







目录
实验内容
熟悉在Linux使用Java编写Mapreduce程序,编写wordcount程序,找出词频排在前十的词。
实验命令操作
打开终端,根据一下提示,输入命令:
启动hadoop
cd /usr/local/hadoop
./sbin/start-dfs.sh判断hadoop是否启动成功,成功会有显示
jps查看jar包
cd /usr/local/hadoop/myapp
ls
上传词频文件cipin.txt 将其存放在input文件夹中存放的内容是你要统计词频的语段
./bin/hdfs dfs -put /home/hadoop/cipin.txt input查看hadoop目录 查看input文件夹下的内容
./bin/hdfs dfs -ls
./bin/hdfs dfs -ls input删除output文件夹,不删除会报错
./bin/hdfs dfs -rm -r output./运行实验3程序
./bin/hadoop jar ./myapp/shiyan3.jar input output
显示运行结果
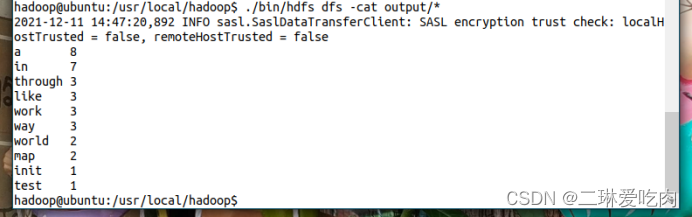
./bin/hdfs dfs -cat output/*关闭hadoop
./sbin/stop-dfs.sh
PS:cipin.txt的内容需要自己编写。可以在本地编辑好了,再上传到hadoop。
实验源码
package sy;
import java.io.IOException;
import java.util.Collections;
import java.util.Comparator;
import java.util.HashMap;
import java.util.LinkedList;
import java.util.List;
import java.util.Map;
import java.util.Map.Entry;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class shiyan3 {
public static class WsMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
@Override
public void map(LongWritable key, Text value, Context context)throws IOException, InterruptedException {
String[] split = value.toString().split(" ");
for (String word : split) {
context.write(new Text(word), new IntWritable(1));
}
}
}
public static class WsReducer extends Reducer<Text, IntWritable, Text, IntWritable>{
Map<String,Integer> map=new HashMap<String, Integer>();
public void reduce(Text key, Iterable<IntWritable> iter,Context conext) throws IOException, InterruptedException {
int count=0;
for (IntWritable wordCount : iter) {
count+=wordCount.get();
}
String name=key.toString();
map.put(name, count);
}
@Override
public void cleanup(Context context)throws IOException, InterruptedException {
//这里将map.entrySet()转换成list
List<Map.Entry<String,Integer>> list=new LinkedList<Map.Entry<String,Integer>>(map.entrySet());
//通过比较器来实现排序
Collections.sort(list,new Comparator<Map.Entry<String,Integer>>() {
//降序排序
@Override
public int compare(Entry<String, Integer> arg0,Entry<String, Integer> arg1) {
return (int) (arg1.getValue() - arg0.getValue());
}
});
for(int i=0;i<10;i++){
context.write(new Text(list.get(i).getKey()), new IntWritable(list.get(i).getValue()));
}
}
}
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
if (otherArgs.length != 2) {
System.err.println("输入参数个数为:"+otherArgs.length+",Usage: wordcount <in> <out>");
System.exit(2);//终止当前正在运行的java虚拟机
}
Job job = Job.getInstance(conf, "CleanUpJob");
job.setJarByClass(shiyan3.class);
job.setMapperClass(WsMapper.class);
job.setReducerClass(WsReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
for(int i = 0; i < otherArgs.length - 1; ++i) {
FileInputFormat.addInputPath(job, new Path(otherArgs[i]));
}
FileOutputFormat.setOutputPath(job, new Path(otherArgs[otherArgs.length - 1]));
System.exit(job.waitForCompletion(true)?0:1);
}
}实验结果















 3651
3651











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











