







 Delta Lake 是一种数据库解决方案,旨在解决大数据平台架构的挑战,提供 ACID 事务、数据管理和性能优化。它演进了从数仓到数据湖再到Lakehouse的架构,支持流批处理和高级分析场景。Delta Lake 的特性包括事务一致性、时间回溯、元数据管理和统一的流批处理。1.0版本引入了Generated Columns和Standalone特性,增强了开放性和易用性,未来将继续扩展其开放生态系统并优化性能。
Delta Lake 是一种数据库解决方案,旨在解决大数据平台架构的挑战,提供 ACID 事务、数据管理和性能优化。它演进了从数仓到数据湖再到Lakehouse的架构,支持流批处理和高级分析场景。Delta Lake 的特性包括事务一致性、时间回溯、元数据管理和统一的流批处理。1.0版本引入了Generated Columns和Standalone特性,增强了开放性和易用性,未来将继续扩展其开放生态系统并优化性能。
作者
王晓龙(筱龙),阿里云开源大数据平台技术专家
1
Delta Lake 介绍
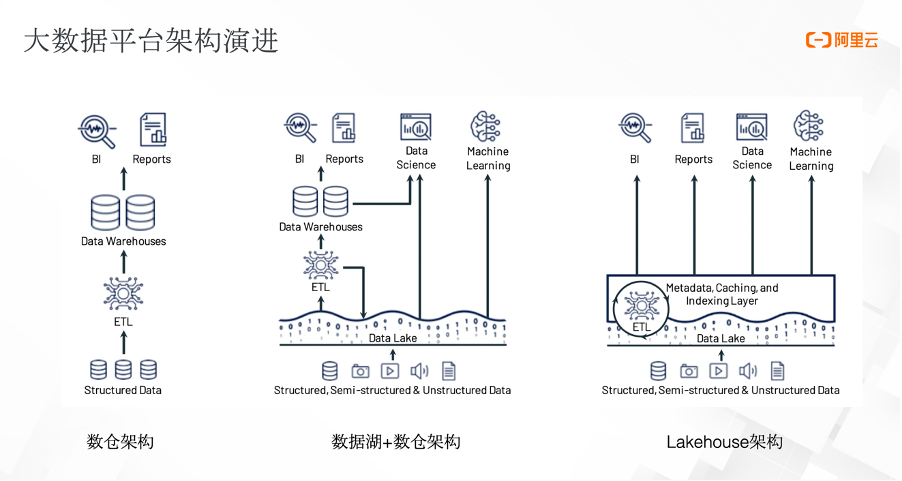
大数据平台架构发展至今,已经经历了三个阶段的技术演进:从最早的数仓,到数据湖+数仓的架构,再到最近两年的 Lakehouse 架构。
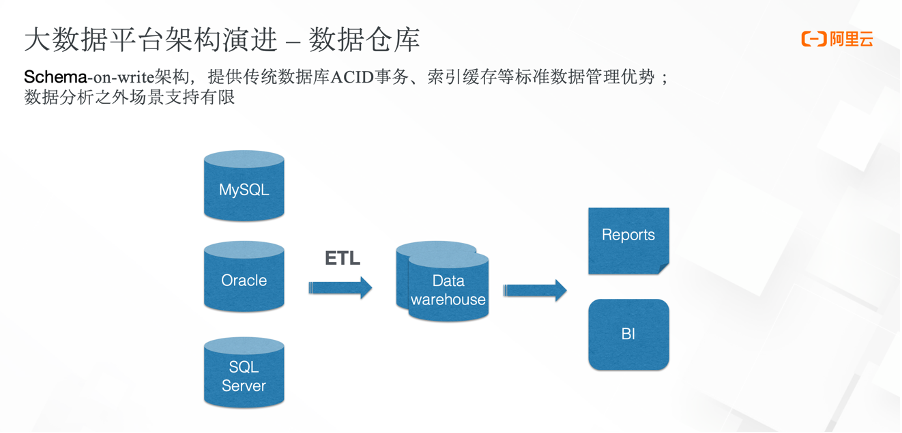
最早的数仓架构是 Schema-on-write 的设计。如上图,数据首先由关系型数据库经过 ETL 导入数据仓库里,可以做一些 BI 分析以及报表分析。它的底层是数据库技术,因此能够提供比较好的数据管理能力,比如能够支持 ACID 事务,能够基于 Schema-on-write 在上游数据写入的时候提供比较强的 Schema 约束,以此保证数据的质量。
同时,基于它自身的诸多优化特性,数仓架构对分析型场景能够提供非常好的支持。但是支持的场景比较有限,基本局限于常用的分析场景。而在大数据时代,随着数据规模的逐渐增加,企业对于数据分析的场景要求越来越多,逐渐产生了一些高级的分析场景需求,比如数据科学类或者机器学习类的场景,而数据仓库对此类需求难以支持。
另外,数据仓库也无法支持半结构化以及非结构化的数据。
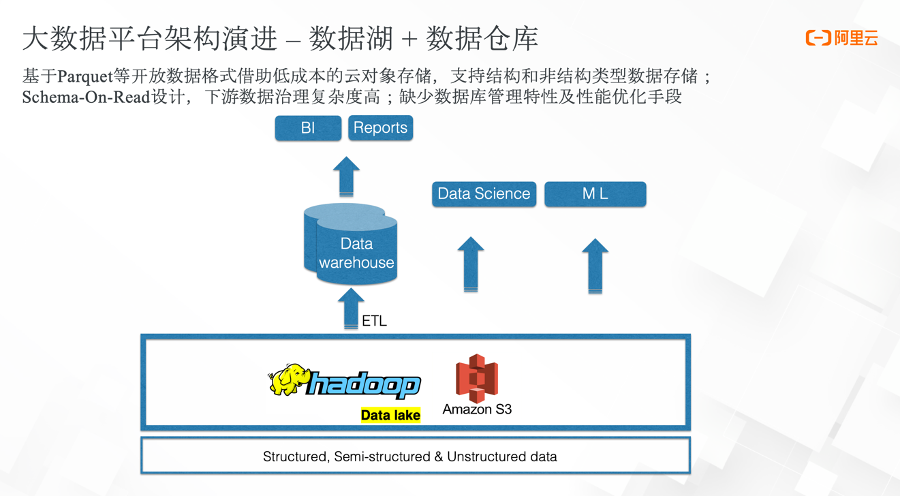
2003年前后,Hadoop 面市。伴随着数据规模体量的爆炸式增长,我们对低成本存储的需求也愈发迫切。于是第二代大数据平台架构雏形初现。它以数据湖为基础,能够支持对结构化、非结构化以及半结构化数据的存储。与数据仓库相比,它是一种 Schema-on-read 的设计,数据能够比较高效地存入数据湖,但是会给下游的分析提供较高的负担。
因为数据在写入之前没有做校验,随着时间的推移,数据湖里的数据会变得越来越脏乱,数据治理的复杂度非常高。同时因为数据湖底层是以开放的数据格式存储在云对象存储上,云对象存储的一些特性会导致数据湖架构缺少像数仓一样的数据管理特性。另外因为云对象存储在大数据查询场景上的性能上不足,导致很多场景下都无法很好地体现数据湖的优势。
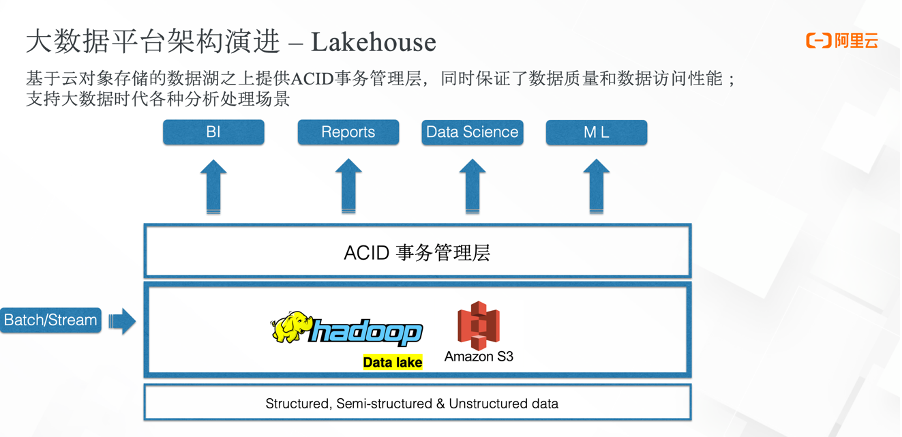
于是第三代大数据平台架构——Lakehouse 应运而生。它在数据湖之上抽象出了事务管理层,能够提供传统数仓的一些数据管理特性,还可以针对云对象存储中的数据做一些数据的性能优化。从而能够针对大数据时代各种复杂的分析场景提供支持,且对于流批两种场景也能够提供统一的处理方式。
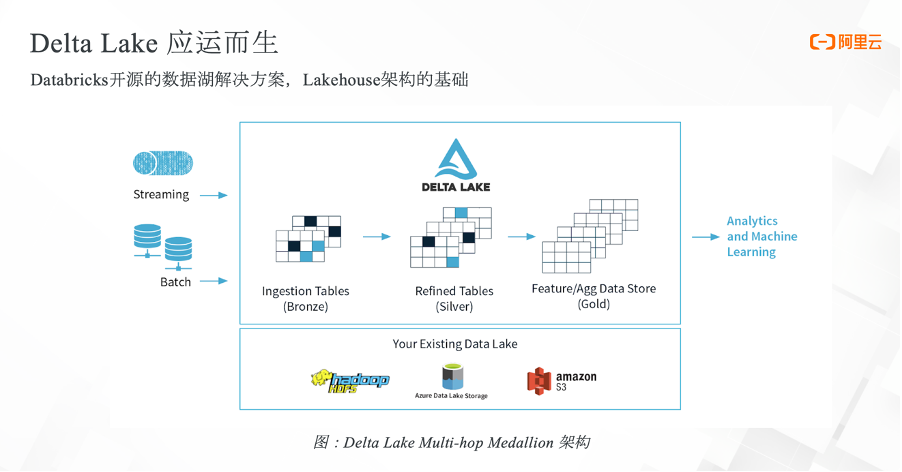
有了 Lakeho
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 312
312











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









