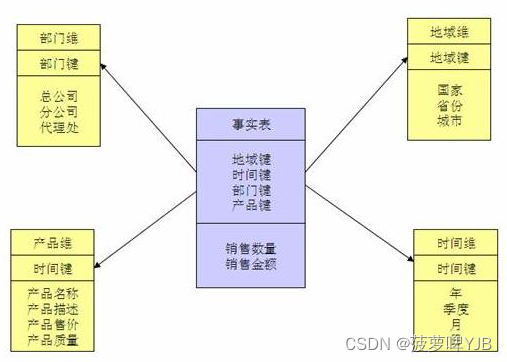
1、星型模型
以事实表为中心,所有维度表直接连在事实表上面。
数据组织直观、执行效率高,因为做了数据冗余,不需要在外部进行连接。
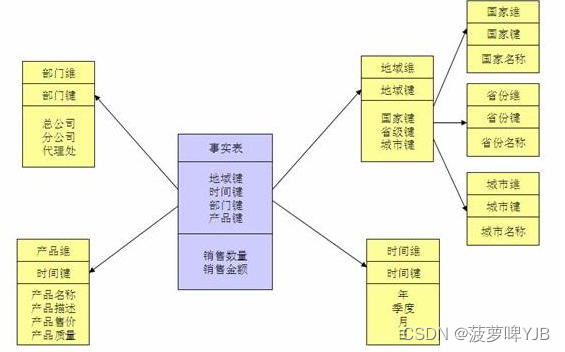
2、雪花模型
维度表可以有其他的维度表,维护成本高,数据性能好。
去除了冗余,需要外建确立管理。
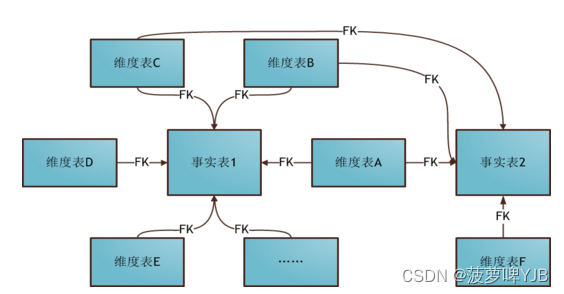
3、星座模型
基于多张事实表,建设一致性维度表,多张事实表共享维度信息。
OneDATA
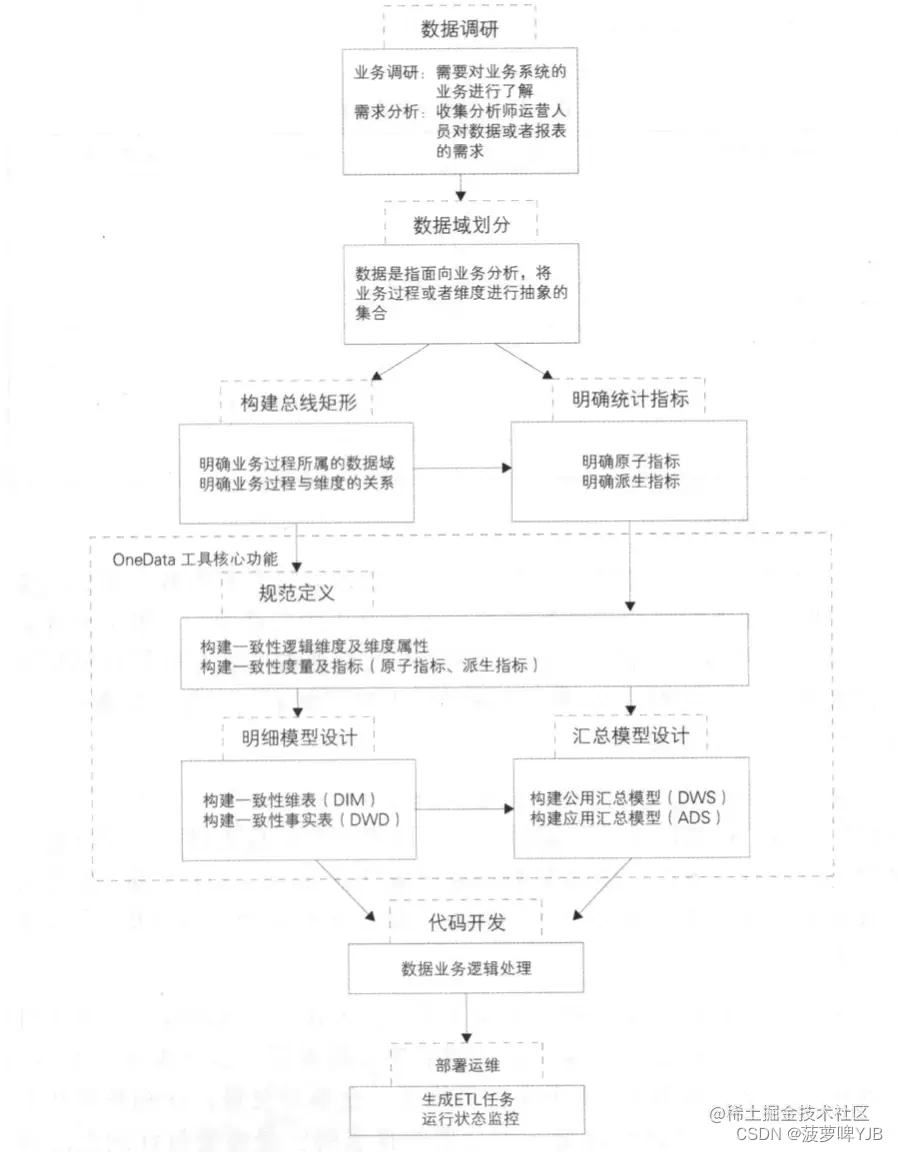
维度建模的步骤,如何确定这些维度的
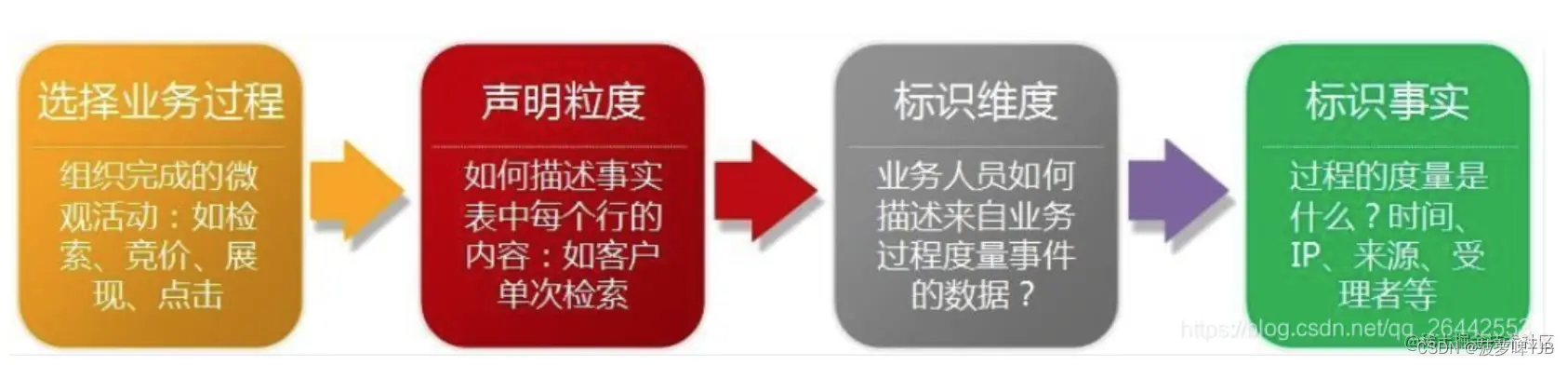
1、选择业务过程
教务系统业务过程:学员购买正价课-助教加微信触达-到课完课/退费退课
2、声明粒度
确定事实表的主键,学员,课程,小节,助教
比如直播间一次学习记录表,一行数据就是一个直播间中用户的学习记录
3、标识维度
通过维度,可以确定度量和事实。例如小节维度,对于直播间,课程属性的需求
4、标识事实:确认事实的指标
比如课程商品的订单活动,相关度量就是销售金额和销售数量
维度表和事实表的区别?
1、维度表:保存这个维度的元数据,例如dim_edu_course_section_base_pt,小节维度表,包含了小节的id、标题、开始结束时间、小节属性(有效、解锁)、小节所属课程以及课程标题、小节所属的直播间id、类型。
2、事实表:每行数据代表一个业务事件。包括业务事件的度量值,事实表 = 主键 + 度量 + 相关维度ID和退化维度。例如dws_edu_pref_user_section_learn_progress_wide_pd(教育履约用户小节学习进度宽表),需要dim表的维度信息计算,例如(学习进度)
维度设计过程
选择维度或新建维度,维度作为维度建模的核心,在企业级数据仓库中必须保证维度的唯一性。例如,助教维度表,与销售维度表高度相同,修改销售维度表
确定主维表,此处的主维表一般是ODS表,直接与业务系统同步。比如商品板块中的商品表。
确定相关维表。数据仓库是业务源系统的数据整合,不同表之间存在关联性。根据对业务的梳理,确定哪些表和主维表间存在关联关系,并选择其中某些表用于生成维度属性。比如类目、SPU、商家等维度和商品存在关联关系。例如,小节维度和直播间维度、课程维度存在关联关系
确定维度属性。本步骤分为两个阶段,第一阶段是直接从主维表中生成新的维度属性;第二个阶段是从相关维度表中选择生成。
一致性维度、一致性事实、总线矩阵
一致性维度:一致性维度的范围是总线架构中的维度,同一集市的维度表,内容相同或包含;
一致性事实:同一集市的维度表,内容相同或包含;
总线矩阵:多维体系结构,业务过程和维度的交点;
事实设计过程
1、根据业务过程确定事实表:接到业务需求后,需要分析业务的整个过程与生命周期,拆解出其中的关键步骤,从而建立事务事实表。例如教育履约的业务过程:购买正价课-添加助教-企微聊天-参课完课-退费退课、复购
2、声明粒度:粒度是事实表中非常重要的一步,出现了问题大概率就会出现重复计算导致指标错误的情况。因此需要根据业务的过程,选择最细级别的原子力度,以保证后期上卷统计有更好的灵活性。例如产品要求统计到订单粒度,但实际业务过程最细粒度是子订单,那么在创建事实表的过程中中应该围绕子订单来进行统计。
3、确定维度:声明了最细粒度,也就意味着确定了主键,其相对应的维度属性也就可以确定。
4、确定事实:事实应该选择与业务过程相关的所有选项,并且粒度与声明的最细粒度一致。
5、关联维度:这一步是针对大数据环境下维度建模的特别步骤,主要为了统计和下游使用的便捷性,适当冗余部分维度,虽然破坏了星型模型的规则,但提高了灵活性。
事实表设计分几种,每一种都是如何在业务中使用
1、单事务事实表:一个阶段的业务过程设计一个事实表,例如dwd_edu_pref_section_drama_detail_pd(教育履约小节直播明细表)
2、多事务事实表:不同阶段的业务过程汇总在一张事实表上,例如教育全链路大宽表
3、周期快照事实表:在确定的时间间隔内,对指标项的统计,获得周期性的度量值,例如期数到课完课数据,对每周的指标进行一次汇总(完课人数、到课人数、退课人数、加微量、触达人数、退费数量)、助教服务表 当月的各种指标
4、累计快照事实表:不确定的时间间隔内,对指标项进行统计。例如淘宝的下单-支付-确认收货-评价时间

3NF
| 范式 | 概念 |
|---|---|
| 1NF | 原子性,数据库中每一列都不可分 |
| 2NF | 所有建依赖于主键(可能是混合主键) |
| 3NF | 每个属性与主键有直接关系,消除传递依赖。(eg:学生表与专业表完全无传值依赖) |
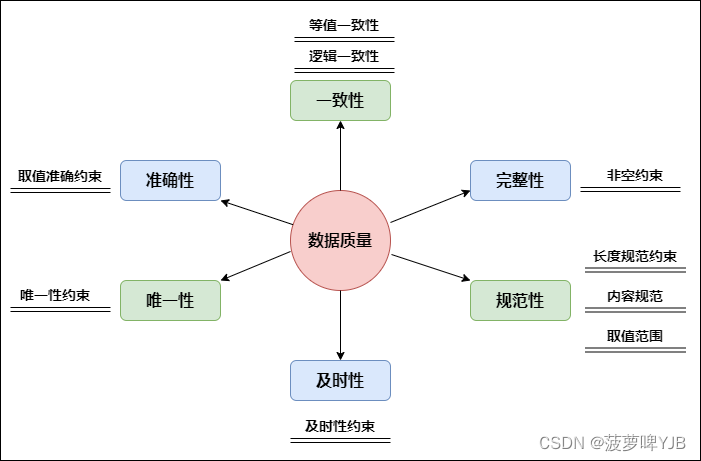
怎么衡量数仓的数据质量,有哪些指标
增量表、全量表、快照表和拉链表
1、全量表:对所有的数据每个分区存一份
2、增量表:只存储当前分区的增量数据
3、快照表:存储的是历史到当前时间的数据。
4、拉链表:对于表中部分字段会被update、查看某一时间段的历史快照、变化比例和频率不是很大的数。
例如,物权表,用户的物权变化是缓慢变化维,采用加行的方式。
评价数仓的好坏
1、模型建设方面
模型复用性,能否被下游引用;
模型的稳定性,数据倾斜、运行时长稳定;
模型的扩展性,内容划分合理性以及与新旧模型的兼容性;
模型建设完善度,能否满足业务的使用;
2、数据成本与性能
无效表的清理;表生命周期的管理;数据倾斜任务;运行超过xxx小时的数据
3、模型的数据质量
HDFS

HDFS文件写入
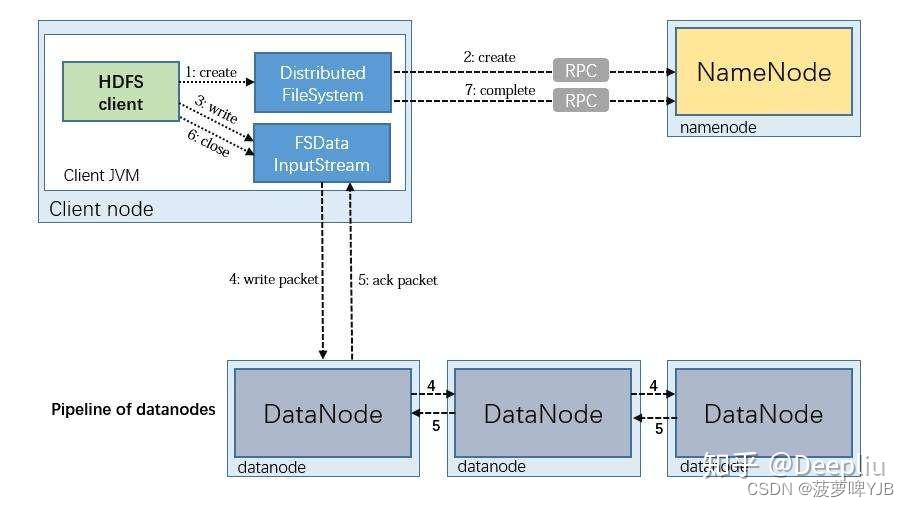
1、client向namenode发送写请求,namenode收到请求后进行用户权限和请求上传路径进行合法验证。响应客户端允许上传
2、client对文件进行切分成block。请求第一块block,namenode收到后返回三台存放数据副本的datanode服务器。client接收到后根据网络拓扑原理(就近原则)找到其中一台进行传输通道建立,然后再与其他两台datanode建立通道串行连接,节约client的io压力
3、通道建立成功后进行数据上传,数据传输最小单位为packet,传输完成后传输第二个block。所有完成后client发送数据上传完成给namenode。
HDFS读取流程
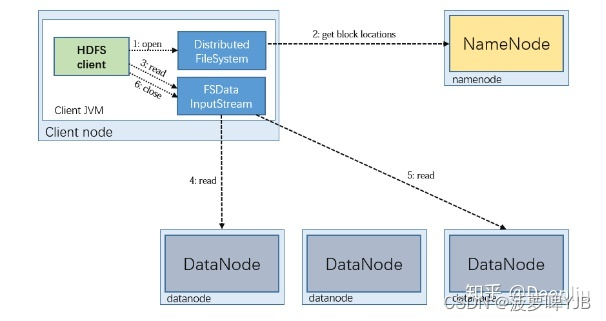
1、client向namenode发送读请求,namenode收到请求后进行请求路径和用户权限校验。校验完成后返回目标文件的元数据信息,包含datanode位置信息与文件的数据块
2、客户端根据元数据信息根据网络拓扑原理和就近原则,发送读请求给datanode
3、datanode收到读请求后,通过HDFS的FSinoutstream将数据读取到本地,然后进行下一个数据块的读取,知道文件的所有block读取完成。
HDFS组成架构
1、client:文件切分;与namenode交互,获取文件位置信息;与datanoode交互,存储数据;关闭、启动、访问HDFS
2、namenode:存储文件的元数据(目录树);
3、datanode:本地系统存储文件的块数据
4、snamenode:对namenode进行元数据备份。editlog的变动录入FSImage中,辅助恢复namenode。
介绍下HDFS,说下HDFS优缺点,以及使用场景
Hadoop架构中负责数据的分布式存储管理的文件系统。
优点:高容错性、分布式架构,可构建在廉价服务器中、适合处理大数据
缺点:不适合低时延、小文件无法合并、不适合并发写入
HDFS的容错机制
集群的部分节点宕机了,根据副本机制,依旧可以从其他机器获取数据,同时,在其他机器上建立该数据副本。
实现方法: HDFS写入时,把文件分割成block,每个block的3个副本存储在三个集群不同机器上。
HDFS的副本机制
■ 第一副本:放置在上传文件的 DataNode上;如果是集群外提交,则随机挑选一台磁盘不太慢、CPU不太忙的节点
■ 第二副本:放置在与第一个副本不同的机架的节点上
■ 第三副本:与第二个副本相同机架的不同节点上。
介绍下HDFS的Block
文件块的大小
文件块的大小默认128M,通过配置参数(dfs.blocksize)规定
文件块配置原理
最佳传输损耗理论:寻址时间占总传输时间1%时,传输损耗最小
MapReduce
介绍下MapReduce
分布式计算框架,将用户的业务逻辑代码整合成完整的分布式运算程序,运行在一个hadoop集群上。
MapReduce架构
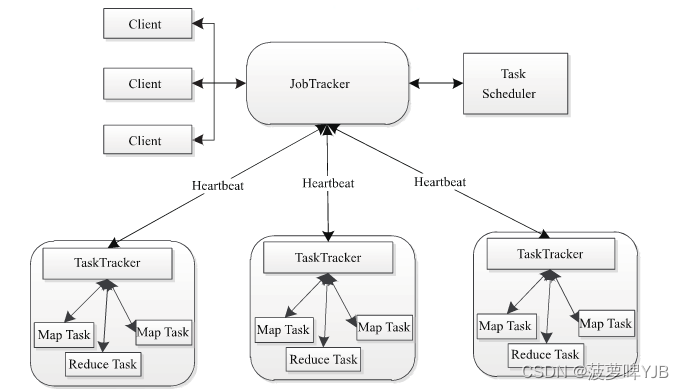
Client:每一个job都会通过client把程序和参数配置打包成jar存储在HDFS,把路径提交到JobTrakcer中Master服务,Master服务创建每一个Task,分发到TaskTracker中。
JobTracker:资源调度和作业监控
TsakTracker:1、周期性通过heartbeat把节点上的资源任务情况反馈给jobtracker;2、执行job的命令;3、分配slot给task
Task:MapTask和ReduceTask
MapReduce工作原理

- split阶段
1、输入文件,InputFormat数据读取
2、split 分片
获取读取的文件,进行逻辑切分。128M,一个集成程序可以计算一个数据块。RecordReader把数据按行切分,输出key(字母偏移量),value(一行数据)。假设HDFS大小为128M,文件是128*10M,Mapreduce就会分为10个MapTask。 - map
map接收数据,逐行输出k,v的list。
通过关联条件,作为map的key。将两张表满足join条件数据发往同一个reduce task。 - shuffle
主要是把数据传输给reduce端:
(1)MapTask收集map()方法的输出<key,value>对,放到内存缓冲区(环形环形缓冲区),其中环形缓冲区的大小默认是100MB;
(2)环形缓冲区到达一定阈值,(80%)时,就会把数据溢出到本地磁盘文件
(3)多个溢写文件会形成大文件
(4)在合并过程中,调用分区(hash算法)和对key进行快速排序sort(分区算法默认是HashPartitioner,分区号是根据key的hashcode对reduce task个数取模得到的。这时候有一个优化方法可选,combiner合并,就是预聚合的操作,将有相同Key 的Value 合并起来, 减少溢写到磁盘的数据量,只能用来累加、最大值使用,不能在求平均值的时候使用)
(5)合成大文件后,map端shuffle的过程也就结束了,后面进入reduce端shuffle的过程。
(6)在Reduce端,shuffle主要分为复制map输出(copy),归并合并(merge sort)两个阶段。reduce会拉取copy同一分区的各个maptask的结果到内存中,如果放不下,就会溢写到磁盘上;然后对内存和磁盘上的数据进行merge归并排序(这样就可以满足将key相同的数据聚在一起) - reduce
reduce从合并的文件中取出一个一个的键值对group,调用用户自定义的reduce方法(),生成最终的输出文件。完成后output到HDFS中
Mapreduce两次排序
- 第一次排序发生在map阶段,在map阶段环形(内存)缓冲区的数据写入到磁盘的时候会根据reducetask的数量生成对应的分区,然后根据对应数据的哈希对分区数取模写入,然后会根据key值对分区中的数据使用快速排序算法进行排序,所以每个分区内的数据是有序的
- 第二次排序发生在reduce阶段,reducetask去每一个maptask所在的节点上的对应的分区(可以根据分区好)上拉取数据,然后因为分区写入使用哈希取模算法,所以相同的数据必定写在同一reduce分区中,采用归并排序对所拉取数据的key进行排序。有几个分区会生成几个partition文件
MapReduce中的Combine是干嘛的?有什么好外?
对MapTask的输出做一个重复key值的合并操作({key,[V1,V2]}),减少网络传输。
MapReduce序列化特点
序列化:把内存中的对象,转化成字节序列,持久化存储和网络传输
反序列化:把收到的字节序列转化为对象
为什么不用java序列化
Java序列化带有其他额外属性(校验信息\header),不利于传输。使用hadoop的writable序列化机制
MapReduce的个数
-
map数量:由数据分成的block数量决定、
-
reduce数量:reduceTask设置的数量决定,默认为1
HIVE join原理
Map阶段
- Key: 关联键
- Value:需要用到的字段(select或者where),以及tag信息(标注value对应的表)
Shuffle阶段 - 根据key值进行hash,推送至不同的reduce中
Reduce - 根据key值完成join操作,通过tag识别不同表中的数据
HIVE
HIVEsql怎么转化成MR的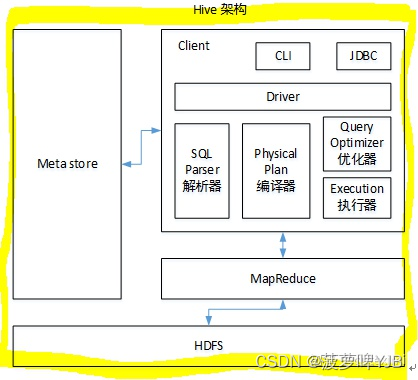
解析器:将sql转化成抽象语法树AST
编译器:把AST编译生成逻辑执行计划
优化器:对逻辑执行计划进行优化
执行器:把逻辑执行计划转化成可以运行的物理计划
HIVE 中order by,sort by, distribute by, cluster by作用以及用法
order by 全局排序,所有数据都在一个reduce中,但是对于大量数据这将会消耗很长的时间去执行
sort by 在task内部保证数据有序
distribute by 指定数据进入同一个reducetask,通常与sort by 一起使用
cluster by cluster by的功能就是distribute by和sort by相结合,只能降序排序
分区表、分桶表、内部表、外部表
1、
内部表:创建内部表时,会把数据移到数据仓库指定的路径。未被external修饰的表为内部表,内部表数据由hive自身管理,在删除表的时候会删除其元数据以及存储数据
外部表:仅记录数据所在的路径,不对数据的位置做改变。建表时被external修饰的为外部表,外部表的数据由hdfs管理,在删除表的时候只会删除元数据,而由hdfs管理的文件则不会被删除
2、
分区表:分类把不同类型的数据存储在不同目录下,分区表中指定分区字段,在查询时按照分区字段查询指定分区数据
动态分区:可以基于查询参数的位置推断分区的名称
set hive.exec.dynamic.partition =true(默认false),表示开启动态分区功能;
set hive.exec.dynamic.partition.mode = nonstrict(默认strict),表示允许所有分区都是动态的,否则必须有静态分区字段
分桶表:把字段按照hash算法进行数据分桶。
作用:
1、通过hash结构,获得更高的查询效率
2、提高join效率
mapjoin原理
在Map阶段将小表读入内存,顺序扫描大表完成Join
HIVE数据倾斜
数据分布不平衡,key值分布不均或者某些key值太集中
(1)key值分布不均导致MR过程中某些reduce需要处理的数据量特别大,有些特别小,导致任务分布不均。
1、可能是mapreduce中某些键值对出现频率非常高。触发Shuffle动作,所有相同key的值就会拉到一个或几个节点上,就容易发生单个节点处理数据量爆增的情况。
2、也可能是因为业务数据分布不均
3、某些SQL语句本身就 倾斜
(2)解决方法:
设置hive.map.aggr=true 开启map端的部分聚合供你,把key相同的聚合在一起
设置hive.groupby.skewindata=true 负载均衡
sql语句
1、 join操作时,数据要进入reduce,需要进行分区,分区时key的值不均匀,hash计算的结果不均匀,key值就集中在某些分区中。
解决方法:
(1)大小表join:map join 在map阶段进行join,完成reduce。让小表进入内存。小表放在join右边
(2)大表join:
- 当一张表中大部分数据为0或者null或者相同的值,容易shuffle给一个reduce。给异常key赋随机前缀分散key
- 当key值都是有效值时,设定set hive.optimize.skewjoin = true; set hive.skewjoin.key = skew_key_threshold控制倾斜阈值。
2、group by造成的数据倾斜
按某个字段进行groupby时,如果数据量特别多,导致reduce处理特别大
解决方法:
设置hive.map.aggr=true //开启map端的部分聚合供你,把key相同的聚合在一起
设置hive.groupby.skewindata=true //负载均衡
给每个key加上前缀进行一次预聚合,再去掉前缀进行一次聚合。两个reduce计算。
3、count distinct:
distinct把map阶段的输出全部分布到一个reduce task上面,先group by 再count
业务数据key值分布不均
hive小文件调优
原因:
数据源上传时就包含很多小文件
动态分区插入数据
reduce数量越多,产生的小文件越多
小文件的影响:
1、小文件会打开很多map,一个map需要开启一个JVM
2、HDFS中,一个小文件对象占150byte,小文件过多占用大量内存
解决方案:
通过参数设置减少reduce的数量
使用hadoop archive命令把小文件进行归档
使用Sequencefile作为表存储格式在一定程度上可以减少小文件数量
HIVE存储格式
TEXTFILE:按行存储,不支持块压缩,默认格式,数据不做压缩,磁盘开销大,加载数据的速度最高
- RCFILE:
数据按行分块,每块按列存储,结合了行存储和列存储的优点
RCFile 保证同一行的数据位于同一节点,因此元组重构的开销很低
RCFile 能够利用列维度的数据压缩,并且能跳过不必要的列读取
- ORCFile:
存储方式:数据按行分块 每块按照列存储
压缩快 快速列存取
效率比rcfile高,是rcfile的改良版本 使用了索引
使用ORC文件格式可以提高hive读、写和处理数据的能力
- PARQUET:按列存储,相对于ORC,Parquet压缩比较低,查询效率较低
- SequenceFile:
Hadoop API提供的一种二进制文件,以<key,value>的形式序列化到文件中
存储方式:行存储
大数据量join
HIVE优化
1、建表优化
2、语法优化
3、job优化
spark
spark基本架构

1、driver:运行application.main()函数,创建sparkcontent模块,负责资源申请和调度
2、cluster manager:控制集群,监控worker
3、worker:负责控制计算节点
4、executor:执行器,运行在worker上面的一个进程
spark 运行流程

1、构建spark application环境,启动sparkconten
2、Sparkcontent向资源管理器(yarn,mesos,standalone)申请executor资源
3、executor向sparkcontext 申请task
4、spark context 把应用程序发送给executor
5、spark context 构建DAG图,把DAG图分解成stage、把TaskSet发送给Task Scheduler,Task Scheduler把task发给executor运行
6、Task 运行完成后释放所有的资源
spark与MapReduce的差别
1、数据中间结果的处理不同,spark把中间的计算结果放在内存中,减少磁盘IO。MR在处理时涉及多次磁盘IO操作
2、spark基于RDD实现高效的迭代计算
3、Spark 基于DAG血统图和checkpoint机制实现很好的容错性
4、MR只有map和reduce操作,实现计算需要多个MR复合设计
spark为什么快
- 消除了冗余的HDFS 读写:Hadoop每次shuffle后,进行磁盘读写操作,spark在shuffle后cache到内存中
- 消除了MapReduce计算:Hadoop的shuffle操作连接着Map和Reduce完整操作,spark基于RDD提供丰富的算子操作。
- JVM优化:Hadoop每次进行MapReduce操作,启动一个Task就会启动一次JVM。Spark的每次MapReduce操作基于线程的,只需要在启动executor时启动一次JVM,内存的Task操作是在线程复用的。
spark 数据倾斜
数据倾斜:任务执行期间,RDD分为一系列分区,每个分区都是数据集的子集。spark调度并行任务的时候,Spark为每一个分区创建一个任务。部分任务的数据量很大,产生数据倾斜(shulfle阶段)
倾斜:distinct、groupbykey、reducebykey、join、repartition
解决方法:
- 过滤少量导致数据倾斜的key
- 对key随机加前缀、执行后去掉前缀、
- 自定义partition
spark容错机制
-
RDD血统图:RDD的lineage记录RDD的元数据信息和转换行为
-
checkpoint检查:将RDD写入磁盘做检查点,使用lineage做容错辅助
-
broadcast广播机制:广播变量,把副本变量分发到每个executor,所有task共享一个副本变量
RDD
RDD分布式数据集
运行流程: -
创建RDD对象
-
DAGScheduler模块介入运算,计算RDD之间依赖关系,形成DAG
-
每一个job分为多个stage
stage划分
- spark任务根据RDD之间依赖关系,形成DAG向量图,DAG提交给DAGScheduler,划分成stage,stage划分依据是宽窄依赖。遇到宽依赖就划分stage,每个stage包含一个或者多个task任务
- 宽窄依赖:宽依赖,一个父RDD被多个子RDD分区使用,发生了shuffle
小文件问题
MR和spark的shuffle区别(*****)
- MR的shuffle
(1)MapTask收集map()方法的输出<key,value>对,放到内存缓冲区(环形环形缓冲区),其中环形缓冲区的大小默认是100MB,
(2)环形缓冲区到达一定阈值,(80%)时,就会把数据溢出到本地磁盘文件
(3)多个溢写文件会形成大文件
(4)在合并过程中,调用分区(hash算法)和对key进行快速排序sort
(5)合成大文件后,map端shuffle的过程也就结束了,后面进入reduce端shuffle的过程。
(6)在Reduce端,shuffle主要分为复制map输出(copy),排序合并(merge sort)两个阶段。把各自的分区copy至reduce任务。 - SPARK的shuffle
基于Hash的实现
基于sort的实现
窗口函数
原理
分析函数 over(partition by 列名 order by 列名 rows between 开始位置 and 结束位置)
partition by 等价于group by分组
order by 全局排序,在同一个task上面排序
1、排序开窗
row_number() over(partition by id1 order by id2)
desk_rank() over(partition by id1 order by id2) 没有间隔
rank() over(partition by id1 order by id2) 有间隔

2、聚合开窗
partition 按相同的进行分区,order by 按当前行累加
max() OVER(partition by id order by id2)
sum() OVER(partition by id order by id2)
avg()
min()
first_value()
last_value()
lead()
sql算法
连续N天登录的用户
select
id
,result_date
,count(result_date) as num
from(
select
id
,date_sub(date,interval cum day) as result_date
from(
select
id
,date(date) as date
,row_number() OVER (PARTITION BY id ORDER BY date(date)) as cum
from test.demo
group by id,date(date)
)t
)t1
group by id
,result_date
having count(result_date)>=3
行转列
SELECT uid,
sum(if(course='语文', score, NULL)) as `语文`,
sum(if(course='数学', score, NULL)) as `数学`,
sum(if(course='英语', score, NULL)) as `英语`,
sum(if(course='物理', score, NULL)) as `物理`,
sum(if(course='化学', score, NULL)) as `化学`
FROM scoreLong
GROUP BY uid
列转行
select uid,语文 as course,score from 表名
WHERE `语文` IS NOT NULL
union
select uid,数学 as course,score from 表名
WHERE `数学` IS NOT NULL
七日留存
select
a.date as date
, sum((case when datediff(b.date,a.date)= 1 then 1 else 0))/count(a.uid) as '次日留存率'
, sum((case when datediff(b.date,a.date)= 3 then 1 else 0))/count(a.uid) as '三日留存率'
, sum((case when datediff(b.date,a.date)= 7 then 1 else 0))/count(a.uid) as '七日留存率'
from
(
select uid
,substr(datetime,0,10) as date
from
table
group by uid ,substr(datetime,0,10)
)a
left join
(
select uid
,substr(datetime,0,10) as date
from
table
group by uid ,substr(datetime,0,10)
)b on a.uid=b.uid and a.date < b.date ---加上了第二个条件可以将join后的表记录数减少一半
group by a.date
相互关注
select
t1.to_user,
t1.from_user,
if(t2.from_user is not null,1,0) as is_friend
from fans t1
left join fans2 t2
on t1.to_user=t2.from_user
and t1.from_user=t2.to_uwer
天/月gmv
要求使用SQL统计出每个用户的累积访问次数
select
count,
sum(count) over(parition by user_id order by day) as sum_count
from table
炸裂函数
| explode() | |
| posexplode() | |
| Lateral View | lateral view udtf(expression) 虚拟表别名 as col1 [,col2,col3……] |
select tf1.*, tf2.*
from (select 0) t
lateral view explode(map('A',10,'B',20,'C',30)) tf1 as key,value
lateral view explode(map('A',10,'B',20,'C',30)) tf2 as key2,value2
where tf1.key = tf2.key2;
集合函数
| concat() | 有null则null |
| concat_ws(分隔符,列,列) | 分隔符不能为null |
| concat_set() | 去重 |
| concat_list() | 排序 |
select username, collect_list(video_name)[0]
from 表名
group by username;















 936
936











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









